- عملية المعالجة اللغوية العصبية
- عملية البرمجة اللغوية العصبية باستخدام بايثون
- الخطوة 1: البحث عن مجموعة بيانات
- الخطوة 2: إعداد البيانات، والترميز ، وإزالة كلمات الإيقاف ، وتجذيعها
- الخطوة 3: توجيه النص
- الخطوة 4: تصنيف النص
- الملخص
المعالجة اللغوية الطبيعية (NLP) هي مجموعة فرعية من الذكاء الاصطناعي حيث نهدف إلى تدريب أجهزة الكمبيوتر على فهم اللغات البشرية. بعض تطبيقات العالم الحقيقي من المعالجة اللغوية الطبيعية هي chatbots و Siri و Google Translator. أثناء العمل على أي مشكلة تعتمد على المعالجة اللغوية الطبيعية، يجب أن نتبع عملية لإعداد مفردات الكلمات من مجموعة بيانات نصية. لذا، إذا كنت تريد فهم عملية حل أي مشكلة بناءً على المعالجة اللغوية الطبيعية، فهذه المقالة مناسبة لك. في هذه المقالة، سوف آخذك خلال العملية الكاملة لـ NLP باستخدام بايثون.
عملية المعالجة اللغوية الطبيعية
لشرح عملية المعالجة اللغوية الطبيعية (NLP)، سآخذك خلال مهمة تصنيف المشاعر sentiment classification باستخدام بايثون. خطوات حل مشكلة البرمجة اللغوية الطبيعية هذه هي:
- البحث عن مجموعة بيانات لتصنيف المشاعر.
- تحضير مجموعة البيانات عن طريق الترميز tokenization وإزالة كلمات التوقف stopwords removal والتجذيع stemming.
- توجيه النص Text vectorization.
- تدريب نموذج تصنيف لتصنيف المشاعر.
عملية البرمجة اللغوية الطبيعية باستخدام بايثون
الخطوة 1: البحث عن مجموعة بيانات
الخطوة الأولى أثناء العمل على أي مشكلة في المعالجة اللغوية الطبيعية هي العثور على مجموعة بيانات نصية. في هذه المشكلة، نحتاج إلى العثور على مجموعة بيانات تحتوي على نص حول مشاعر الأشخاص تجاه منتج أو خدمة. إذا كانت مجموعة البيانات التي عثرت عليها مصنفة (labelled)، فهي مثالية! إذا وجدت مجموعة بيانات نصية غير مصنفة (unlabelled)، يمكنك التعرف على كيفية إضافة تسميات إلى مجموعة بيانات لتصنيف المشاعر من هنا.
لقد وجدت مجموعة بيانات مثالية بناءً على مراجعات الأفلام لمهمة تصنيف المشاعر على Kaggle. يمكنك تنزيل مجموعة البيانات من هنا.
نظرًا لأننا وجدنا مجموعة بيانات لتصنيف المشاعر، فلننتقل إلى أبعد من ذلك عن طريق استيراد مكتبات بايثون ومجموعة البيانات اللازمة:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import BernoulliNB
import nltk
nltk.download('stopwords')
data = pd.read_csv("IMDB Dataset.csv")
print(data.head())

الخطوة 2: إعداد البيانات، والترميز ، وإزالة كلمات الإيقاف ، وتجذيعها
تحتاج مجموعة البيانات النصية الخاصة بنا إلى التحضير قبل استخدامها لأي مشكلة تعتمد على المعالجة اللغوية الطبيعية. هنا سوف:
- إزالة الروابط وجميع الرموز الخاصة من عمود المراجعة (review column).
- قم بترميز وإزالة كلمات الإيقاف من عمود المراجعة.
- جذع الكلمات في عمود المراجعة.
import nltk
import re
nltk.download('stopwords')
stemmer = nltk.SnowballStemmer("english")
from nltk.corpus import stopwords
import string
stopword=set(stopwords.words('english'))
def clean(text):
text = str(text).lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('https?://\S+|www\.\S+', '', text)
text = re.sub('<.*?>+', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\n', '', text)
text = re.sub('\w*\d\w*', '', text)
text = [word for word in text.split(' ') if word not in stopword]
text=" ".join(text)
text = [stemmer.stem(word) for word in text.split(' ')]
text=" ".join(text)
return text
data["review"] = data["review"].apply(clean)
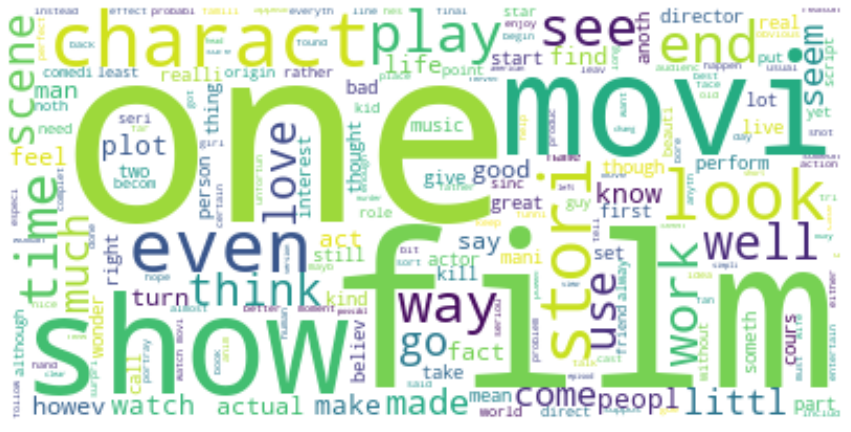
قبل المضي قدمًا، دعنا نلقي نظرة سريعة على سحابة الكلمات (wordcloud) في عمود المراجعة:
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
text = " ".join(i for i in data.review)
stopwords = set(STOPWORDS)
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
plt.figure( figsize=(15,10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
الخطوة 3: توجيه النص
الخطوة التالية هي توجيه النص (Text Vectorization). يعني تحويل جميع الرموز المميزة (tokens) للنص إلى متجهات رقمية. سأقوم هنا أولاً بإجراء توجيه النص على عمود الميزة (عمود المراجعة) ثم أقسم البيانات إلى مجموعات تدريب واختبار:
x = np.array(data["review"])
y = np.array(data["sentiment"])
cv = CountVectorizer()
X = cv.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.20,
random_state=42(
الخطوة 4: تصنيف النص
الخطوة الأخيرة في عملية المعالجة اللغوية الطبيعية هي تصنيف النصوص أو تجميعها. بينما نعمل على حل مشكلة تصنيف المشاعر، سنقوم الآن بتدريب نموذج تصنيف النص. فيما يلي كيفية إعداد نموذج تصنيف النص لتصنيف المشاعر:
from sklearn.linear_model import PassiveAggressiveClassifier
model = PassiveAggressiveClassifier()
model.fit(X_train,y_train)
تحتوي مجموعة البيانات التي استخدمناها لتدريب نموذج تصنيف المشاعر على مراجعات للأفلام. لذلك دعونا نختبر النموذج من خلال تقديم مراجعة الفيلم كمدخل:
user = input("Enter a Text: ")
data = cv.transform([user]).toarray()
output = model.predict(data)
print(output)

الملخص
أثناء العمل على أي مشكلة في المعالجة اللغوية الطبيعية ، نحتاج أولاً إلى:
- ابحث عن مجموعة بيانات نصية textual dataset.
- ثم قم بإعداد مجموعة البيانات عن طريق الترميز tokenization وإزالة كلمات التوقف stopwords removal والتجذيع stemming.
- ثم تنفيذ توجيه النص text vectorization.
- ثم الخطوة الأخيرة هي تصنيف النص text classification أو التجميع clustering.
آمل أن تكون قد أحببت هذه المقالة حول العملية الكاملة لـ NLP باستخدام بايثون.