

- المقدمة
- تنفيذ هذا البرنامج التعليمي
- مجموعة بيانات الكلاب والقطط
- التهيئة
- تنظيف الحيوانات الأليفة: تحسين جودة مجموعة البيانات
- تحميل مجموعة بيانات صور الكلاب والقطط باستخدام Keras
- رسم الحيوانات الأليفة للتحقق من صحة التسمية
- تقسيم عينات التدريب والتحقق من الصحة باستخدام ImageDataGenerator
- شبكة عصبية تلافيفية بسيطة
- زيادة البيانات
- استخدام نموذج مدرب مسبقًا: ResNet50
- الخلاصة
في هذه المقالة، ستقوم ببناء شبكة عصبية تلافيفية CNN من البداية لتصنيف الصور إلى فئتين، كلب أو قطة، بدقة 92٪.
لن نستخدم نقل التعلم transfer learning هذه المرة (لذا لا غش!)، وسأشرح بالتفصيل العملية التي اتبعتها لحل هذه المشكلة الكلاسيكية.
سوف تتعلم كيفية:
- بناء وضبط شبكة تلافيفية مع keras لتصنيف الصور.
- اختر المحسن المناسب للتأكد من أن شبكتك قادرة على التعلم.
- استخدم برنامج keras ImageDataGenerator لزيادة مجموعة البيانات الخاصة بك والحد من الضبط الزائد overfitting.
أخيرًا، ستجرب نموذج ResNet50 المدرب مسبقًا، فقط لترى.
تنفيذ هذا البرنامج التعليمي
على عكس معظم المنشورات في هذه المدونة، لا أقدم وصفة لتشغيل هذا النوتبوك على Google Colab. لقد جربته لكن يبدو أن:
- عمليات نقل القرص على أجهزة Google Colab الافتراضية بطيئة جدًا. يؤدي هذا إلى إبطاء تدريب الشبكات العصبية على مجموعات بيانات كبيرة نسبيًا مثل مجموعة بيانات الكلاب والقطط.
- عدد نوى وحدة المعالجة المركزية على هذه الأجهزة منخفض جدًا للتعامل مع المعالجة المسبقة للصور الثقيلة التي سنحتاج إلى تطبيقها.
نتيجة لذلك، ستحتاج إلى التشغيل على جهازك.
أولاً ، قم بتثبيت TensorFlow لجهاز الكمبيوتر الذي يعمل بنظام التشغيل Linux أو Windows. باستخدام هذه الطرق، ستقوم أيضًا بتثبيت anaconda، بما في ذلك حزمة keras.
بعد ذلك، قم بتثبيت هذه الحزم مع conda:
conda install numpy matplotlib
استنسخ github repo محليًا، وابدأ النوتبوك:
git clone https://github.com/cbernet/maldives.git
cd maldives/dogs_vs_cats
jupyter notebook
وافتح النوتبوك dogs_vs_cats_local.ipynb.
لم أختبر هذه الطريقة، لذا إذا لم تنجح، أخبرني في التعليقات وسأساعدك على الفور.
مجموعة بيانات الكلاب والقطط
تم تقديم مجموعة بيانات الكلاب والقطط لأول مرة في مسابقة Kaggle في عام 2013. للوصول إلى مجموعة البيانات، ستحتاج إلى إنشاء حساب Kaggle وتسجيل الدخول. لا ضغوط، لسنا هنا من أجل المنافسة، ولكن للتعلم!
مجموعة البيانات متوفرة هنا. يمكنك استخدام الأداة المساعدة kaggle للحصول على مجموعة البيانات، أو ببساطة قم بتنزيل ملف train.zip (حوالي 540 ميجابايت). لا تنس تسجيل الدخول إلى Kaggle أولاً.
تعليمات تحضير مجموعة البيانات مخصصة لنظام التشغيل Linux أو macOS. إذا كنت تعمل على Windows، فأنا متأكد من أنه يمكنك بسهولة العثور على طريقة للقيام بذلك (على سبيل المثال، استخدم 7-zip قم بفك ضغط الأرشيف، وWindows Explorer لإنشاء أدلة ونقل الملفات).
بمجرد التنزيل، قم بفك ضغط الأرشيف:
unzip train.zip
قائمة محتويات دليل التدريب:
ls train
سترى الكثير من صور الكلاب والقطط.
في الأقسام التالية، سنستخدم Keras لاسترداد الصور من القرص باستخدام طريقة flow_from_directory لكلاس ImageDataGenerator.
ومع ذلك، تتطلب هذه الطريقة فرز الصور من الفئات المختلفة في أدلة مختلفة. لذلك سنضع كل صور الكلاب في dogs وكل صور القطط في cats:
mkdir cats
mkdir dogs
find train -name 'dog.*' -exec mv {} dogs/ \;
find train -name 'cat.*' -exec mv {} cats/ \;
قد تتساءل عن سبب استخدامي للبحث بدلاً من ملف mv البسيط لنقل الملفات. ذلك لأنه مع mv، يحتاج shell إلى تمرير عدد كبير جدًا من الوسائط إلى الأمر (جميع أسماء الملفات)، وهناك قيود على هذا الرقم على macOS (في Linux، يعمل بشكل جيد). من خلال البحث، يمكننا التغلب على هذا القيد.
التهيئة
الآن، أدخل الخلية الموجودة أسفل موقع دليل مجموعة البيانات، تلك التي تحتوي على الدلائل الفرعية dogs و cats ، وقم بتنفيذها:
# define and move to dataset directory
datasetdir = '/data2/cbernet/maldives/dogs_vs_cats'
import os
os.chdir(datasetdir)
# import the needed packages
import matplotlib.pyplot as plt
import matplotlib.image as img
from tensorflow import keras
# shortcut to the ImageDataGenerator class
ImageDataGenerator = keras.preprocessing.image.ImageDataGenerator
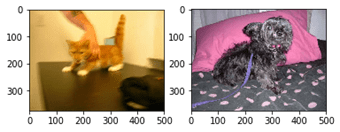
رائع. لكن لنكن أكثر تحديدًا ونطبع بعض المعلومات حول صورنا:
images = []
for i in range(10):
im = img.imread('cats/cat.{}.jpg'.format(i))
images.append(im)
print('image shape', im.shape, 'maximum color level', im.max())
في شكل الصورة، يتوافق العمودان الأولان مع ارتفاع الصورة وعرضها بالبكسل، على التوالي، والعمود الثالث يتوافق مع قنوات الألوان الثلاثة. لذلك يحتوي كل بكسل على ثلاث قيم (للأحمر والأخضر والأزرق على التوالي). نقوم أيضًا بطباعة الحد الأقصى لمستوى اللون في كل قناة، ويمكننا أن نستنتج أن مستويات RGB تقع في النطاق من 0-255.
تنظيف الحيوانات الأليفة: تحسين جودة مجموعة البيانات
إذا كان هناك شيء واحد فقط يجب أن تستخلصه من هذا البرنامج التعليمي فهو هذا:
يجب ألا تثق أبدًا في بياناتك
البيانات دائما قذرة.
لإلقاء نظرة فاحصة على مجموعة البيانات هذه، استخدمت متصفح صور سريعًا للتحقق من جميع الصور في مجلدات الكلاب والقطط. في الواقع، لقد استخدمت تطبيق Preview على جهاز Mac الخاص بي لتصفح أيقونات المعاينة الصغيرة. الدماغ سريع جدًا في اكتشاف المشكلات الواضحة حتى لو تركت عينيك تتجول في عدد كبير من الصور. لذلك لم يستغرقني هذا العمل (الممل) أكثر من 20 دقيقة. لكن بالطبع، لقد فاتني بالتأكيد الكثير من القضايا الأقل وضوحًا.
على أي حال، هذا ما وجدته.
أولاً، ها هي مؤشرات الصور السيئة التي يمكن أن أجدها في كل فئة:
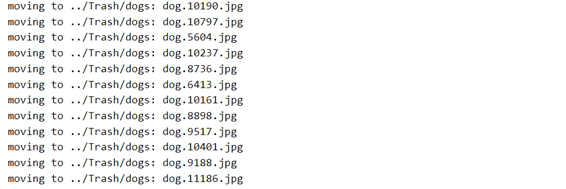
bad_dog_ids = [5604, 6413, 8736, 8898, 9188, 9517, 10161,
10190, 10237, 10401, 10797, 11186]
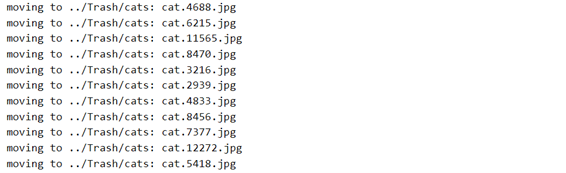
bad_cat_ids = [2939, 3216, 4688, 4833, 5418, 6215, 7377,
8456, 8470, 11565, 12272]
يمكننا بعد ذلك استرداد الصور بهذه المعرفات من مجلدات catsوdogs:
def load_images(ids, categ):
'''return the images corresponding to a list of ids'''
images = []
dirname = categ+'s' # dog -> dogs
for theid in ids:
fname = '{dirname}/{categ}.{theid}.jpg'.format(
dirname=dirname,
categ=categ,
theid=theid
)
im = img.imread(fname)
images.append(im)
return images
bad_dogs = load_images(bad_dog_ids, 'dog')
bad_cats = load_images(bad_cat_ids, 'cat')
def plot_images(images, ids):
ncols, nrows = 4, 3
fig = plt.figure( figsize=(ncols*3, nrows*3), dpi=90)
for i, (img, theid) in enumerate(zip(images,ids)):
plt.subplot(nrows, ncols, i+1)
plt.imshow(img)
plt.title(str(theid))
plt.axis('off')
plot_images(bad_dogs, bad_dog_ids)

بعض هذه الصور لا معنى لها تمامًا، مثل 5604 و8736. بالنسبة إلى 10401 و10797، نرى بالفعل قطة في الصورة! تنهد … الاحتفاظ بالكلاب الكرتونية أم لا أمر قابل للنقاش. أشعر أنه سيكون من الأفضل إزالتها. نفس الشيء بالنسبة لـ 6413، يمكننا الاحتفاظ به، لكنني أخشى أن تركز الشبكة على الرسومات حول صورة الكلب.
الآن دعونا نلقي نظرة على القطط السيئة:
plot_images(bad_cats, bad_cat_ids)

مرة أخرى، لست من محبي الاحتفاظ بقطط الرسوم المتحركة للتدريب، ولكن من يدري، فقد يكون الأمر جيدًا. في الصورة 4688، لدينا قطة كرتونية صغيرة وكلب كرتوني كبير … يجب رفض هذا بوضوح. في الصورة 6215، نرى فروًا فقط، لذا يمكن أن يكون إما قطة أو كلبًا، على الرغم من أن هذا يشبه فراء القطط. ولماذا يوصف الرجل في الصورة رقم 7377 بأنه قطة؟ لا يوجد فكرة…
ومع ذلك، تجدر الإشارة إلى أنه حتى إذا قررنا رفض صور الكارتون للتدريب، فقد تتمكن الشبكة المدربة من التعرف عليها بشكل صحيح.
الآن دعنا ننفذ دالة صغيرة لتنظيف مجموعة البيانات:
import glob
import re
import shutil
# matches any string with the substring ".<digits>."
# such as dog.666.jpg
pattern = re.compile(r'.*\.(\d+)\..*')
def trash_path(dirname):
'''return the path of the Trash directory,
where the bad dog and bad cat images will be moved.
Note that the Trash directory should not be within the dogs/
or the cats/ directory, or Keras will still find these pictures.
'''
return os.path.join('../Trash', dirname)
def cleanup(ids, dirname):
'''move away images with these ids in dirname
'''
os.chdir(datasetdir)
# keep track of current directory
oldpwd = os.getcwd()
# go to either cats/ or dogs/
os.chdir(dirname)
# create the trash directory.
# if it exists, it is first removed
trash = trash_path(dirname)
if os.path.isdir(trash):
shutil.rmtree(trash)
os.makedirs(trash, exist_ok=True)
# loop on all cat or dog files
fnames = os.listdir()
for fname in fnames:
m = pattern.match(fname)
if m:
# extract the id
the_id = int(m.group(1))
if the_id in ids:
# this id is in the list of ids to be trashed
print('moving to {}: {}'.format(trash, fname))
shutil.move(fname, trash)
# going back to root directory
os.chdir(oldpwd)
def restore(dirname):
'''restores files in the trash
I will need this to restore this tutorial to initial state for you
and you might need it if you want to try training the network
without the cleaning of bad images
'''
os.chdir(datasetdir)
oldpwd = os.getcwd()
os.chdir(dirname)
trash = trash_path(dirname)
print(trash)
for fname in os.listdir(trash):
fname = os.path.join(trash,fname)
print('restoring', fname)
print(os.getcwd())
shutil.move(fname, os.getcwd())
os.chdir(oldpwd)
cleanup(bad_cat_ids,'cats')
cleanup(bad_dog_ids, 'dogs')
إذا كنت ترغب في استعادة مجموعة البيانات إلى نسختها الأصلية قبل التنظيف، فما عليك سوى إلغاء التعليق وتنفيذ ما يلي:
# restore('dogs')
# restore('cats')
تحميل مجموعة بيانات صور الكلاب والقطط باستخدام Keras
يتم تدريب الشبكات العصبية من خلال تقديمها مع مجموعات من الصور، كل منها مع تسمية label يحدد الطبيعة الحقيقية للصورة (إما قطة أو كلب في حالتنا). قد تحتوي الدُفعة batch على ترتيب يتراوح بين بضعة أعشار إلى بضع مئات من الصور. إذا كنت تريد مقدمة عن الشبكات العصبية والتعلم الخاضع للإشراف من أجل التصنيف، فيمكنك التحقق من منشوري على التعرف على الأرقام المكتوبة بخط اليد باستخدام scikit-Learn.
لكل صورة، تتم مقارنة توقع الشبكة مع التسمية المقابلة، ويتم تقييم المسافة بين تنبؤات الشبكة والحقيقة للمجموعة بأكملها. بعد ذلك، بعد معالجة الدفعة، يتم تغيير معلمات الشبكة بطريقة تقلل هذه المسافة، وبالتالي تحسين قدرة التنبؤ للشبكة. ثم يبدأ التدريب بشكل متكرر، دفعة بعد دفعة.
لذلك نحن بحاجة إلى طريقة لتحويل صورنا، الآن الملفات الموجودة على القرص، إلى مجموعات من مصفوفات البيانات في الذاكرة والتي يمكن تغذيتها للشبكة أثناء التدريب.
يمكن استخدام ImageDataGenerator بسهولة لهذا الغرض. دعنا نستورد هذه الفئة وننشئ مثيلًا للمولد:
gen = ImageDataGenerator()
الآن، سوف نستخدم طريقة flow_from_directory للكائن gen لبدء إنشاء الدُفعات.
ستعيد هذه الطريقة مكررًا يقوم بإرجاع دفعة في كل مرة يتم تكرارها. لمعرفة كيفية تنظيم البيانات، يمكننا ببساطة إنشاء هذا المكرر، والحصول على أول دفعة لإلقاء نظرة عليها:
iterator = gen.flow_from_directory(
os.getcwd(),
target_size=(256,256),
classes=('dogs','cats')
)
Found 24977 images belonging to 2 classes.
# we can guess that the iterator has a next function,
# because all python iterators have one.
batch = iterator.next()
len(batch)
2
تحتوي الدفعة على عنصرين. ما هو نوعها؟
print(type(batch[0]))
print(type(batch[1]))

مصفوفتان numpy! حسنًا، هذا يعني أنه يمكننا طباعة شكلها وكتابتها:
print(batch[0].shape)
print(batch[0].dtype)
print(batch[0].max())
print(batch[1].shape)
print(batch[1].dtype)

من الواضح أن العنصر الأول عبارة عن مصفوفة من 32 صورة مع 256 × 256 بكسل، و 3 قنوات ملونة، تم ترميزها على أنها عائمة في النطاق من 0 إلى 255. لذا فقد فرض ImageDataGenerator الصورة على 256 × 256 بكسل حسب الطلب، لكنه لم يقم بتسوية اللون بين 0 و 1. سيتعين علينا القيام بذلك لاحقًا.
يحتوي العنصر الثاني على 32 تسمية مقابلة.
قبل إلقاء نظرة مفصلة على التسميات، يمكننا رسم الصورة الأولى:
import numpy as np
# we need to cast the image array to integers
# before plotting as imshow either takes arrays of integers,
# or arrays of floats normalized to 1.
plt.imshow(batch[0][0].astype(np.int))

وهنا التسمية المقابلة:
batch[1][0]
array([1., 0.], dtype=float32)
نرى أن ImageDataGenerator أنتج تلقائيًا تسمية لكل صورة اعتمادًا على الدليل الذي تم العثور عليه فيه. يتم استخدام ترميز واحد ساخن One-hot encoding للتسميات، وهذا بالضبط ما نحتاجه لمهمة التصنيف التي نحن بصدد القيام بها. إذا كنت تريد معرفة المزيد عن الترميز الواحد الساخن، فتحقق من منشوري حول أول شبكة عصبية مع Keras.
يمكننا أيضًا تخمين أن التصنيف [0., 1.]يتوافق مع قطة حقيقية، و [1.,0.]لكلب حقيقي. سيقع توقع الشبكة لصورة معينة في مكان ما بينهما، مثل [0.6,0.4] لكلب. ومع ذلك، هذا مجرد تخمين، والتخمين لا يكفي! نحتاج إلى التأكد، أو نخاطر بتغذية شبكتنا بصور خاطئة (قمامة تدخل، قمامة تخرج garbage in, garbage out).
رسم الحيوانات الأليفة للتحقق من صحة التسمية
للتحقق من صحة تسميات مجموعة البيانات، نريد التحقق من تعيين التسميات بشكل صحيح على دفعات قليلة. لذا فنحن بحاجة إلى دالة يمكنها رسم عدد كبير نسبيًا من الصور وتسميتها. ها هو:
نظرًا لأنها قد تكون المرة الأولى التي تستخدم فيها ImageDataGenerator ، فمن المحتمل أنك تريد أن تكون أكثر ثقة بشأن هذه الأداة. لذلك، سنقوم بتطوير دالة صغيرة في القسم التالي للتحقق من صحة مجموعة بيانات الإدخال.
def plot_images(batch):
imgs = batch[0]
labels = batch[1]
ncols, nrows = 4,8
fig = plt.figure( figsize=(ncols*3, nrows*3), dpi=90)
for i, (img,label) in enumerate(zip(imgs,labels)):
plt.subplot(nrows, ncols, i+1)
plt.imshow(img.astype(np.int))
assert(label[0]+label[1]==1.)
categ = 'dog' if label[0]>0.5 else 'cat'
plt.title( '{} {}'.format(str(label), categ))
plt.axis('off')
plot_images(iterator.next())


يرجى تكرار الخلية السابقة حتى تتأكد من صحة التسميات.
تقسيم عينات التدريب والتحقق من الصحة باستخدام ImageDataGenerator
سنقوم بتدريب شبكتنا العصبية على مجموعة فرعية من صور الكلاب والقطط تسمى مجموعة بيانات التدريب.
إذا كانت الشبكة معقدة بدرجة كافية (إذا كانت تحتوي على معلمات كافية)، فيمكنها البدء في التخصيص، مما يعني أنها قادرة على تعلم الميزات المحددة للصور في مجموعة بيانات التدريب. بمعنى آخر، تفقد الشبكة عمومتها وقدرتها على تصنيف صورة عشوائية على أنها صورة كلب أو قطة.
للتأكد من عدم حدوث الضبط الزائد، سنقوم بتقييم أداء الشبكة على مجموعة بيانات التحقق من الصحة، المنفصلة عن مجموعة بيانات التدريب.
لنقم أولاً بإنشاء ImageDataGenerator جديد. فيما يتعلق بالسابقة، نطلب:
- إعادة قياس جميع مستويات اللون لتكون في النطاق 0-1. نحن نقوم بهذا لأن الشبكات العصبية تتصرف بشكل أفضل في متغيرات الإدخال لترتيب الوحدة.
- استخدم 20٪ من الصور للتحقق، وبالتالي 80٪ للتدريب.
imgdatagen = ImageDataGenerator(
rescale = 1/255.,
validation_split = 0.2,
)
بعد ذلك، نحدد مكرراتنا لمجموعات بيانات التدريب والتحقق من الصحة. نستخدم حجم دفعة batch size من 30 لأنه، عادةً، لا تستطيع الشبكات معرفة ما إذا كان حجم الدُفعة كبيرًا جدًا أو صغيرًا جدًا. يمكنك المحاولة مرة أخرى بحجم دفعة مختلف بعد إكمال هذا البرنامج التعليمي.
يتم فرض الصور على 256 × 256 بكسل. هنا، نحتاج فقط إلى التأكد من أن تنسيق جميع الصور هو نفسه، لأن الشبكة العصبية التلافيفية التي سنستخدمها بها عدد ثابت من المدخلات. اخترت شكل مربع لتجنب حدوث الكثير من التشويه في كل من الصور الأفقية والصورة. ولكن إذا كانت الغالبية العظمى من صورنا صورة شخصية، فربما يكون الشكل الأقرب للصورة هو الخيار الأفضل. لم أتحقق من ذلك.
batch_size = 30
height, width = (256,256)
train_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'training'
)
val_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'validation'
)
شبكة عصبية تلافيفية بسيطة
الشبكات العصبية العميقة التلافيفية هي الخيار المفضل عندما يتعلق الأمر بتصنيف الصور. للحصول على مقدمة مفصلة لهذا النوع من الشبكات، راجع منشوري على ضبط مثل هذه الشبكة للتعرف على الأرقام المكتوبة بخط اليد. النموذج أدناه مشابه جدًا للنموذج الذي استخدمناه في هذه المقالة.
model = keras.models.Sequential()
initializers = {
}
model.add(
keras.layers.Conv2D(
24, 5, input_shape=(256,256,3),
activation='relu',
)
)
model.add( keras.layers.MaxPooling2D(2) )
model.add(
keras.layers.Conv2D(
48, 5, activation='relu',
)
)
model.add( keras.layers.MaxPooling2D(2) )
model.add(
keras.layers.Conv2D(
96, 5, activation='relu',
)
)
model.add( keras.layers.Flatten() )
model.add( keras.layers.Dropout(0.9) )
model.add( keras.layers.Dense(
2, activation='softmax',
)
)
model.summary()
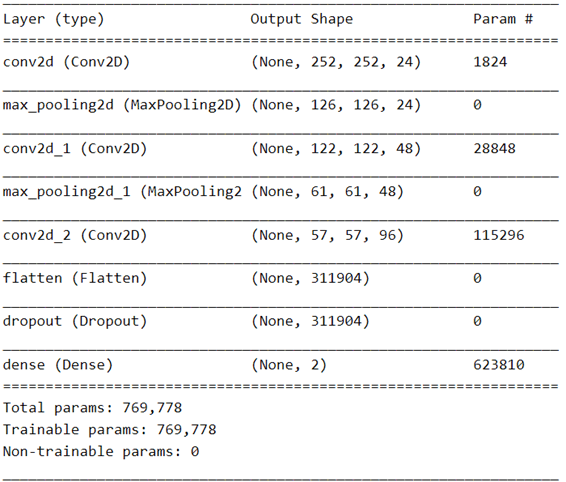
فيما يلي الاختلافات الرئيسية فيما يتعلق بالشبكة المستخدمة في التعرف على الأرقام المكتوبة بخط اليد:
- لدينا اثنين من الخلايا العصبية في آخر طبقة softmax بدلاً من 10، حيث لدينا الآن فئتان.
- صور الإدخال لدينا أكبر بكثير، 256 × 256 بدلاً من 28 × 28. لاحظ أن شكل الإدخال للطبقة الأولى يجب أن يتطابق مع الشكل المعطى للمولد.
- لقد أضفت طبقة تلافيفية ثالثة، وأقوم باستخراج المزيد من الميزات في كل طبقة.
- تم زيادة معدل التسرب dropout rate من 0.4 إلى 0.9 للمساعدة في تقليل الضبط الزائد.
النقطتان الأوليان تقنيتان نوعًا ما، نحتاج فقط إلى القيام بذلك وإلا فلن تعمل الشبكة.
النقطتان الأخيرتان بعيدتان عن الوضوح. تأتي هذه الاختيارات من تحسين طويل الأمد. لقد بدأت بطبقتين تلافيفيتين وميزات أقل، لكن دقة التدريب كانت ثابتة، وهي علامة على أن الشبكة كانت تعاني من الضبط الناقص underfitting. هذا يعني أن الشبكة لم يكن لديها معلمات كافية لوصف مجموعة بيانات التدريب. ناهيك عن مجموعة بيانات التحقق.
لذلك قمت بزيادة التعقيد بإضافة طبقة، وزيادة عدد الميزات المستخرجة في كل طبقة حتى تصل دقة التدريب إلى ما يقرب من 100٪.
في تلك المرحلة، كانت الشبكة تعاني من الضبط الزائد overfitting: كانت دقة التحقق أقل بكثير من دقة التدريب. لذلك قمت بزيادة معدل التسرب ببطء من 0.4 إلى 0.9 لتقليل الضبط الزائد، ووصلت بالفعل إلى هذه القيمة المرتفعة إلى حد ما. وهذا يعني أنه قبل الدخول إلى آخر طبقة كثيفة للتصنيف، تسقط طبقة التسرب 90٪ من المتغيرات من المراحل السابقة للشبكة بشكل عشوائي. هذا كثير!
لتدريب شبكة عصبية، نحتاج إلى استخدام مُحسِّن optimizer. تحدد هذه الأداة كيفية تغيير معلمات الشبكة بعد كل دفعة لتقليل المسافة بين إخراج الشبكة والحقيقة. من بين المحسّنين المطبقين في Keras، غالبًا ما يختار الناس Adam أو RMSProp ، غالبًا على سبيل العادة.
لكن في هذه الحالة، لا يعمل هؤلاء المحسنون جيدًا. غالبًا ما تبدأ الشبكة التدريب في تكوين سيئ بعيدًا جدًا عن مجموعة المعلمات المثلى، ولا يمكنها التعلم. تبدأ الخسارة حوالي 8، ولا تتحسن. نتيجة لذلك، تظل دقة التدريب عند 50٪، وهو ما يعادل تخمينًا عشوائيًا.
لذا عدت إلى التدرج الاشتقاقي العشوائي (SGD). إنه يعمل بشكل جيد والشبكة تتعلم. لكن التدريب طويل جدا. وبالمناسبة، هذا هو السبب في أن الناس اخترعوا محسنات معززة مثل Adam أو RMSProp.
في كل هذه الدراسات، حاولت تغيير معدل التعلم بشكل كبير learning rate، ولكن دون جدوى.
ثم قرأت الورقة حول Adam ، طريقة للتحسين العشوائي ، وقررت أن أجرب AdaMax ، وهو البديل من Adam:
model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adamax(lr=0.001),
metrics=['acc'])
بعد تجميع compiling النموذج، نقوم بتدريبه على مجموعة بيانات التدريب، والتحقق من صحة النتائج في نهاية كل فترة epoch باستخدام مجموعة بيانات التحقق من الصحة. أنا أستخدم 10 نوى من وحدة المعالجة المركزية الخاصة بي للتعامل مع مهام ImageDataGenerator، واثنان من GeForce GTX 1080 Ti لـ TensorFlow.
يجب أن تستغرق كل فترة حوالي دقيقة واحدة. إذا استغرق الأمر أكثر من ذلك بكثير، مثل عشرين دقيقة، فيجب عليك التأكد من أنك تستخدم بالفعل وحدة معالجة الرسوميات الخاصة بك. تحقق من تثبيت برامج تشغيل nvidia و TensorFlow على Linux أو Windows.
history = model.fit_generator(
train_dataset,
validation_data = val_dataset,
workers=10,
epochs=20,
)

الآن وبعد الانتهاء من التدريب، نحتاج إلى طريقة لمعرفة كيفية عمل التدريب. لهذا، سنكتب دالة صغيرة لرسم الخطأ والدقة لكل من مجموعات بيانات التدريب والتحقق من الصحة، كدالة للفترة:
def plot_history(history, yrange):
'''Plot loss and accuracy as a function of the epoch,
for the training and validation datasets.
'''
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
# Get number of epochs
epochs = range(len(acc))
# Plot training and validation accuracy per epoch
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
plt.title('Training and validation accuracy')
plt.ylim(yrange)
# Plot training and validation loss per epoch
plt.figure()
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')
plt.show()
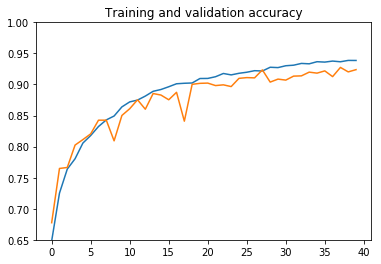
وهنا النتائج:
plot_history(history, (0.65, 1.))
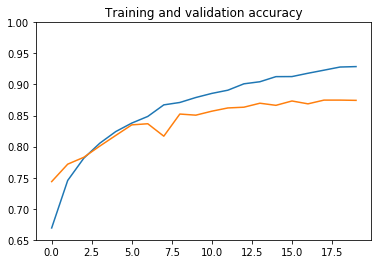
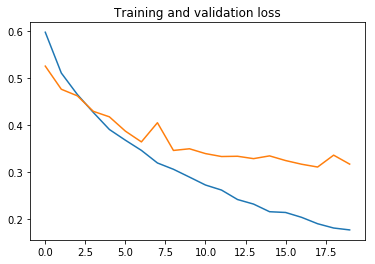
يمكننا أن نستنتج ما يلي:
- دقة التدريب غير قادرة على الاقتراب من 100٪ بسبب معدل التسرب الكبير.
- تبدأ الشبكة في الضبط الزائد في الفترة 6، حتى مع معدل التسرب الكبير.
- تبلغ دقة التحقق من الصحة حوالي 87٪، وهذا ليس سيئًا للغاية.
لا يمكننا زيادة التسرب أكثر، لذلك سنحتاج إلى المزيد من البيانات للقيام بعمل أفضل. في القسم التالي، سنرى كيفية استخدام زيادة البيانات data augmentation لإنشاء المزيد من الصور التدريبية من تلك الموجودة لدينا بالفعل. سيكون ذلك أسهل بكثير وأسرع بكثير من جمع صور القطط والكلاب الجديدة ووضع تسميات عليها.
زيادة البيانات
تتمثل زيادة البيانات في إنشاء أمثلة تدريبية جديدة من الأمثلة التي لدينا بالفعل، بطريقة تؤدي إلى زيادة حجم عينة التدريب بشكل مصطنع. من السهل جدًا القيام بذلك باستخدام ImageDataGenerator. على سبيل المثال، يمكننا أن نبدأ بالتقليب العشوائي randomly flipping لليسار واليمين في صورنا:
imgdatagen = ImageDataGenerator(
rescale = 1/255.,
horizontal_flip = True,
validation_split = 0.2,
)
دعونا نرى تأثير هذا التحول على صورة معينة:
image = img.imread('cats/cat.12.jpg')
def plot_transform():
'''apply the transformation 8 times randomly'''
nrows, ncols = 2,4
fig = plt.figure(figsize=(ncols*3, nrows*3), dpi=90)
for i in range(nrows*ncols):
timage = imgdatagen.random_transform(image)
plt.subplot(nrows, ncols, i+1)
plt.imshow(timage)
plt.axis('off')
plot_transform()

يجب أن تكون قادرًا على رؤية تأثير التقليب الأفقي، إلا إذا كنت غير محظوظ حقًا!
الآن، لنجعل التحويل أكثر تعقيدًا. هذه المرة، سيقوم ImageDataGenerator بقلب الصور وتكبيرها / تصغيرها وتدويرها على أساس عشوائي:
imgdatagen = ImageDataGenerator(
rescale = 1/255.,
horizontal_flip = True,
zoom_range = 0.3,
rotation_range = 15.,
validation_split = 0.1,
)
plot_transform()

لقد رأينا أن هذه التحولات transformations تنتج صورًا جديدة مقبولة تمامًا. لذلك دعونا نعيد تدريب الشبكة مع زيادة البيانات. من المهم ملاحظة أنه نظرًا للطبيعة العشوائية للتحولات، سترى الشبكة كل صورة مرة واحدة فقط. لذلك يمكننا أن نتوقع أنه سيكون من الصعب على الشبكة أن تزداد.
batch_size = 30
height, width = (256,256)
train_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'training'
)
val_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'validation'
)
مع زيادة البيانات، لم تعد هناك حاجة لمعدل تسرب كبير بعد الآن. لقد خفضته من 0.9 إلى 0.2 لكنني لم أحاول ضبط هذه المعلمة:
model = keras.models.Sequential()
initializers = {
}
model.add(
keras.layers.Conv2D(
24, 5, input_shape=(256,256,3),
activation='relu',
)
)
model.add( keras.layers.MaxPooling2D(2) )
model.add(
keras.layers.Conv2D(
48, 5, activation='relu',
)
)
model.add( keras.layers.MaxPooling2D(2) )
model.add(
keras.layers.Conv2D(
96, 5, activation='relu',
)
)
model.add( keras.layers.Flatten() )
model.add( keras.layers.Dropout(0.2) )
model.add( keras.layers.Dense(
2, activation='softmax',
)
)
model.summary()

model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adamax(lr=0.001),
metrics=['acc'])
history_augm = model.fit_generator(
train_dataset,
validation_data = val_dataset,
workers=10,
epochs=40,
)
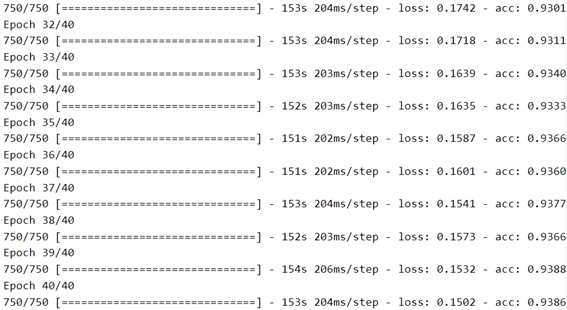
plot_history(history_augm, (0.65, 1))
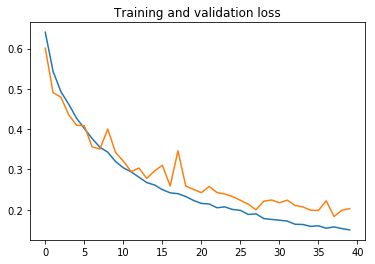
كما ترى، مع زيادة البيانات، يستغرق التدريب وقتًا أطول، ولكن يتم تقليل الضبط الزائد كثيرًا، ويمكننا الوصول إلى دقة تصنيف تبلغ 92٪.
يمكننا الاستمرار في ضبط الشبكة للحد من الضبط الزائد عن طريق زيادة معدل التسرب قليلاً، وتدريب المزيد. لكن أعتقد أننا لن نتمكن من الوصول إلى 95٪ في مجموعة البيانات هذه.
لحسن الحظ، هناك طرق أخرى، كما سنرى.
استخدام نموذج مدرب مسبقًا: ResNet50
يعمل العديد من الأشخاص الأذكياء على التعرف على الصور باستخدام أجهزة قوية ومجموعات بيانات كبيرة جدًا. لا أعرف عنك، لكن ليس لدي ذلك.
ومع ذلك، ما يمكننا فعله هو استخدام شبكاتهم مباشرة. تسمى هذه الشبكات بالنماذج المدربة مسبقًا pre-trained models. نظرًا لأنه يمكن تدريب هذه النماذج على مجموعات بيانات كبيرة جدًا، فإنها عادةً ما تتمتع ببُنية عميقة ومعقدة، كما أنها قوية للغاية. يمكن تنزيل هذه النماذج مع ضبط معلماتها على القيم التي كانت لديها في نهاية التدريب. بهذه الطريقة، يمكننا بسهولة الحصول على أداء ممتاز دون تدريب نموذج جديد بأنفسنا.
فيما يلي قائمة بالموديلات المدربة مسبقًا المتوفرة في keras.
قررت استخدام ResNet50 ، وهو نموذج تم تدريبه على مجموعة بيانات ImageNet ، والتي تحتوي على 14 مليون صورة تنتمي إلى 1000 فئة.
أولاً، نقوم بتنزيل النموذج وإنشائه في بضعة أسطر من التعليمات البرمجية:
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
model = ResNet50(weights='imagenet')
بعد ذلك، نحدد دالة مساعدة صغيرة لتقييم النموذج على صورة إدخال، ونسمي هذه الدالة على بضع صور في مجموعة البيانات الخاصة بنا:
def evaluate(img_fname):
img = image.load_img(img_fname, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
# print the probability and category name for the 5 categories
# with highest probability:
print('Predicted:', decode_predictions(preds, top=5)[0])
plt.imshow(img)
evaluate('dogs/dog.0.jpg')
Predicted: [('n02102318', 'cocker_spaniel', 0.29664052), ('n02097298', 'Scotch_terrier', 0.14396854), ('n02097130', 'giant_schnauzer', 0.14393643), ('n02110627', 'affenpinscher', 0.10783979), ('n02088094', 'Afghan_hound', 0.04753604)]

evaluate('dogs/dog.1.jpg')
Predicted: [('n02099849', 'Chesapeake_Bay_retriever', 0.87790024), ('n02105412', 'kelpie', 0.06544642), ('n02099712', 'Labrador_retriever', 0.008923257), ('n02106550', 'Rottweiler', 0.005405719), ('n02099429', 'curly-coated_retriever', 0.004976345)]
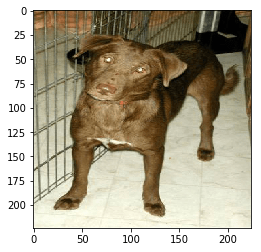
evaluate('dogs/dog.2.jpg')
Predicted: [('n02108551', 'Tibetan_mastiff', 0.2795359), ('n02097474', 'Tibetan_terrier', 0.21642059), ('n02106030', 'collie', 0.21163173), ('n02106166', 'Border_collie', 0.06243812), ('n02108000', 'EntleBucher', 0.040746134)]
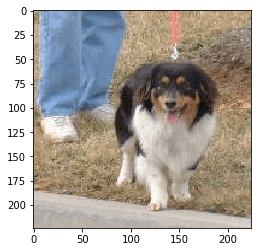
كما ترون، فإن الشبكة تعطي الكلاب في أعلى الفئات، بل إنها تتنبأ إلى حد كبير بسباق الكلب!
ماذا عن القطط؟
evaluate('cats/cat.0.jpg')
Predicted: [('n04404412', 'television', 0.10631036), ('n02094258', 'Norwich_terrier', 0.10413598), ('n02085620', 'Chihuahua', 0.075974055), ('n02093991', 'Irish_terrier', 0.07585583), ('n02123045', 'tabby', 0.07348687)]
هنا لا يعمل بشكل جيد. الفئة الأولى هي التلفاز television، ويفترض أن ذلك يرجع إلى تدني جودة الصورة. ثم نحصل على كلاب من هذا اللون، وأخيراً قطة. في الصورة التالية، الشبكة تتصرف بطريقة أفضل:
evaluate('cats/cat.1.jpg')
Predicted: [('n02123045', 'tabby', 0.6946943), ('n02123159', 'tiger_cat', 0.18619044), ('n02124075', 'Egyptian_cat', 0.06427032), ('n02127052', 'lynx', 0.00819175), ('n03958227', 'plastic_bag', 0.004613503)]

الآن دعنا نحاول مع الرسوم الكاريكاتورية للكلاب:
evaluate('Trash/dogs/dog.9188.jpg')
Predicted: [('n02088466', 'bloodhound', 0.11124672), ('n03000684', 'chain_saw', 0.1000548), ('n03814639', 'neck_brace', 0.04567196), ('n03825788', 'nipple', 0.035572648), ('n03803284', 'muzzle', 0.030304618)]

فئة الاحتمال الأعلى هي بالفعل كلب! … يليه عن كثب منشار السلسلة chain saw. الآن ماذا عن صورة غلاف منشور المدونة هذا؟
# download the image from my github repository
import urllib.request as req
url = 'https://raw.githubusercontent.com/cbernet/maldives/master/dogs_vs_cats/datafrog_chien_chat.png'
req.urlretrieve(url, 'dog_cartoon.jpg')
evaluate('dog_cartoon.jpg')
Predicted: [('n02106662', 'German_shepherd', 0.27522734), ('n02113023', 'Pembroke', 0.17356005), ('n03803284', 'muzzle', 0.12873776), ('n02109047', 'Great_Dane', 0.06609615), ('n02114712', 'red_wolf', 0.060678747)]
لم تنخدع الشبكة بالتنكر: إنه كلب!
حسنًا، لقد استمتعنا مع ResNet50، لكن الشبكة لا تفعل ما نريده بالضبط، وهو تصنيف الصور على أنها كلب أو قطة. للقيام بذلك باستخدام نموذج يعتمد على ImageNet، سنحتاج إلى أن نكون قادرين على اكتشاف أن فئة الحبيبات الدقيقة مثل Great_Dane تنتمي بالفعل إلى فئة dog الخشنة. حتى نقوم بذلك، لا يمكننا تحديد أداء هذا النموذج في سياق مشكلتنا.
يمكننا القيام بذلك يدويًا، لكننا سنتعلم بدلاً من ذلك حلاً أكثر أناقة في المقالة التالية.
الخلاصة
في هذا المنشور، تعلمت كيفية:
- بناء وضبط شبكة تلافيفية مع keras لتصنيف الصور.
- اختر المحسن المناسب للتأكد من أن شبكتك قادرة على التعلم.
- استخدم برنامج keras ImageDataGenerator لزيادة مجموعة البيانات الخاصة بك والحد من الضبط الزائد.
- استخدم نموذج ResNet50 المدرب مسبقًا على مجموعة بيانات ImageNet.
- لقد وصلنا إلى دقة 92٪ من خلال شبكتنا التلافيفية البسيطة، لكننا رأينا أنه سيكون من الصعب المضي قدمًا.
لزيادة تحسين الأداء، سنحتاج إلى استخدام بُنية أكثر تعقيدًا. لكننا نرى أنه حتى مع شبكتنا التلافيفية الصغيرة وزيادة البيانات الجادة، فقد تأثرنا بالفعل بالضبط الزائد overfitting. سيكون الأمر أكثر صعوبة مع شبكة عصبية متطورة تحتوي على العديد من المعلمات.
ولكن في المنشور التالي ، التعرف على الصور باستخدام التعلم الانتقالي ، سنرى كيفية استخدام التعلم الانتقالي لاستخدام أحدث الشبكات التلافيفية لتصنيف الكلاب والقطط بدقة 98.5٪!

