- مقدمة
- الخطوة 1
- الخطوة 2
- الخطوة 3
- الخطوة 4
- الخطوة 5
- الخطوة 6
- الخطوة 7
- الخطوة 8
- الخطوة 9
- الخطوة 10
مقدمة
قبل أيام قليلة، صادفت سؤالًا عن “Quora” اختصر في: “كيف يمكنني تعلم معالجة اللغة الطبيعية في أربعة أشهر فقط؟”. ثم بدأت في كتابة رد موجز. ومع ذلك، سرعان ما تحول إلى شرح مفصل للنهج التربوي الذي استخدمته، وباستخدام هذا النهج ، كيف قمت بالانتقال من خبير في الهندسة الميكانيكية إلى متحمس لمعالجة اللغة الطبيعية (NLP).
ستناقش هذه المقالة خارطة طريق معالجة اللغة الطبيعية (NLP) الكاملة للمبتدئين. سيكون الأمر مختلفًا بعض الشيء فيما يتعلق بالمقالات الأخرى.
أحد أسباب ارتباك المبتدئين عند تعلم المعالجة اللغوية العصبية هو أنهم لا يعرفون ماذا يتعلمون من أين وكيف؟ هناك الكثير من الخيارات للدورات والكتب وخوارزميات البرمجة اللغوية العصبية.
سوف أشارك مجموعة من الخطوات التي يجب عليك اتخاذها لإتقان المعالجة اللغوية الطبيعية.
دعونا نفهم أولاً، ما هو معالجة اللغة الطبيعية؟
المعالجة اللغوية الطبيعية (NLP) هي مجال البحث في الذكاء الاصطناعي الذي يركز بشكل أساسي على معالجة واستخدام بيانات النص والكلام لإنشاء آلات ذكية وإنشاء رؤى من البيانات.
المتطلبات الأساسية لاتباع خارطة الطريق بشكل فعال
- الفكرة الأساسية للغة برمجة بايثون.
- فكرة بسيطة عن خوارزميات التعلم الآلي والعميق.
تم استخدام المكتبات أثناء اتباع خارطة الطريق:
- Natural Language Toolkit (NLTK),
- spaCy,
- Core NLP,
- Text Blob,
- PyNLPI,
- Gensim,
- Pattern, etc.
لنبدأ خطوة بخطوة
الخطوة 1
معالجة النص من المستوى الأول:
- الترميز Tokenization ،
- اللماتة Lemmatization ،
- التجذير Stemming ،
- أجزاء من الكلام (POS) Parts of Speech ،
- إزالة كلمات التوقف Stopwords ،
- إزالة علامات الترقيم Punctuation ، إلخ.
الوصف
في معالجة اللغة الطبيعية، لدينا البيانات النصية، والتي لا تستطيع خوارزميات التعلم الآلي الخاصة بنا استخدامها بشكل مباشر، لذلك يتعين علينا أولاً معالجتها مسبقًا ثم تغذية البيانات المُعالجة مسبقًا إلى خوارزميات التعلم الآلي الخاصة بنا. لذلك، في هذه الخطوة، سنحاول تعلم نفس خطوات المعالجة الأساسية التي يتعين علينا تنفيذها في كل مشكلة من مشكلات معالجة اللغة الطبيعية تقريبًا.
الخطوة 2
مستوى متقدم لتنظيف النص
- التطبيع Normalization ،
- تصحيح الأخطاء المطبعية Correction of Typos ، إلخ.
الوصف
هذه بعض التقنيات المتقدمة التي تساعد بياناتنا النصية على إعطاء نموذجنا أداءً أفضل. دعنا نأخذ فهمًا متقدمًا لبعض هذه التقنيات بشكل مباشر.
التطبيع Normalization: عيّن الكلمات لكلمة لغة ثابتة.
على سبيل المثال، لنحصل على كلمات مثل b4 ، ttyl والتي ، وفقًا للبشر ، يمكن فهمها على أنها “قبل before ” و “التحدث إليك لاحقًا “talk to you later ” على التوالي. ومع ذلك، لا تستطيع الآلات فهم هذه الكلمات بالطريقة نفسها، لذلك يتعين علينا ربط هذه الكلمات بكلمة لغة معينة. تُعرف هذه الخريطة باسم التطبيع.
تصحيح الأخطاء المطبعية Correction of typos: هناك الكثير من الأخطاء في كتابة نص باللغة الإنجليزية أو نصوص بلغات أخرى، مثل Fen بدلاً من Fan. تستلزم المطابقة الدقيقة استخدام قاموس استخدمناه لتعيين الكلمات إلى أشكالها الصحيحة بناءً على التشابه. تصحيح الأخطاء المطبعية هو المصطلح المستخدم لهذا الإجراء.
ملاحظة: هذه ليست سوى بعض الأساليب التي وصفتها، ولكن عليك تحديث معرفتك من خلال تعلم طرق مختلفة بانتظام.
الخطوه 3
معالجة النص من المستوى 2
- حقيبة الكلمات (BOW) Bag of words ،
- تردد المصطلح-معكوس تردد الوثيقة (TF-IDF) ،
- Unigram و Bigram و Ngrams.
الوصف:
كل هذه هي الطرق الأساسية لتحويل بيانات النص الخاصة بنا إلى بيانات رقمية (متجهات Vectors) لتطبيق خوارزمية التعلم الآلي عليها.
الخطوة 4
معالجة النصوص من المستوى 3
- Word2vec ،
- متوسط word2vec.
الوصف
كل هذه تقنيات متقدمة لتحويل الكلمات إلى متجهات.
الخطوة 5
خبرة عملية في حالة الاستخدام
الوصف
بعد اتباع جميع الخطوات المذكورة أعلاه ، الآن في هذه الخطوة ، يمكنك تنفيذ حالة استخدام NLP نموذجية أو مباشرة باستخدام خوارزميات التعلم الآلي مثل Naive Bayes Classifier، إلخ. للحصول على فهم واضح لكل ما سبق وفهم الخطوات التالية.
الخطوة 6
احصل على فهم مستوى متقدم للشبكة العصبية الاصطناعية
الوصف
أثناء التعمق في المعالجة اللغوية العصبية (NLP) ، لا تأخذ الشبكة العصبية الاصطناعية (ANN) بعيدًا جدًا عن وجهة نظرك ؛ عليك أن تعرف خوارزميات التعلم العميق الأساسية ، بما في ذلك الانتشار الخلفي backpropagation ، والانحدار الاشتقاقي gradient descent، وما إلى ذلك.
لإكمال هذه الخطوة، علينا اكتساب المعرفة الأساسية بالتعلم العميق Deep learning، الشبكات العصبية الاصطناعية بشكل أساسي neural networks.
Introduction to Deep Learning and Neural Networks
Optimization Algorithms for Deep Learning
الخطوة 7
نماذج التعلم العميق
الشبكات العصبية المتكررة (RNN) Recurrent Neural Networks ،
رابط لفيديو يوتيوب: https://youtu.be/UNmqTiOnRfg
ذاكرة طويلة قصيرة المدى (LSTM) Long Short Term Memory ،
وحدة البوابات المتكررة (GRU) Gated Recurrent Unit.
الوصف
يتم استخدام RNN بشكل أساسي عندما يكون لدينا تسلسل البيانات في متناول اليد، وعلينا تحليل تلك البيانات. سوف نفهم LSTM و GRU، الموضوعات الناجحة من الناحية المفاهيمية بعد RNN.
الخطوة 8
معالجة النصوص من المستوى 4
👉 تضمين الكلمة Word Embedding.
👉 Word 2 Vec
الوصف
الآن، يمكننا القيام بمشاريع متوسطة المستوى تتعلق بالمعالجة اللغوية العصبية وجعل محترفًا في هذا المجال. فيما يلي بعض الخطوات التي ستميزك عن الأشخاص الآخرين الذين عملوا أيضًا في هذا المجال. لذا، فإن التفوق على كل هؤلاء الأشخاص الذين يتعلمون هذه الموضوعات أمر لا بد منه.
الخطوة 9
- ثنائي الاتجاه LSTM RNN (Bidirectional LSTM RNN)،
- المشفرات Encoders ومفككات التشفير Decoders ،
- نماذج الانتباه الذاتي Self-attention models.
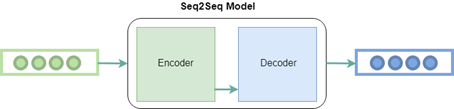
الخطوة 10
- المحولات Transformers.
رابط للفيديو: https://youtu.be/qqt3aMPB81c
الوصف
المحول في المعالجة اللغوية العصبية هو بنية تسعى إلى التعامل مع مهام التسلسل إلى التسلسل أثناء التعامل مع العلاقات طويلة المدى بسهولة. إنها تستفيد من نماذج الاهتمام الذاتي.
الخطوة 11
BERT (تمثيلات الترميز ثنائي الاتجاه من المحولات Bidirectional Encoder Representations from Transformers)
الوصف
إنه نوع من المحولات، وهو يحول الجملة إلى متجه. إنها تقنية قائمة على الشبكة العصبية تستخدم في التدريب المسبق على معالجة اللغة الطبيعية.
هذا يكمل خارطة الطريق لتصبح خبيرًا في المعالجة اللغوية العصبية في عام 2022!