
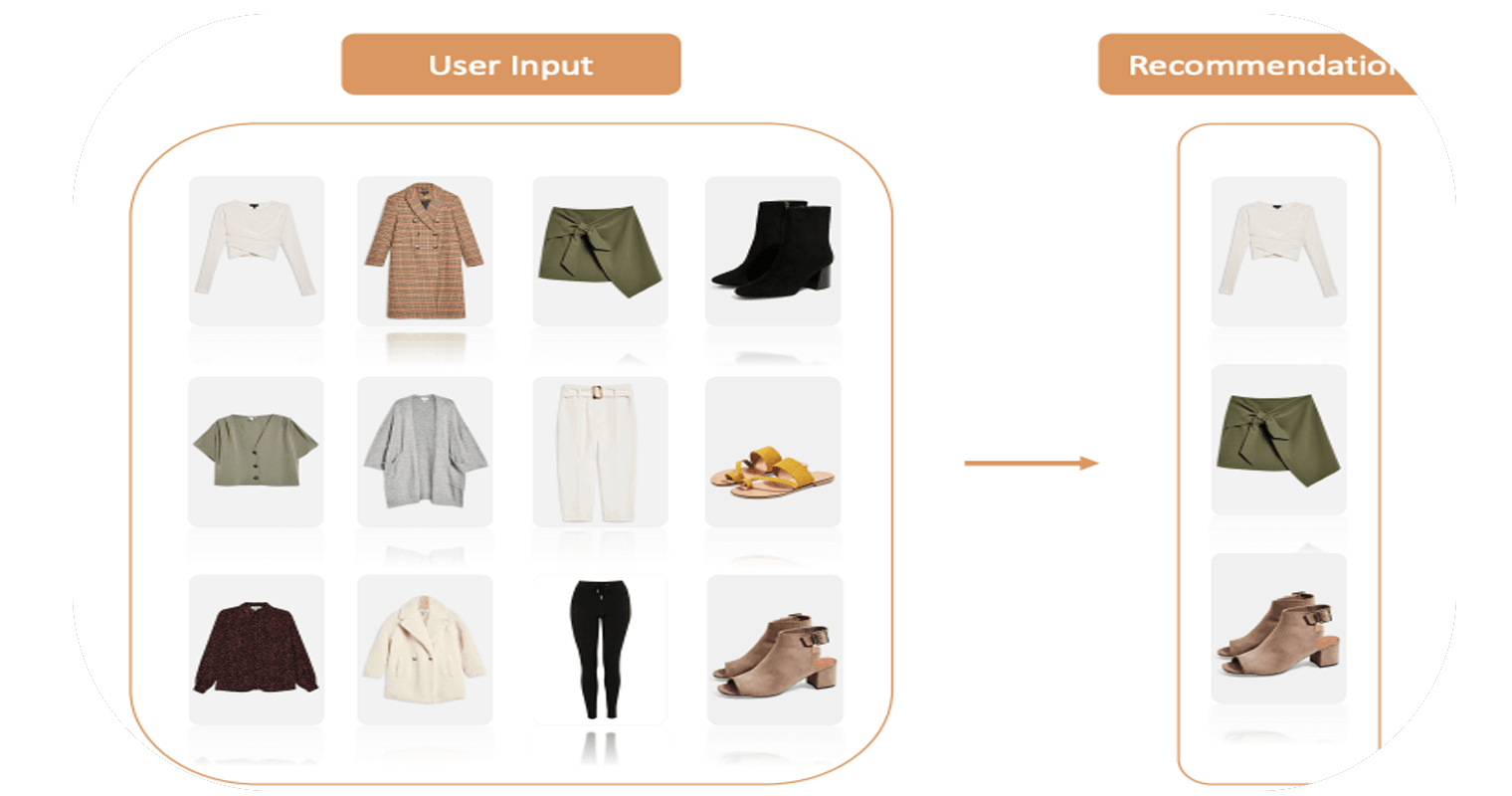
- نظام توصية للأزياء مع التعلم العميق
- اختبار نظام توصية للأزياء
في هذه المقالة، سوف أطلعك على كيفية إنشاء نظام توصية للأزياء باستخدام التعلم الآلي الذي سيعمل مثل توصيات التسوق عبر الإنترنت المخصصة للغاية. ولكن قبل المضي قدمًا، عليك أن تعرف ما هو نظام التوصية recommendation system.
نظام التوصية هو نظام مبرمج للتنبؤ بالعناصر المفضلة في المستقبل من مجموعة كبيرة من المجموعات. يعمل نظام التوصية إما باستخدام تفضيلات المستخدم أو باستخدام العناصر الأكثر تفضيلاً من قبل جميع المستخدمين. التحدي الرئيسي في بناء نظام توصية للأزياء هو أنها صناعة ديناميكية للغاية. يتغير كثيرًا عندما يتعلق الأمر بالمواسم والمهرجانات والظروف الوبائية مثل فيروس كورونا وغيرها الكثير.
نظام توصية للأزياء مع التعلم العميق
على عكس المجالات الأخرى، لا ينبغي أن تستند توصيات الأزياء فقط على الذوق الشخصي والنشاط السابق للعميل. هناك العديد من العوامل الخارجية (العديد منها عاطفية) التي تجعل إنشاء نظام توصية للأزياء أكثر تعقيدًا. يجب أن تؤخذ التصورات العامة في الاعتبار، وكذلك قواعد الموضة وقواعد اللباس والتوجهات الحالية.
دعنا نتعمق الآن في بناء نظام توصية للأزياء باستخدام التعلم الآلي. سأبدأ ببساطة باستيراد جميع الحزم التي نحتاجها لهذه المهمة:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import gdown
from fastai.vision import *
from fastai.metrics import accuracy, top_k_accuracy
from annoy import AnnoyIndex
import zipfile
import time
from google.colab import drive
%matplotlib inline
الآن، تحتاج إلى جمع البيانات في محرك google الخاص بك، وعليك لصق عناوين URL لهذه الروابط لاستيراد مجموعة البيانات في دفتر ملاحظاتك:
# get the meta data
url = 'https://drive.google.com/uc?id=0B7EVK8r0v71pWnFiNlNGTVloLUk'
output = 'list_category_cloth.txt'
gdown.download(url, output, quiet=False)
url = 'https://drive.google.com/uc?id=0B7EVK8r0v71pTGNoWkhZeVpzbFk'
output = 'list_category_img.txt'
gdown.download(url, output, quiet=False)
url = 'https://drive.google.com/uc?id=0B7EVK8r0v71pdS1FMlNreEwtc1E'
output = 'list_eval_partition.txt'
gdown.download(url, output, quiet=False)
الآن، دعنا نحصل على جميع الصور من محرك google الخاص بنا:
# get the images
root_path = './'
url = 'https://drive.google.com/uc?id=1j5fCPgh0gnY6v7ChkWlgnnHH6unxuAbb'
output = 'img.zip'
gdown.download(url, output, quiet=False)
with zipfile.ZipFile("img.zip","r") as zip_ref:
zip_ref.extractall(root_path)
سأقوم الآن ببعض خطوات تحضير البيانات وتنظيف البيانات لتأطير البيانات بطريقة مفيدة:
category_list = []
image_path_list = []
data_type_list = []
# category names
with open('list_category_cloth.txt', 'r') as f:
for i, line in enumerate(f.readlines()):
if i > 1:
category_list.append(line.split(' ')[0])
# category map
with open('list_category_img.txt', 'r') as f:
for i, line in enumerate(f.readlines()):
if i > 1:
image_path_list.append([word.strip() for word in line.split(' ') if len(word) > 0])
# train, valid, test
with open('list_eval_partition.txt', 'r') as f:
for i, line in enumerate(f.readlines()):
if i > 1:
data_type_list.append([word.strip() for word in line.split(' ') if len(word) > 0])
data_df = pd.DataFrame(image_path_list, columns=['image_path', 'category_number'])
data_df['category_number'] = data_df['category_number'].astype(int)
data_df = data_df.merge(pd.DataFrame(data_type_list, columns=['image_path', 'dataset_type']), on='image_path')
data_df['category'] = data_df['category_number'].apply(lambda x: category_list[int(x) - 1])
data_df = data_df.drop('category_number', axis=1)
الآن، سيقوم الكود أدناه بتحويل جميع الصور إلى التضمينات embeddings:
train_image_list = ImageList.from_df(df=data_df, path=root_path, cols='image_path').split_by_idxs(
(data_df[data_df['dataset_type']=='train'].index),
(data_df[data_df['dataset_type']=='val'].index)).label_from_df(cols='category')
test_image_list = ImageList.from_df(df=data_df[data_df['dataset_type'] == 'test'], path=root_path, cols='image_path')
data = train_image_list.transform(get_transforms(), size=224).databunch(bs=128).normalize(imagenet_stats)
data.add_test(test_image_list)
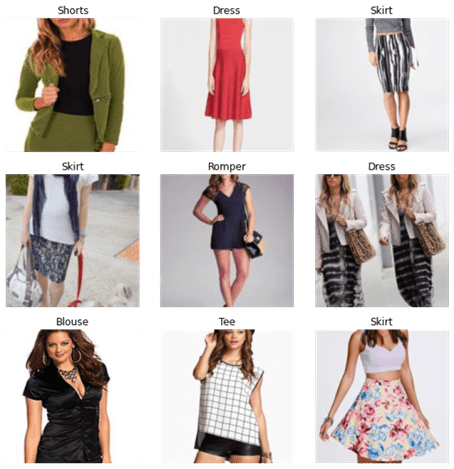
data.show_batch(rows=3, figsize=(8,8))
الآن، سأقوم ببعض الخطوات لنقل التعلم باستخدام مكتبة resnet و PyTorch للحصول على معدل التعلم:
# More layers are generally more accurate but take longer to train: resnet18, resnet34, resnet50, resnet101, resnet152
# get top 1 and top 5 accuracy
def train_model(data, pretrained_model, model_metrics):
learner = cnn_learner(data, pretrained_model, metrics=model_metrics)
learner.model = torch.nn.DataParallel(learner.model)
learner.lr_find()
learner.recorder.plot(suggestion=True)
return learner
pretrained_model = models.resnet18 # simple model that can be trained on free tier
# pretrained_model = models.resnet50 # need pro tier, model I used
model_metrics = [accuracy, partial(top_k_accuracy, k=1), partial(top_k_accuracy, k=5)]
learner = train_model(data, pretrained_model, model_metrics)
learner.fit_one_cycle(10, max_lr=1e-02)
الآن، دعنا نقيم نموذج نقل التعلم:
interp = ClassificationInterpretation.from_learner(learner)
interp.plot_top_losses(9, largest=False, figsize=(15,11), heatmap_thresh=5)

يبدو الناتج جيدًا، الآن قبل المضي قدمًا، دعنا نحفظ هذا النموذج حتى نتمكن من استخدامه بسهولة لمهامنا المستقبلية:
# saving the model (temporary, will lose model once environment resets)
learner.save('resnet-fashion')
الآن، سأستخدم طريقة FastAI لاسترداد صور التضمينات:
class SaveFeatures():
features=None
def __init__(self, m):
self.hook = m.register_forward_hook(self.hook_fn)
self.features = None
def hook_fn(self, module, input, output):
out = output.detach().cpu().numpy()
if isinstance(self.features, type(None)):
self.features = out
else:
self.features = np.row_stack((self.features, out))
def remove(self):
self.hook.remove()
# load the trained model
def load_learner(data, pretrained_model, model_metrics, model_path):
learner = cnn_learner(data, pretrained_model, metrics=model_metrics)
learner.model = torch.nn.DataParallel(learner.model)
learner = learner.load(model_path)
return learner
pretrained_model = models.resnet18 # simple model that can be trained on free tier
# pretrained_model = models.resnet50 # need pro tier
model_metrics = [accuracy, partial(top_k_accuracy, k=1), partial(top_k_accuracy, k=5)]
# if gdrive not mounted:
drive.mount('/content/gdrive')
model_path = "/content/gdrive/My Drive/resnet18-fashion"
# model_path = "/content/gdrive/My Drive/resnet50-fashion"
learner = load_learner(data, pretrained_model, model_metrics, model_path)
أتمنى أن تكون قد فهمت شيئًا من العملية المذكورة أعلاه، والآن سأستخدم طريقة أقرب جيران nearest neighbours لإنشاء نظام توصية للأزياء:
# takes time to populate the embeddings for each image
# Get 2nd last layer of the model that stores the embedding for the image representations
# the last linear layer is the output layer.
saved_features = SaveFeatures(learner.model.module[1][4])
_= learner.get_preds(data.train_ds)
_= learner.get_preds(DatasetType.Valid)
أخيرًا، نقوم بإدراج عمليات التضمين الخاصة بـ 12 عنصرًا (أو أكثر) من تحديد المستخدم في قائمة ومتوسط قيم التضمينات في كل من الأبعاد؛ يؤدي هذا إلى إنشاء كائن شبح ghost object يمثل القيمة الإجمالية لجميع العناصر المحددة.
يمكننا بعد ذلك العثور على أقرب جار لهذا الكائن الشبح:
# prepare the data for generating recommendations (exlcude test data)
# get the embeddings from trained model
img_path = [str(x) for x in (list(data.train_ds.items) +list(data.valid_ds.items))]
label = [data.classes[x] for x in (list(data.train_ds.y.items) +list(data.valid_ds.y.items))]
label_id = [x for x in (list(data.train_ds.y.items) +list(data.valid_ds.y.items))]
data_df_ouput = pd.DataFrame({'img_path': img_path, 'label': label, 'label_id': label_id})
data_df_ouput['embeddings'] = np.array(saved_features.features).tolist()
# Using Spotify's Annoy
def get_similar_images_annoy(annoy_tree, img_index, number_of_items=12):
start = time.time()
img_id, img_label = data_df_ouput.iloc[img_index, [0, 1]]
similar_img_ids = annoy_tree.get_nns_by_item(img_index, number_of_items+1)
end = time.time()
print(f'{(end - start) * 1000} ms')
# ignore first item as it is always target image
return img_id, img_label, data_df_ouput.iloc[similar_img_ids[1:]]
# for images similar to centroid
def get_similar_images_annoy_centroid(annoy_tree, vector_value, number_of_items=12):
start = time.time()
similar_img_ids = annoy_tree.get_nns_by_vector(vector_value, number_of_items+1)
end = time.time()
print(f'{(end - start) * 1000} ms')
# ignore first item as it is always target image
return data_df_ouput.iloc[similar_img_ids[1:]]
def show_similar_images(similar_images_df, fig_size=[10,10], hide_labels=True):
if hide_labels:
category_list = []
for i in range(len(similar_images_df)):
# replace category with blank so it wont show in display
category_list.append(CategoryList(similar_images_df['label_id'].values*0,
[''] * len(similar_images_df)).get(i))
else:
category_list = [learner.data.train_ds.y.reconstruct(y) for y in similar_images_df['label_id']]
return learner.data.show_xys([open_image(img_id) for img_id in similar_images_df['img_path']],
category_list, figsize=fig_size)
# more tree = better approximation
ntree = 100
#"angular", "euclidean", "manhattan", "hamming", or "dot"
metric_choice = 'angular'
annoy_tree = AnnoyIndex(len(data_df_ouput['embeddings'][0]), metric=metric_choice)
# # takes a while to build the tree
for i, vector in enumerate(data_df_ouput['embeddings']):
annoy_tree.add_item(i, vector)
_ = annoy_tree.build(ntree)
اختبار نظام توصية للأزياء
الآن، دعنا نختبر نظام توصيات الأزياء لدينا. لهذا، نحتاج إلى إنشاء بعض الرموز. أولاً، دعنا نرى التوصيات لأي شيء يتعلق بالسراويل القصيرة “shorts”:
def centroid_embedding(outfit_embedding_list):
number_of_outfits = outfit_embedding_list.shape[0]
length_of_embedding = outfit_embedding_list.shape[1]
centroid = []
for i in range(length_of_embedding):
centroid.append(np.sum(outfit_embedding_list[:, i])/number_of_outfits)
return centroid
# shorts
outfit_img_ids = [109938, 106385, 113703, 98666, 113467, 120667, 20840, 8450, 142843, 238607, 124505,222671]
outfit_embedding_list = []
for img_index in outfit_img_ids:
outfit_embedding_list.append(data_df_ouput.iloc[img_index, 3])
outfit_embedding_list = np.array(outfit_embedding_list)
outfit_centroid_embedding = centroid_embedding(outfit_embedding_list)
outfits_selected = data_df_ouput.iloc[outfit_img_ids]
similar_images_df = get_similar_images_annoy_centroid(annoy_tree, outfit_centroid_embedding, 30)
وأخيرًا، سنرى توصيات “السراويل القصيرة”:

هذه استجابة جيدة جدًا من نموذجنا. آمل أن تكون قد أحببت هذه المقالة حول نظام توصية الموضة مع التعلم العميق.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.