

- منشئ العنوان مع التعلم العميق
- توليد التسلسلات
- نموذج LSTM
- مولد العنوان مع نموذج LSTM
- مولد العنوان مع التعلم العميق: اختبار النموذج
- توليد العناوين
في هذه المقالة، سأستخدم مجموعة بيانات مقاطع الفيديو الشائعة على YouTube ولغة برمجة بايثون لتدريب نموذج للغة إنشاء النص باستخدام التعلم الآلي، والذي سيتم استخدامه لمهمة إنشاء عنوان لمقاطع فيديو youtube أو حتى لمدوناتك.
منشئ العنوان Title generator مهمة معالجة لغة طبيعية natural language processing وهي قضية مركزية للعديد من التعلم الآلي، بما في ذلك توليف النص text synthesis، والكلام إلى نص speech to text، وأنظمة المحادثة conversational systems.
لبناء نموذج لمهمة منشئ العنوان أو منشئ النص، يجب تدريب النموذج على معرفة احتمالية حدوث كلمة، باستخدام الكلمات التي ظهرت بالفعل في التسلسل كسياق.
منشئ العنوان مع التعلم العميق
سأبدأ هذه المهمة لإنشاء مولد عنوان باستخدام بايثون والتعلم الآلي عن طريق استيراد المكتبات وقراءة مجموعات البيانات. يمكن تنزيل مجموعات البيانات التي أستخدمها في هذه المهمة من هنا:
import pandas as pd
import string
import numpy as np
import json
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding, LSTM, Dense, Dropout
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from keras.models import Sequential
import keras.utils as ku
import tensorflow as tf
tf.random.set_seed(2)
from numpy.random import seed
seed(1)
#load all the datasets
df1 = pd.read_csv('USvideos.csv')
df2 = pd.read_csv('CAvideos.csv')
df3 = pd.read_csv('GBvideos.csv')
#load the datasets containing the category names
data1 = json.load(open('US_category_id.json'))
data2 = json.load(open('CA_category_id.json'))
data3 = json.load(open('GB_category_id.json'))
نحتاج الآن إلى معالجة بياناتنا حتى نتمكن من استخدام هذه البيانات لتدريب نموذج التعلم الآلي الخاص بنا على مهمة منشئ العنوان. فيما يلي جميع خطوات تنظيف البيانات ومعالجتها التي نحتاج إلى اتباعها:
def category_extractor(data):
i_d = [data['items'][i]['id'] for i in range(len(data['items']))]
title = [data['items'][i]['snippet']["title"] for i in range(len(data['items']))]
i_d = list(map(int, i_d))
category = zip(i_d, title)
category = dict(category)
return category
#create a new category column by mapping the category names to their id
df1['category_title'] = df1['category_id'].map(category_extractor(data1))
df2['category_title'] = df2['category_id'].map(category_extractor(data2))
df3['category_title'] = df3['category_id'].map(category_extractor(data3))
#join the dataframes
df = pd.concat([df1, df2, df3], ignore_index=True)
#drop rows based on duplicate videos
df = df.drop_duplicates('video_id')
#collect only titles of entertainment videos
#feel free to use any category of video that you want
entertainment = df[df['category_title'] == 'Entertainment']['title']
entertainment = entertainment.tolist()
#remove punctuations and convert text to lowercase
def clean_text(text):
text = ''.join(e for e in text if e not in string.punctuation).lower()
text = text.encode('utf8').decode('ascii', 'ignore')
return text
corpus = [clean_text(e) for e in entertainment]
توليد التسلسلات
تتطلب مهام معالجة اللغة الطبيعية إدخال بيانات في شكل سلسلة من الرموز المميزة tokens. الخطوة الأولى بعد تنقية البيانات هي إنشاء سلسلة من الرموز المميزة n-gram.
n-gram هو تسلسل مجاور لعدد n من العناصر لعينة معينة من النص أو المجموعة الصوتية vocal corpus. يمكن أن تكون العناصر كلمات أو مقاطع لفظية أو مقاطع صوتية أو أحرف أو أزواج أساسية. في هذه الحالة، فإن n-grams هي سلسلة من الكلمات في مجموعة من العناوين. الترميز Tokenization هو عملية استخراج الرموز من المجموعة corpus:
tokenizer = Tokenizer()
def get_sequence_of_tokens(corpus):
#get tokens
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
#convert to sequence of tokens
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
return input_sequences, total_words
inp_sequences, total_words = get_sequence_of_tokens(corpus)
نظرًا لأن التسلسلات يمكن أن تكون ذات أطوال متغيرة، يجب أن تكون أطوال التسلسل متساوية. عند استخدام الشبكات العصبية، عادة ما نقوم بتغذية مدخلات في الشبكة أثناء انتظار الإخراج. من الناحية العملية، من الأفضل معالجة البيانات على دفعات بدلاً من معالجة البيانات دفعة واحدة.
يتم ذلك باستخدام المصفوفات [حجم الدُفعة × طول التسلسل]، حيث يتوافق طول التسلسل مع أطول تسلسل. في هذه الحالة، نقوم بملء التسلسلات برمز (عادة 0) ليناسب حجم المصفوفة. تسمى هذه العملية لملء التسلسلات بالرموز المميزة الملء filling. لإدخال البيانات في نموذج تدريب، أحتاج إلى إنشاء تنبؤات predictors وتسميات labels.
سأقوم بإنشاء متواليات من n-gram كمتنبئات والكلمة التالية من n-gram كتسمية:
def generate_padded_sequences(input_sequences):
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding=’pre’))
predictors, label = input_sequences[:,:-1], input_sequences[:, -1]
label = ku.to_categorical(label, num_classes = total_words)
return predictors, label, max_sequence_len
predictors, label, max_sequence_len = generate_padded_sequences(inp_sequences)
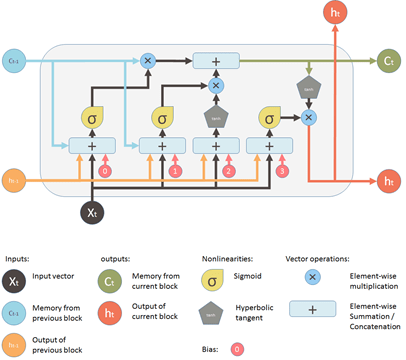
في الشبكات العصبية المتكررة recurrent neural networks(RNN)، يتم نشر مخرجات التنشيط في كلا الاتجاهين، أي من المدخلات إلى المخرجات والمخرجات إلى المدخلات، على عكس الشبكات العصبية ذات التمثيل المباشر حيث تنتشر المخرجات d التنشيط في اتجاه واحد فقط. يؤدي هذا إلى إنشاء حلقات في بُنية الشبكة العصبية التي تعمل بمثابة “حالة ذاكرة memory state” للخلايا العصبية.
نتيجة لذلك، تحتفظ RNN بحالة من خلال مراحل الوقت أو “تتذكر remembers” ما تم تعلمه بمرور الوقت. لحالة الذاكرة مزاياها، ولكن لها أيضًا عيوبها. التدرج gradient الذي يختفي هو واحد منهم.
في هذه المشكلة، أثناء التعلم باستخدام عدد كبير من الطبقات، يصبح من الصعب حقًا على الشبكة تعلم وضبط معلمات الطبقات السابقة. لحل هذه المشكلة، تم تطوير نوع جديد من RNN؛ LSTM (ذاكرة طويلة قصيرة المدى Long Short Term Memory).
مولد العنوان مع نموذج LSTM
يحتوي نموذج LSTM على حالة إضافية (حالة الخلية) والتي تسمح أساسًا للشبكة بمعرفة ما يتم تخزينه في الحالة طويلة المدى، وما يجب حذفه وما يجب قراءته. يحتوي LSTM لهذا النموذج على أربع طبقات:
- طبقة الإدخال Input layer: تأخذ تسلسل الكلمات كمدخل.
- طبقة LSTM: تحسب الناتج باستخدام وحدات LSTM.
- طبقة التسرب Dropout layer: طبقة تنظيم لتجنب فرط التعلم overfitting.
- طبقة الإخراج Output layer: تحسب احتمالية الكلمة التالية المحتملة عند الإخراج.
سأستخدم الآن نموذج LSTM لبناء نموذج لمهمة منشئ العنوان Title Generator مع التعلم العميق:
def create_model(max_sequence_len, total_words):
input_len = max_sequence_len — 1
model = Sequential()
# Add Input Embedding Layer
model.add(Embedding(total_words, 10, input_length=input_len))
# Add Hidden Layer 1 — LSTM Layer
model.add(LSTM(100))
model.add(Dropout(0.1))
# Add Output Layer
model.add(Dense(total_words, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’)
return model
model = create_model(max_sequence_len, total_words)
model.fit(predictors, label, epochs=20, verbose=5)
مولد العنوان مع التعلم الآلي: اختبار النموذج
الآن وقد أصبح نموذج التعلم الآلي الخاص بنا لمنشئ العنوان جاهزًا وتم تدريبه باستخدام البيانات، فقد حان الوقت للتنبؤ بالعنوان بناءً على كلمة الإدخال. يتم ترميز كلمة الإدخال أولاً، ثم يكتمل التسلسل قبل أن يتم تمريرها إلى النموذج المدرب لإرجاع التسلسل المتوقع:
def generate_text(seed_text, next_words, model, max_sequence_len):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding=’pre’)
predicted = model.predict_classes(token_list, verbose=0)
output_word = “”
for word,index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += “ “+output_word
return seed_text.title()
توليد العناوين
الآن بما أننا أنشأنا دالة لإنشاء العناوين، فلنختبر نموذج منشئ العنوان الخاص بنا:
print(generate_text(“spiderman”, 5, model, max_sequence_len))
Output: Spiderman The Voice 2018 Blind Audition
أتمنى أن تكون قد أحببت هذه المقالة حول كيفية إنشاء نموذج منشئ العنوان باستخدام التعلم العميق ولغة برمجة بايثون.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.