
- ما هي القيم المتطرفة في التعلم الآلي؟
- لماذا نحتاج إلى إزالة القيم المتطرفة؟
- كيفية إزالة القيم المتطرفة في التعلم الآلي؟
في عملية بناء نموذج التعلم الآلي machine learning بعد التعامل مع القيم الفارغة null values وتحويل الفئات categories إلى أرقام وإعدادها لنماذجنا، فإن الخطوة التالية هي تحويل البيانات لاكتشاف القيم المتطرفة outliers detection والنماذج التي تتطلب ميزات موزعة بشكل طبيعي. في هذه المقالة، سوف أطلعك على كيفية إزالة القيم المتطرفة في التعلم الآلي باستخدام بايثون.
ما هي القيم المتطرفة في التعلم الآلي؟
القيم المتطرفة هي ملاحظات شاذة تختلف عن المجموعات الأخرى. يمكن أن يكون لها آثار سلبية على إدراكنا للبيانات وبناء نموذجنا. يمكن أن يكون لدينا قيم متطرفة بسبب إدخال البيانات أو الخطأ البشري، أو أدوات القياس التالفة أو غير المؤهلة، أو التلاعب بالبيانات، أو dummies لاختبار طرق الكشف أو لإضافة الضوضاء، وأخيراً الأخبار في البيانات.
حتى عند إنشاء أرقام عشوائية من التوزيع، ستكون هناك قيم نادرة تنحرف عن متوسط جميع الأمثلة الأخرى. هذه القيم هي القيم التي نريد التخلص منها لتدريب نموذج التعلم الآلي بشكل صحيح.
هناك نوعان من القيم المتطرفة في التعلم الآلي:
- القيم المتطرفة أحادية المتغير Univariate Outliers: عندما ننظر إلى القيم في فضاء ميزة واحدة (على سبيل المثال، النظر فقط في توزيع عمود سعر البيع).
- القيم المتطرفة متعددة المتغيرات Multivariate outliers: عندما ننظر إلى فضاء ذي أبعاد n، يمثل كل بُعد كيانًا. في هذه الحالة، نظرًا لوجود عدد كبير جدًا من الميزات التي يجب وضعها في الاعتبار، لا يمكننا فقط رسم البيانات واكتشاف مدى بُعد المجموعات عن المجموعات العادية، لذلك نستخدم النماذج لإجراء هذا الاكتشاف نيابةً عنا.
لماذا نحتاج إلى إزالة القيم المتطرفة؟
هناك العديد من الأسباب التي تجعل شخصًا ما قد يفكر في إزالة بعض الأمثلة من مجموعة البيانات الخاصة به، حتى عندما تكون مجموعة البيانات صغيرة ونحتاج إلى جميع المعلومات التي يمكننا الحصول عليها. نحتاج إلى إزالة القيم المتطرفة لأنها يمكن أن تكون مدمرة لنموذج التعلم الآلي الخاص بنا وتصور الواقع.
نريد أن يتنبأ نموذجنا بالتسمية الأكثر احتمالية وألا يتأثر بقيمة عشوائية في مجموعة البيانات الخاصة بنا. أفضل طريقة هي إزالة أقل قدر ممكن ولكن جعل النماذج قوية بحيث يمكنها تجاهل أو محاكاة تأثيرها على التنبؤ بنموذج التعلم الآلي.
كيفية إزالة القيم المتطرفة في التعلم الآلي؟
لإزالة القيم المتطرفة نحتاج إلى اكتشافها. أفضل طريقة لاكتشاف القيم المتطرفة هي الطريقة اليدوية manual method. تحتاج إلى استعراض جميع المعلومات ومعرفة اتجاهات البيانات. أي نقطة تكون بعيدة جدًا عن بقية البيانات هي إشارة إلى حالة متطرفة.
ومع ذلك، إذا كنت تريد معرفة كيفية اكتشاف القيم المتطرفة باستخدام لغة برمجة بايثون، فيمكنك إلقاء نظرة على هذا البرنامج التعليمي. دعنا الآن نرى كيفية إزالة القيم المتطرفة في التعلم الآلي. سأقوم أولاً باستيراد مجموعة البيانات وإجراء بعض معالجة البيانات لفهم البيانات ولإعداد البيانات حتى أتمكن من إزالة القيم المتطرفة:
import numpy as np
import pandas as pd
# for vis
import matplotlib.pyplot as plt
import plotly.express as px
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import seaborn as sns
sns.set_style("whitegrid")
from sklearn.preprocessing import LabelEncoder, OrdinalEncoder
# anomaly and skewness detection
from scipy import stats
from scipy.stats import skew, norm
from scipy.special import boxcox1p
from numpy import mean, std
from IPython.display import HTML
from matplotlib import animation
from termcolor import colored
# Importing and concating train and test set
train = pd.read_csv('train.csv', )
test = pd.read_csv('test.csv')
train.name = 'train'
test.name = 'test'
# keeping testing id for submission in the future
test_id = test.Id
for df in [train, test]:
df.drop(columns = ['Id'], inplace = True)
df_concat = pd.concat([train, test], axis = 0).reset_index(drop = True)
df_concat.name = 'both dfs'
df_concat.loc[:train.shape[0], 'which'] = 'train'
df_concat.loc[train.shape[0]:, 'which'] = 'test'
# Dropping two unuseful columns
df_concat.drop(columns = ['PoolQC', 'Utilities'], inplace = True)
# Filling missing values
# Filling with zero
# fields about the Garage
for field in ['GarageType', 'GarageFinish','GarageQual', 'GarageCond',
'BsmtFinType1','BsmtQual','BsmtCond', 'BsmtExposure', 'BsmtFinType1',
'BsmtFinType2','MiscFeature','Alley','Fence','FireplaceQu',
'MasVnrType' ] :
df_concat[field].fillna('None',inplace=True)
for field in ['MasVnrArea','BsmtFullBath','BsmtHalfBath'
,'BsmtFinSF1','GarageCars','GarageArea','TotalBsmtSF',
'BsmtUnfSF','BsmtFinSF2','GarageYrBlt','TotalBsmtSF']:
df_concat[field].fillna(0,inplace=True)
# Filling with appropriate values
df_concat['LotFrontage'] = df_concat.groupby('Neighborhood')['LotFrontage']\
.transform(lambda x: x.fillna(x.mean()))
for feature in ['MSZoning', 'Electrical']:
df_concat[feature] = df_concat.groupby('Neighborhood')[feature]\
.transform(lambda x: x.fillna(x.mode()[0]))
for field in ['SaleType','Exterior1st','Exterior2nd',]:
df_concat[field].fillna(df_concat[field].mode()[0],inplace=True)
df_concat.Functional.fillna('Typ',inplace=True)
df_concat.KitchenQual.fillna('TA',inplace=True)
# Converting categorical data into numerical
### ordinal
ordinal_fields_with_labelencoder=['LandSlope','YearBuilt','YearRemodAdd',
'CentralAir','GarageYrBlt','PavedDrive',
'YrSold']
### ordinal with labelencoder...
for field in ordinal_fields_with_labelencoder:
le = LabelEncoder()
df_concat[field] = le.fit_transform(df_concat[field].values)
features_that_are_already_ordinal = ['OverallQual','OverallCond','MoSold',
'FullBath','KitchenAbvGr','TotRmsAbvGrd']
### ordinal features that need to be sorted with ordinal encoder...
fields_that_need_to_be_ordered = [
'MSSubClass','ExterQual','LotShape','BsmtQual','BsmtCond',
'BsmtExposure','BsmtFinType1', 'BsmtFinType2','HeatingQC',
'Functional','FireplaceQu','KitchenQual', 'GarageFinish',
'GarageQual','GarageCond','Fence'
]
for field in fields_that_need_to_be_ordered:
df_concat[field] = df_concat[field].astype(str)
orders=[#msclass
['20','30','40','45','50','60','70','75','80','85', '90','120','150','160','180','190'],
#ExterQual
['Po','Fa','TA','Gd','Ex'],
#LotShape
['Reg','IR1' ,'IR2','IR3'],
#BsmtQual
['None','Fa','TA','Gd','Ex'],
#BsmtCond
['None','Po','Fa','TA','Gd','Ex'],
#BsmtExposure
['None','No','Mn','Av','Gd'],
#BsmtFinType1
['None','Unf','LwQ', 'Rec','BLQ','ALQ' , 'GLQ' ],
#BsmtFinType2
['None','Unf','LwQ', 'Rec','BLQ','ALQ' , 'GLQ' ],
#HeatingQC
['Po','Fa','TA','Gd','Ex'],
#Functional
['Sev','Maj2','Maj1','Mod','Min2','Min1','Typ'],
#FireplaceQu
['None','Po','Fa','TA','Gd','Ex'],
#KitchenQual
['Fa','TA','Gd','Ex'],
#GarageFinish
['None','Unf','RFn','Fin'],
#GarageQual
['None','Po','Fa','TA','Gd','Ex'],
#GarageCond
['None','Po','Fa','TA','Gd','Ex'],
#PoolQC
#['None','Fa','Gd','Ex'],
#Fence
['None','MnWw','GdWo','MnPrv','GdPrv'] ]
### ordinal features with specific order.....
for i in range(len(orders)):
ord_en = OrdinalEncoder(categories = {0:orders[i]})
df_concat.loc[:,fields_that_need_to_be_ordered[i]] = ord_en.fit_transform(df_concat.loc[:,fields_that_need_to_be_ordered[i]].values.reshape(-1,1))
# Finally one hot encoding categorical data that are not ordinal
df_concat=pd.get_dummies(df_concat.drop(columns = ['which']))
train = df_concat[:train.shape[0]]
test = df_concat[train.shape[0]:].drop(columns = ['SalePrice'])
def finding_over_fitting_features(df, percentage = 99.9):
overfit=[]
for feature in df.columns:
most_frequent=(df[feature] .value_counts().iloc[0])
if most_frequent/len(df) *100 >99.9:
overfit.append(feature)
return(overfit)
overfitted = finding_over_fitting_features(df_concat, percentage = 99.0)
df_concat.drop(columns = overfitted, inplace = True)
df = pd.read_csv('mood_swings/mood swings.csv', sep = ' ')
الآن دعنا نرى كيفية إزالة القيم المتطرفة:
fig, axes = plt.subplots(1, 2, figsize=(20,8),)
fig.suptitle('Before and After Manually removing outliers')
axes[0].set_title('Before')
axes[1].set_title('After')
g = sns.regplot(x=train['GrLivArea'], y=train['SalePrice'], ax = axes[0])
g.text(4500, 400000, "Outliers", horizontalalignment='left', size='large', color='black', weight='semibold')
g.axvline(4000, ls='--', color = 'red')
idx_manual = np.where(train['GrLivArea']>4000)[0]
train_NoOutlier = train.drop(idx_manual)
g = sns.regplot(x=train_NoOutlier['GrLivArea'], y=train_NoOutlier['SalePrice'], ax = axes[1])
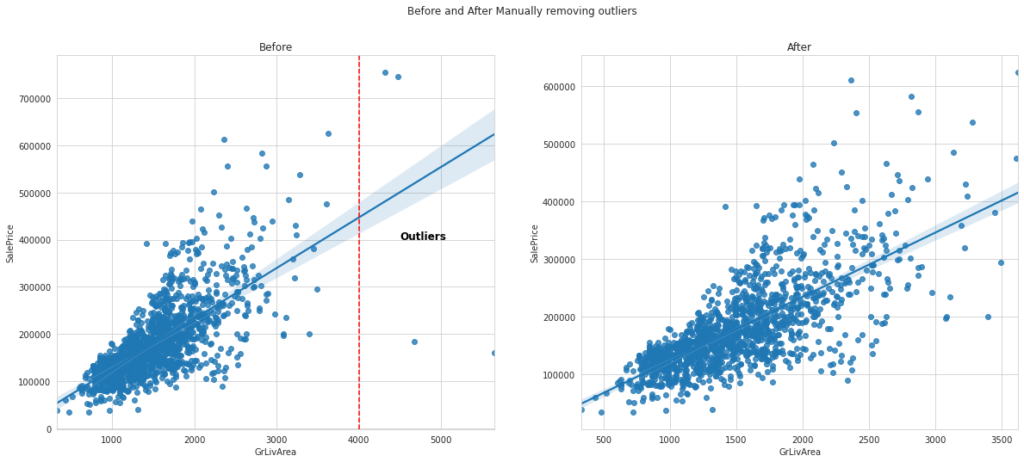
شاهد كيف يتم توزيع البيانات بشكل أقل وأكثر تركيزًا في نطاق أصغر من مساحة الأرضية. على الرغم من أنه لا يزال بإمكانك إلقاء نظرة فاحصة ومعرفة أن هناك قيمًا صغيرة جدًا في الزاوية اليسرى السفلية من الرسم البياني تُظهر العقارات التي يتم بيعها بقيم صغيرة بشكل غير طبيعي.
يمكنك المضي قدمًا وحذفها ومعرفة ما سيحدث لنتائجك. لقد قمت بإزالة الأسعار التي تقل عن 40000 يدويًا وسيساعد ذلك بالفعل في دقة نموذج التعلم الآلي الخاص بنا.
آمل أن تكون قد أحببت هذه المقالة حول كيفية إزالة القيم المتطرفة في التعلم الآلي باستخدام بايثون.



