المقدمة
في هذه المقالة، أقوم بإنشاء سير عمل علم البيانات خطوة بخطوة باستخدام سير عمل مرئي وبدون برمجة باستخدام KNIME.
KNIME هي بيئة مفتوحة المصدر حيث يمكن جمع البيانات ومناقشتها ، أو فهمها من خلال تقنيات النمذجة والتصور، بطريقة السحب والإفلات. يتيح ذلك للمستخدم نسيان الكود والتركيز على البيانات ونماذج ومفاهيم علم البيانات.
علاوة على ذلك، يمكن أن يكون سير العمل المرئي لـ KNIME فعالاً في زيادة قابلية قراءة سير العمل وصيانتها في الوقت المناسب.
من يجب أن يقرأ هذا المقال
بايثون هي لغة البرمجة الأكثر استخدامًا لعلم البيانات، ويتم استخدام العديد من اللغات الأخرى حاليًا في هذا المجال، مثل R و Scala و Julia وحتى Javascript و C#. ولكن ماذا لو كانت لديك مهارات برمجة قليلة أو معدومة؟ هل لا يزال بإمكانك الاقتراب من علم البيانات واستخدامه؟ يجب أن يكون واضحًا الآن أن الإجابة إيجابية.
هذه المقالة ليست مخصصة فقط لعلماء البيانات الذين يرغبون في تعلم طريقة مختلفة لإنشاء وتقديم منتجات علوم البيانات، ولكنها مناسبة أيضًا لمحللي البيانات أو مطوري SQL مع خبرة برمجة قليلة تتجاوز SQL القديمة الجيدة، أو لأصحاب المصلحة ومحللي الأعمال الذين الرغبة في أداء بعض علوم بيانات الخدمة الذاتية دون الحاجة إلى تعلم كيفية البرمجة.
مجموعة البيانات والنموذج التنبئي
في هذا البرنامج التعليمي، أستخدم مجموعة بيانات Kaggle ، استنزاف وأداء موظفي IBM HR Analytics (انظر قائمة المراجع). هذه مجموعة بيانات خيالية تم إنشاؤها بواسطة علماء بيانات IBM، وتحتوي على 50 عمودًا تصف 1470 موظفًا، مع بيانات تتعلق بالعمر، والمسافة من العمل، والدخل الشهري، وإجمالي سنوات العمل وما إلى ذلك. الحقل الرئيسي هو الحقل المسمى Attrition، والذي يحتوي على “Yes” إذا غادر الموظف الشركة ، و “لا” بخلاف ذلك. سيكون الهدف من البرنامج التعليمي هو تحميل مجموعة البيانات ومعالجتها مسبقًا واستكشافها لجمع رؤى مفيدة وبناء نموذج تنبؤي قادر على فهم ما إذا كان بإمكان الشخص ترك الشركة أم لا.
تثبيت KNIME
لبدء برنامجنا التعليمي، نحتاج إلى الحصول على نسخة من KNIME على الكمبيوتر المحمول الخاص بنا. KNIME مجاني ويمكن تنزيله وتثبيته من https://www.knime.com/downloads.
إعداد البيئة المحلية
أثناء التثبيت، يرجى ملاحظة بيئة KNIME المحلية، على سبيل المثال على جهاز MacBook الخاص بي ، يكون ضمن / Users / mac / knime-workspace.
قبل بدء تشغيل KNIME، أنشئ دليلًا (على سبيل المثال EmployeeChurn) ضمن البيئة المحلية وألصق الملفين EmployeeAttritionLabels.csv و EmployeeData.csv. (على سبيل المثال مسار الملف الأول، في حالتي، سيكون /Users/mac/knime-workspace/EmployeeChurn/EmployeeAttritionLabels.csv).
تركيب اضافة KNIME
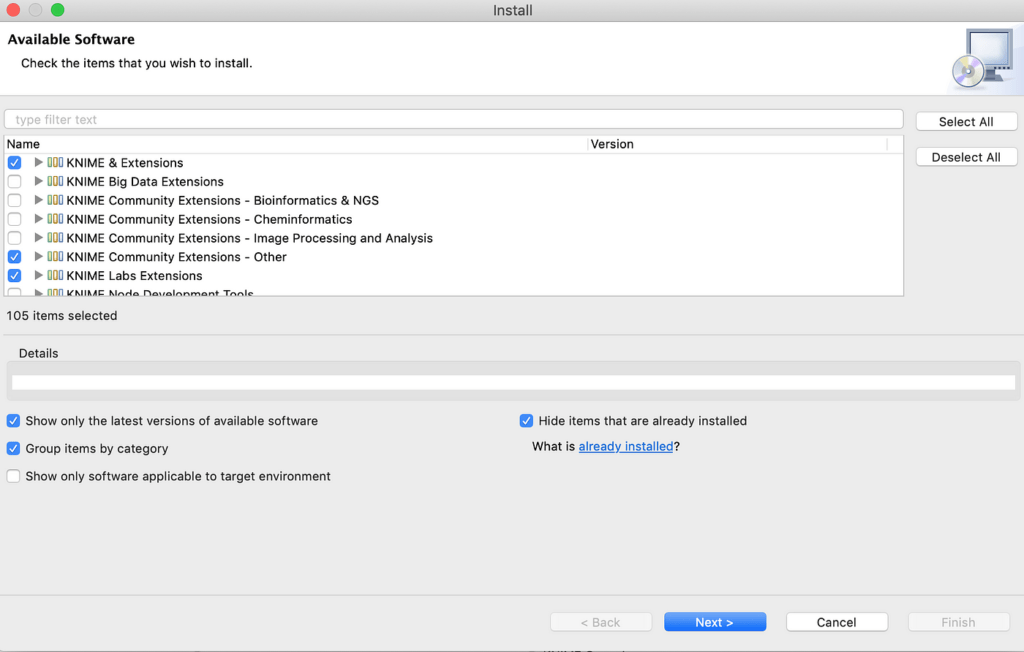
افتح KNIME وفي File->Install KNIME Extensions… حدد الاضافات المميزة في الشكل 1 لتثبيت الاضافات التي سنستخدمها (تحتوي الإضافات على أدوات وعقد وميزات إضافية تتجاوز الإصدار القياسي).
انشاء سير العمل
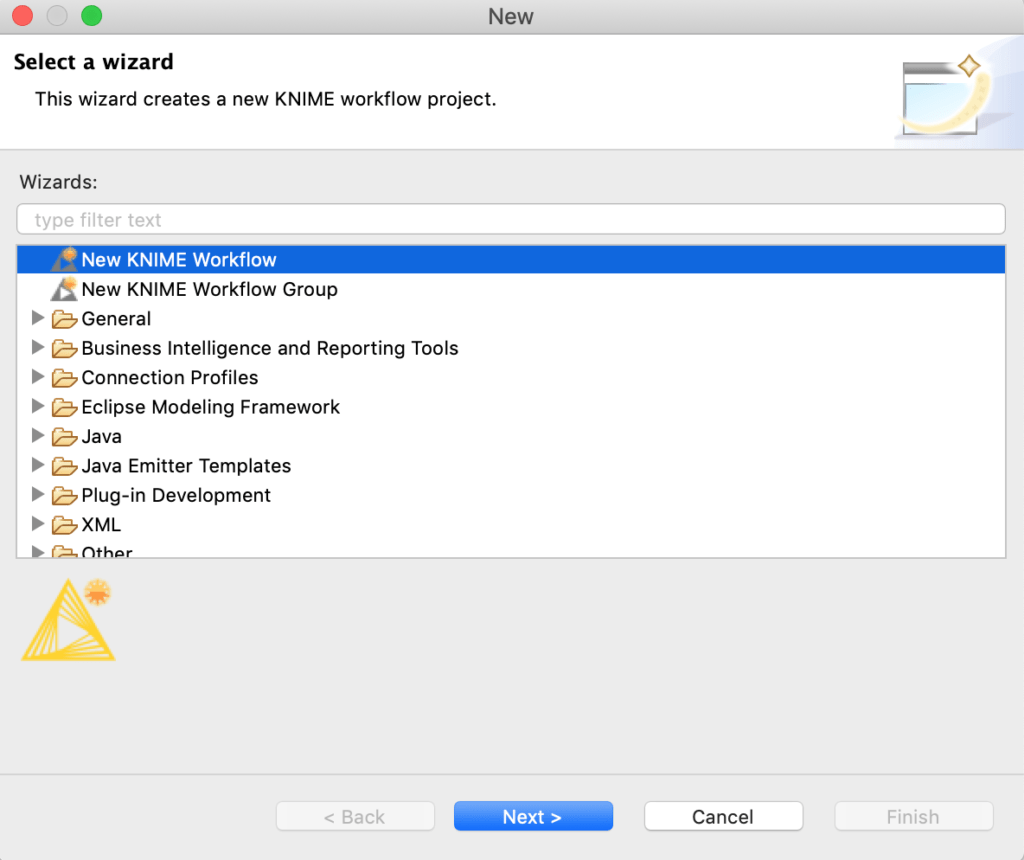
حان الوقت الآن لإنشاء سير عمل KNIME الخاص بنا، وتحديد File-> New-> New KNIME Workflow (الشكل 2) وتسميته KNIME-Employee-Churn.
واجهة مستخدم KNIME
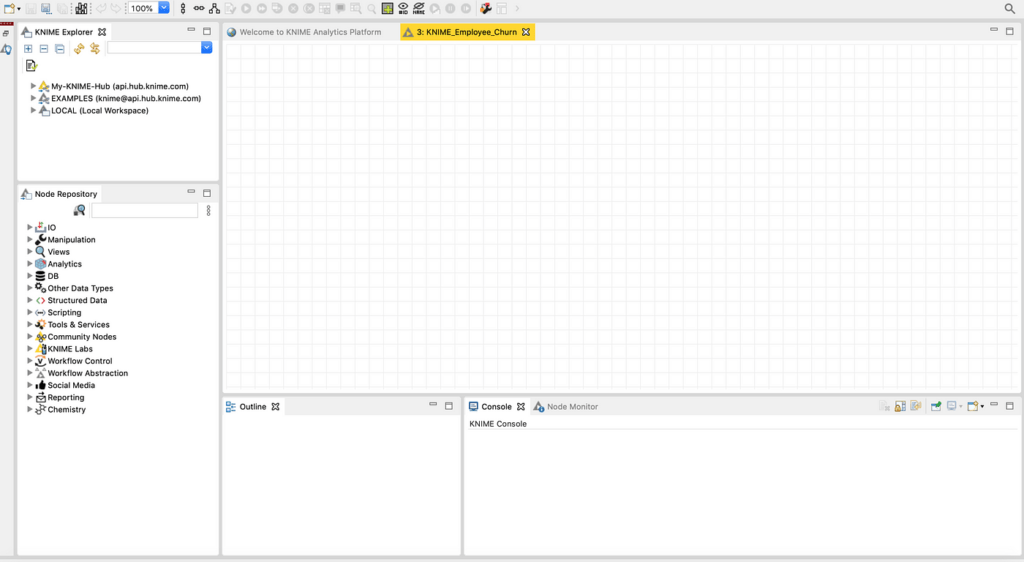
الآن بعد أن تم إعداد كل شيء، يمكننا إلقاء نظرة سريعة على واجهة مستخدم KNIME، كما هو موضح في الشكل 3. هناك سبعة عناصر رئيسية للبيئة المرئية:
- القائمة الأفقية العلوية، مع بعض الاختصارات المفيدة للوظائف المستخدمة بكثرة.
- Explorer أعلى اليسار ، حيث يمكن التنقل بين الأمثلة سابقة الإنشاء أو الملفات الموجودة في مساحة العمل المحلية
- Node Repository ، حيث يمكن تصفح العقد حسب الفئة أو البحث عن النص الكامل ثم سحبها إلى مساحة العمل
- مساحة العمل المركزية Central Workspace، حيث يمكن بناء وإدارة سير العمل المرئي.
- مخطط تفصيلي Outline، حيث يتم تمثيل معاينة مساحة العمل بالكامل.
- وحدة التحكم Console، حيث يتم عرض رسائل الخطأ أو التحذير أو الحالة.
- مراقب العقدة Node Monitor، حيث يتم عرض حالة ومعلومات العقدة المحددة.
إنشاء عقد File Reader
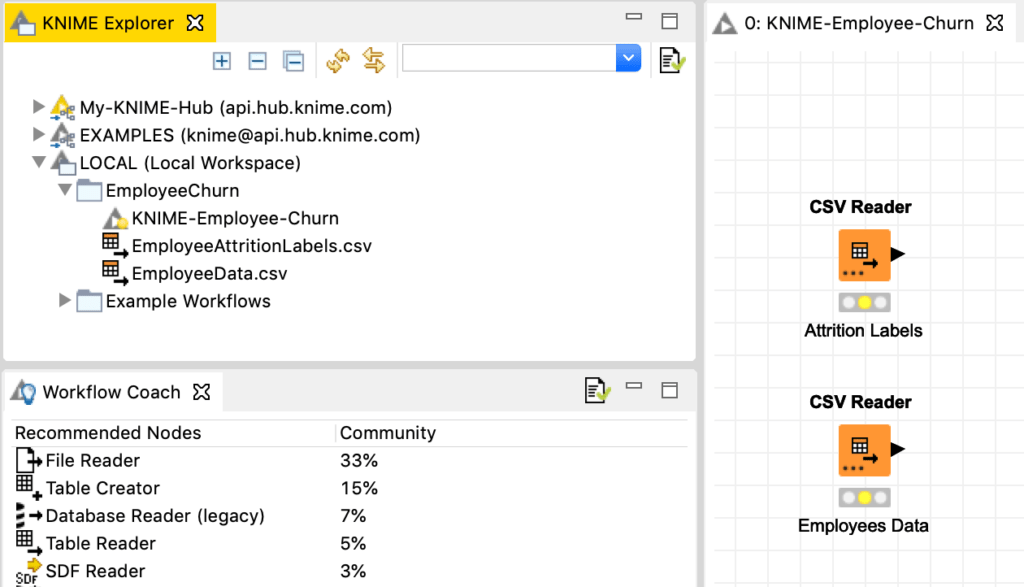
داخل سير العمل workflow، يمكننا إنشاء عقد KNIME الأولى الخاصة بنا ، ويمكننا القيام بذلك عن طريق سحب الملفين من مستكشف KNIME إلى مساحة سير العمل في المركز (الشكل 4). يتعرف KNIME تلقائيًا على نوع الملف وينشئ عقدة القارئ Reader Node المناسبة، في هذه الحالة CSV reader. بالنقر على تسميات “Node 1” و “Node 2” ، يمكننا إعادة تسمية العقدتين باسم “Attrition Labels” و “Employees Data”.
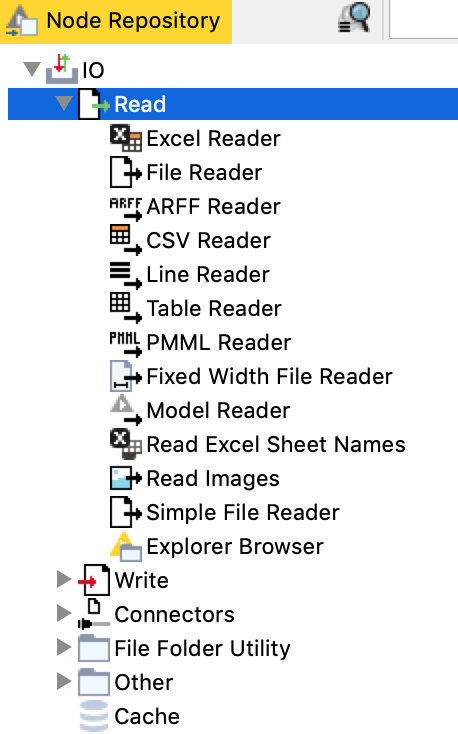
كان بإمكاننا إنشاء Reader Nodes بالاختيار من Node Repository أيضًا، في القائمة اليمنى، وتحديد CSV Reader ضمن IO->Read (الشكل 5).
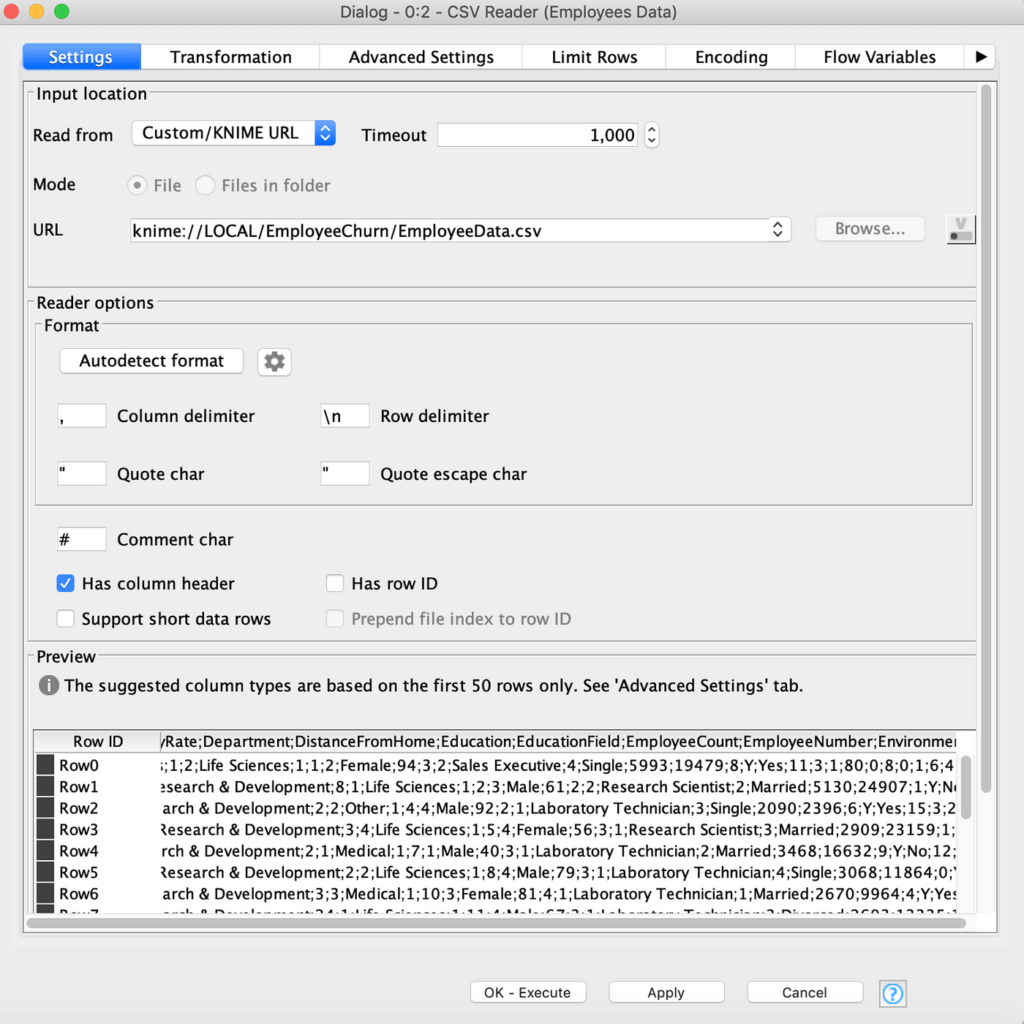
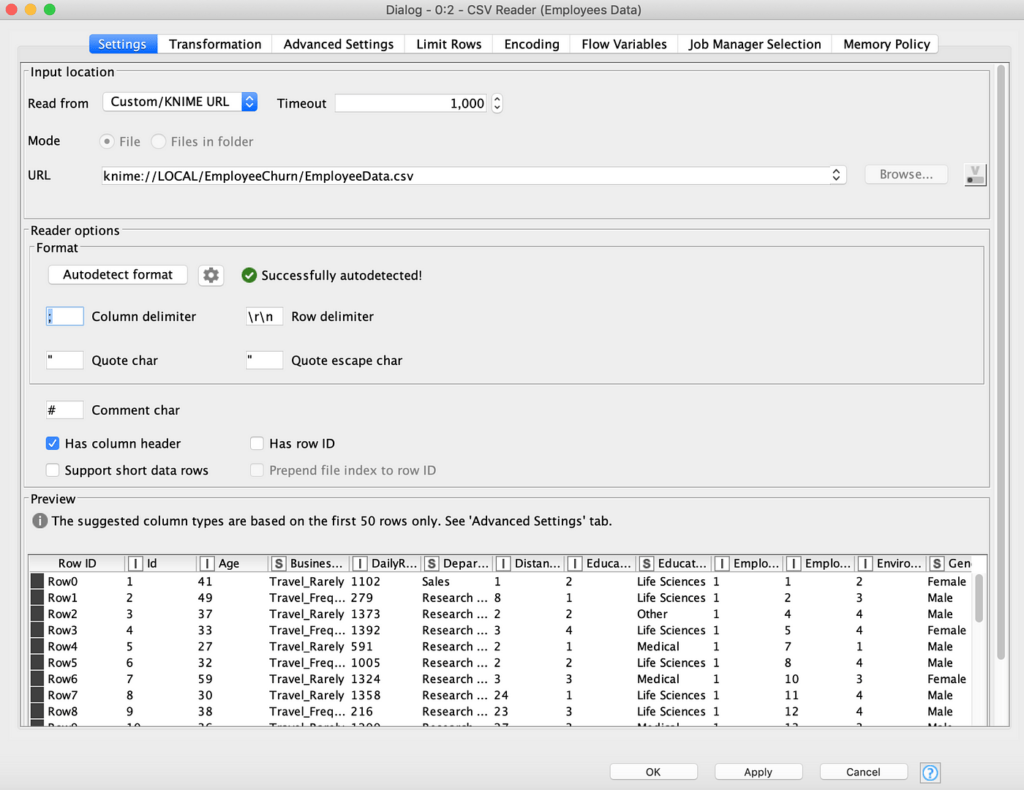
بالنقر المزدوج على Reader يمكننا استكشاف خصائص الملف، مثل معاينة أول 50 صفًا. من الممكن هنا أن يكون Readerقد حصل على محدد العمود الخاطئ، كما في الشكل 6. يمكننا فهمه من حقيقة أن الأعمدة في المعاينة لم يتم فصلها بشكل صحيح، ولكن جميعها في سلسلة طويلة واحدة لكل صف.
لحل الموقف، يمكننا النقر فوق “Autodetect format” أو كتابة “;” مباشرة كمحدد عمود column delimiter، وانقر فوق موافق- تنفيذ لتصحيح المشكلة ورؤية الأعمدة مفصولة بشكل صحيح، كما في الشكل 7.
إنشاء التعليقات التوضيحية
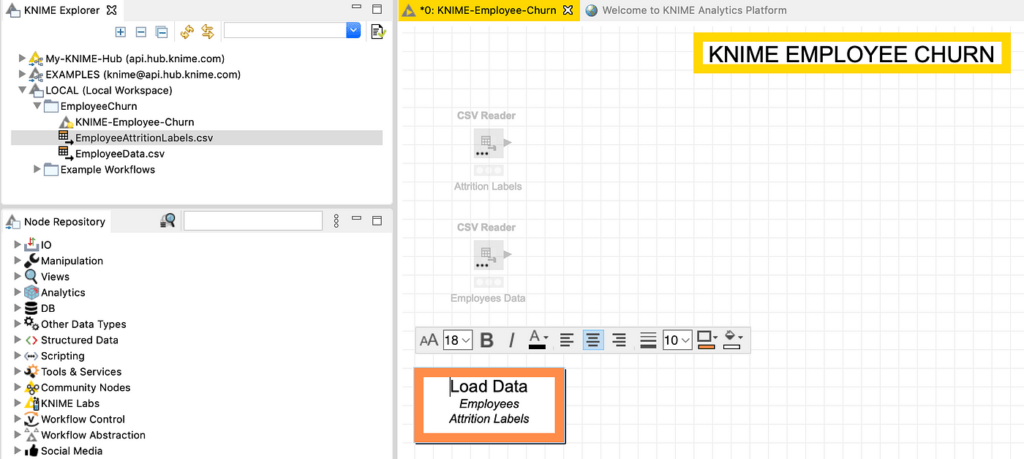
علاوة على ذلك، يمكننا النقر بزر الماوس الأيمن فوق (ctrl + click في Mac) في أي مكان في KNIME Workspace لإنشاء تعليق توضيحي. بمجرد إنشاء التعليق التوضيحي، يمكننا النقر فوق القلم الرصاص بالقرب منه لتعديله، واللعب بنمط الخط والحد / الخلفية. هنا قمت بإنشاء عنوان في الأعلى ومربع أسفل قارئات الملفات، لإظهار أنهم ينتمون إلى خطوة “Load Data” ، كما هو موضح في الشكل 8.
ربط مصادر البيانات
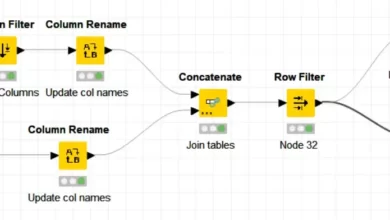
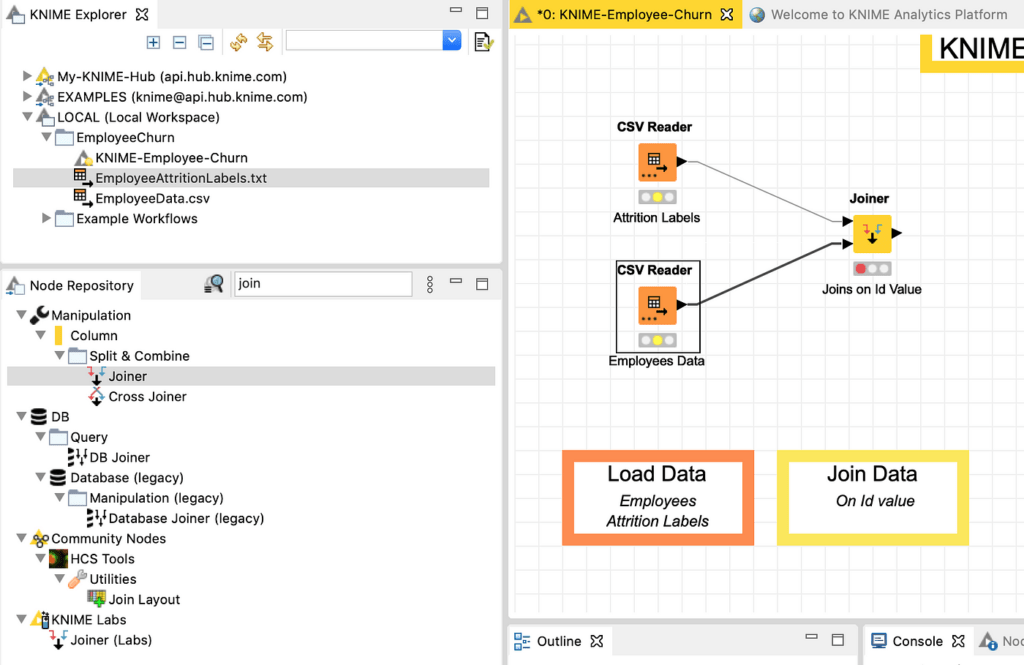
بمجرد أن نحصل على مصادر البيانات الخاصة بنا، يمكننا إجراء صلة داخلية عليها باستخدام عقدة Joiner ، والتي يمكن العثور عليها في Node Repository عن طريق كتابة “join” في البحث. يجب سحب أداة الربط في مساحة العمل وإسقاطها بعد مصادر البيانات، وربطها يدويًا بالنقر فوق كل مثلث “output” صغير موجود في مصادر البيانات وسحب الخط إلى مثلث “input” الرابط. سيبدو الموقف النهائي كما في الشكل 9، حيث تمت إضافة تعليق توضيحي مناسب أيضًا.
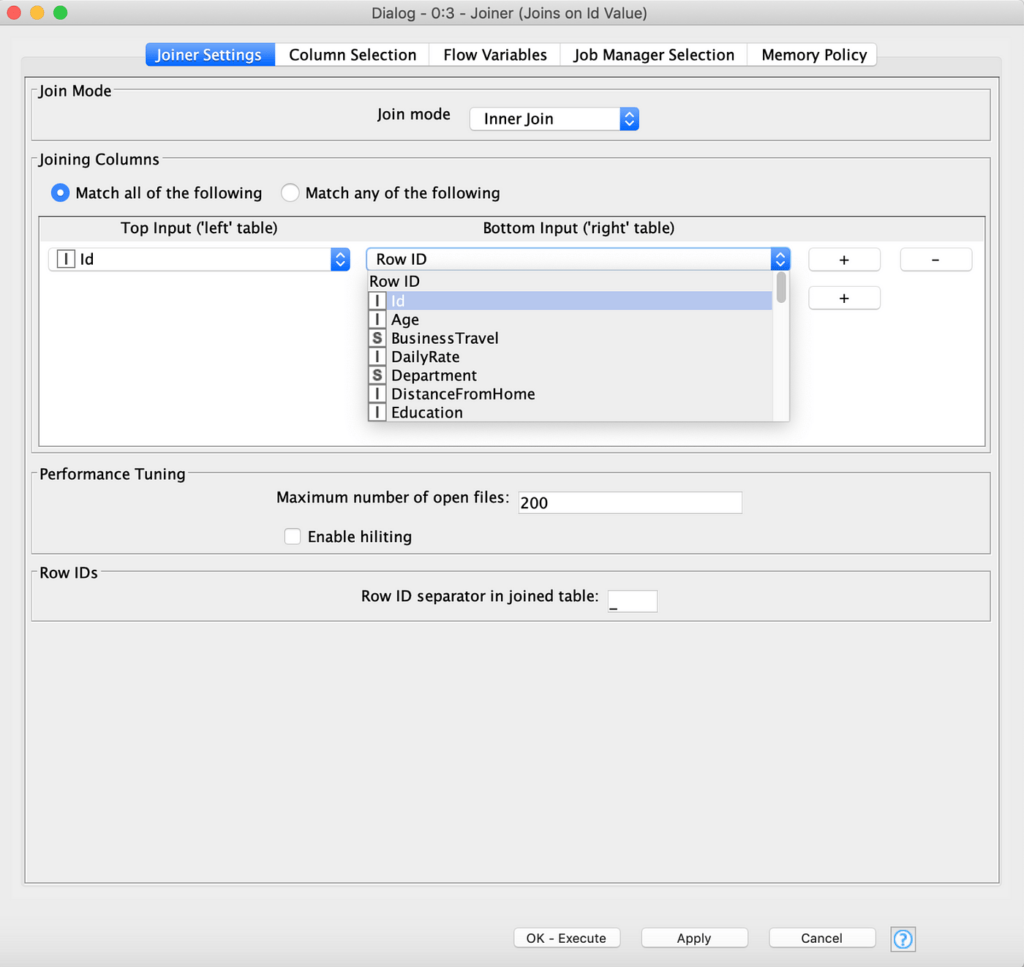
بمجرد ربط عقدة Joiner، نحتاج إلى تحديد وضع الانضمام. من خلال النقر على Joiner، يجب علينا اختيار وضع “Inner Join” واختيار الأعمدة التي ننضم إليها، والتي تسمى Id في كلا الجدولين (الشكل 10).
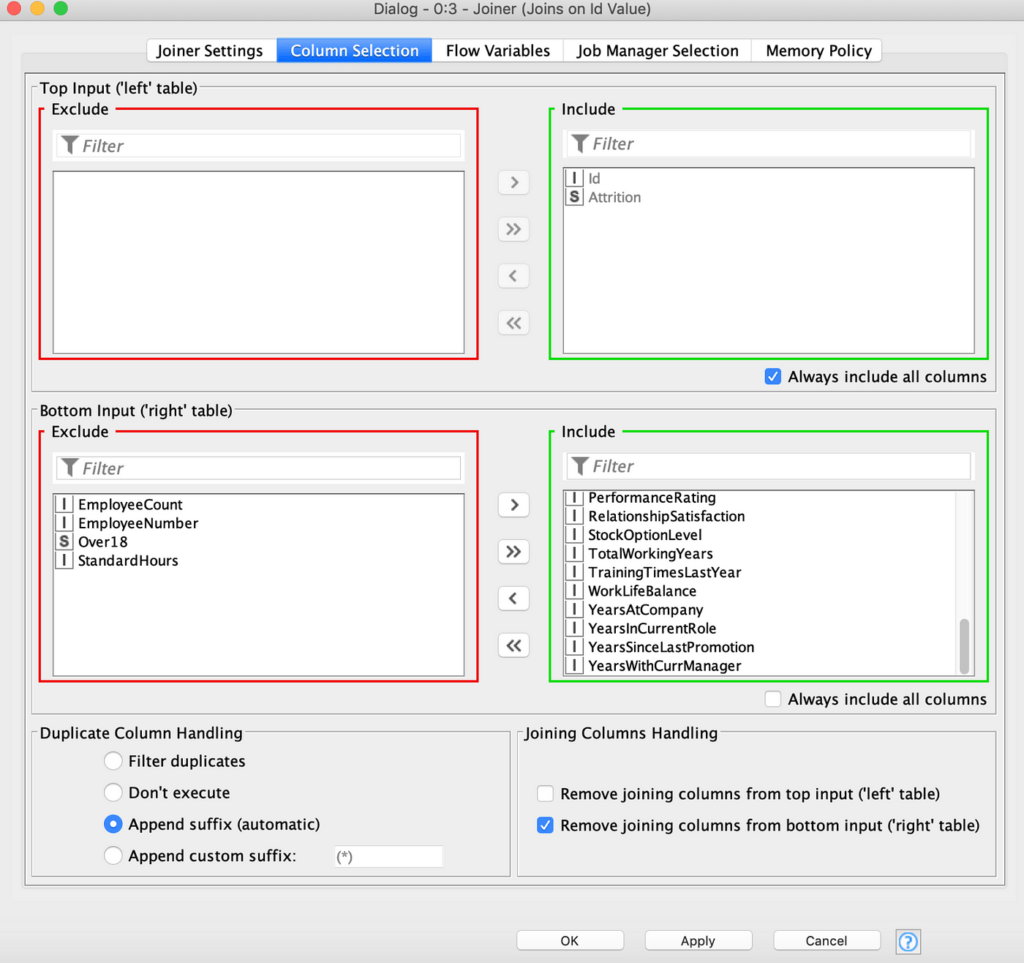
علاوة على ذلك، يمكننا استبعاد بعض الأعمدة التي تحتوي على معلومات غير ضرورية، مثل “EmployeeCount” و “EmployeeNumber” و “Over18” و “StandardHours” ، وذلك باستخدام علامة التبويب ” Column Selection ” واستخدام الأسهم في مربعات التحديد المتعددة لنقلها إلى قسم الاستبعاد Exclude section ، كما هو موضح في الشكل 11.
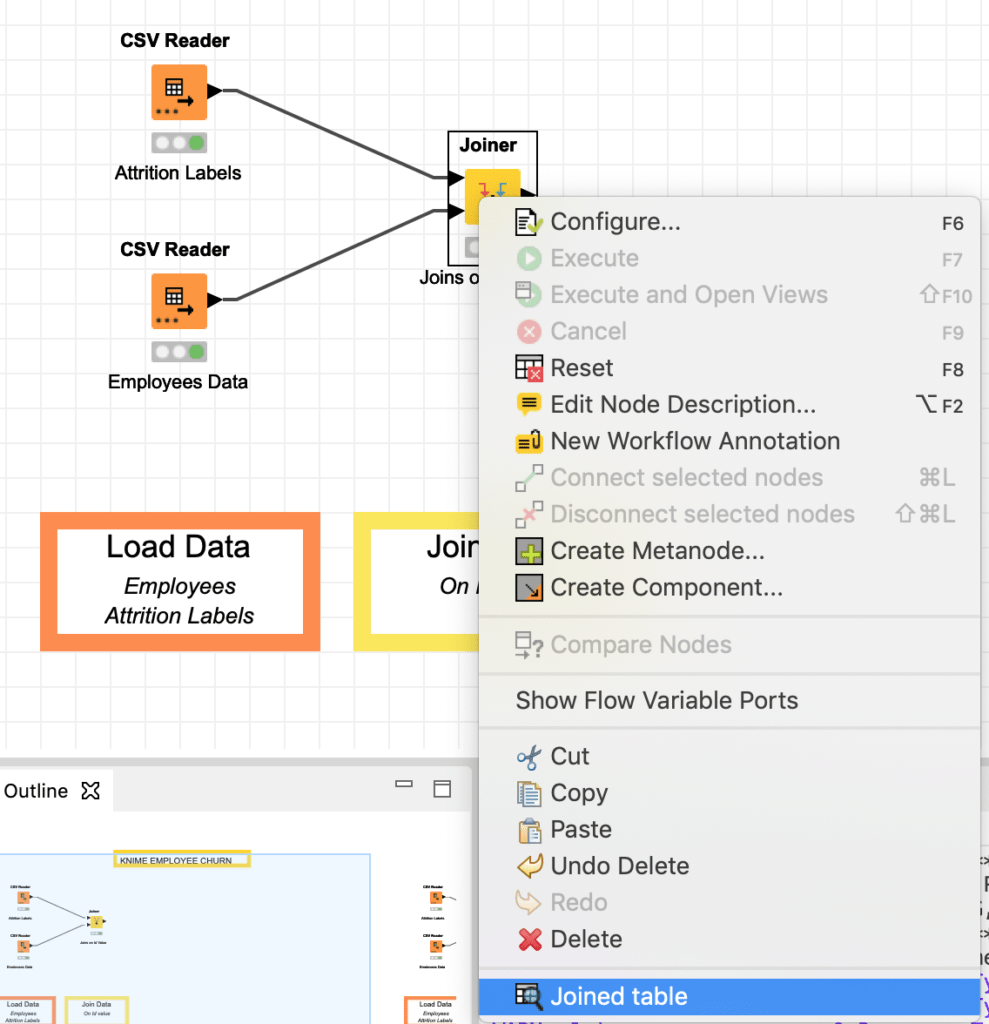
بعد النقر فوق “Apply” ، يمكننا تنفيذ Joiner بالنقر بزر الماوس الأيمن فوقه واختيار “Execute” ، والتحقق من عدم ظهور رسائل خطأ في وحدة التحكم اليمنى السفلية. يمكننا بعد ذلك التحقق من أن الجدول المنضم قد انضم بالفعل إلى معلومات “churn” الموظف مع البيانات الأخرى من خلال النقر على ” Joined Table” كما في الشكل 12. يرجى عدم وجود “traffic light” أسفل كل عقدة. يضيء الضوء باللون الأحمر عندما لا يتم ربط العقدة أو تكوينها بشكل صحيح. يصبح كهرمانيًا عندما يتم ربط العقدة وتكوينها وجاهزة للتنفيذ، وفي النهاية تصبح خضراء عندما يتم تنفيذها بنجاح.
معالجة الحقول
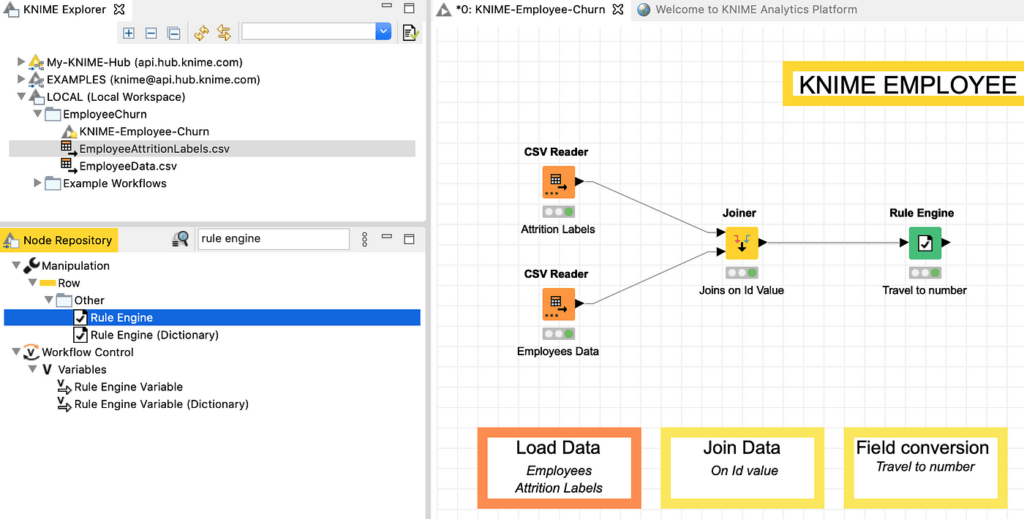
عند فحص الجدول المرتبط، نرى أن العديد من الحقول فئوية categorical وأن حقل BusinessTravel عبارة عن سلسلة من ثلاثة قيم لا تحدد السفر أو السفر ذي التردد المتوسط أو السفر عالي التردد. لجعل البيانات قابلة للإدارة من خلال نموذجنا التنبئي، نحتاج أولاً إلى تحويل BusinessTravel إلى رقم (0/1/2) ثم إلى ترميز الأعمدة الفئوية مثل “MaritalStatus” و “EducationField” و “Department” و وهكذا. للقيام بذلك، يمكننا تطبيق Rule Engine في سلسلة وعقد واحد إلى العديد One to Many. كما هو الحال من قبل، نستخدم بحث Node Repository للعثور على عقدة Rule Engine ، وسحبها إلى مساحة العمل لتوصيلها Joiner ، كما في الشكل 13.
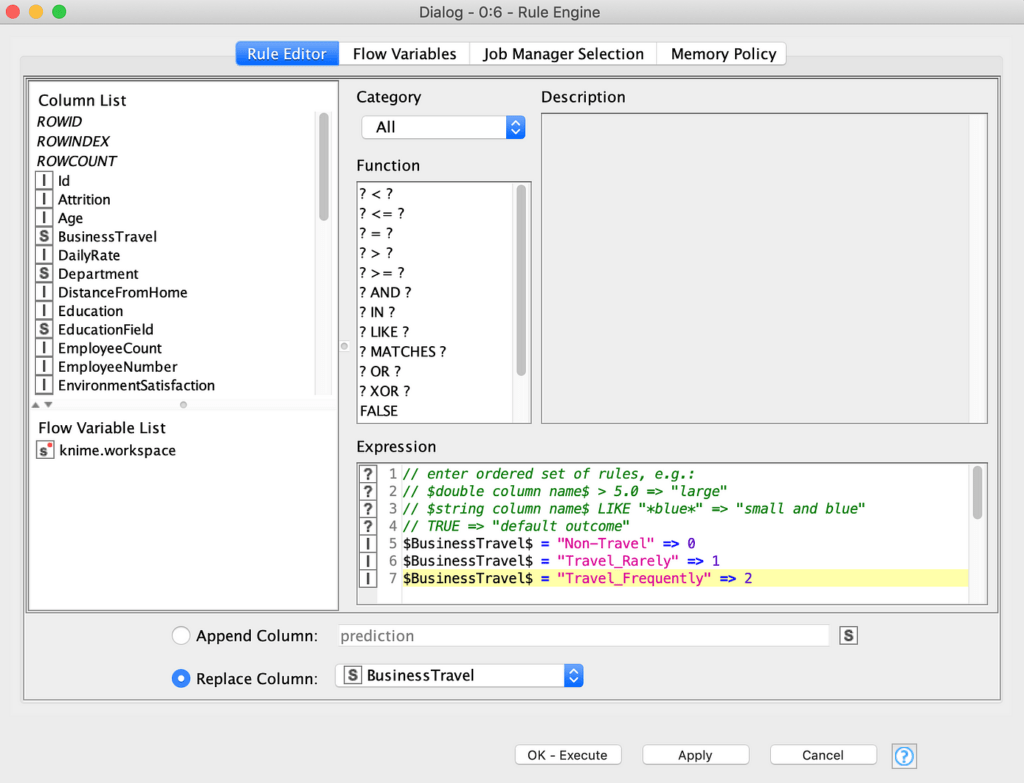
بالنقر المزدوج على عقدة Rule Engine ، يمكننا إخبار العقدة باستبدال العمود “BusinessTravel” (في أسفل النافذة مع زر الاختيار في استبدال واختيار “BusinessTravel” من القائمة المنسدلة) بقيم تساوي العدد الصحيح 0 إذا كان الحقل يحتوي على سلسلة “Non-Travel” ، 1 إذا كان يحتوي على قيمة “Travel_rarely” و 2 إذا كان يحتوي على قيمة “Travel_Frequently” ، على النحو المعبر عنه بالقواعد البسيطة التي أضفناها في مربع Expression (الشكل 14). تذكر، كالمعتاد، أن تقوم بتطبيق وتنفيذ ثم فحص النتائج.
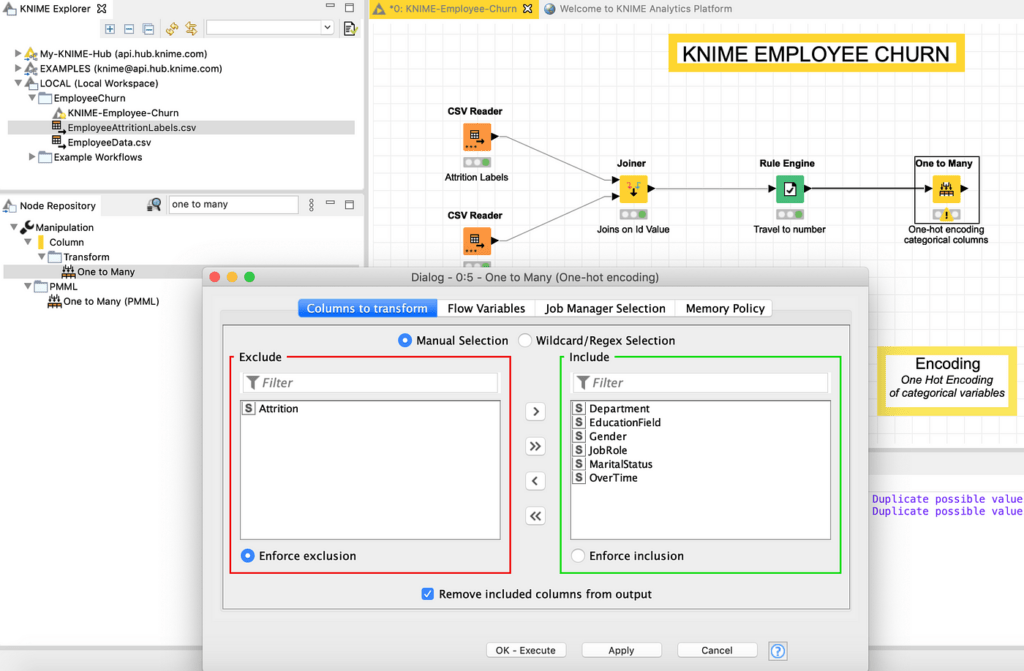
لإجراء ترميز واحد ساخن one-hot encoding ، نضيف ونربط العقدة One to Many ونهيئها لتحل محل (حدد خانة الاختيار “إزالة الأعمدة المضمنة من الإخراج Remove included columns from output “) جميع أعمدة السلسلة التي تحتوي على ترميز واحد ساخن بعيدًا عن “Attrition ” ، باستخدام الأسهم في مربع حوار التحديد المتعدد لتحريك “Attrition” على اليسار كما هو موضح في الشكل 10. “Attrition ” لا يحتاج إلى تحويل لأنه ليس متغيرًا مستقلاً لمشكلتنا، ولكنه في الواقع المتغير التابع يمكن توقعها.
هنا، لدينا تحذير (علامة تعجب صفراء على العقدة) في لوحة التحكم أدناه يقول “تم العثور على قيم مكررة محتملة. سيتم إلحاق اسم العمود الأصلي “. هذا صحيح، نظرًا لأن بعض الأعمدة المحددة لها قيم حقول متطابقة (على سبيل المثال “Human Resources” موجودة في كل من JobRole وفي أعمدة EducationalField ، لذلك لتجنب الارتباك ، ستحتوي الأعمدة الجديدة جميعها على أسماء مكونة من قيمة الحقل مرتبطًا باسم العمود الأصلي ، أي “Human_Resources_Job_Role”).
مرة أخرى، نقوم بتنفيذ وفحص النتيجة للتحقق من صحتها (تحقق من إدخال “One Hot Encoding” في قائمة المراجع إذا كنت بحاجة إلى تحديث حول الموضوع).
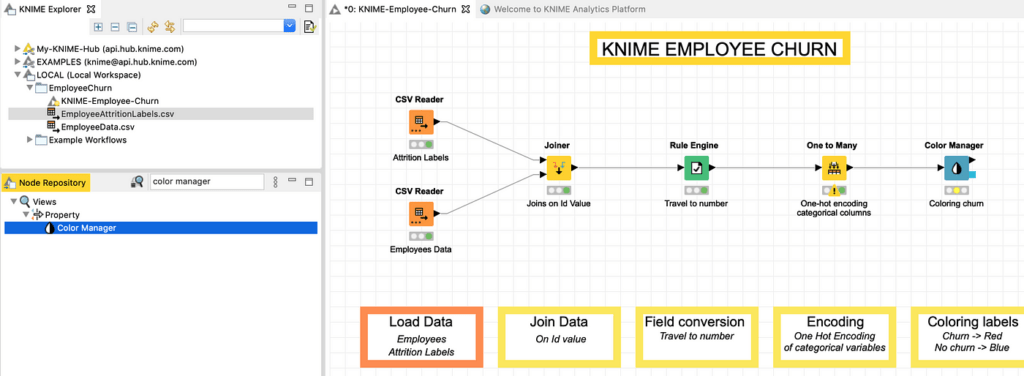
الإجراء الأخير الذي نقوم به على الحقول هو تلوين الصفوف باللون الأحمر أو الأزرق اعتمادًا على قيمة الحقل churn، وهو أمر سيصبح مفيدًا في جزء التصور visualization، عند التخطيط أو استكشاف نتائج شجرة القرار على سبيل المثال. يمكننا القيام بذلك عن طريق إضافة Color Manager وربطه كما هو موضح في الشكل 16.
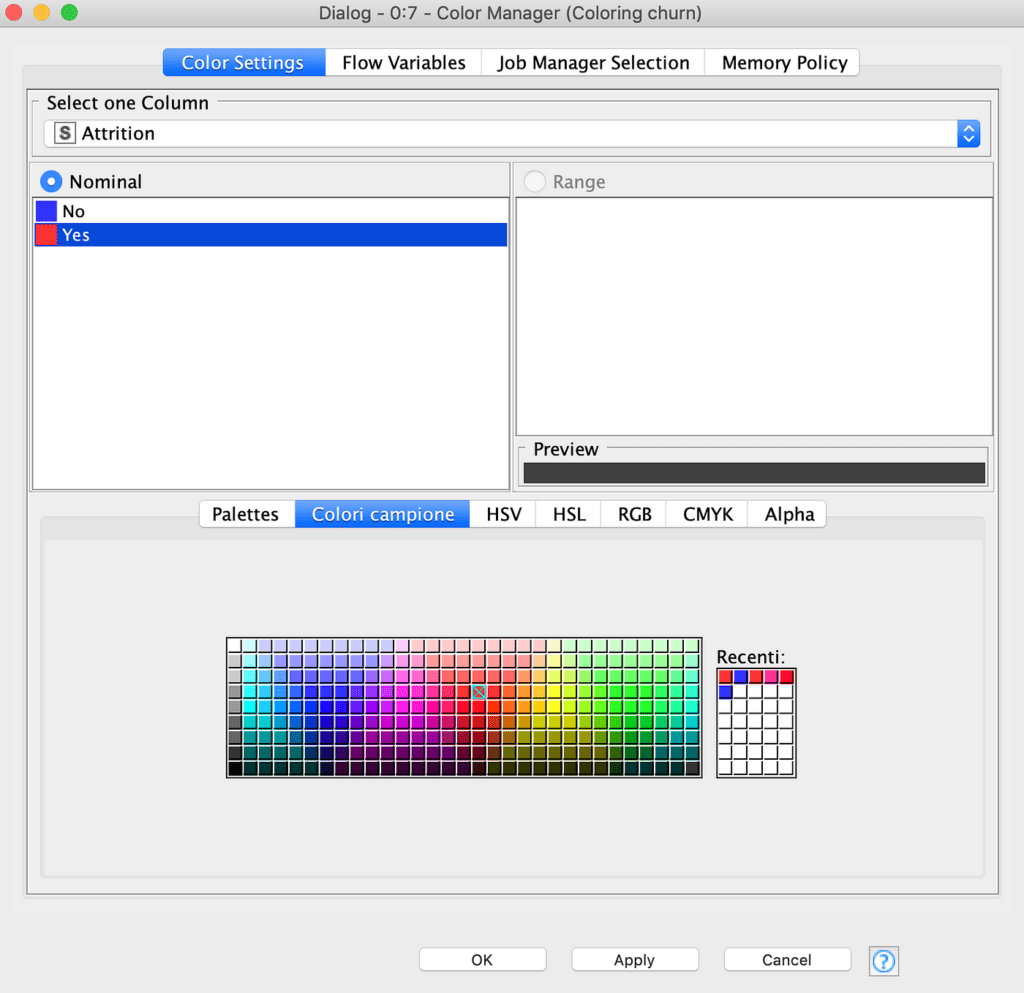
داخل Color Manager ، يمكننا ربط اللون الأحمر بقيمة Attrition “Yes” واللون الأزرق بقيمة Attrition “No” عن طريق تحديد القيم والنقر على اللون المطلوب في اللوحة كما هو موضح في الشكل 17.
التحضير: التقسيم وأخذ العينات
الخطوات الأخيرة اللازمة قبل أن نتمكن من تشغيل التدريب هي تقسيم مجموعة البيانات الخاصة بنا وأخذ عينات منها. يتم تنفيذ التقسيم لأننا نحتاج إلى “تنحية put aside ” جزء من مجموعة البيانات الخاصة بنا للتحقق لاحقًا من نموذجنا المُدرب. بالطبع، إذا تم تدريب النموذج واختباره على نفس مجموعة البيانات، فإن دقته ستكون عالية بشكل مضلل، لأنه سيتم اختباره مقابل العينات التي “شاهدها seen ” بالفعل في الماضي.
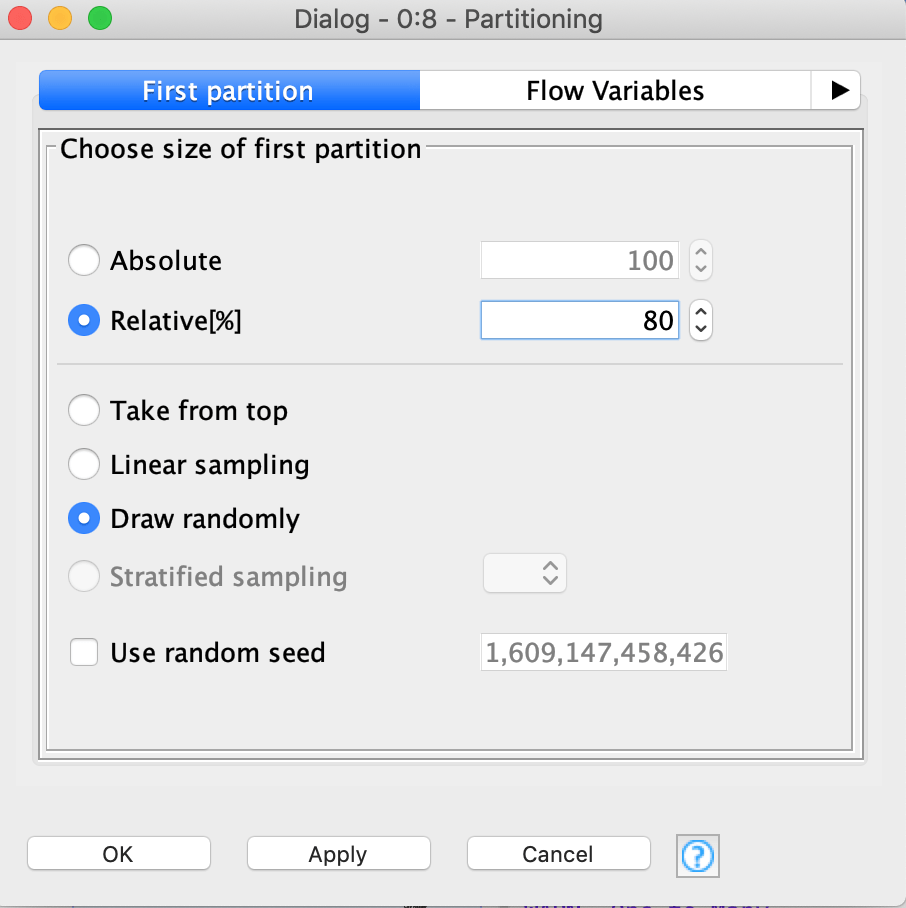
يعد تدريب النموذج على 80 ٪ من العينات والتحقق من صحتها على 20 ٪ متبقية من العينات غير المرئية سابقًا، ممارسة شائعة تستخدم لتجنب هذا الفخ وقياس قيمة دقة موثوقة. لتقسيم السجلات الحالية في مجموعتين عشوائيتين 80-20، يمكننا استخدام عقدة التقسيم Partitioning كما هو موضح في الشكل 18.
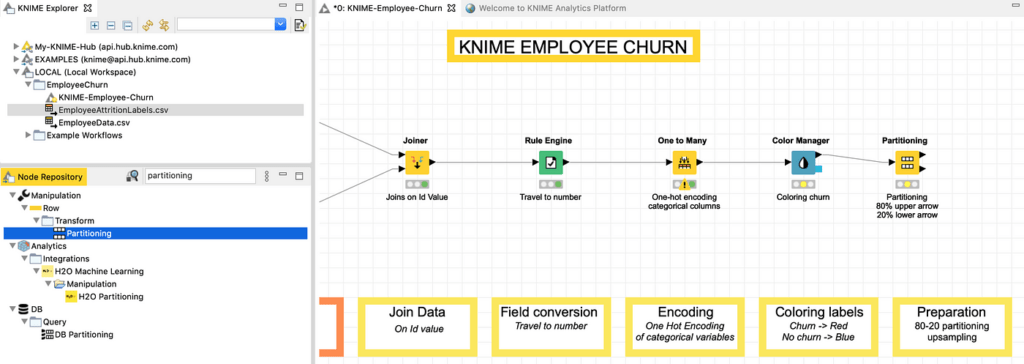
يمكن تحديد الاختيار العشوائي ونسبة 80-20 بسهولة في نوافذ عقد Partitioning ، كما هو موضح في الشكل 19.
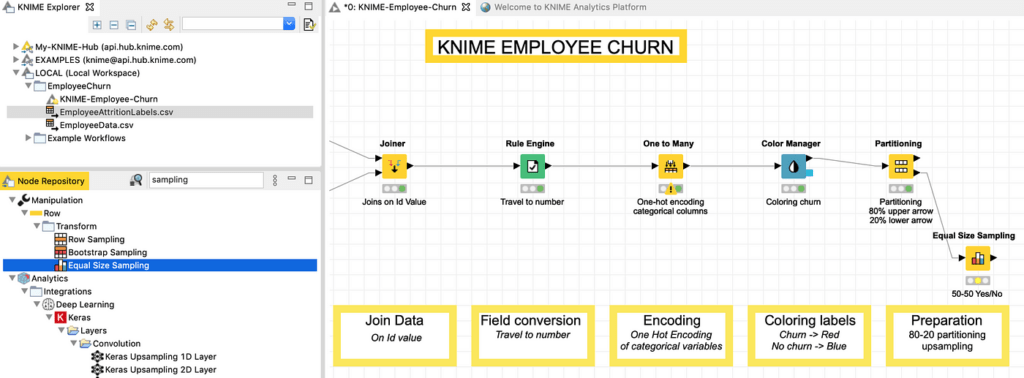
تتضمن خطوة التحضير الأخيرة مجموعة بيانات 20٪ لاستخدامها في التحقق من الصحة. يحتاج إلى مزيد من المعالجة للتأكد من أن الفئتين، أي الموظفين المستنزفين churning employees والموظفين غير المستنزفين ، non churning employees يتم تمثيلهم بشكل متساوٍ. يتم الحصول على هذا عن طريق إزالة الصفوف التي تنتمي إلى فئة الأغلبية بشكل عشوائي حتى تتساوى صفوف الفئتين في العدد.
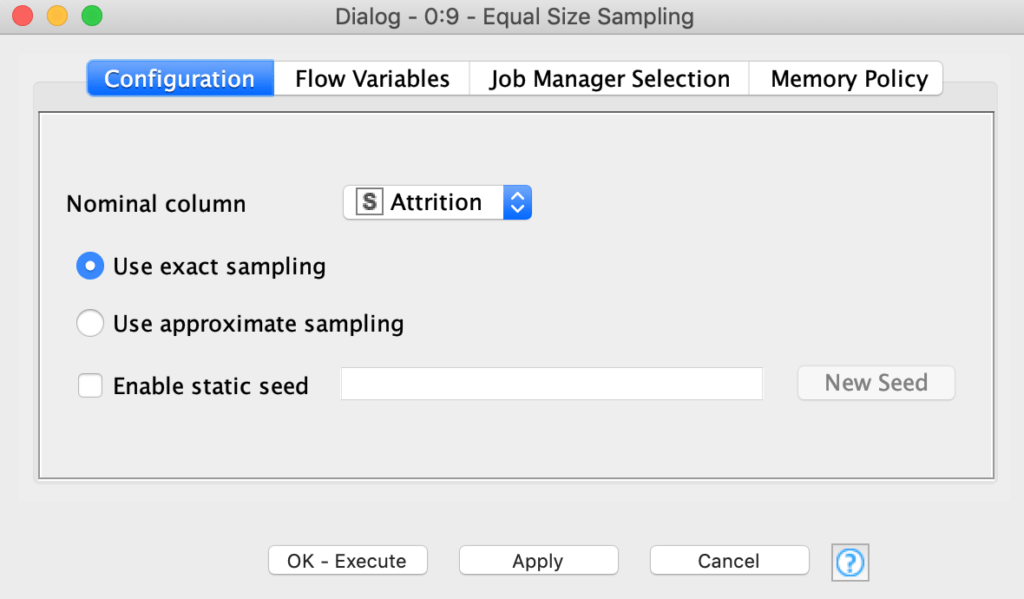
نحن بحاجة إلى هذه الخطوة لأنه إذا كانت الفئات غير متوازنة بشكل كبير، فلنفترض أن 9 من كل 10 موظفين لا يستنزفون، فإن نموذجًا بسيطًا للغاية (وغبيًا) يتنبأ بـ “عدم حدوث استنزاف no churn ” بنسبة 100٪ من الوقت سيحقق مع ذلك دقة 90٪، وهذا من شأنه تكون مضللة مرة أخرى. للحصول على تمثيل متساوٍ يمكننا استخدام عقدة Equal Size Sampling، كما هو موضح في الشكل 20.
يتم تكوين العقدة Equal Size Sampling عن طريق تحديد العمود الذي يمثل فئة اهتمامنا، في هذه الحالة “Attrition” ووضع “Use selected sampling”، كما هو موضح في الشكل 21. وكالعادة، لا تنس تنفيذ execute العقدة.
تدريب النموذج
حانت اللحظة لتدريب نموذجنا التنبئي، الذي سيكون شجرة قرار Decision Tree. شجرة القرار هي خوارزمية تقسم بشكل متكرر صفوف مجموعة البيانات في مجموعات فرعية ثنائية، مع اتخاذ قرار التقسيم في كل مرة على قيمة حدية معينة لعمود واحد، بطريقة تزيد من تجانس المجموعات الفرعية فيما يتعلق بمتغير الفئة.
هذا يعني على سبيل المثال أنه إذا كنت أقوم بتدريب شجرة قرارات للتنبؤ بجودة النبيذ الأحمر من سلسلة من المتغيرات، وكانت الخوارزمية تنقسم على قيمة محتوى الكبريتات ، فإن عتبة التركيز concentration threshold للتقسيم سوف تتوافق مع قيمة تعطي أعلى نسبة ممكنة من النبيذ الجيد في مجموعة فرعية واحدة ، والأقل في المجموعة الفرعية الأخرى.
الهدف النهائي للخوارزمية هو إنشاء أصغر شجرة، من بين العديد من الأشجار الممكنة، وفي نفس الوقت الحفاظ على الفعالية التنبؤية للشجرة نحو عينات جديدة (انظر المزيد حول أشجار القرار في فقرة تقييم النموذج وفي قائمة المراجع).
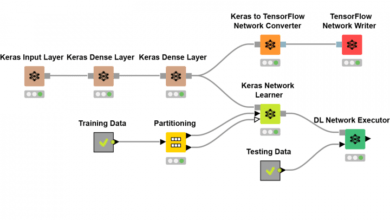
لتدريب شجرة القرار في KNIME، أحتاج إلى إنشاء عقدة Decision Tree Learner وتوصيلها بإخراج 80٪ من عقدة Partitioning كما هو موضح في الشكل 22.
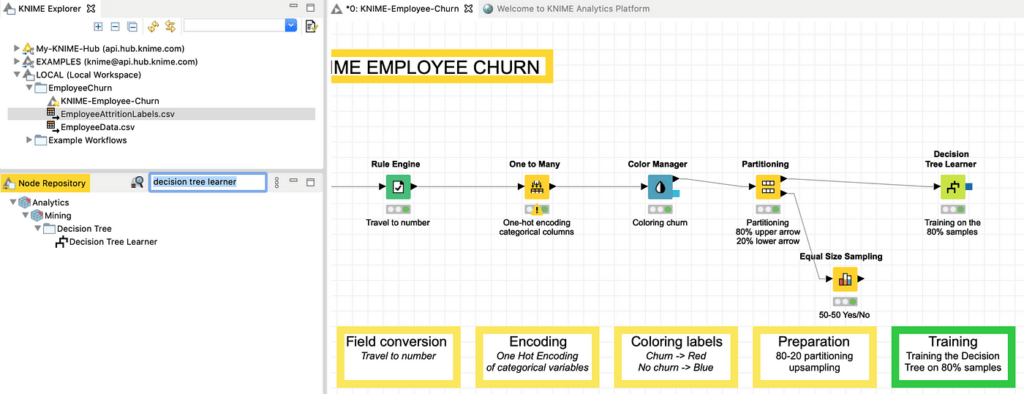
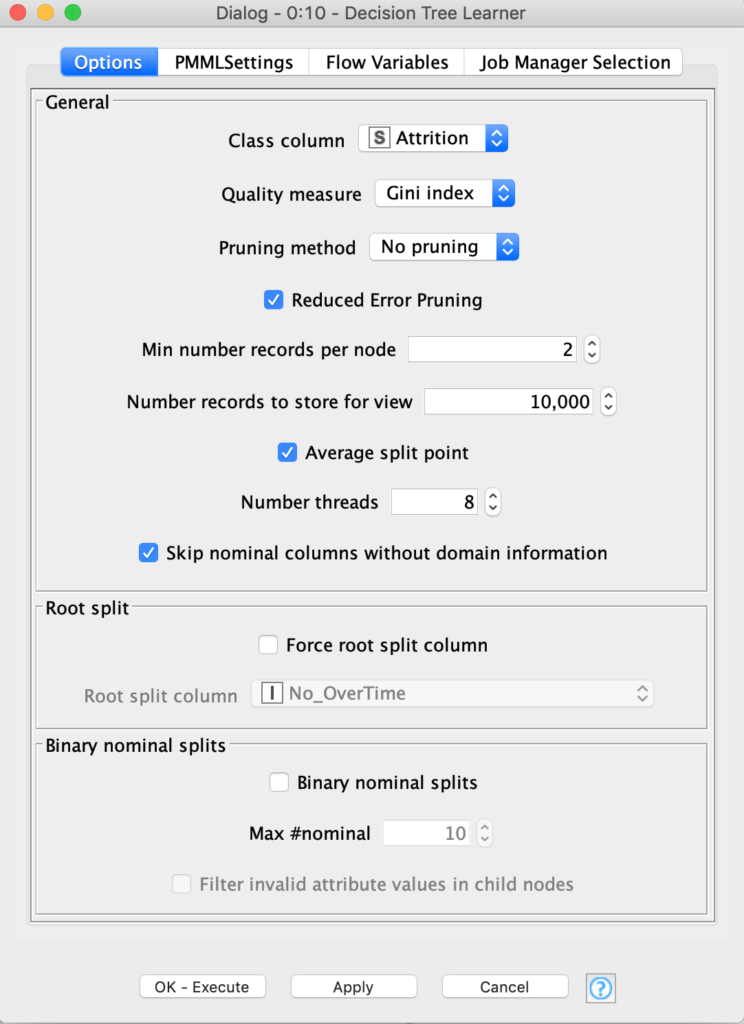
تظهر نافذة التكوين الخاصة بشجرة القرار، حيث نترك جميع المعلمات للإعداد الافتراضي لهذا البرنامج التعليمي ، في الشكل 23 (تحقق من أن الفئة الذي نقوم بتدريب الشجرة عليه هو “Attrition” بالفعل).
تقييم النموذج
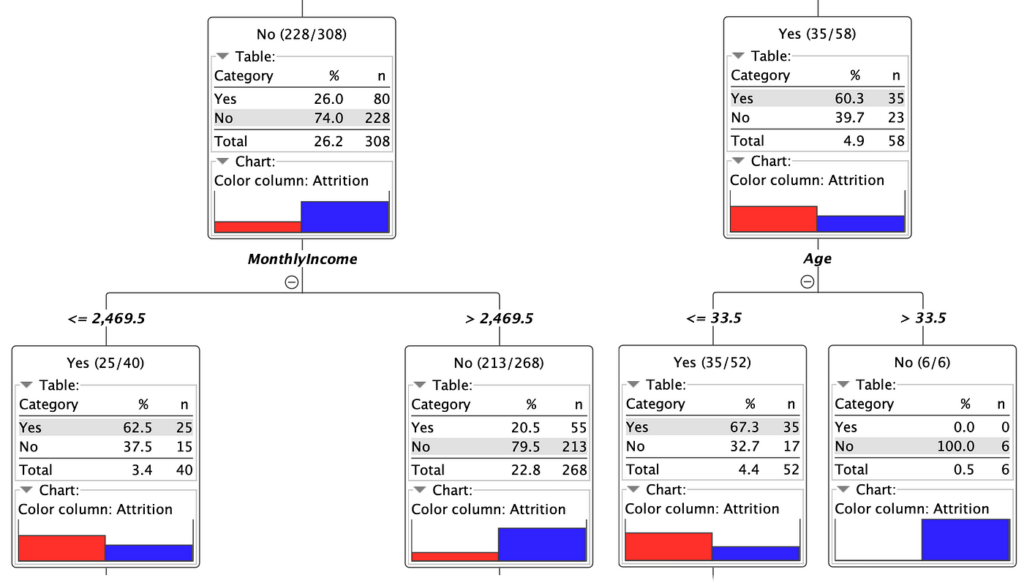
بمجرد تدريب النموذج، فإن أول شيء يمكننا القيام به هو استكشاف الرؤى المكتسبة للشجرة عن طريق النقر بزر الماوس الأيمن على عقدة Decision Tree Learner وتحديد خيار “View: Decision Tree View” من القائمة المنسدلة. كما هو مبين في الشكل 24 ، تم إجراء التقسيم الأول على عمود TotalWorkingYears ، مع حد 1.5 سنة وهو الأكثر فاعلية في الحصول على مجموعات فرعية مع أقصى قدر من الفصل فيما يتعلق بفئة Attrition.
مرة أخرى من الشكل، حصلنا على فكرة قيمة: احتمال حدوث استنزاف أعلى بكثير بالنسبة للأشخاص الذين أمضوا في الشركة أقل من 1.5 سنة ، وعندما يتم تجاوز هذا الحد يصبح أقل بكثير ، لذلك يجب أن تحظى الشركة برعاية خاصة في الاحتفاظ بالموظفين الجدد.
استكشاف الشجرة باستخدام navigator الموجود على يمين طريقة عرض الشجرة وعن طريق فتح الفروع بالرمز “+” ، يمكن العثور على رؤى مفيدة أخرى ، على سبيل المثال تلك الموضحة في الشكل 25 ، والتي تعرض كيف يمكن للأشخاص الذين تقل أعمارهم عن 33.5 عامًا أو لديهم الدخل الشهري أقل من 2470 دولارًا من المرجح أن يغادروا.
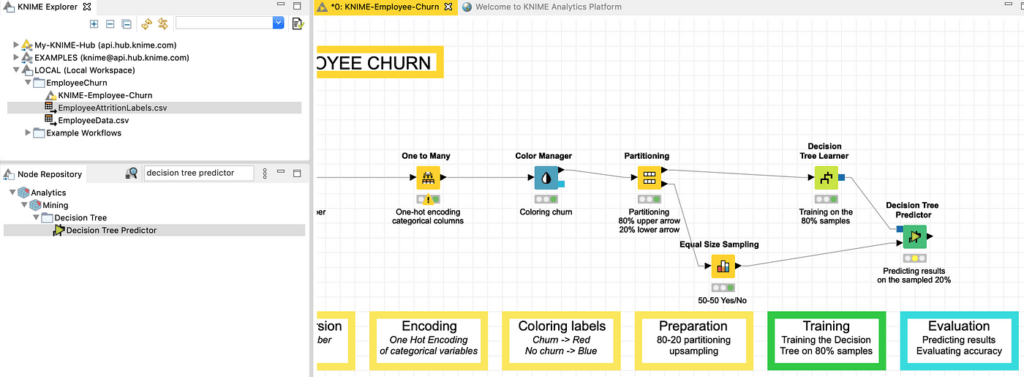
علاوة على ذلك، يمكننا التحقق من دقة النموذج في مجموعة البيانات بنسبة 20٪، وإدخال النموذج في عقدة Decision Tree Predictor، وهي العقدة القادرة على تحميل نموذج شجرة قرار مدرب والتنبؤ بنتائج الفئة مقابل مجموعة بيانات الإدخال. عقدة Decision Tree Predictor موضحة في الشكل 26. هنا أيضًا نقبل المعلمات الافتراضية وننفذ العقدة.
يمكن استكشاف نتائج التنبؤ عن طريق النقر بزر الماوس الأيمن على العقدة واختيار “Classified Data” في أسفل القائمة المنسدلة. يظهر عمود جديد على اليمين، يسمى Prediction (Attrition) ويمكن التحقق من النتائج المتوقعة بصريًا مقابل التسمية الأصلية، والتي يتم تقديمها من خلال لون السجل (أحمر = “نعم” ، أزرق = “لا”) ، كما هو موضح في الشكل 27.

لقياس عدد التنبؤات التي كانت صحيحة أو خاطئة، يمكننا إضافة وتنفيذ العقدة الأخيرة من هذا البرنامج التعليمي، وهي عقدة Scorer، كما هو موضح في الشكل 28.
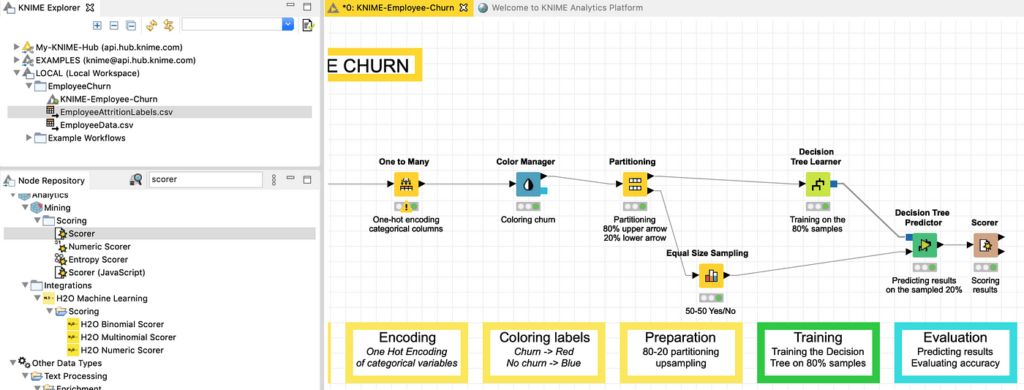
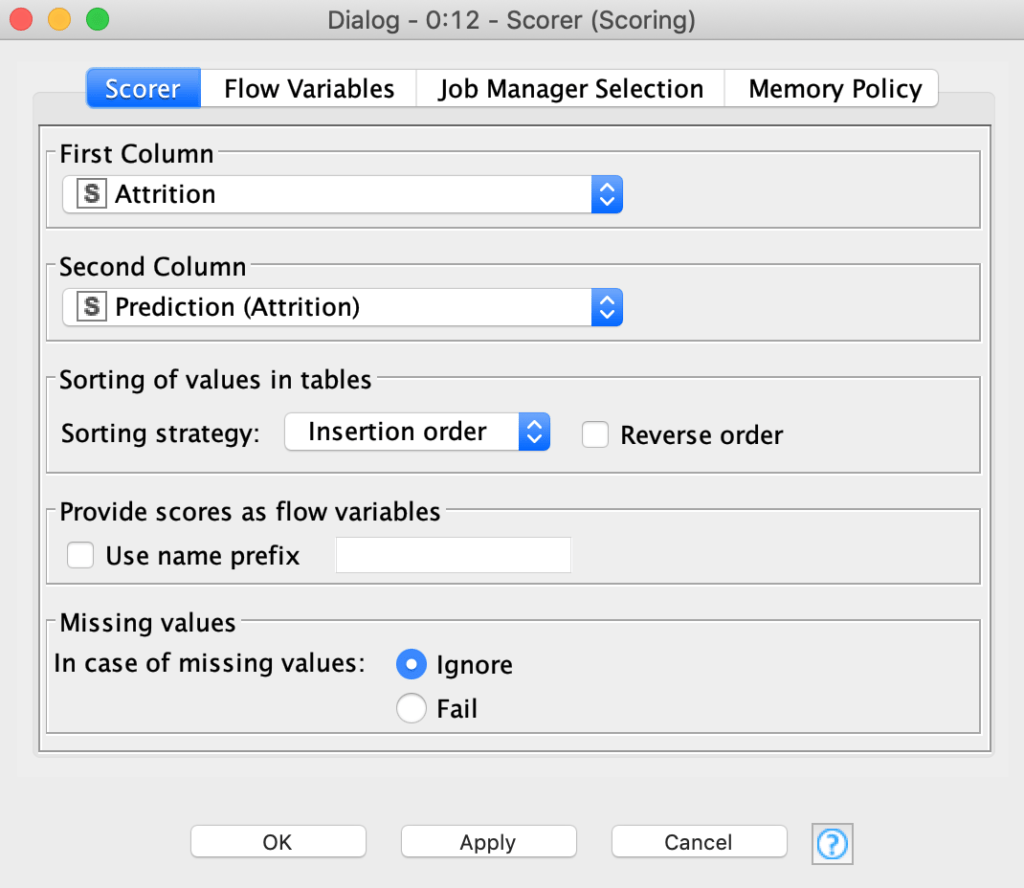
يتم تكوين عقدة Scorer كالمعتاد عن طريق النقر المزدوج عليها ، من خلال الانتباه إلى حقيقة أن قياس الدقة يجب أن يتم بين “Attrition” و ” Prediction(Attrition) ” كما هو موضح في الشكل 29.
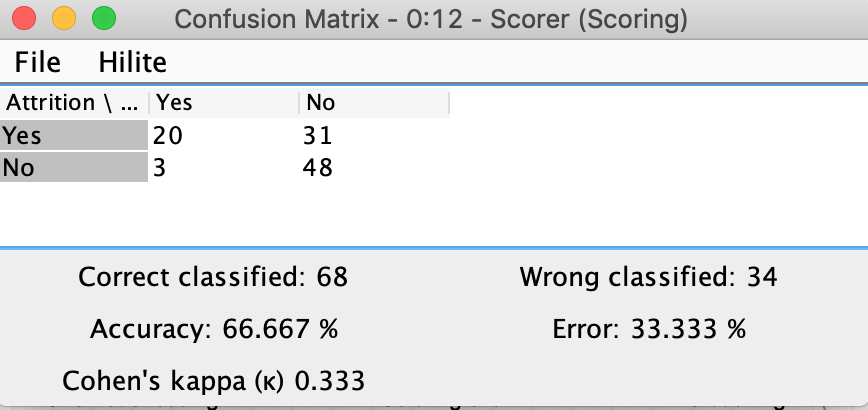
أخيرًا، يمكننا التحقق من دقة النموذج عن طريق النقر بزر الماوس الأيمن على عقدة Scorer وتحديد عرض: خيار مصفوفة الارتباك Confusion Matrix ، كما هو موضح في الشكل 30. كما هو موضح في الشكل، 48 من أصل 51 من غير المستنزفين (صف “لا” في المصفوفة) تم تحديدها بشكل صحيح، بينما تم تحديد 20 فقط من أصل 51 مستنزفين بشكل صحيح.
هذا أعطى ما مجموعه 68 عينة مصنفة بشكل صحيح مقابل 34 مصنفة بشكل خاطئ، وبدقة إجمالية 2/3 (66،667٪). هذا بالتأكيد أفضل من المصنف “العشوائيrandom” ، والذي من شأنه أن يعطي دقة بنسبة 50٪ على مجموعة بيانات متوازنة بشكل متساوٍ ، وليست نتيجة سيئة لنموذج يستخدم جميع الإعدادات الافتراضية دون أي ضبط دقيق fine-tuning ، ولكن بالتأكيد يحتوي سير العمل على مجال واضح للتحسين (كتلميح لمزيد من الممارسة ، حصل المؤلف على دقة بنسبة 85٪ باستخدام نموذج الانحدار اللوجستي Logistic Regression بدلاً من شجرة القرار Decision Tree).
الاستنتاجات
لقد أنشأنا سير عمل بيانات بسيطًا للغاية ونموذجًا تنبئيًا باستخدام بيئة KNIME المرئية. هنا يمكنك تنزيل Workflow المستخدم في المثال. هناك الكثير لنتعلمه في دورة KNIME الذاتية وفي الاوراق الخاصة بـ KNIME (انظر قائمة المراجع).
لى أمل أن تجد هذه المقالة مفيدة، أشجعك على الاتصال بي عبر LinkedIn للحصول على تعليقات أو اقتراحات أو مجرد التواصل.
المراجع
Decision Tree: https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
KNIME cheat sheets: https://www.knime.com/cheat-sheets
KNIME self-paced course: https://www.knime.com/knime-self-paced-courses
IBM HR Analytics Employee Attrition & Performance: https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset
One Hot Encoding: https://towardsdatascience.com/what-is-one-hot-encoding-and-how-to-use-pandas-get-dummies-function-922eb9bd4970
Download the workflow shown in the example from the KNIME Hub: https://we.tl/t-bbHp182L0C
As previously published on LinkedIn Pulse https://www.linkedin.com/pulse/codeless-data-science-knime-fabio-rebecchi/