- ما هو تحليل المشاعر؟
- مشروع التعلم الآلي حول تحليل المشاعر باستخدام بايثون
- تصوير الكلمات السلبية والإيجابية
- تدريب نموذج التعلم الآلي لتحليل المشاعر
في التعلم الآلي Machine Learning، يشير تحليل المشاعر Sentiment analysis إلى تطبيق معالجة اللغة الطبيعية natural language processing واللغويات الحاسوبية computational linguistics وتحليل النص text analysis لتحديد وتصنيف الآراء الشخصية في المستندات المصدر. في هذه المقالة، سأقدم لك مشروع التعلم الآلي حول تحليل المشاعر باستخدام لغة برمجة بايثون.
ما هو تحليل المشاعر؟
يهدف تحليل المشاعر إلى تحديد موقف الكاتب تجاه موضوع أو القطبية السياقية العامة للمستند. يمكن أن يكون الموقف هو حكمه أو تقييمه أو حالته العاطفية أو التواصل العاطفي المقصود.
في تحليل المشاعر، تتمثل المهمة الرئيسية في تحديد كلمات الرأي opinion words، وهو أمر مهم للغاية. كلمات الرأي هي مؤشرات سائدة على المشاعر، وخاصة الصفات والظروف والأفعال، على سبيل المثال: ” I love this camera. It’s amazing!”
تُعرف كلمات الرأي أيضًا باسم كلمات القطبية polarity words، أو كلمات المشاعر، أو معجم الرأي sentiment words، أو كلمات الرأي opinion words، والتي يمكن عمومًا تقسيمها إلى نوعين: الكلمات الإيجابية positive words، على سبيل المثال، رائع wonderful، أنيق elegant، مذهل astonishing. والكلمات السلبية negative words، على سبيل المثال فظيع horrible، مقرف disgusting، فقير poor.
مشروع التعلم الآلي حول تحليل المشاعر باستخدام بايثون
الآن في هذا القسم، سوف آخذك خلال مشروع التعلم الآلي حول تحليل المشاعر باستخدام لغة برمجة بايثون. لنبدأ باستيراد جميع مكتبات بايثون ومجموعة البيانات dataset الضرورية:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer
count=CountVectorizer()
data=pd.read_csv("Train.csv")
data.head()
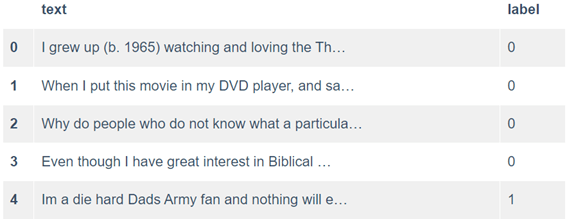
بعد قراءة مجموعة البيانات التي تحتوي على 40 ألفًا من تقييمات الأفلام من IMDB، نرى أن هناك عمودين بارزين. أحدهما هو TEXT الذي يحتوي على النقد والآخر هو LABEL الذي يحتوي على O و 1، حيث 0-سلبي و 1-إيجابي.
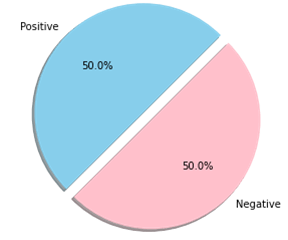
الآن دعنا نرسم توزيع البيانات:
fig=plt.figure(figsize=(5,5))
colors=["skyblue",'pink']
pos=data[data['label']==1]
neg=data[data['label']==0]
ck=[pos['label'].count(),neg['label'].count()]
legpie=plt.pie(ck,labels=["Positive","Negative"],
autopct ='%1.1f%%',
shadow = True,
colors = colors,
startangle = 45,
explode=(0, 0.1))
ثم سنقوم باستيراد RE، أي عملية التعبير العادي regular expression، نستخدم هذه المكتبة لإزالة علامات html مثل “<a>” أو. لذلك كلما صادفنا هذه العلامات، فإننا نستبدلها بسلسلة فارغة. ثم سنقوم أيضًا بتعديل الرموز التعبيرية التي يمكن أن تكون وجوهًا ضاحكة :)، وجه حزين: (أو حتى وجه مستاء: /. سنقوم بتغيير الرموز التعبيرية في النهاية للحصول على مجموعة نصية نظيفة:
import re
def preprocessor(text):
text=re.sub('<[^>]*>','',text)
emojis=re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)',text)
text=re.sub('[\W]+',' ',text.lower()) +\
' '.join(emojis).replace('-','')
return text
data['text']=data['text'].apply(preprocessor)
الآن، سأستخدم PorterStemmer من nltk لتبسيط البيانات وإزالة التعقيدات غير الضرورية في بياناتنا النصية:
from nltk.stem.porter import PorterStemmer
porter=PorterStemmer()
def tokenizer(text):
return text.split()
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
تصوير الكلمات السلبية والإيجابية
لتصوير الكلمات السلبية والإيجابية باستخدام سحابة الكلمات wordcloud، سأقوم أولاً بإزالة كلمات التوقف stopwords:
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop=stopwords.words('english')
from wordcloud import WordCloud
positivedata = data[ data['label'] == 1]
positivedata =positivedata['text']
negdata = data[data['label'] == 0]
negdata= negdata['text']
def wordcloud_draw(data, color = 'white'):
words = ' '.join(data)
cleaned_word = " ".join([word for word in words.split()
if(word!='movie' and word!='film')
])
wordcloud = WordCloud(stopwords=stop,
background_color=color,
width=2500,
height=2000
).generate(cleaned_word)
plt.figure(1,figsize=(10, 7))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
print("Positive words are as follows")
wordcloud_draw(positivedata,'white')
print("Negative words are as follows")
wordcloud_draw(negdata)
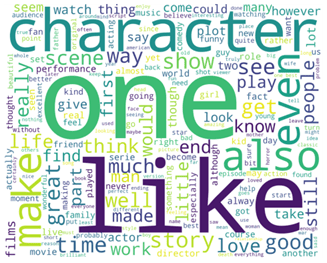
الكلمات الإيجابية التي يتم إبرازها هي love، excellent، perfect، good، beautiful، kind، والكلمات السلبية التي يتم إبرازها هي: horrible، wasteful، problem، stupid، horrible، bad، poor.
سأستخدم الآن TF-IDF Vertorizer لتحويل المستندات الأولية إلى مصفوفة ميزات feature matrix وهو أمر مهم جدًا لتدريب نموذج التعلم الآلي:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf=TfidfVectorizer(strip_accents=None,lowercase=False,preprocessor=None,tokenizer=tokenizer_porter,use_idf=True,norm='l2',smooth_idf=True)
y=data.label.values
x=tfidf.fit_transform(data.text)
تدريب نموذج التعلم الآلي لتحليل المشاعر
الآن لتدريب نموذج التعلم الآلي، سأقسم البيانات إلى مجموعات تدريب بنسبة 50 بالمائة واختبار بنسبة 50 بالمائة:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,random_state=1,test_size=0.5,shuffle=False)
دعنا الآن ندرب نموذج التعلم الآلي لمهمة تحليل المشاعر باستخدام نموذج الانحدار اللوجستي Logistic Regression:
from sklearn.linear_model import LogisticRegressionCV
clf=LogisticRegressionCV(cv=6,scoring='accuracy',random_state=0,n_jobs=-1,verbose=3,max_iter=500).fit(X_train,y_train)
y_pred = clf.predict(X_test)
from sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))

أتمنى أن تكون قد أحببت هذه المقالة حول تحليل المشاعر باستخدام لغة برمجة بايثون.