

- مشكلة التصنيف الثنائي
- نموذج متعدد الطبقات Perceptron
- كيفية حساب مقاييس النموذج
- الملخص
بمجرد ملاءمة fit نموذج الشبكة العصبية للتعلم العميق، يجب عليك تقييم evaluate أدائه في مجموعة بيانات اختبار.
هذا أمر بالغ الأهمية، لأن الأداء المبلغ عنه يسمح لك بالاختيار بين النماذج المرشحة والتواصل مع أصحاب المصلحة حول مدى جودة النموذج في حل المشكلة.
نموذج واجهة برمجة تطبيقات API التعلم العميق Keras محدود للغاية من حيث المقاييس التي يمكنك استخدامها للإبلاغ عن أداء النموذج.
أنا أطرح أسئلة متكررة، مثل:
كيف يمكنني حساب الدقة precision والاستدعاء recall لنموذجي؟
و:
كيف يمكنني حساب F1-score أو مصفوفة الارتباك confusion matrix لنموذجي؟
في هذا البرنامج التعليمي، سوف تكتشف كيفية حساب المقاييس metrics لتقييم نموذج الشبكة العصبية للتعلم العميق الخاص بك مع مثال خطوة بخطوة.
بعد الانتهاء من هذا البرنامج التعليمي، ستعرف:
كيفية استخدام مقاييس scikit-Learn API لتقييم نموذج التعلم العميق.
كيفية عمل تنبؤات الفئة والاحتمالات بنموذج نهائي مطلوب بواسطة scikit-Learn API.
كيفية حساب الدقة والاستدعاء ودرجة F1 وROC AUC والمزيد باستخدام واجهة برمجة تطبيقات scikit-Learn للنموذج.
ابدأ مشروعك بكتابي الجديد Deep Learning With Python ، بما في ذلك البرامج التعليمية خطوة بخطوة وملفات كود مصدر Python لجميع الأمثلة.
هيا بنا نبدأ.
نظرة عامة على البرنامج التعليمي
ينقسم هذا البرنامج التعليمي إلى ثلاثة أجزاء:
- مشكلة التصنيف الثنائي
- نموذج متعدد الطبقات Perceptron
- كيفية حساب مقاييس النموذج
مشكلة التصنيف الثنائي
سوف نستخدم مشكلة تصنيف ثنائية binary classification قياسية كأساس لهذا البرنامج التعليمي، تسمى مشكلة “دائرتين two circles”.
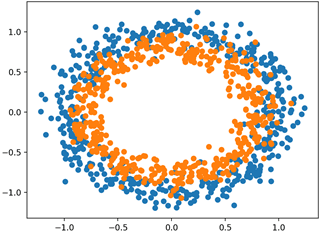
تسمى مشكلة الدائرتين لأن المشكلة تتكون من النقاط التي عند رسمها تظهر دائرتين متحدة المركز، واحدة لكل فئة. على هذا النحو، هذا مثال على مشكلة التصنيف الثنائي. المشكلة لها مدخلين يمكن تفسيرهما على أنهما إحداثيان x و y على الرسم البياني. كل نقطة تنتمي إلى الدائرة الداخلية أو الخارجية.
تسمح لك دالة make_circles() في مكتبة scikit-Learn بتوليد عينات من مشكلة الدائرتين. تسمح لك الوسيطة “n_samples” بتحديد عدد العينات المراد إنشاؤها، مقسمة بالتساوي بين الفئتين. تسمح لك الوسيطة ” noise” بتحديد مقدار الضوضاء الإحصائية العشوائية المضافة إلى مدخلات أو إحداثيات كل نقطة، مما يجعل مهمة التصنيف أكثر صعوبة. تحدد الوسيطة “random_state” الأصل لمولد الرقم العشوائي شبه العشوائي pseudorandom، مما يضمن إنشاء نفس العينات في كل مرة يتم فيها تشغيل الكود.
يولد المثال أدناه 1000 عينة، مع 0.1 ضوضاء إحصائية وبذرة 1.
# generate 2d classification dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
بمجرد الإنشاء، يمكننا إنشاء مخطط لمجموعة البيانات للحصول على فكرة عن مدى صعوبة مهمة التصنيف. يولد المثال أدناه عينات ويرسمها، ويلون كل نقطة وفقًا للفئة، حيث يتم تلوين النقاط التي تنتمي إلى الفئة 0 (الدائرة الخارجية) باللون الأزرق والنقاط التي تنتمي إلى الفئة 1 (الدائرة الداخلية) ملونة باللون البرتقالي.
# Example of generating samples from the two circle problem
from sklearn.datasets import make_circles
from matplotlib import pyplot
from numpy import where
# generate 2d classification dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# scatter plot, dots colored by class value
for i in range(2):
samples_ix = where(y == i)
pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1])
pyplot.show()
يؤدي تشغيل المثال إلى إنشاء مجموعة البيانات ورسم النقاط على الرسم البياني، ويظهر بوضوح دائرتين متحدة المركز للنقاط التي تنتمي إلى الفئة 0 والفئة 1.
نموذج متعدد الطبقات Perceptron
سنقوم بتطوير نموذج متعدد الطبقات Multilayer Perceptron، أو MLP، لمعالجة مشكلة التصنيف الثنائي.
لم يتم تحسين هذا النموذج للمشكلة، لكنه ماهر (أفضل من العشوائي).
بعد إنشاء عينات مجموعة البيانات، سنقسمها إلى جزأين متساويين: أحدهما لتدريب النموذج والآخر لتقييم النموذج المدرب.
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
بعد ذلك، يمكننا تحديد نموذج MLP الخاص بنا. النموذج بسيط، حيث يتوقع متغيري إدخال من مجموعة البيانات، وطبقة مخفية واحدة تحتوي على 100 عقدة، ودالة تنشيط ReLU ، ثم طبقة إخراج مع عقدة واحدة ودالة تنشيط sigmoid. سيتنبأ النموذج بقيمة تتراوح بين 0 و 1 والتي سيتم تفسيرها فيما إذا كان مثال الإدخال ينتمي إلى الفئة 0 أو الفئة 1
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
سيكون النموذج مناسبًا باستخدام دالة خطأ الانتروبيا الثنائية binary cross entropy وسنستخدم نسخة Adam الفعالة من التدرج الاشتقاقي العشوائي stochastic gradient descent. سيراقب النموذج أيضًا مقياس دقة التصنيف.
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
سنلائم fit نموذج 300 حقبة تدريبية بحجم الدُفعة batch size الافتراضي المكون من 32 عينة وتقييم أداء النموذج في نهاية كل فترة تدريب على مجموعة بيانات الاختبار.
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0)
في نهاية التدريب، سنقوم بتقييم النموذج النهائي مرة أخرى في التدريب واختبار مجموعات البيانات والإبلاغ عن دقة التصنيف.
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
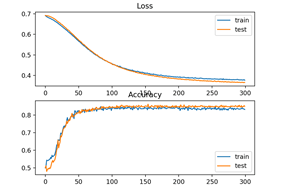
أخيرًا، سيتم رسم أداء النموذج في مجموعات التدريب والاختبار المسجلة أثناء التدريب باستخدام المخطط الخطي line plot، واحد لكل من الخطأ loss ودقة التصنيف classification accuracy.
# plot loss during training
pyplot.subplot(211)
pyplot.title('Loss')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title('Accuracy')
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
بربط كل هذه العناصر معًا، يتم سرد قائمة التعليمات البرمجية الكاملة للتدريب وتقييم MLP في مشكلة الدائرتين أدناه.
# multilayer perceptron model for the two circles problem
from sklearn.datasets import make_circles
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot loss during training
pyplot.subplot(211)
pyplot.title('Loss')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title('Accuracy')
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
تشغيل المثال يناسب النموذج بسرعة كبيرة على وحدة المعالجة المركزية (لا يلزم GPU).
ملاحظة: قد تختلف نتائجك نظرًا للطبيعة العشوائية للخوارزمية أو إجراء التقييم، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات وقارن النتيجة المتوسطة.
تم تقييم النموذج، والإبلاغ عن دقة التصنيف في مجموعات التدريب والاختبار بحوالي 83٪ و 85٪ على التوالي.
Train: 0.838, Test: 0.850
تم إنشاء شكل يوضح خطي خطين: أحدهما لمنحنيات التعلم للخطأ في مجموعات التدريب والاختبار والآخر للتصنيف في مجموعات التدريب والاختبار.
تشير المخططات إلى أن النموذج مناسب للمشكلة بشكل جيد.
كيفية حساب مقاييس النموذج
ربما تحتاج إلى تقييم نموذج الشبكة العصبية للتعلم العميق الخاص بك باستخدام مقاييس إضافية غير مدعومة بواسطة واجهة برمجة تطبيقات مقاييس Keras.
واجهة برمجة تطبيقات مقاييس Keras محدودة وقد ترغب في حساب مقاييس مثل الدقة والاستدعاء و F1 والمزيد.
تتمثل إحدى طرق حساب المقاييس الجديدة في تنفيذها بنفسك في Keras API وجعل Keras تحسبها لك أثناء تدريب النموذج وأثناء تقييم النموذج.
للمساعدة في هذا الأسلوب، راجع البرنامج التعليمي:
هذا يمكن أن يكون تحديا من الناحية الفنية.
هناك بديل أبسط بكثير وهو استخدام النموذج النهائي لعمل تنبؤ لمجموعة بيانات الاختبار ، ثم حساب أي مقياس تريده باستخدام واجهة برمجة تطبيقات المقاييس scikit-Learn.
هناك ثلاثة مقاييس، بالإضافة إلى دقة التصنيف، مطلوبة عادة لنموذج الشبكة العصبية في مشكلة التصنيف الثنائي وهي:
- الدقة (Precision).
- الاستدعاء (Recall).
- درجة F1 (F1 Score).
في هذا القسم، سنحسب هذه المقاييس الثلاثة، بالإضافة إلى دقة التصنيف باستخدام مقاييس scikit-Learn API ، وسنقوم أيضًا بحساب ثلاثة مقاييس إضافية أقل شيوعًا ولكنها قد تكون مفيدة. هم انهم:
- كابا كوهين Cohen’s Kappa
- ROC AUC
- مصفوفة الارتباك Confusion Matrix.
هذه ليست قائمة كاملة بمقاييس نماذج التصنيف التي يدعمها scikit-Learn؛ ومع ذلك، سيوضح لك حساب هذه المقاييس كيفية حساب أي مقاييس قد تحتاجها باستخدام واجهة برمجة تطبيقات scikit-Learn.
للحصول على قائمة كاملة بالمقاييس المدعومة ، راجع:
سيحسب المثال في هذا القسم مقاييس نموذج MLP ، ولكن يمكن استخدام نفس الكود لحساب المقاييس لنماذج أخرى ، مثل RNNs و CNN.
يمكننا استخدام نفس الكود من الأقسام السابقة لإعداد مجموعة البيانات، بالإضافة إلى تحديد النموذج وملائمته. لتبسيط المثال، سنضع كود هذه الخطوات في دالة بسيطة.
أولاً، يمكننا تحديد دالة تسمى get_data() والتي ستنشئ مجموعة البيانات وتقسيمها إلى مجموعات تدريب واختبار.
# generate and prepare the dataset
def get_data():
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
بعد ذلك، سنحدد دالة تسمى get_model() تحدد نموذج MLP وتناسبه في مجموعة بيانات التدريب.
# define and fit the model
def get_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy, epochs=300, verbose=0)
return model
يمكننا بعد ذلك استدعاء دالة get_data() لإعداد مجموعة البيانات ودالة get_model()لملاءمة النموذج وإعادته.
# generate data
trainX, trainy, testX, testy = get_data()
# fit model
model = get_model(trainX, trainy)
الآن بعد أن أصبح لدينا نموذج مناسب لمجموعة بيانات التدريب، يمكننا تقييمه باستخدام مقاييس من scikit-learn metrics API.
أولاً، يجب أن نستخدم النموذج لعمل تنبؤات. تتطلب معظم دوال القياس مقارنة بين قيم الفئة الحقيقية true class values (على سبيل المثال testy) وقيم الفئة المتوقعة predicted class values (yhat_classes). يمكننا التنبؤ بقيم الفئة مباشرة باستخدام نموذجنا باستخدام دالة predict_classes()في النموذج.
تتطلب بعض المقاييس، مثل ROC AUC ، توقع احتمالات الفئة (yhat_probs). يمكن استرجاعها عن طريق استدعاء دالة predict()في النموذج.
لمزيد من المساعدة في إجراء التنبؤات باستخدام نموذج Keras ، راجع المنشور:
يمكننا عمل تنبؤات الطبقة والاحتمالات باستخدام النموذج.
# predict probabilities for test set
yhat_probs = model.predict(testX, verbose=0)
# predict crisp classes for test set
yhat_classes = model.predict_classes(testX, verbose=0)
يتم إرجاع التنبؤات في مصفوفة ثنائية الأبعاد، مع صف واحد لكل مثال في مجموعة بيانات الاختبار وعمود واحد للتنبؤ.
تتوقع واجهة برمجة تطبيقات مقاييس scikit-Learn مصفوفة أحادية (1D array) البعد من القيم الفعلية والمتوقعة للمقارنة، لذلك، يجب علينا تقليل مصفوفات التنبؤ ثنائية الأبعاد إلى مصفوفات أحادية البعد.
# reduce to 1d array
yhat_probs = yhat_probs[:, 0]
yhat_classes = yhat_classes[:, 0]
نحن الآن جاهزون لحساب المقاييس لنموذج الشبكة العصبية للتعلم العميق الخاص بنا. يمكننا البدء بحساب دقة التصنيف classification accuracy والدقة precision والاستدعاء recall و F1 scores.
# accuracy: (tp + tn) / (p + n)
accuracy = accuracy_score(testy, yhat_classes)
print('Accuracy: %f' % accuracy)
# precision tp / (tp + fp)
precision = precision_score(testy, yhat_classes)
print('Precision: %f' % precision)
# recall: tp / (tp + fn)
recall = recall_score(testy, yhat_classes)
print('Recall: %f' % recall)
# f1: 2 tp / (2 tp + fp + fn)
f1 = f1_score(testy, yhat_classes)
print('F1 score: %f' % f1)
لاحظ أن حساب المقياس بسيط مثل اختيار المقياس الذي يهمنا واستدعاء الدالة التي تمر في قيم الفئة الحقيقية (testy) وقيم الفئة المتوقعة (yhat_classes).
يمكننا أيضًا حساب بعض المقاييس الإضافية، مثل Cohen’s kappa و ROC AUC ومصفوفة الارتباك.
لاحظ أن ROC AUC تتطلب احتمالات الفئة المتوقعة (yhat_probs) كوسيطة بدلاً من الفئات المتوقعة (yhat_classes).
# kappa
kappa = cohen_kappa_score(testy, yhat_classes)
print('Cohens kappa: %f' % kappa)
# ROC AUC
auc = roc_auc_score(testy, yhat_probs)
print('ROC AUC: %f' % auc)
# confusion matrix
matrix = confusion_matrix(testy, yhat_classes)
print(matrix)
الآن بعد أن عرفنا كيفية حساب المقاييس لشبكة عصبية للتعلم العميق باستخدام واجهة برمجة تطبيقات scikit-Learn ، يمكننا ربط كل هذه العناصر معًا في مثال كامل ، مدرج أدناه.
# demonstration of calculating metrics for a neural network model using sklearn
from sklearn.datasets import make_circles
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import cohen_kappa_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
from keras.models import Sequential
from keras.layers import Dense
# generate and prepare the dataset
def get_data():
# generate dataset
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# split into train and test
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
# define and fit the model
def get_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(100, input_shape=(2,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy, epochs=300, verbose=0)
return model
# generate data
trainX, trainy, testX, testy = get_data()
# fit model
model = get_model(trainX, trainy)
# predict probabilities for test set
yhat_probs = model.predict(testX, verbose=0)
# predict crisp classes for test set
yhat_classes = model.predict_classes(testX, verbose=0)
# reduce to 1d array
yhat_probs = yhat_probs[:, 0]
yhat_classes = yhat_classes[:, 0]
# accuracy: (tp + tn) / (p + n)
accuracy = accuracy_score(testy, yhat_classes)
print('Accuracy: %f' % accuracy)
# precision tp / (tp + fp)
precision = precision_score(testy, yhat_classes)
print('Precision: %f' % precision)
# recall: tp / (tp + fn)
recall = recall_score(testy, yhat_classes)
print('Recall: %f' % recall)
# f1: 2 tp / (2 tp + fp + fn)
f1 = f1_score(testy, yhat_classes)
print('F1 score: %f' % f1)
# kappa
kappa = cohen_kappa_score(testy, yhat_classes)
print('Cohens kappa: %f' % kappa)
# ROC AUC
auc = roc_auc_score(testy, yhat_probs)
print('ROC AUC: %f' % auc)
# confusion matrix
matrix = confusion_matrix(testy, yhat_classes)
print(matrix)
ملاحظة: قد تختلف نتائجك نظرًا للطبيعة العشوائية للخوارزمية أو إجراء التقييم، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات وقارن النتيجة المتوسطة.
يؤدي تشغيل المثال إلى تحضير مجموعة البيانات dataset preparation، وتلائم النموذج model fitting، ثم حساب المقاييس الخاصة بالنموذج الذي تم تقييمه في مجموعة بيانات الاختبار وإعداد التقارير عنها.
Accuracy: 0.842000
Precision: 0.836576
Recall: 0.853175
F1 score: 0.844794
Cohens kappa: 0.683929
ROC AUC: 0.923739
[[206 42]
[ 37 215]]
إذا كنت بحاجة إلى مساعدة في تفسير مقياس معين، فربما تبدأ بـ “دليل مقاييس التصنيف” في وثائق واجهة برمجة تطبيقات scikit-Learn: دليل مقاييس التصنيف.
أيضا، تحقق من صفحة ويكيبيديا للمقياس الخاص بك؛ على سبيل المثال: الدقة والاستدعاء، ويكيبيديا.
الملخص
في هذا البرنامج التعليمي، اكتشفت كيفية حساب المقاييس لتقييم نموذج الشبكة العصبية للتعلم العميق الخاص بك باستخدام مثال خطوة بخطوة.
على وجه التحديد، لقد تعلمت:
- كيفية استخدام مقاييس scikit-Learn API لتقييم نموذج التعلم العميق.
- كيفية عمل تنبؤات الفئة والاحتمالات بنموذج نهائي مطلوب بواسطة scikit-Learn API.
- كيفية حساب الدقة والاستدعاء ودرجة F1 و ROC و AUC والمزيد باستخدام scikit-Learn API للنموذج.



