

- معالجة البيانات المفقودة باستخدام بايثون
- البيانات العددية المفقودة
- NaN و None في Pandas
- العمل على القيم الفارغة
- اكتشاف القيم الفارغة
- معالجة البيانات المفقودة عن طريق ملء القيم الخالية
هناك فرق كبير بين البيانات التي تحصل عليها لممارسة مهارات علم البيانات والبيانات التي تحصل عليها في العالم الحقيقي. بصراحة، ستأتي دائمًا العديد من مجموعات البيانات التي ستدخلها في عملية مهام علم البيانات في العالم الفعلي مع قدر من البيانات المفقودة missing data. أحيانًا يصبح الأمر صعبًا عندما تشير مصادر البيانات المختلفة إلى طرق مختلفة لفقدان البيانات.
في هذه المقالة، سأركز على معالجة البيانات المفقودة، وسأناقش كيف يمكننا القيام بذلك مع مكتبة pandas في بايثون. سينصب تركيزي فقط على الأدوات التي توفرها pandas للتعامل مع البيانات المفقودة.
معالجة البيانات المفقودة باستخدام بايثون
القيمة الأولى التي يستخدمها Pandas هي None. كائن مفرد من نوع بايثون يُستخدم غالبًا لفقدان البيانات في كود بايثون. نظرًا لأنه كائن بايثون، لا يمكن استخدام أي منها في أي مصفوفة عشوائية من NumPy / Pandas ، ولكن فقط في المصفوفات التي تحتوي على نوع بيانات “object ” (أي مصفوفات كائنات بايثون):
import numpy as np
import pandas as pd
vals1 = np.array([1, None, 3, 4])
vals1

يعني هذا النوع dtype = object أن أفضل تمثيل شائع للنوع يمكن أن يستدل عليه NumPy لمحتويات المصفوفة هو أنها كائنات بايثون. على الرغم من أن هذا النوع من مصفوفة الكائنات مفيد لبعض الأغراض، فإن أي عمليات على البيانات سيتم إجراؤها على مستوى بايثون، مع مقدار حمل أكبر بكثير من الإجراءات السريعة النموذجية التي يتم رؤيتها للمصفوفات ذات الأنواع الأصلية:
for dtype in ['object', 'int']:
print("dtype =", dtype)
%timeit np.arange(1E6, dtype=dtype).sum()
print()

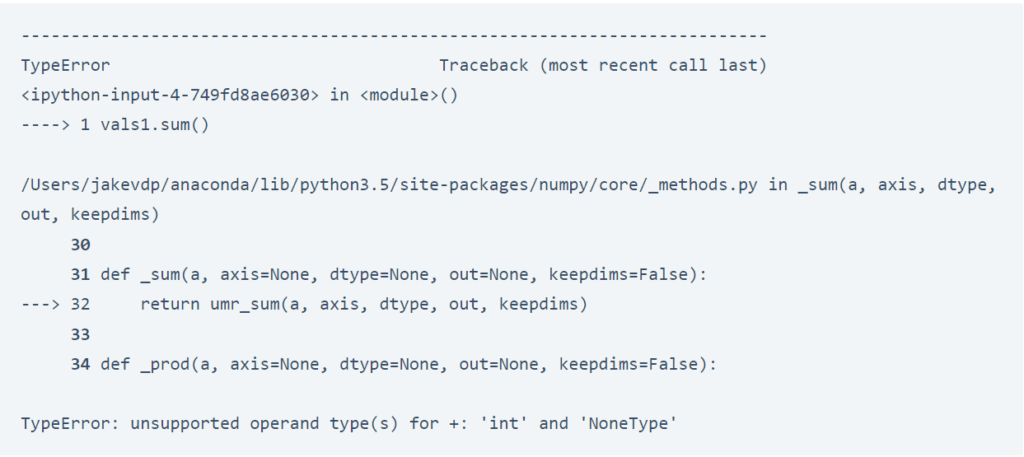
يعني استخدام كائنات بايثون في المصفوفة أيضًا أنك إذا أجريت تجميعات مثل sum() أو min() عبر مصفوفة بقيمة None ، فستتلقى خطأً بشكل عام:
vals1.sum()
البيانات العددية المفقودة
التمثيل الآخر للبيانات المفقودة ، NaN (اختصار لـ Not a Number) ، مختلف ؛ إنها قيمة نقطة عائمة معينة تتعرف عليها جميع الأنظمة التي تستخدم تمثيل النقطة العائمة IEEE القياسي:
vals2 = np.array([1, np.nan, 3, 4])
vals2.dtype

لاحظ أن NumPy اختار نوع النقطة العائمة الأصلي لهذه المصفوفة: هذا يعني أنه بخلاف مصفوفة الكائنات من قبل، تدعم هذه المصفوفة العمليات السريعة التي يتم دفعها إلى التعليمات البرمجية المترجمة. يجب أن تدرك أن nan يشبه إلى حد ما فيروسات البيانات – فهو يصيب أي كائن آخر يلمسه. بغض النظر عن العملية، ستكون نتيجة الحساب باستخدام NaN هي NaN أخرى:
1 + np.nan

0 * np.nan

لاحظ أن هذا يعني أن التجميعات aggregates فوق القيم محددة جيدًا (أي أنها لا تؤدي إلى خطأ) ولكنها ليست مفيدة دائمًا:
vals2.sum(), vals2.min(), vals2.max()

يوفر NumPy بعض التجميعات الخاصة التي ستتجاهل هذه القيم المفقودة:
np.nansum(vals2), np.nanmin(vals2), np.nanmax(vals2)

ضع في اعتبارك أن NaN هي على وجه التحديد قيمة فاصلة عائمة ؛ لا توجد قيمة NaN مكافئة للأعداد الصحيحة أو السلاسل أو الأنواع الأخرى.
NaN و None في Pandas
لكل من NaN و None مكانهما، وقد تم تصميم Pandas للتعامل مع الاثنين تقريبًا بالتبادل، والتحويل بينهما عند الاقتضاء:
pd.Series([1, np.nan, 2, None])

بالنسبة للأنواع التي ليس لها قيمة وهمية متاحة، يقوم Pandas تلقائيًا بالكتابة عند وجود قيم NA. على سبيل المثال ، إذا قمنا بتعيين قيمة في مصفوفة عدد صحيح على np.nan، فسيتم تلقائيًا تنشيطها إلى نوع النقطة العائمة لتلائم NA:
x = pd.Series(range(2), dtype=int)
x

x[0] = None
x

لاحظ أنه بالإضافة إلى تحويل المصفوفة الصحيحة إلى النقطة العائمة ، يقوم Pandas تلقائيًا بتحويل None إلى قيمة NaN.
العمل على القيم الفارغة
كما رأينا، يعامل بانداس None و NaN على أنهما قابلين للتبادل بشكل أساسي للإشارة إلى القيم المفقودة أو الفارغة. لتسهيل هذا الاصطلاح، هناك العديد من الطرق المفيدة لاكتشاف القيم الفارغة وإزالتها واستبدالها في هياكل بيانات Pandas. منها:
- isnull(): إنشاء قناع منطقي boolean mask يشير إلى القيم المفقودة.
- notnull(): عكس isnull() .
- dropna(): إرجاع نسخة مصفاة من البيانات.
- fillna(): إرجاع نسخة من البيانات بقيم مفقودة معبأة filled أو مضمنة imputed.
سنختتم هذا القسم باستكشاف موجز وعرض توضيحي لهذه الإجراءات.
اكتشاف القيم الفارغة
هياكل بيانات Pandas لها طريقتان مفيدتان للكشف عن البيانات الفارغة: isnull() و notnull(). سيعيد أحدهما قناعًا منطقيًا فوق البيانات. على سبيل المثال:
data = pd.Series([1, np.nan, 'hello', None])
data.isnull()

data[data.notnull()]

ينتج عن الطريقتين isnull() و notnull() نتائج منطقية مماثلة لـ DataFrames.
حذف القيم الفارغة
بالإضافة إلى القناع المستخدم من قبل، هناك طرق ملائمة ، dropna() (الذي يزيل قيم NA) و fillna() (الذي يملأ قيم NA). بالنسبة إلى Series، تكون النتيجة مباشرة:
data.dropna()

بالنسبة إلى DataFrame، هناك المزيد من الخيارات. ضع في اعتبارك DataFrame التالي:
df = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
df
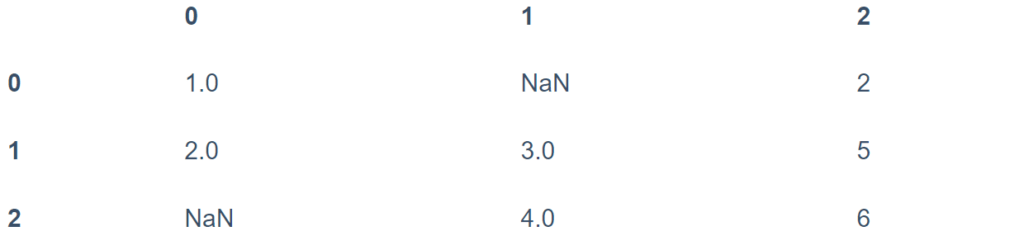
لا يمكننا إسقاط (حذف) قيم مفردة من DataFrame ؛ يمكننا فقط إسقاط صفوف كاملة أو أعمدة كاملة. اعتمادًا على التطبيق، قد ترغب في أحدهما أو الآخر، لذا فإن dropna() يوفر عددًا من الخيارات لـ DataFrame.
بشكل افتراضي ، يقوم dropna()بإسقاط جميع الصفوف التي توجد بها أي قيمة فارغة:
df.dropna()
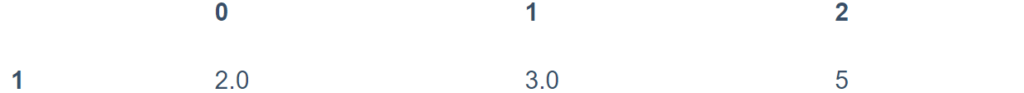
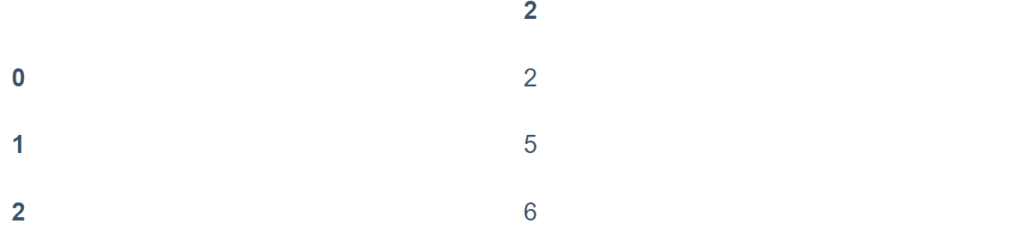
بدلاً من ذلك، يمكنك إسقاط قيم NA على طول محور مختلف ؛ axis=1 يسقط كل الأعمدة التي تحتوي على قيمة فارغة:
df.dropna(axis='columns')
لكن هذا يسقط بعض البيانات المفيدة أيضًا؛ قد تكون مهتمًا بدلاً من ذلك بإسقاط صفوف أو أعمدة بجميع قيم NA، أو غالبية قيم NA. يمكن تحديد ذلك من خلال معلمات how أو thresh ، والتي تسمح بالتحكم الممتاز في عدد القيم الخالية للسماح بالمرور.
الإعداد الافتراضي هو ‘how=any’ ، بحيث يتم إسقاط أي صف أو عمود (اعتمادًا على الكلمة الأساسية للمحور axis ) يحتوي على قيمة فارغة. يمكنك أيضًا تحديد كيفية ‘how=all’، والتي ستؤدي فقط إلى إسقاط الصفوف / الأعمدة التي تمثل جميعها قيمًا خالية:
df[3] = np.nan
df

df.dropna(axis='columns', how='all')
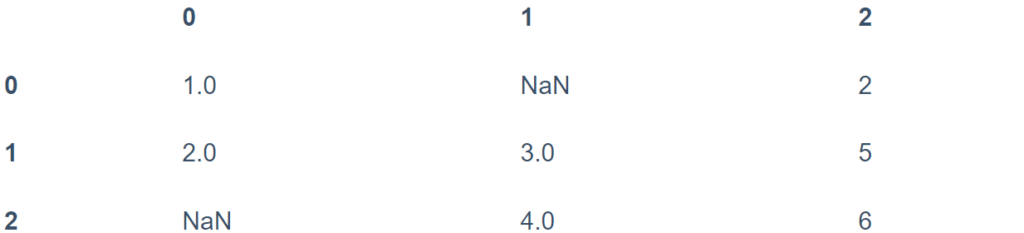
للتحكم الأكثر دقة، تتيح لك معلمة العتبة thresh تحديد الحد الأدنى لعدد القيم غير الخالية للصف / العمود المطلوب الاحتفاظ به:
df.dropna(axis='rows', thresh=3)

هنا تم إسقاط الصف الأول والأخير نظرًا لاحتوائهما على قيمتين غير فارغتين فقط.
معالجة البيانات المفقودة عن طريق ملء القيم الفارغة
في بعض الأحيان بدلاً من إسقاط قيم NA، تفضل استبدالها بقيمة صالحة. قد تكون هذه القيمة رقمًا واحدًا مثل الصفر، أو قد تكون نوعًا من التضمين imputation أو الاستيفاء interpolation من القيم الجيدة.
يمكنك القيام بذلك في مكانه باستخدام طريقة isnull() كقناع ، ولكن نظرًا لأنها عملية شائعة توفر Pandas طريقة fillna() ، التي تُرجع نسخة من المصفوفة مع استبدال القيم الخالية.
ضع في اعتبارك السلسلة Series التالية:
data = pd.Series([1, np.nan, 2, None, 3], index=list('abcde'))
data

يمكننا ملء إدخالات NA بقيمة واحدة، مثل الصفر:
data.fillna(0)

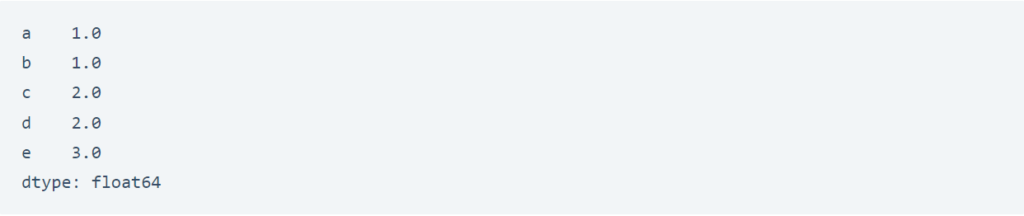
يمكننا تحديد تعبئة إلى الأمام forward-fill لنشر القيمة السابقة إلى الأمام:
# forward-fill
data.fillna(method='ffill')
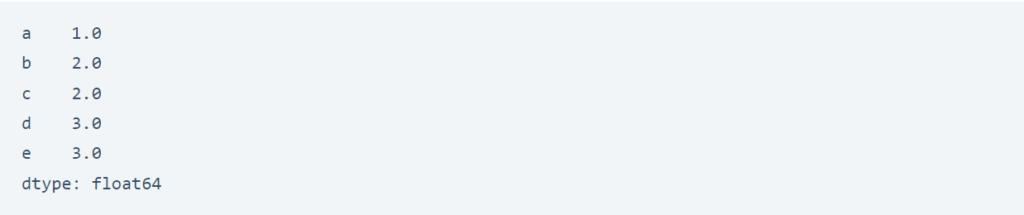
أو يمكننا تحديد التعبئة الخلفية back-fill لنشر القيم التالية للخلف:
# back-fill
data.fillna(method='bfill')
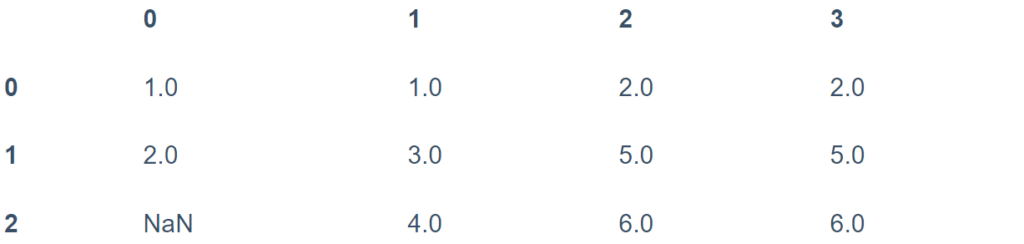
بالنسبة إلى DataFrames ، تكون الخيارات متشابهة ، ولكن يمكننا أيضًا تحديد محور axis تتم على طوله عمليات التعبئة:
df

df.fillna(method='ffill', axis=1)
آمل أن تكون قد أحببت هذه المقالة حول التعامل مع البيانات المفقودة.



