
مشروع3: تحليل المشاعر على تويتر باستخدام التعلم الالي

Twitter هو أحد منصات التواصل الاجتماعي حيث يتمتع الأشخاص بحرية مشاركة آرائهم حول أي موضوع. نرى أحيانًا مناقشة قوية على Twitter حول رأي شخص ما تؤدي أحيانًا إلى مجموعة من التغريدات السلبية. مع وضع ذلك في الاعتبار، إذا كنت تريد معرفة كيفية إجراء تحليل المشاعر على Twitter، فهذه المقالة مناسبة لك. في هذه المقالة، سوف أطلعك على مهمة تحليل المشاعر على Twitter باستخدام Python.
تحليل المشاعر على تويتر
تحليل المشاعر Sentiment analysis مهمة معالجة اللغة الطبيعية. يجب على جميع منصات وسائل التواصل الاجتماعي مراقبة مشاعر المشاركين في المناقشة. نرى في الغالب آراء سلبية على تويتر عندما تكون المناقشة سياسية. لذلك، يجب أن تستمر كل منصة في تحليل المشاعر للعثور على نوع الأشخاص الذين ينشرون الكراهية والسلبية على نظامهم الأساسي.
بالنسبة لمهمة تحليل المشاعر على Twitter، قمت بجمع مجموعة بيانات من Kaggle تحتوي على تغريدات حول مناقشة طويلة داخل مجموعة من المستخدمين. مهمتنا هنا هي تحديد عدد التغريدات السلبية والإيجابية حتى نتمكن من إعطاء نتيجة. لذلك، في القسم أدناه، سأقدم لك مهمة تحليل المشاعر على Twitter باستخدام Python.
تحليل المشاعر على Twitter باستخدام Python
لنبدأ مهمة تحليل المشاعر على Twitter من خلال استيراد مكتبات Python ومجموعة البيانات اللازمة:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import re
import nltk
import nltk
data = pd.read_csv("https://raw.githubusercontent.com/amankharwal/Website-data/master/twitter.csv")
print(data.head())
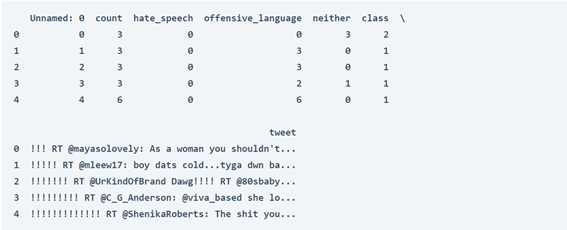
يحتوي عمود التغريدات tweet column في مجموعة البيانات أعلاه على التغريدات التي نحتاج إلى استخدامها لتحليل مشاعر المشاركين في المناقشة. ولكن للمضي قدمًا، يتعين علينا تنظيف الكثير من الأخطاء والرموز الخاصة الأخرى لأن هذه التغريدات تحتوي على الكثير من الأخطاء اللغوية. إذن إليك كيف يمكننا تنظيف عمود التغريدة:
nltk.download('stopwords')
stemmer = nltk.SnowballStemmer("english")
from nltk.corpus import stopwords
import string
stopword=set(stopwords.words('english'))
def clean(text):
text = str(text).lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('https?://\S+|www\.\S+', '', text)
text = re.sub('<.*?>+', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\n', '', text)
text = re.sub('\w*\d\w*', '', text)
text = [word for word in text.split(' ') if word not in stopword]
text=" ".join(text)
text = [stemmer.stem(word) for word in text.split(' ')]
text=" ".join(text)
return text
data["tweet"] = data["tweet"].apply(clean)
الآن، الخطوة التالية هي حساب درجات المشاعر لهذه التغريدات وتعيين تسمية للتغريدات على أنها إيجابية positive أو سلبية negative neutral أو محايدة. إليك كيفية حساب درجات المشاعر في التغريدات:
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sentiments = SentimentIntensityAnalyzer()
data["Positive"] = [sentiments.polarity_scores(i)["pos"] for i in data["tweet"]]
data["Negative"] = [sentiments.polarity_scores(i)["neg"] for i in data["tweet"]]
data["Neutral"] = [sentiments.polarity_scores(i)["neu"] for i in data["tweet"]]
الآن سأختار فقط الأعمدة من هذه البيانات التي نحتاجها لبقية مهمة تحليل المشاعر على Twitter:
data = data[["tweet", "Positive",
"Negative", "Neutral"]]
print(data.head())
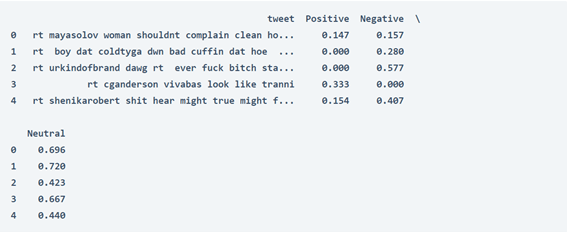
دعنا الآن نلقي نظرة على التصنيف الأكثر شيوعًا المخصص للتغريدات وفقًا لدرجات المشاعر:
x = sum(data["Positive"])
y = sum(data["Negative"])
z = sum(data["Neutral"])
def sentiment_score(a, b, c):
if (a>b) and (a>c):
print("Positive 😊 ")
elif (b>a) and (b>c):
print("Negative 😠 ")
else:
print("Neutral 🙂 ")
sentiment_score(x, y, z)
Neutral 🙂
لذا فإن معظم التغريدات محايدة، ما يعني أنها ليست إيجابية ولا سلبية. الآن دعنا نلقي نظرة على إجمالي درجات المشاعر:
print("Positive: ", x)
print("Negative: ", y)
print("Neutral: ", z)
Positive: 2880.086000000009
Negative: 7201.020999999922
Neutral: 14696.887999999733
مجموع التغريدات المحايدة أعلى بكثير من السلبية والإيجابية، لكن من بين جميع التغريدات السلبية أكبر من التغريدات الإيجابية، لذلك يمكننا القول إن معظم الآراء سلبية.
الملخص
هذه هي الطريقة التي يمكنك بها أداء مهمة تحليل المشاعر على Twitter باستخدام لغة برمجة Python. تحليل المشاعر مهمة معالجة اللغة الطبيعية. تحتاج جميع منصات وسائل التواصل الاجتماعي إلى التحقق من مشاعر الأشخاص المشاركين في المناقشة. آمل أن تكون قد أحببت هذا المقال على تحليل المشاعر على Twitter باستخدام Python.