
في هذا المقال، سوف أطلعكم على كيفية تصنيف جنسيات الأشخاص باستخدام أسمائهم. سوف تفكر في كيفية تصنيف الجنسيات باستخدام الأسماء فقط. هناك الكثير حول كيفية اللعب بالأسماء.
تصنيف الجنسيات
لنبدأ بمهمة التعلم العميق هذه لتصنيف الجنسيات عن طريق استيراد الحزم الضرورية. سأصنف الجنسيات بناءً على الأسماء على أنها هندية أو غير هندية. لذلك، دعنا نستورد بعض الحزم ونبدأ بالمهمة:
from tensorflow import keras
import tensorflow as tf
import pandas as pd
import os
import re
الآن، دعنا نستورد مجموعات البيانات. يمكن تنزيل مجموعات البيانات التي أستخدمها هنا في هذه المقالة بسهولة من هنا. الآن بعد استيراد مجموعات البيانات، سأقوم بإعداد دالتين مساعدتين لتنظيف البيانات ومعالجة البيانات:
male_data = pd.read_csv(male.csv)
female_data = pd.read_csv(femaile.csv)
repl_list = ['s/o','d/o','w/o','/','&',',','-']
def clean_data(name):
name = str(name).lower()
name = (''.join(i for i in name if ord(i)<128)).strip()
for repl in repl_list:
name = name.replace(repl," ")
if '@' in name:
pos = name.find('@')
name = name[:pos].strip()
name = name.split(" ")
name = " ".join([each.strip() for each in name])
return name
def remove_records(merged_data):
merged_data['delete'] = 0
merged_data.loc[merged_data['name'].str.find('with') != -1,
'delete'] = 1
merged_data.loc[merged_data['count_words']>=5,'delete']=1
merged_data.loc[merged_data['count_words']==0,'delete']=1
merged_data.loc[merged_data['name'].str.contains(r'\d') == True,
'delete']=1
cleaned_data = merged_data[merged_data.delete==0]
return cleaned_data
merged_data = pd.concat((male_data,female_data),axis=0)
merged_data['name'] = merged_data['name'].apply(clean_data)
merged_data['count_words'] = merged_data['name'].str.split().apply(len)
cleaned_data = remove_records(merged_data)
indian_cleaned_data = cleaned_data[['name','count_words']].drop_duplicates(
subset='name',keep='first')
indian_cleaned_data['label'] = 'indian'
len(indian_cleaned_data)
13754
بعد تحميل وإزالة الإدخالات الخاطئة في البيانات، حصلنا على عدد قليل من السجلات تقريبا 13000.
بالنسبة للأسماء غير الهندية، هناك حزمة أنيقة تسمى Faker. هذا يولد أسماء من مناطق مختلفة:
from faker import Faker
fake = Faker(‘en_US’)
fake.name()
‘Brian Evans’
لقد أنشأنا نفس عدد الأسماء تقريبًا كما لدينا في مجموعة البيانات الهندية. ثم أزلنا عينات أطول من 5 كلمات. احتوت مجموعة البيانات الهندية على الكثير من الأسماء بأسماء أولى فقط. لذلك نحن بحاجة إلى جعل التوزيع العام لغير الهند متشابهًا أيضًا.
non_indian_data.head()
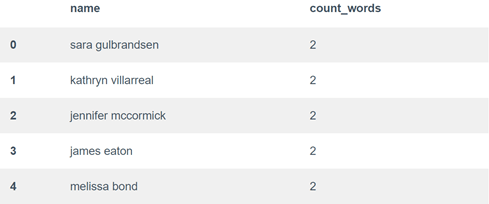
انتهى بنا المطاف بحوالي 14000 اسم غير هندي و13000 اسم هندي. لنقم الآن ببناء شبكة عصبية لتصنيف الجنسيات باستخدام الأسماء:
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from keras.layers.embeddings import Embedding
from keras.utils import to_categorical
import numpy as np
from sklearn.preprocessing import LabelEncoder
from keras.callbacks import Callback
np.random.seed(42)
def char_encoded_representation(data,tokenizer,vocab_size,max_len):
char_index_sentences = tokenizer.texts_to_sequences(data)
sequences = [to_categorical(x, num_classes=vocab_size) for x in char_index_sentences]
X = sequence.pad_sequences(sequences, maxlen=max_len)
return X
def build_model(hidden_units,max_len,vocab_size):
model = Sequential()
model.add(LSTM(hidden_units,input_shape=(max_len,vocab_size)))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
print(model.summary())
return model
model = build_model(100,max_len,vocab_size)
model.fit(X_train, y_train, epochs=20, batch_size=64,callbacks=myCallback(X_test,y_test))
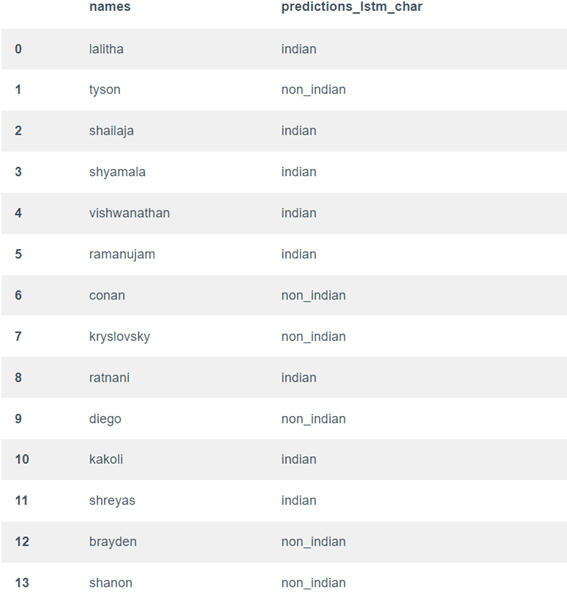
هذه هي الطريقة التي يمكننا بها تصنيف الجنسيات بسهولة باستخدام التعلم العميق. لم أقم بتضمين الكود الكامل والاستكشاف هنا، يمكنك إلقاء نظرة على الكود الكامل من هنا.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.