

- نموذج التنبؤ بالكلمة التالية
- هندسة الميزات
- بناء الشبكة العصبية المتكررة
- تدريب نموذج توقع الكلمة التالية
- تقييم نموذج التنبؤ بالكلمة التالية
- اختبار نموذج التنبؤ بالكلمة التالية
تقدم معظم لوحات المفاتيح في الهواتف الذكية ميزات التنبؤ بالكلمة التالية؛ يستخدم google أيضًا توقع الكلمة التالية استنادًا إلى سجل التصفح الخاص بنا. لذلك يتم أيضًا تخزين البيانات المحملة مسبقًا في وظيفة لوحة المفاتيح بهواتفنا الذكية للتنبؤ بالكلمة التالية بشكل صحيح. في هذه المقالة، سأقوم بتدريب نموذج التعلم العميق للتنبؤ بالكلمة التالية باستخدام بايثون. سأستخدم مكتبة Tensorflow وKeras في بايثون لنموذج التنبؤ بالكلمة التالية.
لصنع نموذج توقع الكلمة التالية، سأقوم بتدريب شبكة عصبية متكررة (RNN). فلنبدأ بهذه المهمة الآن دون إضاعة أي وقت.
نموذج التنبؤ بالكلمة التالية
للبدء بنموذج التنبؤ بالكلمة التالية، دعنا نستورد بعض المكتبات التي نحتاجها لهذه المهمة:
import numpy as np
from nltk.tokenize import RegexpTokenizer
from keras.models import Sequential, load_model
from keras.layers import LSTM
from keras.layers.core import Dense, Activation
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import pickle
import heapq
كما قلت سابقًا، تستخدم Google سجل التصفح الخاص بنا لعمل تنبؤات بالكلمة التالية، ويتم تدريب الهواتف الذكية وجميع لوحات المفاتيح المدربة على التنبؤ بالكلمة التالية باستخدام بعض البيانات. لذلك سأستخدم أيضًا مجموعة بيانات. يمكنك تنزيل مجموعة البيانات من هنا.
الآن دعنا نحمّل البيانات ونلقي نظرة سريعة على ما سنعمل معه:
path = '1661-0.txt'
text = open(path).read().lower()
print('corpus length:', len(text))
سأقوم الآن بتقسيم مجموعة البيانات إلى كل كلمة بالترتيب ولكن دون وجود بعض الأحرف الخاصة.
tokenizer = RegexpTokenizer(r'w+')
words = tokenizer.tokenize(text)
['project', 'gutenberg', 's', 'the', 'adventures', 'of', 'sherlock', 'holmes', 'by', ............................... , 'our', 'email', 'newsletter', 'to', 'hear', 'about', 'new', 'ebooks']
الآن ستكون العملية التالية هي تنفيذ هندسة الميزات feature engineering في بياناتنا. لهذا الغرض، سنطلب قاموسًا يحتوي على كل كلمة في البيانات ضمن قائمة الكلمات الفريدة كمفتاح key، وهي أجزاء مهمة كقيمة value.
unique_words = np.unique(words)
unique_word_index = dict((c, i) for i, c in enumerate(unique_words))
هندسة الميزات
تعني هندسة الميزات أخذ أي معلومات لدينا حول مشكلتنا وتحويلها إلى أرقام يمكننا استخدامها لبناء مصفوفة الميزات الخاصة بنا. إذا كنت تريد برنامجًا تعليميًا مفصلاً عن هندسة الميزات، فيمكنك تعلمه من هنا.
سأحدد هنا طول الكلمة الذي سيمثل عدد الكلمات السابقة التي ستحدد كلمتنا التالية. سأحدد الكلمات السابقة للحفاظ على الكلمات الخمس السابقة والكلمات التالية المقابلة لها في قائمة الكلمات التالية.
WORD_LENGTH = 5
prev_words = []
next_words = []
for i in range(len(words) - WORD_LENGTH):
prev_words.append(words[i:i + WORD_LENGTH])
next_words.append(words[i + WORD_LENGTH])
print(prev_words[0])
print(next_words[0])
الآن سوف أقوم بإنشاء مصفوفتين فارغتين x لتخزين الميزات وy لتخزين التسمية المقابلة لها. سأكرر x وy إذا كانت الكلمة متاحة بحيث يصبح الموضع المقابل 1.
X = np.zeros((len(prev_words), WORD_LENGTH, len(unique_words)), dtype=bool)
Y = np.zeros((len(next_words), len(unique_words)), dtype=bool)
for i, each_words in enumerate(prev_words):
for j, each_word in enumerate(each_words):
X[i, j, unique_word_index[each_word]] = 1
Y[i, unique_word_index[next_words[i]]] = 1
بناء الشبكة العصبية المتكررة
كما ذكرت سابقًا، سأستخدم الشبكات العصبية المتكررة لنموذج التنبؤ بالكلمة التالية. هنا سأستخدم نموذج LSTM، وهو RNN قوي جدًا.
model = Sequential()
model.add(LSTM(128, input_shape=(WORD_LENGTH, len(unique_words))))
model.add(Dense(len(unique_words)))
model.add(Activation('softmax'))
تدريب نموذج توقع الكلمة التالية
سأقوم بتدريب نموذج التنبؤ بالكلمة التالية في 20 حقبة:
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(X, Y, validation_split=0.05, batch_size=128, epochs=2, shuffle=True).history
لقد قمنا الآن بتدريب نموذجنا بنجاح، قبل المضي قدمًا في تقييم نموذجنا، سيكون من الأفضل حفظ هذا النموذج لاستخدامنا في المستقبل.
model.save('keras_next_word_model.h5')
pickle.dump(history, open("history.p", "wb"))
model = load_model('keras_next_word_model.h5')
history = pickle.load(open("history.p", "rb"))
تقييم نموذج التنبؤ بالكلمة التالية
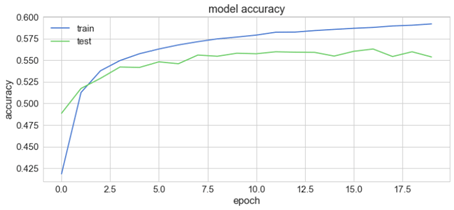
دعنا الآن نلقي نظرة سريعة على كيفية تصرف نموذجنا بناءً على تغييرات دقته وخسارته أثناء التدريب:
plt.plot(history['acc'])
plt.plot(history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
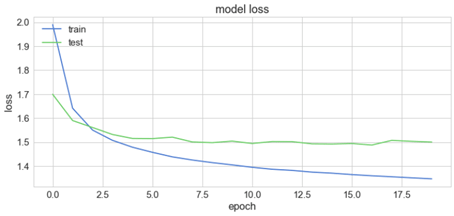
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
اختبار نموذج التنبؤ بالكلمة التالية
فلنقم الآن ببناء برنامج بايثون للتنبؤ بالكلمة التالية باستخدام نموذجنا المُدرَّب. لهذا، سأحدد بعض الدوال الأساسية التي سيتم استخدامها في العملية.
def prepare_input(text):
x = np.zeros((1, SEQUENCE_LENGTH, len(chars)))
for t, char in enumerate(text):
x[0, t, char_indices[char]] = 1.
return x
الآن قبل المضي قدمًا، دعنا نختبر الدالة، تأكد من استخدام دالة lower() أثناء إعطاء الإدخال:
prepare_input("This is an example of input for our LSTM".lower())
لاحظ أن التسلسلات يجب أن تتكون من 40 حرفًا (وليس كلمات) حتى نتمكن من وضعها بسهولة في موتر من الشكل (57، 40، 1). قبل المضي قدمًا، فلنتحقق مما إذا كانت الدالة التي تم إنشاؤها تعمل بشكل صحيح.
def prepare_input(text):
x = np.zeros((1, WORD_LENGTH, len(unique_words)))
for t, word in enumerate(text.split()):
print(word)
x[0, t, unique_word_index[word]] = 1
return x
prepare_input("It is not a lack".lower())
array([[[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]]])
الآن سأقوم بإنشاء دالة لإرجاع العينات:
def sample(preds, top_n=3):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds)
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
return heapq.nlargest(top_n, range(len(preds)), preds.take)
والآن سأقوم بإنشاء دالة للتنبؤ بالكلمة التالية:
def predict_completion(text):
original_text = text
generated = text
completion = ''
while True:
x = prepare_input(text)
preds = model.predict(x, verbose=0)[0]
next_index = sample(preds, top_n=1)[0]
next_char = indices_char[next_index]
text = text[1:] + next_char
completion += next_char
if len(original_text + completion) + 2 > len(original_text) and next_char == ' ':
return completion
تم إنشاء هذه الدالة للتنبؤ بالكلمة التالية حتى يتم إنشاء مساحة. سيفعل ذلك عن طريق تكرار الإدخال، والذي سيطلب نموذج RNN الخاص بنا ويستخرج مثيلات منه. الآن سأقوم بتعديل الدالة المذكورة أعلاه للتنبؤ بأحرف متعددة:
def predict_completions(text, n=3):
x = prepare_input(text)
preds = model.predict(x, verbose=0)[0]
next_indices = sample(preds, n)
return [indices_char[idx] + predict_completion(text[1:] + indices_char[idx]) for idx in next_indices]
الآن سأستخدم التسلسل المكون من 40 حرفًا والذي يمكننا استخدامه كأساس لتوقعاتنا.
quotes =[
"It is not a lack of love, but a lack of friendship that makes unhappy marriages.",
"That which does not kill us makes us stronger.",
"I'm not upset that you lied to me, I'm upset that from now on I can't believe you.",
"And those who were seen dancing were thought to be insane by those who could not hear the music.",
"It is hard enough to remember my opinions, without also remembering my reasons for them!"
]
الآن أخيرًا، يمكننا استخدام النموذج للتنبؤ بالكلمة التالية:
for q in quotes:
seq = q[:40].lower()
print(seq)
print(predict_completions(seq, 5))
print()
it is not a lack of love, but a lack of
['the ', 'an ', 'such ', 'man ', 'present, ']
that which does not kill us makes us str
['ength ', 'uggle ', 'ong ', 'ange ', 'ive ']
i'm not upset that you lied to me, i'm u
['nder ', 'pon ', 'ses ', 't ', 'uder ']
and those who were seen dancing were tho
['se ', 're ', 'ugh ', ' servated ', 't ']it is hard enough to remember my opinion
[' of ', 's ', ', ', 'nof ', 'ed ']
أتمنى أن تكون قد أحببت هذا المقال من نموذج التنبؤ بالكلمة التالية.



