

- تطبيق الدقة والاستدعاء في التعلم الآلي
- درجة F1 في الدقة والاستدعاء
- موازنة الدقة / الاستدعاء
في التعلم الآلي، تعد الدقة Precision والاستدعاء Recall أهم مقياسين لتقييم النموذج Model Evaluation. تمثل الدقة النسبة المئوية لنتائج نموذجك ذات الصلة بنموذجك. يمثل الاستدعاء النسبة المئوية الإجمالية لإجمالي النتائج ذات الصلة المصنفة بشكل صحيح بواسطة خوارزمية التعلم الآلي الخاصة بك.
في هذه المقالة، سأوضح لك كيف يمكنك تطبيق الدقة Precision والاستدعاء Recall لتقييم أداء نموذج التعلم الآلي الخاص بك.
تطبيق الدقة والاستدعاء في التعلم الآلي
سأقوم بتطبيق الدقة Precision والاستدعاء Recall باستخدام منشوري السابق في التصنيف الثنائي Binary Classification. سأواصل هذه المهمة من حيث انتهيت في التصنيف الثنائي.
يوفر Scikit-Learn العديد من الدوال لحساب مقاييس المصنف classifier metrics:
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred)
0.8370879772350012
4096 / (4096 + 1522)
0.6511713705958311
درجة F1 في الدقة والاستدعاء
غالبًا ما يكون من المناسب دمج هذين المقياسين في معلمة واحدة تسمى درجة F1 (F1 score)، على وجه الخصوص، إذا كنت بحاجة إلى طريقة بسيطة لمقارنة مصنفين. درجة F1 هو المتوسط التوافقي harmonic mean للدقة والاسترجاع.
في حين أن المتوسط العادي regular mean يعامل جميع القيم بالتساوي، فإن المتوسط التوافقي يعطي وزناً أكبر للقيم المنخفضة. نتيجة لذلك، سيحصل المصنف على درجة F1 عالية فقط إذا كان كلا المقياسين مرتفعين.
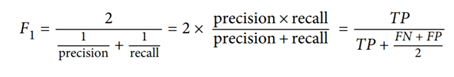
لحساب درجة F1، ما عليك سوى استدعاء الدالة f1_score():
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
0.7325171197343846
4096 / (4096 + (1522 + 1325) / 2)
0.7420962043663375
موازنة الدقة / الاستدعاء
لفهم هذه الموازنة، دعنا نلقي نظرة على كيفية قيام SGDClassifier باتخاذ قرارات التصنيف الخاصة به. لكل حالة، يتم حساب النتيجة بناءً على دالة القرار. إذا كانت هذه الدرجة أعلى من عتبة threshold، فإنها تخصص المثال للفئة الإيجابية positive class؛ وإلا فإنه يعينها للفئة السلبية negative class.
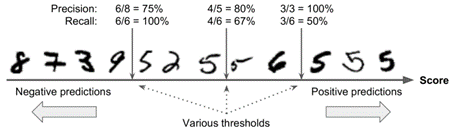
في الصورة أعلاه موازنة الدقة / الاسترجاع، يتم ترتيب النماذج حسب درجة المصنف، وتعتبر النماذج التي تتجاوز عتبة القرار المختارة إيجابية؛ كلما زاد الحد، انخفض الاسترجاع، ولكن (بشكل عام) زادت الدقة.
لا يسمح لك Scikit-Learn بتعيين العتبة مباشرةً، ولكنه يمنحك حق الوصول إلى درجات القرار التي يستخدمها لإجراء التنبؤات. بدلاً من استدعاء طريقة predict() للمصنف ، يمكنك استدعاء طريقة الدالة decision_function() ، والتي تُرجع النتيجة لكل حالة ، ثم استخدام أي حد تريده لعمل تنبؤات بناءً على تلك الدرجات:
y_scores = sgd_clf.decision_function([some_digit])
y_scores
array([2164.22030239])
threshold = 0
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
array([ True])
يستخدم SGDClassifier عتبة يساوي 0، لذلك يُرجع الكود السابق نفس النتيجة مثل طريقة predict() (أي ، True). دعنا نرفع حد العتبة:
threshold = 8000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
array([False])
كيف تقرر استخدام أي عتبة؟ أولاً، استخدم الدالة cross_val_predict () للحصول على درجات جميع الحالات في مجموعة التدريب، ولكن هذه المرة حدد أنك تريد إرجاع درجات القرار بدلاً من التنبؤات:
_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.legend(loc="center right", fontsize=16) # Not shown in the book
plt.xlabel("Threshold", fontsize=16) # Not shown
plt.grid(True) # Not shown
plt.axis([-50000, 50000, 0, 1]) # Not shown
recall_90_precision = recalls[np.argmax(precisions >= 0.90)]
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]
plt.figure(figsize=(8, 4)) # Not shown
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.plot([threshold_90_precision, threshold_90_precision], [0., 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [0.9, 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [recall_90_precision, recall_90_precision], "r:")# Not shown
plt.plot([threshold_90_precision], [0.9], "ro") # Not shown
plt.plot([threshold_90_precision], [recall_90_precision], "ro") # Not shown
save_fig("precision_recall_vs_threshold_plot") # Not shown
plt.show()
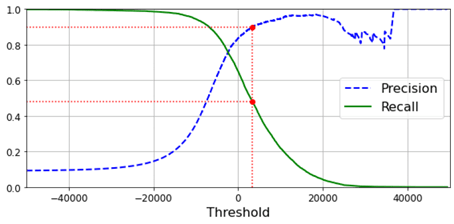
قد تتساءل عن سبب كون المنحنى الأزرق أكثر وعورة من المنحنى الأخضر في الناتج أعلاه. والسبب هو أن الدقة قد تذهب في بعض الأحيان إلى أسفل عندما ترفع الحد الأدنى (على الرغم من أنه بشكل عام، سوف ينخفض أعلى).
هناك طريقة أخرى لتحديد الموازنة الجيدة وهي رسم هذين المقياسين مباشرة مقابل الاستدعاء:
y_train_pred == (y_scores > 0)).all()
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.grid(True)
plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
plt.plot([0.4368, 0.4368], [0., 0.9], "r:")
plt.plot([0.0, 0.4368], [0.9, 0.9], "r:")
plt.plot([0.4368], [0.9], "ro")
save_fig("precision_vs_recall_plot")
plt.show()
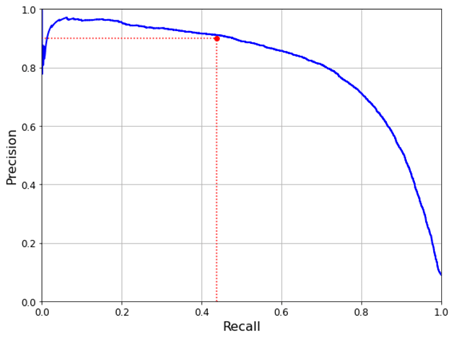
يمكنك أن ترى أن الدقة تبدأ في الانخفاض بشكل حاد عند استدعاء 80٪. ربما ترغب في تحديد موازنة الدقة / الاستدعاء قبل هذا الانخفاض مباشرة. أتمنى أن تكون قد أحببت هذه المقالة.



