

- الشروع في العمل مع PyGAD
- وحدة pygad.kerasga
- خطوات تدريب نموذج Keras باستخدام PyGAD
- تحديد نوع المشكلة
- إنشاء نموذج Keras
- إنشاء فئة pygad.kerasga.KerasGA
- تحضير بيانات التدريب
- دالة الخسارة
- دالة اللياقة
- دالة رد الاتصال (اختياري)
- إنشاء مثيل لفئة pygad.GA
- تنفيذ الخوارزمية الجينية
- اللياقة مقابل رسم الجيل
- إحصائيات عن النموذج المدرب
- كود كامل للانحدار
- كود كامل للتصنيف باستخدام CNN
PyGAD هي مكتبة بايثون مفتوحة المصدر لبناء الخوارزمية الجينية وتدريب خوارزميات التعلم الآلي. يقدم مجموعة واسعة من المعلمات لتخصيص الخوارزمية الجينية للعمل مع أنواع مختلفة من المشاكل.
تمتلك PyGAD وحداتها الخاصة التي تدعم بناء وتدريب الشبكات العصبية (NN) والشبكات العصبية التلافيفية (CNN). على الرغم من أن هذه الوحدات تعمل بشكل جيد، إلا أنه يتم تنفيذها في بايثون دون أي إجراءات تحسين إضافية. هذا يؤدي إلى أوقات حسابية عالية نسبيًا حتى للمشكلات البسيطة.
يدعم أحدث إصدار من PyGAD ، 2.8.0 (تم إصداره في 20 سبتمبر 2020) ، وحدة جديدة لتدريب نماذج Keras. على الرغم من أن Keras مبنية في بايثون، إلا أنها سريعة. والسبب هو أن Keras تستخدم TensorFlow كخلفية، وأن TensorFlow محسّن للغاية.
يناقش هذا البرنامج التعليمي كيفية تدريب نماذج Keras باستخدام PyGAD. تتضمن المناقشة بناء نماذج Keras باستخدام إما النموذج التسلسلي Sequential Model أو واجهة برمجة التطبيقات الوظيفية Functional API، وبناء مجموعة أولية من معلمات نموذج Keras ، وإنشاء دالة لياقة مناسبة fitness function، والمزيد.
يمكنك أيضًا متابعة الكود الموجود في هذا البرنامج التعليمي وتشغيله مجانًا على Gradient Community Notebookمن ML Showcase. مخطط البرنامج التعليمي الكامل هو كما يلي:
- الشروع في استخدام PyGAD.
- وحدة pygad.kerasga.
- خطوات تدريب نموذج Keras باستخدام PyGAD.
- تحديد نوع المشكلة.
- إنشاء نموذج Keras.
- إنشاء فئة pygad.kerasga.KerasGA.
- تحضير بيانات التدريب.
- دالة الخسارة.
- دالة اللياقة.
- دالة رد الاتصال الجيل (اختياري).
- إنشاء مثيل لفئة pygad.GA.
- تنفيذ الخوارزمية الجينية.
- اللياقة مقابل رسم الجيل.
- إحصائيات عن النموذج المدرب.
- كود كامل للانحدار.
- كود كامل للتصنيف باستخدام CNN.
هيا بنا نبدأ.
الشروع في العمل مع PyGAD
لبدء هذا البرنامج التعليمي، من الضروري تثبيت PyGAD. إذا كان لديك PyGAD مثبتًا بالفعل، فتحقق من السمة __version__ للتأكد من تثبيت PyGAD 2.8.0 على الأقل.
import pygad
print(pygad.__version__)
يتوفر PyGAD في PyPI (Python Package Index)، ويمكن تثبيته باستخدام أداة تثبيت pip. إذا لم يكن لديك PyGAD مثبتًا بالفعل، فتأكد من تثبيت PyGAD 2.8.0 أو أعلى.
pip install pygad>=2.8.0
يمكنك العثور على وثائق PyGAD في Read the Docs، بما في ذلك بعض نماذج المشكلات. فيما يلي مثال على كيفية حل مشكلة بسيطة، أي تحسين معلمات النموذج الخطي linear model.
import pygad
import numpy
function_inputs = [4,-2,3.5,5,-11,-4.7]
desired_output = 44
def fitness_func(solution, solution_idx):
output = numpy.sum(solution*function_inputs)
fitness = 1.0 / (numpy.abs(output - desired_output) + 0.000001)
return fitness
num_generations = 100
num_parents_mating = 10
sol_per_pop = 20
num_genes = len(function_inputs)
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
fitness_func=fitness_func,
sol_per_pop=sol_per_pop,
num_genes=num_genes)
ga_instance.run()
ga_instance.plot_result()
وحدة pygad.kerasga
بدءًا من PyGAD 2.8.0 ، تم تقديم وحدة نمطية جديدة تسمى kerasga. مختصر لـ Keras Genetic Algorithm. تقدم الوحدة الدوال التالية:
- بناء المجموعة الأولية للحلول باستخدام فئة KerasGA. يحتوي كل حل على جميع المعلمات الخاصة بنموذج Keras.
- تمثيل معلمات نموذج Keras ككروموسوم (أي متجه احادي الاتجاه) باستخدام دالة model_weights_as_vector().
- استعادة معلمات نموذج Keras من الكروموسوم باستخدام دالة model_weights_as_matrix().
تحتوي الوحدة النمطية pygad.kerasga على فئة تسمى KerasGA. يقبل مُنشئ constructor هذه الفئة معاملين:
- model: نموذج Keras.
- num_solutions: عدد الحلول في المجتمع population.
بناءً على هاتين المعلمتين، تُنشئ فئة pygad.kerasga.KerasGA سمات مثيل:
- model: إشارة إلى نموذج Keras.
- num_solutions: عدد الحلول في المجتمع.
- population_weights: قائمة متداخلة تحتوي على معلمات النموذج. يتم تحديث هذه القائمة بعد كل جيل generation.
بافتراض حفظ نموذج Keras في متغير model، فإن الكود أدناه ينشئ مثيلًا لفئة KerasGAويحفظه في متغير keras_ga. يتم تعيين القيمة 10 للوسيطة num_solutions، مما يعني أن المحتوى به 10 حلول.
يُنشئ المُنشئ قائمة طول تساوي قيمة وسيطة num_solutions. يحتوي كل عنصر في القائمة على قيم مختلفة لمعلمات النموذج بعد تحويله إلى متجه أحادي الأبعاد باستخدام دالة model_weights_as_vector(). استنادًا إلى مثيل فئة KerasGA ، يمكن إرجاع المجتمع الأولي initial population من خاصية population_weights. بافتراض أن النموذج يحتوي على 60 معلمة وأن هناك 10 حلول، فإن شكل المجتمع الأولي هو 10×60.
import pygad.kerasga
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
initial_population = keras_ga.population_weights
يلخص القسم التالي خطوات تدريب نموذج Keras باستخدام PyGAD. ستتم مناقشة كل خطوة من هذه الخطوات بمزيد من التفصيل فيما بعد.
خطوات تدريب نموذج Keras باستخدام PyGAD
يتم تلخيص خطوات تدريب نموذج Keras باستخدام PyGAD على النحو التالي:
- تحديد نوع المشكلة.
- إنشاء نموذج Keras.
- إنشاء فئة pygad.kerasga.KerasGA.
- تحضير بيانات التدريب.
- دالة الخسارة.
- دالة اللياقة.
- دالة رد الاتصال (اختياري).
- إنشاء مثيل لفئة pygad.GA.
- تشغيل الخوارزمية الجينية.
تناقش الأقسام التالية كل خطوة من هذه الخطوات.
تحديد نوع المشكلة
يساعد نوع المشكلة (إما التصنيف classification أو الانحدار regression) في تحديد ما يلي:
- دالة الخسارة (التي تستخدم لبناء دالة اللياقة).
- طبقة الإخراج في نموذج Keras.
- بيانات التدريب.
بالنسبة لمشكلة الانحدار، يمكن أن تكون دالة الخسارة هي متوسط الخطأ المطلق mean absolute error أو متوسط الخطأ التربيعي mean squared errorأو دالة أخرى كما هو مذكور هنا.
بالنسبة لمشكلة التصنيف، يمكن أن تكون دالة الخسارة عبارة عن إنتروبيا ثنائية binary cross-entropy (للتصنيف الثنائي binary classification) ، أو إنتروبيا فئوية categorical cross-entropy (للمشكلات متعددة الفئات multi-class problems) ، أو دالة أخرى كما هو مدرج في هذه الصفحة.
تختلف دالة التنشيط activation function في طبقة المخرجات بناءً على ما إذا كانت المشكلة تتعلق بالتصنيف أو الانحدار. بالنسبة لمشكلة التصنيف، قد تكون softmax ، مقارنة بخطية linear الانحدار.
بالنسبة للمخرجات، بالنسبة لمشكلة الانحدار، سيكون الناتج دالة مستمرة، مقارنةً بتسمية فئة لمشاكل التصنيف.
باختصار، من الأهمية بمكان تحديد نوع المشكلة مسبقًا بحيث يتم تحديد بيانات التدريب ودالة الخسارة بشكل صحيح.
إنشاء نموذج Keras
هناك ثلاث طرق لبناء نموذج Keras:
- النموذج المتسلسل Sequential Model.
- API الوظيفية Functional API.
- نموذج Subclassing Model Subclassing.
يدعم PyGAD بناء نموذج Keras باستخدام كل من النموذج المتسلسل وAPI الوظيفية.
النموذج المتسلسل
لإنشاء نموذج تسلسلي باستخدام Keras، ما عليك سوى إنشاء كل طبقة باستخدام الوحدة النمطية tensorflow.keras.layers. ثم قم بإنشاء مثيل للفئة tensorflow.keras.Sequential. أخيرًا، استخدم طريقة add() لإضافة الطبقات إلى النموذج.
import tensorflow.keras
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")
model = tensorflow.keras.Sequential()
model.add(input_layer)
model.add(dense_layer1)
model.add(output_layer)
لاحظ أن دالة تنشيط طبقة الإخراج خطية linear ، مما يعني أن هذا يتعلق بمشكلة انحدار. بالنسبة لمشكلة التصنيف، يمكن أن تكون دالة التنشيط softmax. في السطر التالي، تحتوي طبقة الإخراج على 2 خلايا عصبية (1 لكل فئة) وتستخدم دالة تنشيط softmax.
output_layer = tensorflow.keras.layers.Dense(2, activation=”linear”)
API الوظيفية
بالنسبة لحالة API الوظيفية، يتم إنشاء كل طبقة بشكل طبيعي (بالطريقة نفسها التي رأيناها أعلاه، عند إنشاء نموذج تسلسلي). باستثناء طبقة الإدخال، يتم استخدام كل طبقة لاحقة كدالة تقبل الطبقة السابقة كوسيطة. أخيرًا، تم إنشاء مثيل لفئة tensorflow.keras.Model ، والتي تقبل طبقات الإدخال والإخراج كوسائط.
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")(input_layer)
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")(dense_layer1)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
بعد إنشاء نموذج Keras ، فإن الخطوة التالية هي إنشاء مجموعة أولية من معلمات نموذج Keras باستخدام فئة KerasGA.
إنشاء فئة pygad.kerasga.KerasGA
بإنشاء مثيل لفئة pygad.kerasga.KerasGA ، يتم إنشاء مجموعة أولية لمعلمات نموذج Keras. الكود التالي يمرر نموذج Keras الذي تم إنشاؤه في القسم السابق إلى وسيطة model لمنشئ فئة KerasGA.
import pygad.kerasga
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
ينشئ القسم التالي بيانات التدريب المستخدمة لتدريب نموذج Keras.
تحضير بيانات التدريب
يتم إعداد بيانات التدريب بناءً على نوع المشكلة (التصنيف أو الانحدار).
بالنسبة لمشكلة الانحدار بمخرج واحد، إليك بعض بيانات التدريب التي تم إنشاؤها عشوائيًا حيث تحتوي كل عينة على 3 مدخلات.
# Data inputs
data_inputs = numpy.array([[0.02, 0.1, 0.15],
[0.7, 0.6, 0.8],
[1.5, 1.2, 1.7],
[3.2, 2.9, 3.1]])
# Data outputs
data_outputs = numpy.array([[0.1],
[0.6],
[1.3],
[2.5]])
يوجد أدناه نموذج لبيانات التدريب مع مدخلين لمشكلة تصنيف ثنائي مثل XOR. يتم تحضير النواتج بحيث تحتوي الطبقة الناتجة على خليتين عصبيتين؛ 1 لكل فئة.
# XOR problem inputs
data_inputs = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
# XOR problem outputs
data_outputs = numpy.array([[1, 0],
[0, 1],
[0, 1],
[1, 0]])
يناقش القسم التالي دالة الخسارة لمشاكل الانحدار والتصنيف.
دالة الخسارة
تختلف دالة الخسارة (الخطأ) بناءً على نوع المشكلة. يناقش هذا القسم بعض دوال الخسارة في الوحدة النمطية tensorflow.keras.losses من Keras لمشاكل الانحدار والتصنيف.
الانحدار
بالنسبة لمشكلة الانحدار، تتضمن دوال الخسارة ما يلي:
tensorflow.keras.losses.MeanAbsoluteError()tensorflow.keras.losses.MeanSquaredError()
تحقق من هذه الصفحة لمزيد من المعلومات.
فيما يلي مثال يحسب متوسط الخطأ المطلق حيث يمثل y_true و y_pred المخرجات الحقيقية والمتوقعة.
mae = tensorflow.keras.losses.MeanAbsoluteError()
loss = mae(y_true, y_pred).numpy()
التصنيف
بالنسبة لمشكلة التصنيف، تشمل دوال الخسارة ما يلي:
- tensorflow.keras.losses.BinaryCrossentropy() للتصنيف الثنائي.
- tensorflow.keras.losses.CategoricalCrossentropy() للتصنيف متعدد الفئات.
تحقق من هذه الصفحة لمزيد من المعلومات.
فيما يلي مثال لحساب إنتروبيا الطبقة الثنائية:
bce = tensorflow.keras.losses.BinaryCrossentropy()
loss = bce(y_true, y_pred).numpy()
بناءً على دالة الخسارة، يتم إعداد دالة اللياقة وفقًا للقسم التالي.
دالة اللياقة
دوال الخسارة لمشاكل التصنيف أو الانحدار هي دوال تصغير minimization functions، في حين أن دوال اللياقة للخوارزمية الجينية هي دوال تعظيم maximization functions. لذلك، يتم حساب قيمة اللياقة fitness value على أنها مقلوبة لقيمة الخسارة loss value.
fitness_value = 1.0 / loss
الخطوات المستخدمة لحساب قيمة اللياقة للنموذج هي كما يلي:
- قم باستعادة معلمات النموذج من المتجه أحادي الأبعاد.
- اضبط معلمات النموذج.
- قم بعمل تنبؤات.
- احسب قيمة الخسارة.
- احسب قيمة اللياقة.
- أعد قيمة اللياقة.
اللياقة للانحدار
يقوم الكود أدناه ببناء دالة اللياقة الكاملة التي تعمل مع PyGAD لحل مشكلة الانحدار. دالة اللياقة في PyGAD هي دالة بايثون عادية تأخذ وسيطين. يمثل الأول الحل الذي يجب حساب قيمة اللياقة. الوسيطة الثانية هي فهرس الحل داخل المجتمع، والذي قد يكون مفيدًا في بعض الحالات.
الحل الذي تم تمريره إلى دالة اللياقة هو متجه احادي البعد لاستعادة معلمات نموذج Keras من هذا المتجه، يتم استخدام pygad.kerasga.model_weights_as_matrix().
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model, weights_vector=solution)
بمجرد استعادة المعلمات، يتم استخدامها كمعلمات حالية للنموذج بواسطة طريقة set_weights().
model.set_weights(weights=model_weights_matrix)
بناءً على المعلمات الحالية، يتنبأ النموذج بالمخرجات باستخدام طريقة التنبؤ predict().
predictions = model.predict(data_inputs)
تُستخدم المخرجات المتوقعة لحساب قيمة الخسارة. يستخدم متوسط الخطأ mean absolute error المطلق كدالة خسارة.
mae = tensorflow.keras.losses.MeanAbsoluteError()
نظرًا لأن قيمة الخسارة قد تكون 0.0، فمن الأفضل إضافة قيمة صغيرة إليها مثل 0.00000001 لتجنب القسمة على الصفر أثناء حساب قيمة اللياقة.
solution_fitness = 1.0 / (mae(data_outputs, predictions).numpy() + 0.00000001)
أخيرًا، يتم إرجاع قيمة اللياقة.
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
mae = tensorflow.keras.losses.MeanAbsoluteError()
solution_fitness = 1.0 / (mae(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitness
اللياقة للتصنيف الثنائي
بالنسبة لمشكلة التصنيف الثنائي، يوجد أدناه دالة لياقة تعمل مع PyGAD. يحسب الخسارة الثنائية عبر الانتروبيا ، بافتراض أن مشكلة التصنيف ثنائية.
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
bce = tensorflow.keras.losses.BinaryCrossentropy()
solution_fitness = 1.0 / (bce(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitness
يبني القسم التالي دالة رد الاتصال callback function يتم تنفيذها في نهاية كل جيل.
دالة رد الاتصال (اختياري)
يمكن استدعاء دالة رد الاتصال بعد اكتمال كل جيل لحساب بعض الإحصائيات حول أحدث المعلمات التي تم الوصول إليها. هذه الخطوة اختيارية، ولأغراض التصحيح debugging فقط.
تم تنفيذ دالة رد الاتصال الجيل أدناه. في PyGAD، يجب أن تقبل دالة رد الاتصال هذه معلمة تشير إلى مثيل الخوارزمية الجينية، والتي يمكن من خلالها جلب المجتمع الحاليين باستخدام سمة population.
تقوم هذه الدالة بطباعة رقم الجيل الحالي وقيمة اللياقة للحل الأفضل. مثل هذه المعلومات تبقي المستخدم على اطلاع دائم بتقدم الخوارزمية الجينية.
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
إنشاء مثيل لفئة pygad.GA
الخطوة التالية نحو تدريب نموذج Keras باستخدام PyGAD هي إنشاء مثيل لفئة pygad.GA. منشئ هذه الفئة يقبل العديد من الوسيطات التي يمكن استكشافها في الوثائق.
تُنشئ كتلة الكود التالية فئة pygad.GA بتمرير الحد الأدنى لعدد الوسائط لهذا التطبيق، وهي:
- num_generations: عدد الأجيال.
- num_parents_mating: عدد الوالدين للتزاوج.
- initial_population: المجتمع الأوليون لمعلمات نموذج Keras.
- fitness_func: دالة اللياقة.
- on_generation: دالة رد الاتصال الجيل.
لاحظ أن عدد الحلول داخل المجتمع تم ضبطه مسبقًا على 10 في منشئ فئة KerasGA. وبالتالي ، يجب أن يكون عدد الوالدين للتزاوج أقل من 10.
num_generations = 250
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)
يقوم القسم التالي بتشغيل الخوارزمية الجينية لبدء تدريب نموذج Keras.
تنفيذ الخوارزمية الجينية
يتم تشغيل مثيل الفئة pygad.GA باستدعاء طريقة run().
ga_instance.run()
من خلال تنفيذ هذه الطريقة، تبدأ دورة حياة PyGAD وفقًا للشكل التالي.
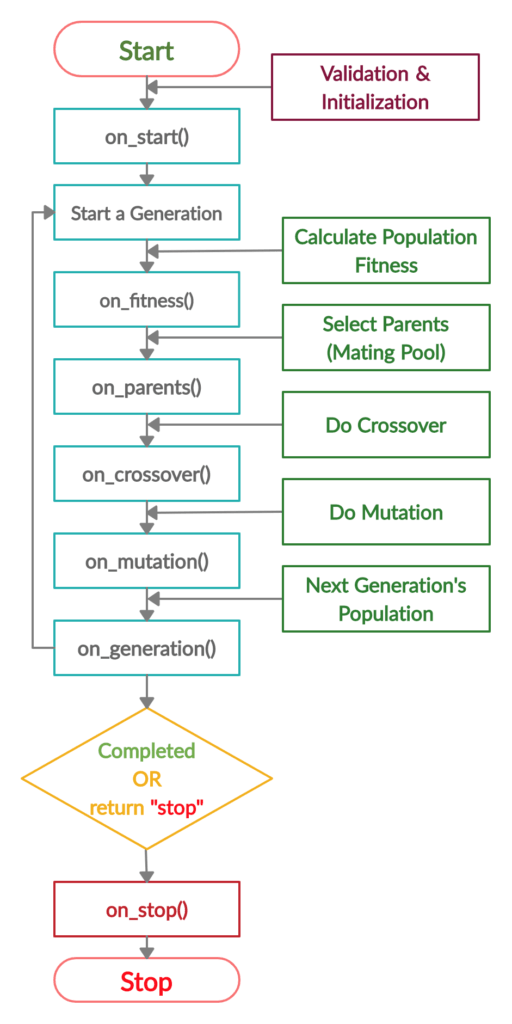
يناقش القسم التالي كيفية استخلاص بعض الاستنتاجات حول النموذج المدرب.
اللياقة مقابل رسم الجيل
باستخدام طريقة plot_result() في فئة pygad.GA ، ينشئ PyGAD شكلًا يوضح كيف تتغير قيمة اللياقة لكل جيل.
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
إحصائيات عن النموذج المدرب
فئة pygad.GA له طريقة تسمى best_solution() والتي تُرجع 3 مخرجات:
- تم العثور على أفضل حل.
- قيمة اللياقة لأفضل الحلول.
- مؤشر أفضل الحلول ضمن المجتمع.
يستدعي الكود التالي أسلوب best_solution() ويطبع معلومات حول أفضل حل موجود.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))
بعد ذلك، سنقوم باستعادة أوزان نموذج Keras من أفضل الحلول. بناءً على الأوزان المستعادة، يتنبأ النموذج بمخرجات عينات التدريب. يمكنك أيضًا توقع مخرجات العينات الجديدة.
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
print("Predictions : \n", predictions)
الكود أدناه يحسب الخسارة، أي متوسط الخطأ المطلق.
كود كامل للانحدار
بالنسبة لمشكلة الانحدار التي تستخدم متوسط الخطأ المطلق كدالة خسارة ، إليك الكود الكامل.
import tensorflow.keras
import pygad.kerasga
import numpy
import pygad
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
mae = tensorflow.keras.losses.MeanAbsoluteError()
abs_error = mae(data_outputs, predictions).numpy() + 0.00000001
solution_fitness = 1.0 / abs_error
return solution_fitness
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")(input_layer)
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")(dense_layer1)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
weights_vector = pygad.kerasga.model_weights_as_vector(model=model)
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
# Data inputs
data_inputs = numpy.array([[0.02, 0.1, 0.15],
[0.7, 0.6, 0.8],
[1.5, 1.2, 1.7],
[3.2, 2.9, 3.1]])
# Data outputs
data_outputs = numpy.array([[0.1],
[0.6],
[1.3],
[2.5]])
num_generations = 250
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)
ga_instance.run()
# After the generations complete, some plots are showed that summarize how the outputs/fitness values evolve over generations.
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
print("Predictions : \n", predictions)
mae = tensorflow.keras.losses.MeanAbsoluteError()
abs_error = mae(data_outputs, predictions).numpy()
print("Absolute Error : ", abs_error)
بعد اكتمال الكود، يوضح الشكل التالي كيف تزداد قيمة اللياقة. هذا يدل على أن نموذج Keras يتعلم بشكل صحيح.
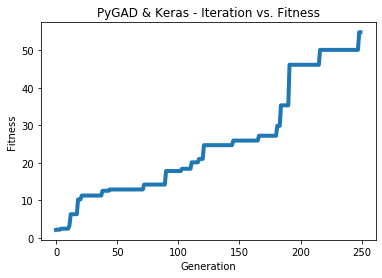
فيما يلي مزيد من التفاصيل حول النموذج المدرب. لاحظ أن القيم المتوقعة قريبة من القيم الحقيقية. MAE هو 0.018.
Fitness value of the best solution = 54.79189095217631
Index of the best solution : 0
Predictions :
[[0.11471477]
[0.6034051 ]
[1.3416876 ]
[2.486804 ]]
Absolute Error : 0.018250866
كود كامل للتصنيف باستخدام CNN
يُنشئ الكود التالي شبكة عصبية تلافيفية باستخدام Keras لتصنيف مجموعة بيانات من 80 صورة، حيث يكون حجم كل صورة 100x100x3 لاحظ أنه يتم استخدام خسارة الانتروبيا الفئوية لأن مجموعة البيانات بها 4 فئات.
يمكن تنزيل بيانات التدريب من هنا (مدخلات مجموعة البيانات) وهنا (مخرجات مجموعة البيانات).
import tensorflow.keras
import pygad.kerasga
import numpy
import pygad
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
cce = tensorflow.keras.losses.CategoricalCrossentropy()
solution_fitness = 1.0 / (cce(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitness
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
# Build the keras model using the functional API.
input_layer = tensorflow.keras.layers.Input(shape=(100, 100, 3))
conv_layer1 = tensorflow.keras.layers.Conv2D(filters=5,
kernel_size=7,
activation="relu")(input_layer)
max_pool1 = tensorflow.keras.layers.MaxPooling2D(pool_size=(5,5),
strides=5)(conv_layer1)
conv_layer2 = tensorflow.keras.layers.Conv2D(filters=3,
kernel_size=3,
activation="relu")(max_pool1)
flatten_layer = tensorflow.keras.layers.Flatten()(conv_layer2)
dense_layer = tensorflow.keras.layers.Dense(15, activation="relu")(flatten_layer)
output_layer = tensorflow.keras.layers.Dense(4, activation="softmax")(dense_layer)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
# Data inputs
data_inputs = numpy.load("dataset_inputs.npy")
# Data outputs
data_outputs = numpy.load("dataset_outputs.npy")
data_outputs = tensorflow.keras.utils.to_categorical(data_outputs)
num_generations = 200
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)
ga_instance.run()
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
# print("Predictions : \n", predictions)
# Calculate the categorical crossentropy for the trained model.
cce = tensorflow.keras.losses.CategoricalCrossentropy()
print("Categorical Crossentropy : ", cce(data_outputs, predictions).numpy())
# Calculate the classification accuracy for the trained model.
ca = tensorflow.keras.metrics.CategoricalAccuracy()
ca.update_state(data_outputs, predictions)
accuracy = ca.result().numpy()
print("Accuracy : ", accuracy)
يوضح الشكل التالي كيف تتطور قيمة اللياقة لكل جيل. طالما زادت قيمة اللياقة، يمكنك زيادة عدد الأجيال لتحقيق دقة أفضل.
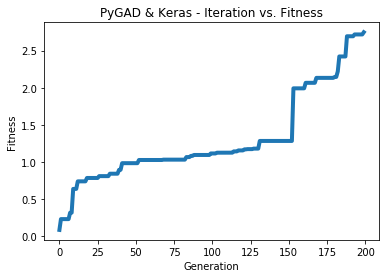
فيما يلي بعض المعلومات حول النموذج المدرب:
Fitness value of the best solution = 2.7462310258668805
Categorical Crossentropy : 0.3641354
Accuracy : 0.75
خاتمة
رأينا في هذا البرنامج التعليمي كيفية تدريب نماذج Keras باستخدام الخوارزمية الجينية مع مكتبة PyGAD مفتوحة المصدر. يمكن إنشاء نماذج Keras باستخدام النموذج التسلسلي أو واجهة برمجة التطبيقات الوظيفية.
باستخدام وحدة pygad.kerasga ، يتم إنشاء مجموعة أولية من أوزان نموذج Keras ، حيث يحتوي كل حل على مجموعة مختلفة من الأوزان للنموذج. تطورت هذه المجموعة لاحقًا وفقًا لدورة حياة PyGAD حتى تكتمل جميع الأجيال.
نظرًا لطبيعة TensorFlow عالية السرعة ، وهي الواجهة الخلفية لـ Keras ، يمكن لـ PyGAD تدريب البنى المعقدة في فترة زمنية مقبولة.



