
- نموذج التنبؤ بالزلازل مع التعلم العميق
- العرض المرئي للبيانات
- تقسيم مجموعة البيانات
- الشبكة العصبية للتنبؤ بالزلازل
في هذه المقالة، سأطلعك على كيفية إنشاء نموذج لمهمة توقع الزلازل باستخدام التعلم الآلي ولغة برمجة بايثون. يعد التنبؤ بالزلازل أحد أكبر المشكلات التي لم يتم حلها في علوم الأرض.
مع زيادة استخدام التكنولوجيا، زادت العديد من محطات المراقبة الزلزالية، لذلك يمكننا استخدام التعلم الآلي والأساليب الأخرى التي تعتمد على البيانات للتنبؤ بالزلازل.
نموذج التنبؤ بالزلازل مع التعلم الآلي
من المعروف أنه إذا حدثت كارثة في منطقة ما، فمن المحتمل أن تحدث مرة أخرى. بعض المناطق بها زلازل متكررة، ولكن هذا ليس سوى كمية مقارنة بالمقارنة مع المناطق الأخرى.
لذلك، فإن التنبؤ بالزلزال مع التاريخ والوقت وخط العرض وخط الطول من البيانات السابقة ليس اتجاهًا يتبع مثل الأشياء الأخرى، إنه يحدث بشكل طبيعي.
سأبدأ هذه المهمة لإنشاء نموذج للتنبؤ بالزلازل عن طريق استيراد مكتبات بايثون الضرورية:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
فلنقم الآن بتحميل مجموعة البيانات وقراءتها. يمكن تنزيل مجموعة البيانات التي أستخدمها هنا بسهولة من هنا:
</p>
data = pd.read_csv("database.csv")
data.columns
<p></p>
Index(['Date', 'Time', 'Latitude', 'Longitude', 'Type', 'Depth', 'Depth Error',
'Depth Seismic Stations', 'Magnitude', 'Magnitude Type',
'Magnitude Error', 'Magnitude Seismic Stations', 'Azimuthal Gap',
'Horizontal Distance', 'Horizontal Error', 'Root Mean Square', 'ID',
'Source', 'Location Source', 'Magnitude Source', 'Status'],
dtype='object')
<p>الآن دعنا نرى الخصائص الرئيسية لبيانات الزلازل وننشئ كائنًا من هذه الخصائص، أي التاريخ dateوالوقت time وخط العرض latitude وخط الطول longitude والعمق depth والحجم magnitude:
</p>
data = data [['Date'، 'Time'، 'Latitude'، 'Longitude'، 'Depth'، 'Magnitude']]
data.head ()
<p>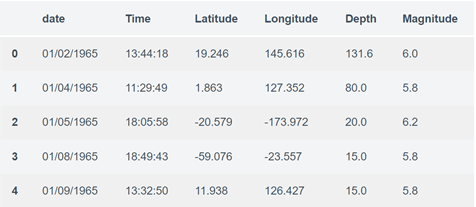
نظرًا لأن البيانات عشوائية، فنحن بحاجة إلى قياسها بناءً على مدخلات النموذج. في هذا، نقوم بتحويل التاريخ والوقت المحددين إلى وقت Unix وهو بالثواني ورقم. يمكن استخدام هذا بسهولة كمدخل للشبكة التي أنشأناها:
</p>
import datetime
import time
timestamp = []
for d, t in zip(data['Date'], data['Time']):
try:
ts = datetime.datetime.strptime(d+' '+t, '%m/%d/%Y %H:%M:%S')
timestamp.append(time.mktime(ts.timetuple()))
except ValueError:
# print('ValueError')
timestamp.append('ValueError')
timeStamp = pd.Series(timestamp)
data['Timestamp'] = timeStamp.values
final_data = data.drop(['Date', 'Time'], axis=1)
final_data = final_data[final_data.Timestamp != 'ValueError']
final_data.head()
<p>
العرض المرئي للبيانات
الآن، قبل إنشاء نموذج التنبؤ بالزلازل، دعنا نرسم البيانات الموجودة على خريطة العالم التي تعرض تمثيلًا واضحًا لمكان تواتر الزلزال:
</p>
from mpl_toolkits.basemap import Basemap
m = Basemap(projection='mill',llcrnrlat=-80,urcrnrlat=80, llcrnrlon=-180,urcrnrlon=180,lat_ts=20,resolution='c')
longitudes = data["Longitude"].tolist()
latitudes = data["Latitude"].tolist()
#m = Basemap(width=12000000,height=9000000,projection='lcc',
#resolution=None,lat_1=80.,lat_2=55,lat_0=80,lon_0=-107.)
x,y = m(longitudes,latitudes)
fig = plt.figure(figsize=(12,10))
plt.title("All affected areas")
m.plot(x, y, "o", markersize = 2, color = 'blue')
m.drawcoastlines()
m.fillcontinents(color='coral',lake_color='aqua')
m.drawmapboundary()
m.drawcountries()
plt.show()
<p>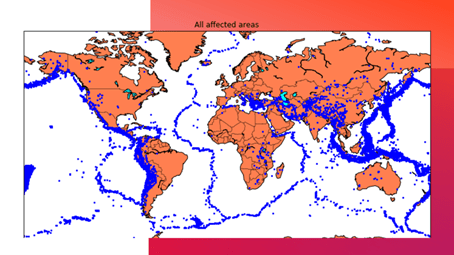
تقسيم مجموعة البيانات
الآن، لإنشاء نموذج التنبؤ بالزلازل، نحتاج إلى تقسيم البيانات إلى Xs و ys والتي سيتم إدخالها على التوالي في النموذج كمدخلات لتلقي الإخراج من النموذج.
المدخلات هنا هي TImestamp وLatitude وLongitude والمخرجات هي Magnitude وDepth. سأقوم بتقسيم x وy إلى تدريب train واختبار test مع التحقق من الصحة validation. تحتوي مجموعة التدريب على 80٪ ومجموعة الاختبار تحتوي على 20٪:
</p>
X = final_data[['Timestamp', 'Latitude', 'Longitude']]
y = final_data[['Magnitude', 'Depth']]
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, X_test.shape)
<p></p>
(18727, 3) (4682, 3) (18727, 2) (4682, 3)
<p>الشبكة العصبية للتنبؤ بالزلازل
الآن سوف أقوم بإنشاء شبكة عصبية لتناسب البيانات من مجموعة التدريب. ستتألف شبكتنا العصبية من ثلاث طبقات كثيفة dense layers تحتوي كل منها على 16 و16 و2 عقدة وتعيد قراءتها. سيتم استخدام Relu وsoftmax كدوال تنشيط:
</p>
from keras.models import Sequential
from keras.layers import Dense
def create_model(neurons, activation, optimizer, loss):
model = Sequential()
model.add(Dense(neurons, activation=activation, input_shape=(3,)))
model.add(Dense(neurons, activation=activation))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
<p>سأقوم الآن بتحديد المعلمات الفائقة hyperparameters بخيارين أو أكثر للعثور على أفضل ملاءمة best fit:
</p>
from keras.wrappers.scikit_learn import KerasClassifier
model = KerasClassifier(build_fn=create_model, verbose=0)
# neurons = [16, 64, 128, 256]
neurons = [16]
# batch_size = [10, 20, 50, 100]
batch_size = [10]
epochs = [10]
# activation = ['relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear', 'exponential']
activation = ['sigmoid', 'relu']
# optimizer = ['SGD', 'RMSprop', 'Adagrad', 'Adadelta', 'Adam', 'Adamax', 'Nadam']
optimizer = ['SGD', 'Adadelta']
loss = ['squared_hinge']
param_grid = dict(neurons=neurons, batch_size=batch_size, epochs=epochs, activation=activation, optimizer=optimizer, loss=loss)
<p>نحتاج الآن إلى العثور على أفضل نموذج ملائم للنموذج أعلاه والحصول على متوسط درجة الاختبار والانحراف المعياري لأفضل نموذج مناسب:
</p>
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1)
grid_result = grid.fit(X_train, y_train)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
<p></p>
Best: 0.957655 using {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.333316 (0.471398) with: {'activation': 'sigmoid', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.000000 (0.000000) with: {'activation': 'sigmoid', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'Adadelta'} 0.957655 (0.029957) with: {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.645111 (0.456960) with: {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'Adadelta'}
<p>في الخطوة أدناه، يتم استخدام أفضل المعلمات الملائمة لنفس النموذج لحساب النتيجة باستخدام بيانات التدريب وبيانات الاختبار:
</p>
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(3,)))
model.add(Dense(16, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='SGD', loss='squared_hinge', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=10, epochs=20, verbose=1, validation_data=(X_test, y_test))
[test_loss, test_acc] = model.evaluate(X_test, y_test)
print("Evaluation result on Test Data : Loss = {}, accuracy = {}".format(test_loss, test_acc))
<p></p>
Evaluation result on Test Data : Loss = 0.5038455790406056, accuracy = 0.9241777017858995
<p>لذلك يمكننا أن نرى في الناتج أعلاه أن نموذج الشبكة العصبية الخاص بنا للتنبؤ بالزلازل يعمل بشكل جيد. آمل أن تكون قد أحببت هذه المقالة حول كيفية إنشاء نموذج التنبؤ بالزلازل باستخدام التعلم الآلي ولغة برمجة بايثون.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.