

- مقدمة
- ما هو نقل التعلم؟
- وصف البيانات
- تنفيذ الكود
- الخاتمة
مقدمة
أصبح تصنيف الوجبات السريعة Fast food classification وظيفة مهمة في نظام توصيل الطعام الآلي. أصبح التعلم الآلي Machine learning شائعًا مع نمو سلاسل الوجبات السريعة والحاجة إلى أنظمة التعرف على الأطعمة الدقيقة والفعالة. في هذه المدونة، سوف نستكشف استخدام نقل التعلم transfer learning لتصنيف الوجبات السريعة باستخدام PyTorch. نقل التعلم هو أسلوب يستفيد من النماذج المدربة مسبقًا pre-trained models لحل المهام الجديدة ببيانات محدودة.
سنناقش كيفية ضبط بشكل دقيق fine-tune نموذج مدرب مسبقًا لتصنيف الوجبات السريعة والنتائج التي تم الحصول عليها من هذا النهج.
اهداف التعلم
- التعرف على PyTorch للتعلم العميق.
- كيفية استخدام نقل التعلم في PyTorch؟
- زيادة البيانات Data Augmentation.
- تصوير النموذج Visualise the Model.
جدول المحتويات
- ما هو نقل التعلم؟
- وصف البيانات.
- تنفيذ الكود.
ما هو نقل التعلم؟
نقل التعلم Transfer learning هو أسلوب يستخدم الأوزان المدربة مسبقًا pre-trained weights لنموذج التعلم العميق لأداء مهمة جديدة ببيانات محدودة. في سياق ResNet18 (الذي سأستخدمه في هذا المشروع)، سيشمل نقل التعلم أخذ نموذج ResNet18 مدرب مسبقًا وضبط أوزانه لمهمة تصنيف وجبات سريعة محددة. يهدف هذا النهج إلى الاستفادة من المعرفة المكتسبة من خلال النموذج المدرب مسبقًا على مجموعة بيانات كبيرة لحل المهمة الجديدة باستخدام بيانات وموارد حسابية أقل. عادةً ما تتضمن عملية الضبط الدقيق fine-tuning إعادة تدريب الطبقات النهائية لنموذج ResNet18 لتكييفها مع المهمة الجديدة. يوجد أدناه مخطط نموذج resnet18.
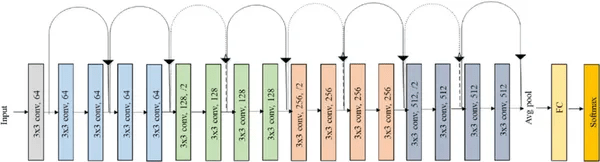
يمكنك أن ترى أن النموذج يتكون من 17 طبقة من الطبقة التلافيفية Convolutional layer مع فلتر (3×3) وطبقة واحدة من الطبقة المتصلة بالكامل Fully connected layer. الأخير هو دالة Softmax لفئات متعددة من تصنيف الصور.
وصف البيانات
البيانات مستضافة في Kaggle هنا.
هناك 10 فئات من صور الوجبات السريعة.
- برجر Burger.
- دونات Donut.
- نقانق Hot Dog.
- بيتزا Pizza.
- ساندويتش Sandwich.
- بطاطس مشوية Baked Potato.
- دجاج مقرمش Crispy Chicken.
- بطاطس مقلية Fries.
- تاكو Taco.
- تاكيتو Taquito.
تنفيذ الكود
الخطوة 1: استيراد جميع المكتبات الضرورية.
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
الخطوة 2: ضبط PATH على مجموعة البيانات والجهاز.
PATH = "../data/Fast Food Classification V2/"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# make sure my GPU is detected.
print(device)
الخطوة 3: زيادة البيانات وتطبيعها.
تعد زيادة البيانات Data augmentation تقنية حاسمة تُستخدم في التعلم العميق لزيادة حجم مجموعة بيانات التدريب ومنع الضبط الزائد overfitting. يمكن أن يساعد في تحسين أداء وقوة نماذج التعلم العميق، خاصة في السيناريوهات ذات البيانات المحدودة.
data_transforms = {
'Train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'Valid': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
الخطوة 4: تحميل مجموعة البيانات وإنشاء كائن Dataloader.
image_datasets = {
x: datasets.ImageFolder(os.path.join(PATH, x),
data_transforms[x]) for x in ['Train', 'Valid']
}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=32,
shuffle=True,
) for x in ['Train', 'Valid']
}
dataset_sizes = {x: len(image_datasets[x]) for x in ['Train', 'Valid']}
class_names = image_datasets['Train'].classes
print(classes)
>>>
['Baked Potato',
'Burger',
'Crispy Chicken',
'Donut',
'Fries',
'Hot Dog',
'Pizza',
'Sandwich',
'Taco',
'Taquito']
دعونا نرى بعض بيانات التدريب.
# create a function image show
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# Get a batch of training data
inputs, classes = next(iter(dataloaders['Train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out)

الخطوة 5: إنشاء دالة التدريب.
تأخذ الدالة المدخلات التالية:
- Model: نموذج التعلم العميق الذي سيتم تدريبه.
- : معيار دالة الخطأ المستخدم لتقييم أداء النموذج.
- Optimizer: تقوم خوارزمية التحسين بتحديث معلمات النموذج أثناء التدريب.
- Scheduler: يتم استخدام جدولة معدل التعلم learning rate لضبط معدل التعلم أثناء التدريب.
- num_epochs:عدد فترات التدريب (الافتراضي = 25).
تقوم الدالة بتدريب النموذج على عدد من الفترات num_epochs، بالتناوب بين مرحلتي التدريب training والتحقق من الصحة validation. في كل فترة، يتم تحديث معلمات النموذج باستخدام المُحسِّن Optimizer والمعيار Criterion لحساب الخطأ. أثناء مرحلة التدريب، يتم حساب التدرجات gradients باستخدام backward()، ويتم تحديث المعلمات parameters باستخدام optimizer.step(). يتم تقييم أداء النموذج في مرحلة التحقق من الصحة دون تحديث المعلمات.
بعد كل فترة، تتم طباعة مقاييس الأداء (الخطأ loss والدقة accuracy). يتم حفظ أفضل أوزان النموذج (بأعلى دقة في التحقق من الصحة) باستخدام copy.deepcopy(). في نهاية التدريب، تتم طباعة الوقت المنقضي وأفضل دقة تحقق من الصحة، ويتم تحميل أفضل أوزان للنموذج باستخدام النموذج model.load_state_dict(). أخيرًا، يتم إرجاع النموذج المدرب.
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['Train', 'Valid']:
if phase == 'Train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'Train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'Train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'Train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'Valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best Valid Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(best_model_wts)
return model
الخطوة 6: ابدأ تدريب النموذج باستخدام أوزان Resnet18.
model_1 = models.resnet18(pretrained=True)
num_ftrs = model_1.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_1.fc = nn.Linear(num_ftrs, len(class_names))
model_1 = model_1.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_sgd = optim.SGD(model_1.parameters(), lr=0.001, momentum=0.9)
optimizer_adam = optim.Adam(model_1.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_adam, step_size=7, gamma=0.1)
model_resnetft = train_model(model_1, criterion, optimizer_adam, exp_lr_scheduler,
num_epochs=15)
output >>>
Epoch 0/14
----------
Train Loss: 1.3397 Acc: 0.5660
Valid Loss: 1.0503 Acc: 0.6691
.
.
.
continues
.
.
.
Epoch 14/14
----------
Train Loss: 0.4054 Acc: 0.8709
Valid Loss: 0.4723 Acc: 0.8600
Training complete in 27m 23s
Best Valid Acc: 0.867714
لذلك، يمكنك أن ترى أن إكمال التدريب يستغرق ما يقرب من 28 دقيقة في GPU في Nvidia Tesla P100. ونسبة دقة التحقق الأفضل هي 86.77٪.
الخطوة 7: انظر الآن بعض النتائج
يقوم الكود أولاً بتعيين النموذج إلى وضع التقييم (model.eval())ويقوم بتهيئة عداد images_so_far لتتبع عدد الصور المرئية حتى الآن. يتم إنشاء الشكل أيضًا باستخدام plt.figure() .
تقوم الدالة بعد ذلك بالتكرار على بيانات التحقق باستخدام التعداد (dataloaders[‘Valid’]). لكل تكرار، يتم نقل صور الإدخال والتسميات إلى الجهاز المحدد (باستخدام inputs.to(device) و labels.to(device))، ويتم حساب تنبؤات النموذج باستخدام model(inputs). يتم الحصول على الفئة المتوقعة لكل صورة باستخدام preds = torch.max(outputs, 1).
لكل صورة إدخال، يرسم الكود الصورة باستخدام imshow(inputs.cpu().data[j]) ويضع العنوان للفئة المتوقعة. يتتبع الكود عدد الصور المرئية حتى الآن باستخدام عداد images_so_far ، وإذا كان عدد الصور المرئية يساوي الرقم المحدد ، فستعود الدالة.
أخيرًا، يعيد الكود النموذج إلى وضع التدريب الأصلي الخاص به model.train(mode=was_training).
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['Valid']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
# Visualize model
visualize_model(model_1)





الخاتمة
لقد أوضحت هذه المقالة استخدام نقل التعلم لإجراء تصنيف للوجبات السريعة باستخدام بُنية ResNet18 و PyTorch. أظهر التنفيذ كيفية الضبط الدقيق لنموذج مدرب مسبقًا على مجموعة بيانات الطعام وتقييم أداء النموذج في مجموعة التحقق من الصحة. أظهرت النتائج أن نقل التعلم يمكن أن يستفيد بشكل فعال من المعرفة المكتسبة من مجموعة البيانات واسعة النطاق لتحسين أداء مهمة تصنيف الأغذية. بشكل عام، يعد نقل التعلم أداة قوية لحل مشاكل الرؤية الحاسوبية ولديه القدرة على إحداث ثورة في هذا المجال. فيما يلي بعض التعلم الأساسي من هذا المشروع:
- ResNet18 هي بُنية تعليمية عميقة شائعة تستخدم في مهام الرؤية الحاسوبية، ويمكن استخدامها كمستخرج ميزة feature extractor في نقل التعلم.
- نقل التعلم هو أسلوب في التعلم العميق حيث يتم ضبط نموذج مدرب مسبقًا لمهمة محددة.
- أظهر تنفيذ الكود كيفية ضبط نموذج ResNet18 المدربين مسبقًا على مجموعة بيانات الطعام وتقييم أداء النموذج على مجموعة التحقق من الصحة.
- أدت تقنيات زيادة البيانات إلى زيادة حجم مجموعة بيانات التدريب وتحسين أداء النموذج.
- أظهرت النتائج أن نقل التعلم باستخدام ResNet18 و PyTorch يمكن أن يصنف بشكل فعال صور الوجبات السريعة ويحقق دقة عالية.
- يعد نقل التعلم أداة قوية لحل مشاكل الرؤية الحاسوبية ولديه القدرة على إحداث ثورة في هذا المجال.
آمل أن تساعدك هذه المقالة في مهمتك التعليمية. إذا كان لديك أي أسئلة، قم بالتعليق أدناه. الكود بأكملها موجودة في نوتبوك Kaggle الخاص بي.



