

- 1. إعداد النظام الخاص بك
- 1.1 إنشاء سير العمل الأول الخاص بك
- 2. إدخال KNIME
- 1.2 استيراد ملفات البيانات
- 2.2 التصوير والتحليل
- 3. كيف تنظف بياناتك؟
- 1.3 البحث عن القيم المفقودة
- 2.3 التضمين
- 4. تدريب النموذج الأول الخاص بك
- 5. ارسال الحل الخاص بك
1. إعداد النظام الخاص بك
لتبدأ بـ KNIME، تحتاج أولاً إلى تثبيته وإعداده على جهاز الكمبيوتر الخاص بك.
الخطوة 1: اذهب إلى www.knime.com/downloads

الخطوة 2: تحديد الإصدار الصحيح لجهاز الكمبيوتر الخاص بك.

الخطوة 3: قم بتثبيت النظام الأساسي وتعيين دليل العمل لـ KNIME لتخزين ملفاته.

هكذا ستبدو شاشتك الرئيسية في KNIME.
1.1 إنشاء سير العمل الأول الخاص بك
قبل أن نتعمق أكثر في كيفية عمل KNIME، دعنا نحدد بعض المصطلحات الأساسية لمساعدتنا في فهمنا ثم نرى كيفية فتح مشروع جديد في KNIME.
العقدة Node: العقدة هي نقطة المعالجة الأساسية لأي معالجة للبيانات. يمكنه القيام بعدد من الإجراءات بناءً على ما تختاره في سير عملك.
سير العمل Workflow: سير العمل هو تسلسل الخطوات أو الإجراءات التي تتخذها في النظام الأساسي الخاص بك لإنجاز مهمة معينة.
سيوضح لك مدرب سير العمل workflow coach الموجود في الزاوية العلوية اليسرى النسبة المئوية لمجتمع KNIME الذي يوصي بعقدة معينة للاستخدام. سيعرض مستودع العقدة جميع العقد التي يمكن أن يتضمنها سير عمل معين، حسب احتياجاتك. يمكنك أيضًا الانتقال إلى ” Browse Example Workflows ” للتحقق من المزيد من مهام سير العمل بمجرد إنشاء أول واحد لك. هذه هي الخطوة الأولى نحو بناء حل لأي مشكلة.
لإعداد سير عمل، يمكنك اتباع هذه الخطوات.
الخطوة 1: اذهب إلى قائمة ملف، وانقر على جديد.

الخطوة 2: قم بإنشاء سير عمل KNIME جديد في النظام الأساسي الخاص بك وقم بتسميته “Introduction “.
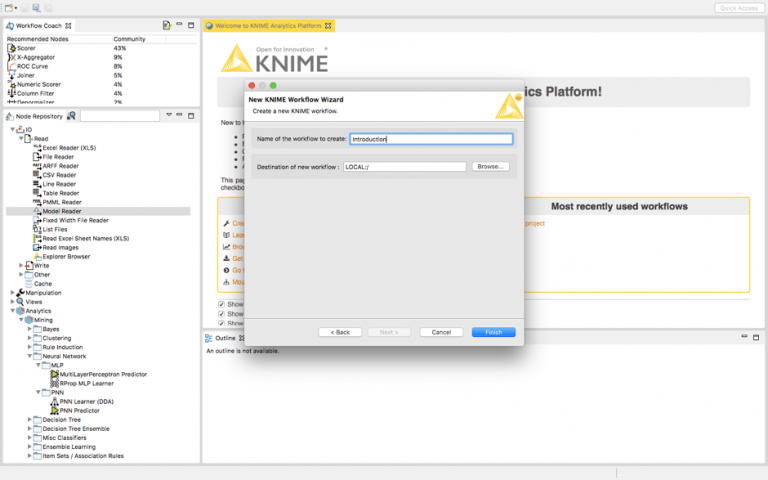
الخطوة 3: الآن عند النقر فوق “Finish” ، يجب أن تكون قد أنشأت سير عمل KNIME الأول بنجاح.
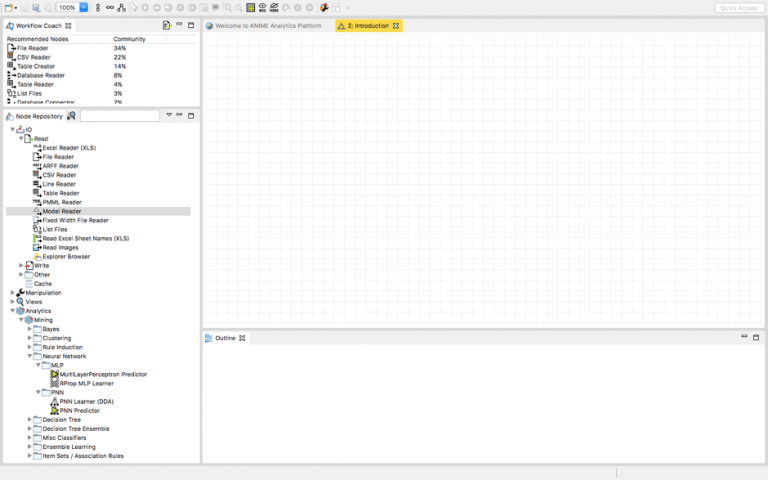
هذا هو سير العمل الفارغ الخاص بك على KNIME. أنت الآن جاهز لاستكشاف أي مشكلة وحلها عن طريق سحب أي عقدة من المستودع repository إلى سير عملك.
2. إدخال KNIME
KNIME هي منصة يمكن أن تساعدنا في حل أي مشكلة يمكن أن نفكر فيها ، في حدود علم البيانات اليوم. الموضوعات التي تتراوح من أبسط التصورات أو الانحدارات الخطية إلى التعلم العميق المتقدم، يمكن لـ KNIME أن تفعل كل شيء.
كنموذج لحالة الاستخدام، فإن المشكلة التي نتطلع إلى حلها في هذا البرنامج التعليمي هي مشكلة التدريب على Big Mart Sales التي يمكن الوصول إليها في Datahack.
بيان المشكلة كما يلي:
جمع علماء البيانات في BigMart بيانات مبيعات 2013 لـ 1559 منتجًا عبر 10 متاجر في مدن مختلفة. أيضًا، تم تحديد سمات معينة لكل منتج ومتجر. الهدف هو بناء نموذج تنبؤي ومعرفة مبيعات كل منتج في متجر معين.
باستخدام هذا النموذج، ستحاول BigMart فهم خصائص المنتجات والمتاجر التي تلعب دورًا رئيسيًا في زيادة المبيعات.
1.2 استيراد ملفات البيانات
دعونا نبدأ بالخطوة الأولى والمهمة للغاية في فهم المشكلة؛ استيراد بياناتنا.

قم بسحب وإسقاط عقدة “file reader” في سير العمل وانقر عليها نقرًا مزدوجًا. بعد ذلك، استعرض الملف الذي تريد استيراده إلى سير عملك.
في هذه المقالة، نظرًا لأننا سنتعلم كيفية حل مشكلة ممارسة Big Mart Sales، فسوف أقوم باستيراد مجموعة بيانات التدريب من Big Mart Sales.
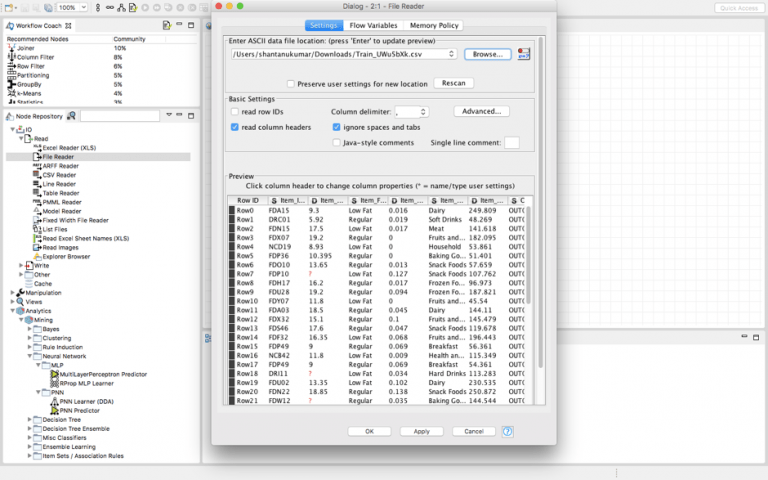
هذا ما ستبدو عليه المعاينة، بمجرد استيراد مجموعة البيانات.
دعونا نرسم بعض الأعمدة ذات الصلة ونجد العلاقة بينها. يساعدنا الارتباط في العثور على الأعمدة التي قد تكون مرتبطة ببعضها البعض ولدينا قوة تنبؤية أعلى لمساعدتنا في نتائجنا النهائية.
لإنشاء مصفوفة ارتباط correlation matrix ، نكتب “Linear Correlation” في مستودع العقدة node repository ، ثم نسحبها وإفلاتها في سير العمل لدينا.
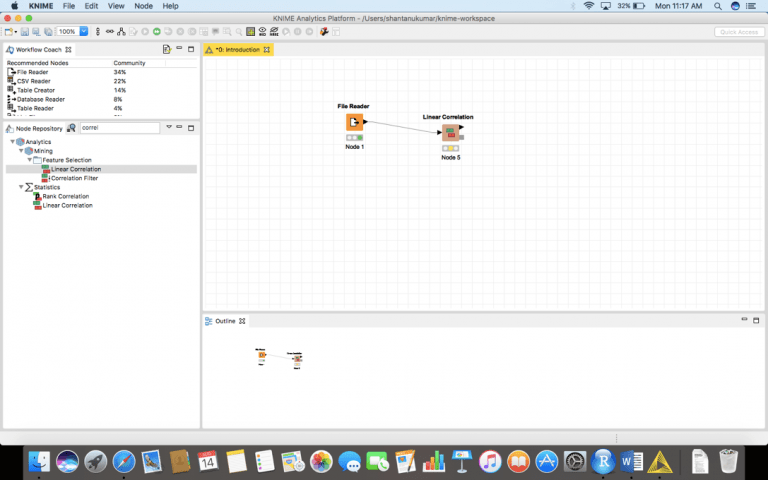
بعد أن نقوم بسحبه وإفلاته كما هو موضح، سنقوم بتوصيل إخراج file reader بإدخال العقدة “Linear Correlation”.
انقر فوق الزر الأخضر “Execute” في أعلى لوحة. الآن انقر بزر الماوس الأيمن فوق عقدة correlation وحدد ” View: Correlation Matrix ” لإنشاء الصورة أدناه.
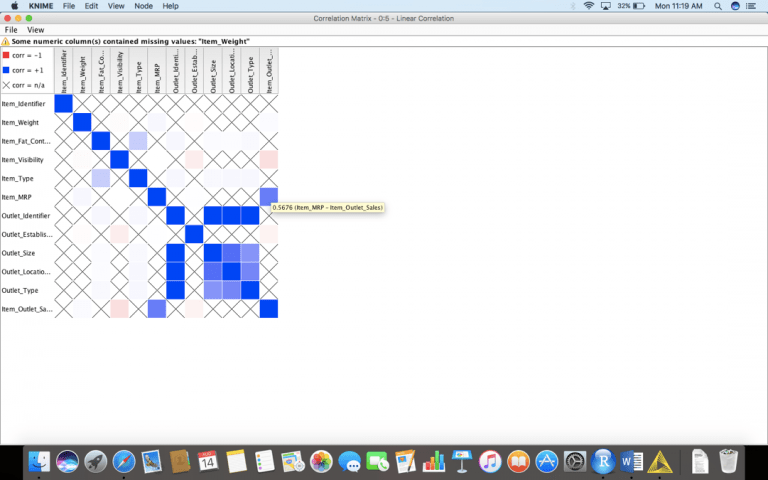
سيساعدك هذا في تحديد الميزات المهمة والمطلوبة للحصول على تنبؤات أفضل عن طريق تمرير مؤشر الماوس فوق الخلية المعينة.
بعد ذلك، سوف نرسم نطاق وأنماط مجموعة البيانات لفهمها بشكل أفضل.
2.2 التصوير والتحليل:
أحد الأشياء الأساسية التي نرغب في معرفتها من بياناتنا هو أن ما يتم بيعه هو الحد الأقصى من العناصر الأخرى.
ستكون هناك طريقتان لتفسير المعلومات:
1.مخطط مبعثر Scatterplot
ابحث عن “Scatter Plot” ضمن علامة التبويب “Views” في مستودع العقد الخاص بنا. قم بسحبه وإفلاته بطريقة مشابهة لسير العمل الخاص بك، وقم بتوصيل إخراج File Reader بهذه العقدة.
بعد ذلك، قم بتكوين العقدة الخاصة بك لتحديد عدد صفوف البيانات التي تحتاجها وترغب في تصويرها. [اخترت 3000]
انقر فوق execute، ثم انقر فوق View: Scatter Plot.
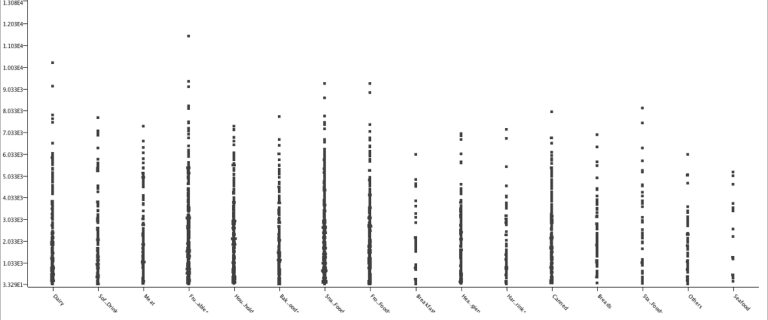
لقد حددت المحور X ليكون Item_Type والمحور Y ليكون Item_Outlet_Sales.
يمثل المخطط أعلاه مبيعات كل نوع عنصر على حدة ، وتبين لنا أن الفواكه والخضروات تُباع بأعلى الأرقام.
2.مخطط دائري Pie Chart
لفهم متوسط تقدير المبيعات لجميع أنواع المنتجات في قاعدة بياناتنا، سنستخدم مخططًا دائريًا pie chart.
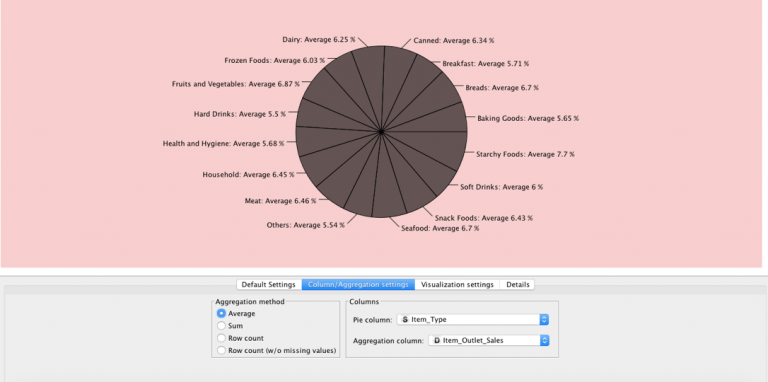
انقر فوق عقدة Pie Chart ضمن Views وقم بتوصيلها بـ File Reader الخاص بك. اختر الأعمدة التي تحتاجها للفصل واختر طرق التجميع المفضلة لديك، ثم قم بتطبيقها.
يوضح لنا هذا الرسم البياني أن المبيعات تم تقسيمها بشكل متوسط على جميع أنواع المنتجات. حصدت شركة “Starchy Foods” أعلى متوسط مبيعات بنسبة 7.7٪.
لقد استخدمت نوعين فقط من العناصر المرئية على الرغم من أنه يمكنك استكشاف البيانات بأشكال عديدة أثناء تصفح علامة التبويب “Views”. يمكنك استخدام الرسوم البيانية histograms ومخططات الخطية line plots وما إلى ذلك لتصور بياناتك بشكل أفضل.
3. كيف تنظف بياناتك؟
الأشياء الأخرى التي يمكنك تضمينها في نهجك قبل تدريب نموذجك هي تنظيف البيانات Data Cleaning واستخراج الميزات Feature Extraction. سأغطي هنا نظرة عامة على خطوات تنظيف البيانات في KNIME. لمزيد من الفهم، اتبع هذه المقالة حول استكشاف البيانات وهندسة الميزات.
1.3 البحث عن القيم المفقودة
قبل أن ننسب القيم، نحتاج إلى معرفة القيم المفقودة Missing Values.
انتقل إلى مستودع العقدة node repository مرة أخرى، وابحث عن العقدة ” Missing Values “. قم بسحبه وإفلاته، وقم بتوصيل إخراج File Reader الخاص بنا بالعقدة.
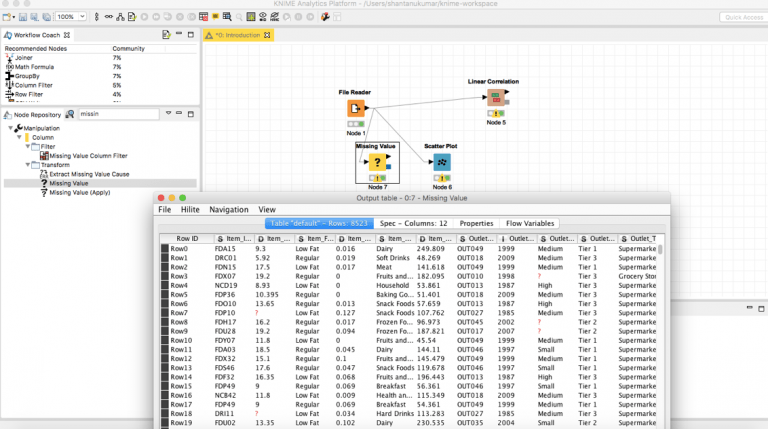
2.3 التضمين
لإسناد القيم، حدد العقدة القيمة المفقودة وانقر فوق تكوين configure. حدد الافتراضات المناسبة التي تريدها لبياناتك اعتمادًا على نوع البيانات، و “Apply”.
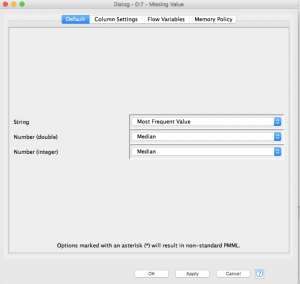
الآن عندما ننفذها، تكون مجموعة البيانات الكاملة الخاصة بنا ذات القيم المحتسبة جاهزة في منفذ الإخراج للعقدة ” Missing Values“. من أجل تحليلي، اخترت طرق التضمين على النحو التالي:
String: Most Frequent Value
Number (Double): Median
Number (Integer): Median
يمكنك الاختيار من بين مجموعة متنوعة من تقنيات التضمين مثل:
String:
- Next Value
- Previous Value
- Custom Value
- Remove Row
Number (Double and Integer):
- Mean
- Median
- Previous Value
- Next Value
- Custom Value
- Linear Interpolation
- Moving Average
4. تدريب النموذج الأول الخاص بك
دعونا نلقي نظرة على كيفية بناء نموذج التعلم الآلي في KNIME.
1.4 تنفيذ نموذج خطي
للبدء بالأساسيات، سنقوم أولاً بتدريب نموذج خطي Linear Model يشمل جميع ميزات مجموعة البيانات فقط لفهم كيفية تحديد الميزات وبناء نموذج.
انتقل إلى مستودع العقدة واسحب ” Linear Regression Learner” إلى سير عملك. ثم قم بتوصيل البيانات النظيفة التي جمعتها في “منفذ الإخراج Output Port ” لعقدة ” Missing Value “.
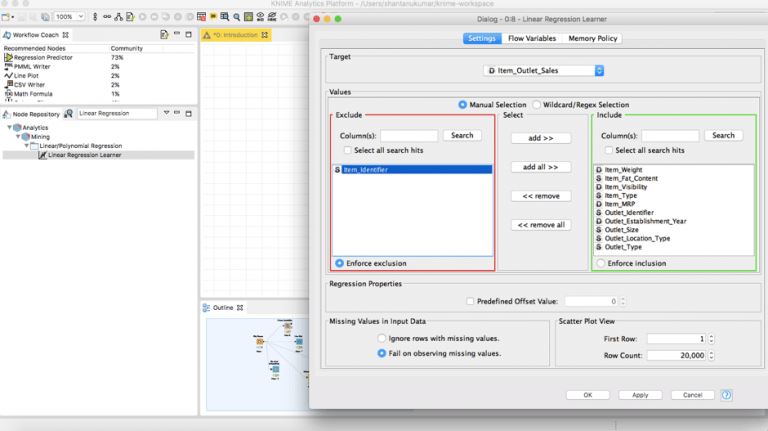
يجب أن تكون هذه الشاشة مرئية حتى الآن. في علامة تبويب configuration، استبعد Item_Identifier وحدد المتغير الهدف في الأعلى. بعد إكمال هذه المهمة، تحتاج إلى استيراد بيانات الاختبار Test data لتشغيل النموذج الخاص بك.
اسحب وأفلت file reader آخر في سير العمل وحدد بيانات الاختبار من نظامك.
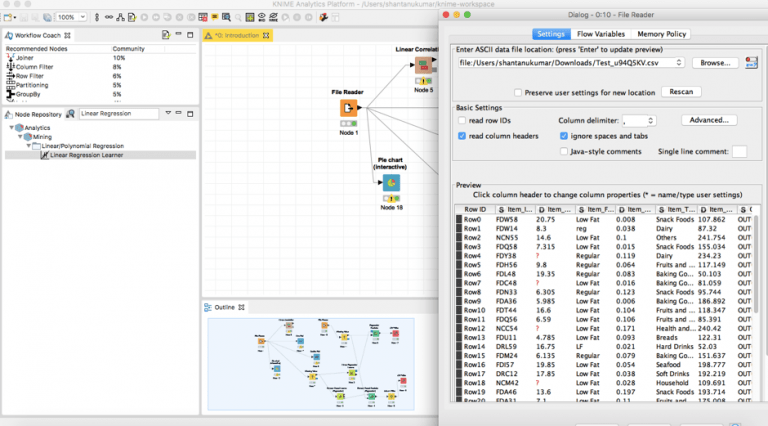
كما نرى، تحتوي بيانات الاختبار على قيم مفقودة أيضًا. سنقوم بتشغيلها من خلال عقدة ” Missing Value ” بنفس الطريقة التي استخدمناها لبيانات التدريب.
بعد أن قمنا بتنظيف بيانات الاختبار الخاصة بنا أيضًا، سنقدم الآن عقدة جديدة ” Regression Predictor “.
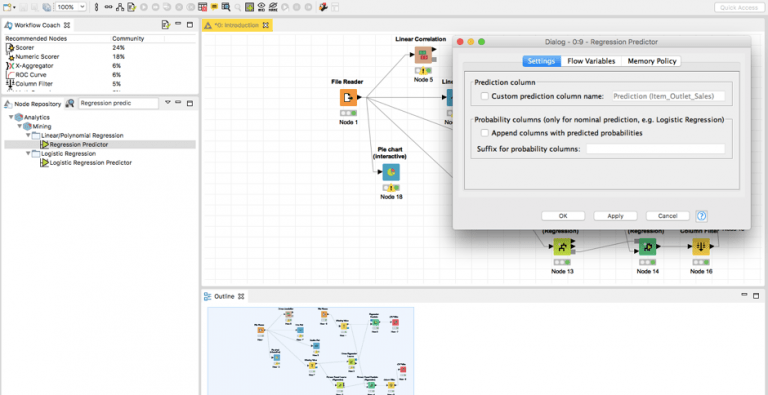
قم بتحميل النموذج الخاص بك في المتنبئ predictor عن طريق توصيل مخرجات المتعلم learner بإدخال المتنبئ. في الإدخال الثاني للمتنبئ، قم بتحميل بيانات الاختبار الخاصة بك. سيقوم المتنبئ بضبط عمود التنبؤ تلقائيًا بناءً على المتعلم الخاص بك، ولكن يمكنك تغييره يدويًا أيضًا.
تمتلك KNIME القدرة على تدريب بعض النماذج المتخصصة جدًا أيضًا ضمن علامة التبويب ” Analytics”. هنا قائمة شاملة
- Clustering
- Neural Networks
- Ensemble Learners
- Naïve Bayes
5. ارسال الحل الخاص بك
بعد تنفيذ المتنبئ الآن، يكون الإخراج جاهزًا تقريبًا للإرسال submission.
ابحث عن العقدة ” Column Filter” في مستودع العقد واسحبها إلى سير عملك. قم بتوصيل ناتج المتنبئ predictor بفلتر العمود column filter وقم بتكوينه لتصفية الأعمدة التي تحتاجها. في هذه الحالة، تحتاج إلى Item_Identifier و Outlet_Identifier وتوقع Outlet_Sales.
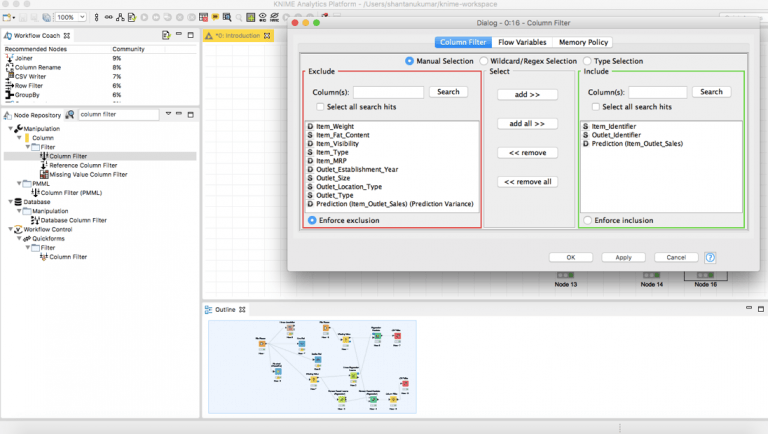
قم بتنفيذ ” Column Filter” وأخيراً، ابحث عن العقدة “CSV Writer” وقم بتوثيق تنبؤاتك على محرك الأقراص الثابتة لديك.
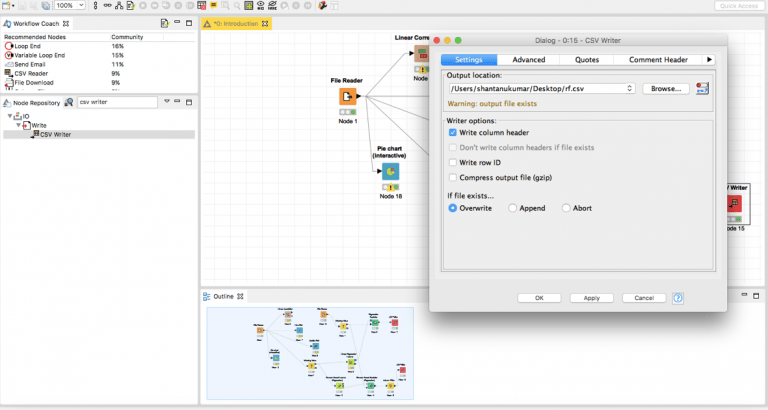
اضبط المسار لتعيينه حيث تريد تخزين ملف .csv، وقم بتنفيذ هذه العقدة. أخيرًا، افتح ملف .csv لتصحيح أسماء الأعمدة وفقًا للحل الذي نقدمه. اضغط ملف .csv في ملف .zip وأرسل الحل!
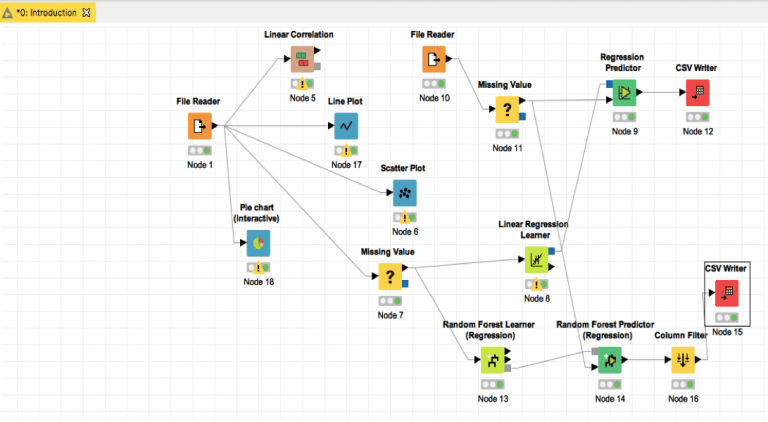
هذا هو مخطط سير العمل النهائي الذي تم الحصول عليه.
سير عمل KNIME سهل للغاية عندما يتعلق الأمر بإمكانية النقل. يمكن إرسالها إلى أصدقائك أو زملائك للبناء عليها معًا، مما يضيف إلى وظائف منتجك!
لتصدير سير عمل KNIME ، يمكنك ببساطة النقر فوق File -> Export KNIME Workflow.
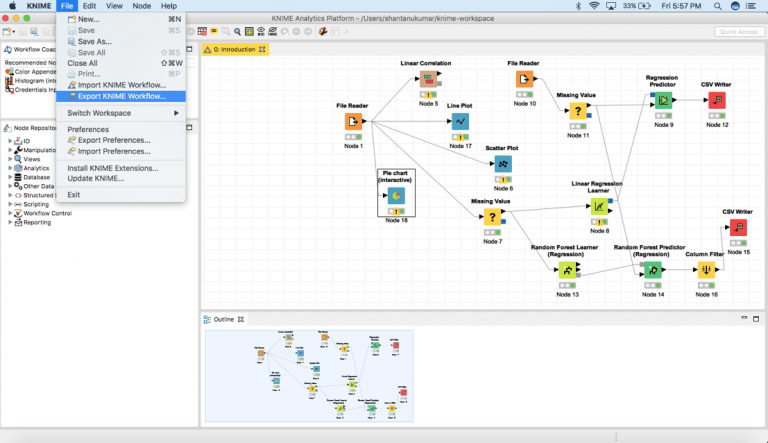
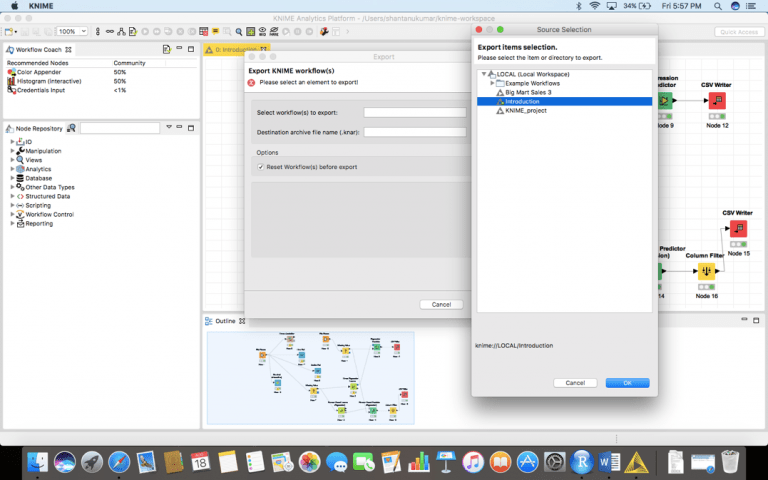
بعد ذلك، حدد سير العمل المناسب الذي تريد تصديره وانقر فوق إنهاء!
الملخص
KNIME هي منصة يمكن استخدامها في أي نوع من التحليل تقريبًا. في هذه المقالة، اكتشفنا كيفية تصوير مجموعة بيانات واستخراج ميزات مهمة منها. تم إجراء النمذجة التنبؤية أيضًا، باستخدام مُنبئ الانحدار الخطي لتقدير المبيعات لكل عنصر وفقًا لذلك. أخيرًا، قمنا بتصفية الأعمدة المطلوبة وتصديرها إلى ملف .csv.
آمل أن يكون هذا البرنامج التعليمي قد ساعدك في الكشف عن جوانب المشكلة التي ربما تكون قد أغفلتها من قبل. من المهم جدًا فهم خط أنابيب علم البيانات والخطوات التي نتخذها لتدريب النموذج، ومن المؤكد أن هذا سيساعدك على بناء نماذج تنبؤية أفضل قريبًا. حظا سعيدا مع مساعيكم!