- بيان المشكلة لتنبؤ بسعر الكمبيوتر المحمول
- مجموعة بيانات لتنبؤ بأسعار أجهزة الكمبيوتر المحمول
- الفهم الأساسي لبيانات التنبؤ بسعر الكمبيوتر المحمول
- تحليل البيانات الاستكشافية لمجموعة بيانات توقع أسعار أجهزة الكمبيوتر المحمول
- 1) توزيع العمود الهدف
- 2) عمود الشركة Company column
- 3) نوع الكمبيوتر المحمول
- 4) هل يختلف السعر باختلاف حجم الكمبيوتر المحمول بالبوصة؟
- هندسة الميزات والمعالجة المسبقة لنموذج التنبؤ بسعر الكمبيوتر المحمول
- 5) دقة الشاشة
- استخراج معلومات شاشة اللمس
- استخراج معلومات وجود قناة IPS
- استخراج أبعاد دقة الشاشة المحور X والمحور Y
- استبدال دقة البوصة، X و Y بـ PPI
- 6) عمود وحدة المعالجة المركزية
- كيف يختلف السعر باختلاف المعالجات؟
- 7) السعر مع ذاكرة الوصول العشوائي
- 8) عمود الذاكرة
- 9) متغير GPU
- 10) عمود نظام التشغيل
- التحول اللوغاريتمي العادي
- نمذجة التعلم الآلي لتنبؤ أسعار أجهزة الكمبيوتر المحمول
- استيراد المكتبات
- التقسيم الى بيانات التدريب والاختبار
- تنفيذ خط أنابيب للتدريب والاختبار
التعلم الآلي هو فرع من فروع الذكاء الاصطناعي الذي يتعامل مع تنفيذ التطبيقات التي يمكن أن تقوم بالتنبؤ في المستقبل بناءً على البيانات السابقة. إذا كنت متحمسًا لعلوم البيانات أو ممارسًا، فستساعدك هذه المقالة في بناء مشروع التعلم الآلي الشامل الخاص بك من البداية. هناك العديد من الخطوات المتضمنة في بناء مشروع التعلم الآلي ولكن ليست كل الخطوات إلزامية لاستخدامها في مشروع واحد، وكل هذا يتوقف على البيانات. في هذه المقالة، سنبني مشروع توقع أسعار أجهزة الكمبيوتر المحمول ونتعرف على دورة حياة مشروع التعلم الآلي.
بيان المشكلة لتنبؤ بسعر الكمبيوتر المحمول
سنقوم بعمل مشروع لتنبؤ أسعار أجهزة الكمبيوتر المحمول. بيان المشكلة هو أنه إذا أراد أي مستخدم شراء جهاز كمبيوتر محمول، فيجب أن يكون تطبيقنا متوافقًا لتوفير سعر مبدئي للكمبيوتر المحمول وفقًا لتكوينات المستخدم. على الرغم من أنه يبدو وكأنه مشروع بسيط أو مجرد تطوير نموذج، إلا أن مجموعة البيانات التي لدينا صاخبة وتحتاج إلى الكثير من هندسة الميزات والمعالجة المسبقة التي ستثير اهتمامك بتطوير هذا المشروع.
مجموعة بيانات لتنبؤ بأسعار أجهزة الكمبيوتر المحمول
يمكنك تنزيل مجموعة البيانات من هنا. معظم الأعمدة في مجموعة البيانات صاخبة noisy وتحتوي على الكثير من المعلومات. ولكن مع هندسة الميزات feature engineering التي تقوم بها، ستحصل على المزيد من النتائج الجيدة. المشكلة الوحيدة هي أننا نمتلك بيانات أقل ولكننا سنحصل على دقة جيدة بشأنها. الشيء الجيد الوحيد هو أنه من الأفضل أن يكون لديك بيانات كبيرة. سنقوم بتطوير موقع ويب يمكنه التنبؤ بسعر مبدئي لجهاز كمبيوتر محمول بناءً على تكوين المستخدم.
الفهم الأساسي لبيانات التنبؤ بسعر الكمبيوتر المحمول
الآن دعونا نبدأ العمل على مجموعة بيانات في نوتبوك Jupyter الخاص بنا. الخطوة الأولى هي استيراد المكتبات وتحميل البيانات. بعد ذلك سنأخذ فهمًا أساسيًا للبيانات مثل شكلها وعينتها وهل هناك أي قيم فارغة موجودة في مجموعة البيانات. يُعد فهم البيانات خطوة مهمة للتنبؤ أو أي مشروع للتعلم الآلي.
من الجيد عدم وجود قيم فارغة NULL values. ونحتاج إلى تغييرات طفيفة في الوزن وعمود ذاكرة الوصول العشوائي لتحويلها إلى رقمية عن طريق إزالة الوحدة المكتوبة بعد القيمة. لذلك سنقوم بتنظيف البيانات هنا للحصول على أنواع الأعمدة الصحيحة.
data.drop(columns=['Unnamed: 0'],inplace=True)
## remove gb and kg from Ram and weight and convert the cols to numeric
data['Ram'] = data['Ram'].str.replace("GB", "")
data['Weight'] = data['Weight'].str.replace("kg", "")
data['Ram'] = data['Ram'].astype('int32')
data['Weight'] = data['Weight'].astype('float32')
تحليل البيانات الاستكشافية لمجموعة بيانات توقع أسعار أجهزة الكمبيوتر المحمول
التحليل البيانات الاستكشافي Exploratory Data Analysis(EDA) هو عملية لاستكشاف وفهم علاقة البيانات والبيانات بعمق كامل بحيث تجعل خطوات هندسة الميزات ونمذجة التعلم الآلي سلسة ومبسطة للتنبؤ. تتضمن EDA التحليل أحادي المتغير أو ثنائي المتغير أو متعدد المتغيرات. تساعد EDA على إثبات صحة افتراضاتنا أو خطأها. بمعنى آخر، من المفيد إجراء اختبار الفرضيات. سنبدأ من العمود الأول ونستكشف كل عمود ونفهم التأثير الذي يحدثه على العمود الهدف. في الخطوة المطلوبة، سنقوم أيضًا بتنفيذ مهام المعالجة المسبقة وهندسة الميزات. هدفنا في أداء EDA المتعمق هو إعداد البيانات وتنظيفها لتحسين نمذجة التعلم الآلي لتحقيق أداء عالٍ ونماذج معممة. فلنبدأ في تحليل مجموعة البيانات وإعدادها للتنبؤ.
1) توزيع العمود الهدف
العمل مع توزيع العمود الهدف target column بيان مشكلة الانحدار مهم لفهمه.
sns.distplot(data['Price'])
plt.show()
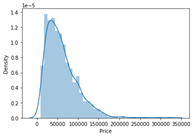
توزيع المتغير المستهدف منحرف ومن الواضح أن السلع ذات الأسعار المنخفضة يتم بيعها وشرائها أكثر من السلع ذات العلامات التجارية.
2) عمود الشركة Company column
نريد أن نفهم كيف يؤثر اسم العلامة التجارية على سعر الكمبيوتر المحمول أو ما هو متوسط سعر كل علامة تجارية لأجهزة الكمبيوتر المحمول؟ إذا قمت برسم مخطط تعداد (مخطط تواتر frequency plot) لشركة ما، فإن الفئات الرئيسية الموجودة هي Lenovo وDell وHP وAsus وما إلى ذلك.
الآن إذا رسمنا علاقة الشركة بالسعر، فيمكنك ملاحظة كيف يختلف السعر باختلاف العلامات التجارية.
#what is avg price of each brand?
sns.barplot(x=data['Company'], y=data['Price'])
plt.xticks(rotation="vertical")
plt.show()
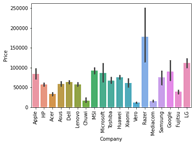
تعد أجهزة الكمبيوتر المحمولة Razer وApple وLG وMicrosoft وGoogle وMSI باهظة الثمن، والبعض الآخر في نطاق الميزانية.
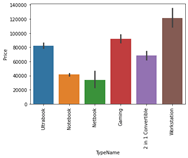
3) نوع الكمبيوتر المحمول
ما نوع الكمبيوتر المحمول الذي تبحث عنه مثل كمبيوتر محمول للألعاب أو محطة عمل أو كمبيوتر محمول. نظرًا لأن الأشخاص الرئيسيين يفضلون الكمبيوتر المحمول لأنه يقع ضمن نطاق الميزانية ويمكن استنتاج نفس الشيء من بياناتنا.
#data['TypeName'].value_counts().plot(kind='bar')
sns.barplot(x=data['TypeName'], y=data['Price'])
plt.xticks(rotation="vertical")
plt.show()
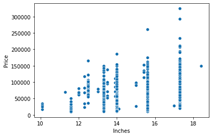
4) هل يختلف السعر باختلاف حجم الكمبيوتر المحمول بالبوصة؟
يتم استخدام مخطط المبعثر Scatter plot عندما يكون كلا العمودين رقميًا ويجيب على سؤالنا بطريقة أفضل. من المخطط أدناه يمكننا أن نستنتج أن هناك علاقة وليست علاقة قوية بين عمود السعر والحجم.
sns.scatterplot(x=data['Inches'],y=data['Price'])
هندسة الميزات والمعالجة المسبقة لنموذج التنبؤ بسعر الكمبيوتر المحمول
هندسة الميزات Feature engineering هي عملية لتحويل البيانات الأولية إلى معلومات مفيدة. هناك العديد من الطرق التي تندرج تحت هندسة الميزات مثل التحويل transformation والترميز الفئوي categorical encoding وما إلى ذلك. الآن الأعمدة التي لدينا صاخبة لذا نحتاج إلى تنفيذ بعض خطوات هندسة الميزات.
5) دقة الشاشة
دقة الشاشة Screen Resolution تحتوي على الكثير من المعلومات. قبل أي تحليل أولاً، نحتاج إلى إجراء هندسة الميزات عليه. إذا لاحظت قيمًا فريدة للعمود، فيمكننا أن نرى أن كل القيم تعطي معلومات تتعلق بوجود لوحة IPS، وهي شاشة تعمل باللمس للكمبيوتر المحمول أم لا، ودقة شاشة المحور X والمحور Y. لذلك، سنقوم باستخراج العمود إلى 3 أعمدة جديدة في مجموعة البيانات.
استخراج معلومات شاشة اللمس
إنه متغير ثنائي لذا يمكننا ترميزه بالرقم 0 و 1. يعني أحدهما أن الكمبيوتر المحمول هو شاشة تعمل باللمس والصفر يشير إلى عدم وجود شاشة تعمل باللمس.
data['Touchscreen'] = data['ScreenResolution'].apply(lambda x:1 if 'Touchscreen' in x else 0)
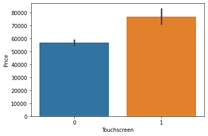
#how many laptops in data are touchscreen
sns.countplot(data['Touchscreen'])
#Plot against price
sns.barplot(x=data['Touchscreen'],y=data['Price'])
إذا قمنا برسم عمود الشاشة التي تعمل باللمس مقابل السعر، فإن أجهزة الكمبيوتر المحمولة المزودة بشاشات تعمل باللمس تكون باهظة الثمن وهذا صحيح في الحياة الواقعية.
استخراج معلومات وجود قناة IPS
إنه متغير ثنائي والرمز هو نفسه الذي استخدمناه أعلاه. أجهزة الكمبيوتر المحمولة المزودة بقناة IPS موجودة بشكل أقل في بياناتنا ولكن من خلال مراقبة العلاقة مقابل سعر أجهزة الكمبيوتر المحمولة ذات قناة IPS مرتفعة.
#extract IPS column
data['Ips'] = data['ScreenResolution'].apply(lambda x:1 if 'IPS' in x else 0)
sns.barplot(x=data['Ips'],y=data['Price'])
استخراج أبعاد دقة الشاشة المحور X والمحور Y
الآن كلا البُعد موجودان في نهاية السلسلة النصية ويفصل بينهما بعلامة متقاطعة. لذلك سنقوم أولاً بتقسيم السلسلة التي تحتوي على مسافة والوصول إلى آخر سلسلة من القائمة. ثم قم بتقسيم السلسلة بعلامة متقاطعة والوصول إلى الصفر والأول للفهرس لأبعاد المحور X و Y.
def findXresolution(s):
return s.split()[-1].split("x")[0]
def findYresolution(s):
return s.split()[-1].split("x")[1]
#finding the x_res and y_res from screen resolution
data['X_res'] = data['ScreenResolution'].apply(lambda x: findXresolution(x))
data['Y_res'] = data['ScreenResolution'].apply(lambda y: findYresolution(y))
#convert to numeric
data['X_res'] = data['X_res'].astype('int')
data['Y_res'] = data['Y_res'].astype('int')
استبدال دقة البوصة، X و Y بـ PPI
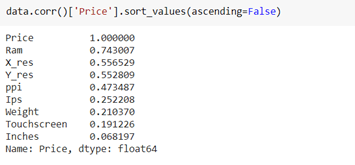
إذا وجدت ارتباط الأعمدة بالسعر باستخدام طريقة corr، فيمكننا أن نرى أن البوصة ليس لها ارتباط قوي ولكن دقة المحور X و Y لها دقة عالية جدًا حتى نتمكن من الاستفادة منها وتحويل هذه الأعمدة الثلاثة إلى عمود واحد يُعرف بالبكسل لكل بوصة (PPI). في النهاية، هدفنا هو تحسين الأداء من خلال تقليل الميزات.
data['ppi'] = (((data['X_res']**2) + (data['Y_res']**2))**0.5/data['Inches']).astype('float')
data.corr()['Price'].sort_values(ascending=False)
الآن عندما ترى ارتباط السعر، فإن مؤشر أسعار المنتجين له علاقة قوية.
لذا يمكننا الآن إسقاط الأعمدة الإضافية غير المفيدة. في هذه المرحلة، بدأنا في الاحتفاظ بالأعمدة المهمة في مجموعة البيانات الخاصة بنا.
data.drop(columns = ['ScreenResolution', 'Inches','X_res','Y_res'], inplace=True)
6) عمود وحدة المعالجة المركزية
إذا لاحظت عمود وحدة المعالجة المركزية، فإنه يحتوي أيضًا على الكثير من المعلومات. إذا كنت تستخدم دالة فريدة أو دالة حساب القيمة مرة أخرى في عمود وحدة المعالجة المركزية، فلدينا 118 فئة مختلفة. المعلومات التي يقدمها حول المعالجات المسبقة في أجهزة الكمبيوتر المحمولة والسرعة.
#first we will extract Name of CPU which is first 3 words from Cpu column and then we will check which processor it is
def fetch_processor(x):
cpu_name = " ".join(x.split()[0:3])
if cpu_name == 'Intel Core i7' or cpu_name == 'Intel Core i5' or cpu_name == 'Intel Core i3':
return cpu_name
elif cpu_name.split()[0] == 'Intel':
return 'Other Intel Processor'
else:
return 'AMD Processor'
data['Cpu_brand'] = data['Cpu'].apply(lambda x: fetch_processor(x))
لاستخراج المعالج المسبق، نحتاج إلى استخراج الكلمات الثلاث الأولى من السلسلة. لدينا معالج Intel ومعالج AMD المسبق لذلك نحتفظ بـ 5 فئات في مجموعة البيانات لدينا مثل i3 وi5 وi7 ومعالجات Intel الأخرى ومعالجات AMD.
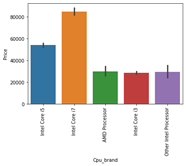
كيف يختلف السعر باختلاف المعالجات؟
يمكننا مرة أخرى استخدام خاصية المخطط الشريطي bar plot للإجابة على هذا السؤال. ومن الواضح أن سعر معالج i7 مرتفع، ثم معالج i5 ومعالج i3 ومعالج AMD يقعان في نفس النطاق تقريبًا. ومن ثم سيعتمد السعر على المعالج المسبق.
sns.barplot(x=data['Cpu_brand'],y=data['Price'])
plt.xticks(rotation='vertical')
plt.show()
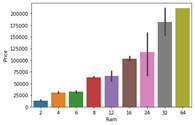
7) السعر مع ذاكرة الوصول العشوائي
مرة أخرى تحليل ثنائي المتغير للسعر مع ذاكرة الوصول العشوائي. إذا لاحظت المخطط، فإن السعر له علاقة إيجابية قوية جدًا بذاكرة الوصول العشوائية أو يمكنك قول علاقة خطية.
sns.barplot(data['Ram'], data['Price'])
plt.show()
8) عمود الذاكرة
عمود الذاكرة memory column هو مرة أخرى عمود صاخب يعطي فهمًا لمحركات الأقراص الثابتة. تأتي العديد من أجهزة الكمبيوتر المحمولة مزودة بـ HHD وSSD على حد سواء، كما يوجد في بعضها فتحة خارجية لإدخالها بعد الشراء. يمكن أن يزعج هذا العمود تحليلك إذا لم يتم تصميمه بشكل صحيح. لذلك إذا كنت تستخدم عدد القيم في عمود، فنحن لدينا 4 فئات مختلفة من الذاكرة مثل HHD وSSD وتخزين الفلاش والهجين.
#preprocessing
data['Memory'] = data['Memory'].astype(str).replace('.0', '', regex=True)
data["Memory"] = data["Memory"].str.replace('GB', '')
data["Memory"] = data["Memory"].str.replace('TB', '000')
new = data["Memory"].str.split("+", n = 1, expand = True)
data["first"]= new[0]
data["first"]=data["first"].str.strip()
data["second"]= new[1]
data["Layer1HDD"] = data["first"].apply(lambda x: 1 if "HDD" in x else 0)
data["Layer1SSD"] = data["first"].apply(lambda x: 1 if "SSD" in x else 0)
data["Layer1Hybrid"] = data["first"].apply(lambda x: 1 if "Hybrid" in x else 0)
data["Layer1Flash_Storage"] = data["first"].apply(lambda x: 1 if "Flash Storage" in x else 0)
data['first'] = data['first'].str.replace(r'D', '')
data["second"].fillna("0", inplace = True)
data["Layer2HDD"] = data["second"].apply(lambda x: 1 if "HDD" in x else 0)
data["Layer2SSD"] = data["second"].apply(lambda x: 1 if "SSD" in x else 0)
data["Layer2Hybrid"] = data["second"].apply(lambda x: 1 if "Hybrid" in x else 0)
data["Layer2Flash_Storage"] = data["second"].apply(lambda x: 1 if "Flash Storage" in x else 0)
data['second'] = data['second'].str.replace(r'D', '')
#binary encoding
data["Layer2HDD"] = data["second"].apply(lambda x: 1 if "HDD" in x else 0)
data["Layer2SSD"] = data["second"].apply(lambda x: 1 if "SSD" in x else 0)
data["Layer2Hybrid"] = data["second"].apply(lambda x: 1 if "Hybrid" in x else 0)
data["Layer2Flash_Storage"] = data["second"].apply(lambda x: 1 if "Flash Storage" in x else 0)
#only keep integert(digits)
data['second'] = data['second'].str.replace(r'D', '')
#convert to numeric
data["first"] = data["first"].astype(int)
data["second"] = data["second"].astype(int)
#finalize the columns by keeping value
data["HDD"]=(data["first"]*data["Layer1HDD"]+data["second"]*data["Layer2HDD"])
data["SSD"]=(data["first"]*data["Layer1SSD"]+data["second"]*data["Layer2SSD"])
data["Hybrid"]=(data["first"]*data["Layer1Hybrid"]+data["second"]*data["Layer2Hybrid"])
data["Flash_Storage"]=(data["first"]*data["Layer1Flash_Storage"]+data["second"]*data["Layer2Flash_Storage"])
#Drop the un required columns
data.drop(columns=['first', 'second', 'Layer1HDD', 'Layer1SSD', 'Layer1Hybrid',
'Layer1Flash_Storage', 'Layer2HDD', 'Layer2SSD', 'Layer2Hybrid',
'Layer2Flash_Storage'],inplace=True)
أولاً، قمنا بتنظيف عمود الذاكرة ثم صنعنا 4 أعمدة جديدة وهي عبارة عن عمود ثنائي حيث يحتوي كل عمود على 1 و 0 يشير إلى أن المبلغ أربعة موجود وغير موجود. يحتوي أي كمبيوتر محمول على نوع واحد من الذاكرة أو مزيج من نوعين. لذلك في العمود الأول، يتكون من حجم الذاكرة الأول وإذا كانت الفتحة الثانية موجودة في الكمبيوتر المحمول، فسيحتوي العمود الثاني عليها، وإلا فإننا نملأ القيم الخالية بصفر. بعد ذلك في عمود معين، قمنا بضرب القيم بقيمتها الثنائية. هذا يعني أنه في حالة وجود ذاكرة معينة في أي كمبيوتر محمول، فإنها تحتوي على قيمة ثنائية كقيمة واحدة وسيتم ضرب القيمة الأولى بها، ونفس الشيء مع المجموعة الثانية. بالنسبة للكمبيوتر المحمول الذي يحتوي على فتحة ثانية، ستكون القيمة صفرًا مضروبة في صفر تساوي صفرًا.
الآن عندما نرى ارتباط السعر، يكون للتخزين الهجين والتخزين الفلاش ارتباط أقل أو معدومًا مع السعر. سنقوم بإسقاط هذا العمود مع وحدة المعالجة المركزية والذاكرة التي لم تعد مطلوبة.
data.drop(columns=['Hybrid','Flash_Storage','Memory','Cpu'],inplace=True)
9) متغير GPU
تحتوي وحدة المعالجة الرسومية (GPU) على العديد من الفئات في البيانات. لدينا بطاقة رسومية ذات علامة تجارية موجودة على جهاز كمبيوتر محمول. ليس لدينا عدد سعات مثل بطاقة الرسوم (6 جيجا بايت، 12 جيجا بايت) الموجودة. لذلك سنقوم ببساطة باستخراج اسم العلامة التجارية.
# Which brand GPU is in laptop
data['Gpu_brand'] = data['Gpu'].apply(lambda x:x.split()[0])
#there is only 1 row of ARM GPU so remove it
data = data[data['Gpu_brand'] != 'ARM']
data.drop(columns=['Gpu'],inplace=True)
10) عمود نظام التشغيل
هناك العديد من فئات أنظمة التشغيل. سنحتفظ بجميع فئات windows في واحدة، وMac في واحد، والباقي في فئات أخرى. هذه طريقة هندسة ميزات بسيطة وأكثرها استخدامًا، يمكنك تجربة شيء آخر إذا وجدت ارتباطًا أكثر بالسعر.
#Get which OP sys
def cat_os(inp):
if inp == 'Windows 10' or inp == 'Windows 7' or inp == 'Windows 10 S':
return 'Windows'
elif inp == 'macOS' or inp == 'Mac OS X':
return 'Mac'
else:
return 'Others/No OS/Linux'
data['os'] = data['OpSys'].apply(cat_os)
data.drop(columns=['OpSys'],inplace=True)
عندما تقوم برسم السعر مقابل نظام التشغيل، فإن Mac كالمعتاد يكون أغلى سعرًا.
sns.barplot(x=data['os'],y=data['Price'])
plt.xticks(rotation='vertical')
plt.show()

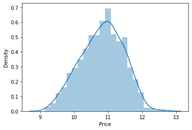
التحول اللوغاريتمي العادي
لقد رأينا توزيع المتغير الهدف الذي فوقه كان منحرفًا لليمين. بتحويله إلى التوزيع الطبيعي سيزداد أداء الخوارزمية. نأخذ سجل القيم التي تتحول إلى التوزيع الطبيعي الذي يمكنك ملاحظته أدناه. لذلك أثناء فصل المتغيرات التابعة والمستقلة، سنأخذ سجلًا للسعر، وفي عرض النتيجة نؤدي أسًا لها.
sns.distplot(np.log(data['Price']))
plt.show()
نمذجة التعلم الآلي لتنبؤ أسعار أجهزة الكمبيوتر المحمول
الآن قمنا بإعداد بياناتنا وفهم مجموعة البيانات بشكل أفضل. فلنبدأ بنمذجة التعلم الآلي ونعثر على أفضل خوارزمية مع أفضل المعلمات الفائقة لتحقيق أقصى قدر من الدقة.
استيراد المكتبات
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import r2_score,mean_absolute_error
from sklearn.linear_model import LinearRegression,Ridge,Lasso
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,AdaBoostRegressor,ExtraTreesRegressor
from sklearn.svm import SVR
from xgboost import XGBRegressor
لقد قمنا باستيراد مكتبات لتقسيم البيانات، وخوارزميات يمكنك تجربتها. في وقت لا نعرف أيهما هو الأفضل حتى تتمكن من تجربة جميع الخوارزميات المستوردة.
التقسيم الى بيانات التدريب والاختبار
كما ناقشنا، أخذنا سجل المتغيرات التابعة. وتبدو بيانات التدريب شيئًا ما أسفل إطار البيانات.
X = data.drop(columns=['Price'])
y = np.log(data['Price'])
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.15,random_state=2)
تنفيذ خط أنابيب للتدريب والاختبار
الآن سنقوم بتنفيذ خط أنابيب لتبسيط عملية التدريب والاختبار. أولاً، نستخدم محول عمود ColumnTransformer لترميز المتغيرات الفئوية وهي الخطوة الأولى. بعد ذلك، نقوم بإنشاء كائن من خوارزمية لدينا ونمرر كلا الخطوتين إلى خط الأنابيب. باستخدام كائنات خط الأنابيب، نتوقع النتيجة على البيانات الجديدة ونعرض الدقة.
step1 = ColumnTransformer(transformers=[
('col_tnf',OneHotEncoder(sparse=False,drop='first'),[0,1,7,10,11])
],remainder='passthrough')
step2 = RandomForestRegressor(n_estimators=100,
random_state=3,
max_samples=0.5,
max_features=0.75,
max_depth=15)
pipe = Pipeline([
('step1',step1),
('step2',step2)
])
pipe.fit(X_train,y_train)
y_pred = pipe.predict(X_test)
print('R2 score',r2_score(y_test,y_pred))
print('MAE',mean_absolute_error(y_test,y_pred))
في الخطوة الأولى للترميز الفئوي، مررنا فهرس الأعمدة للترميز، وتمرر الوسائل التمريرية الأعمدة الرقمية الأخرى كما هي. أفضل دقة حصلت عليها مع Random Forest المفضلة على الإطلاق. لكن يمكنك استخدام هذا الرمز مرة أخرى عن طريق تغيير الخوارزمية ومعلماتها. أنا أعرض Random Forest. يمكنك القيام بضبط المعلمات الفائقة باستخدام GridsearchCV أو Random Search CV. يمكننا أيضًا القيام بميزة التحجيم ولكنها لا تحدث أي تأثير على Random Forest.