- إنشاء سير عمل (workflow)
- استيراد ملفات البيانات
- استكشاف البيانات والمعالجة المسبقة
- تقسيم البيانات
- خط أنابيب التعلم الآلي: تدريب واختبار وتقييم
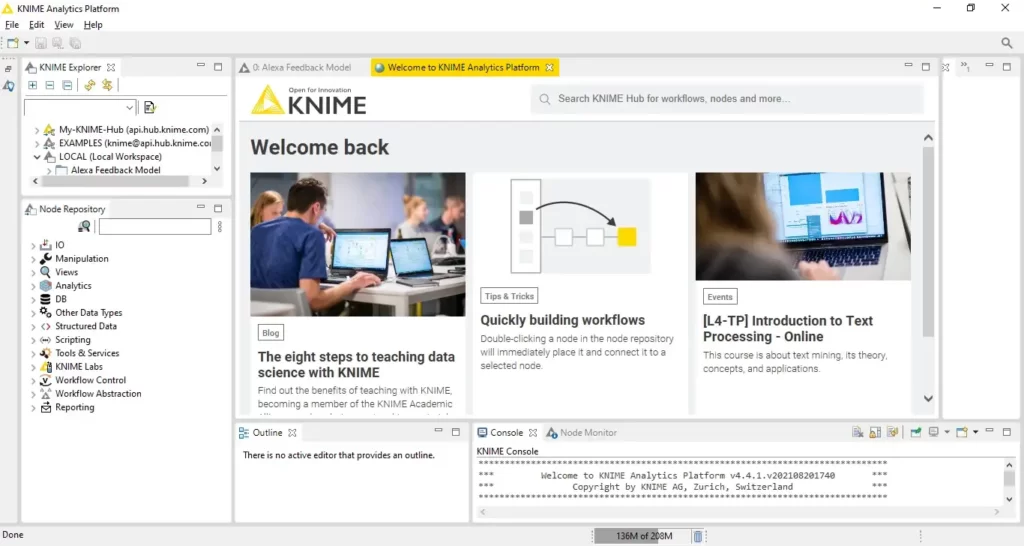
KNIME Analytics Platform هي مصدر مفتوح ، وبرنامج بدون كود لإنشاء مشاريع علوم البيانات من طرف إلى طرف – من إعداد البيانات والتعلم الآلي إلى تصوير البيانات ، وأكثر من ذلك بكثير. فيما يلي المزايا الرئيسية:
- لا داعي لمعرفة Python أو R أو أي لغة برمجة أخرى لبناء نموذج تعلم آلي او عميق.
- يمنحك المرونة في كتابة القواعد المعرفة من قبل المستخدم، والبيانات المنطقية والمزيد لمطابقة الصفوف المطلوبة.
- وهو يدعم جميع أنواع خوارزميات التعلم الآلي والتعلم العميق لأي حالة استخدام ملفوفة في واجهة مستخدم رسومية سهلة الاستخدام.
في هذه المقالة، سأقدم لك جولة سريعة حول كيفية إنشاء نموذج للتعلم الآلي باستخدام KNIME Analytics Platform من البداية.
للبدء ، نحتاج إلى إنشاء سير عمل في KNIME.
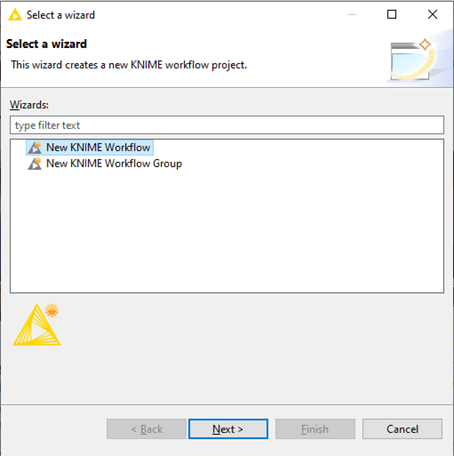
إنشاء سير عمل (workflow)
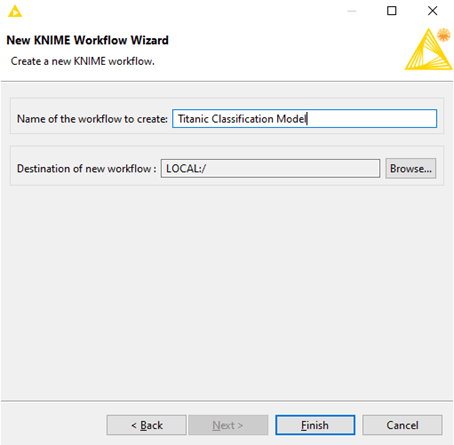
انقر فوق File -> New -> اختر New KNIME Workflow-> انقر فوق التالي
قم بتسمية سير عمل KNIME الخاص بك -> انقر فوق Finish.

استيراد ملفات البيانات
بعد إنشاء سير العمل، فإن الخطوة الأولى هي استيراد مجموعة بيانات.
هنا، سنستخدم مجموعة بيانات تيتانيك titanic (التدريب train) المشهورة عالميًا.
يمكن لأولئك الذين ليس لديهم مجموعة البيانات العملاقة تنزيلها على Kaggle من هذا الرابط: https://www.kaggle.com/c/titanic/data
الآن، دعنا نعود إلى KNIME. يوضح الشكل 5 سير عمل KNIME فارغًا في محرر سير العمل (Workflow Editor).
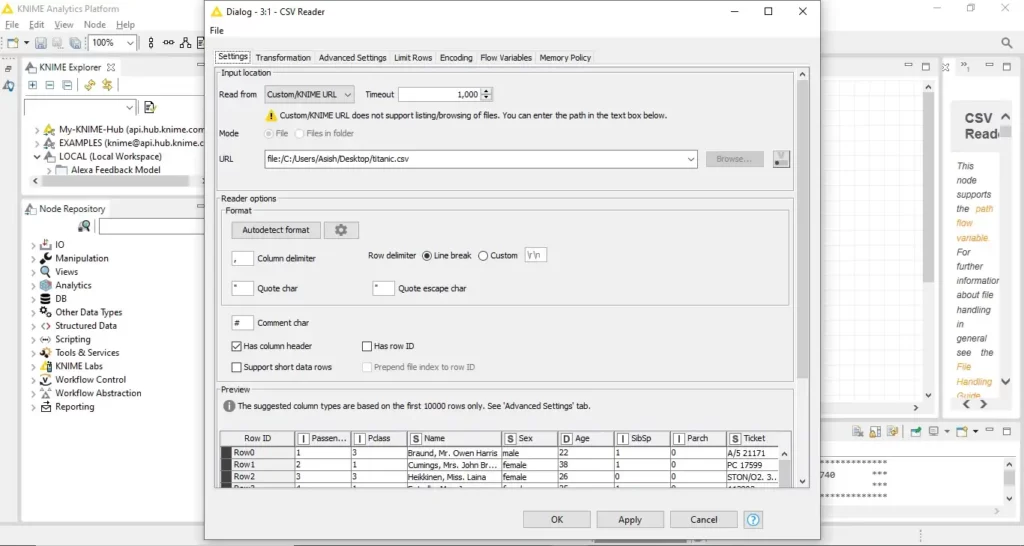
يمكننا سحب وإسقاط أي ملف Excel أو CSV أو بيانات بتنسيقات أخرى مباشرة في Workflow Editor. اسحب مجموعة البيانات العملاقة وأفلتها في أي مكان في سير العمل الفارغ. بعد إسقاط الملف، ستظهر نافذة منبثقة وتطلب تكوين configure قارئ الملفات المقابل – في هذه الحالة عقدة CSV Reader. كل ما علينا فعله هو النقر فوق “OK” في نافذة التكوين configuration window.
بمجرد استيراد مجموعة البيانات الخاصة بنا بنجاح، هناك ثلاثة أشياء يجب تذكرها: تسمى وحدات البناء لكل سير عمل KNIME بالعقد ولها ثلاث حالات لونية مثل إشارات المرور:
- يعني اللون الأحمر أن العقد لم يتم تكوينها بعد.
- يعني اللون الأصفر أنه تم تكوين العقد ولكن لم يتم تنفيذها بعد.
- يعني اللون الأخضر أن العقد تم تنفيذها بنجاح.
الآن، نحن بحاجة إلى تنفيذ عقدة CSV Reader. للقيام بذلك، ما عليك سوى النقر بزر الماوس الأيمن على العقدة وتحديد Execute في مربع الحوار.
بعد التنفيذ، يتغير لون العقدة من الأصفر إلى الأخضر، ويمكننا رؤية بياناتنا عن طريق النقر بزر الماوس الأيمن على العقدة واختيار File Table.
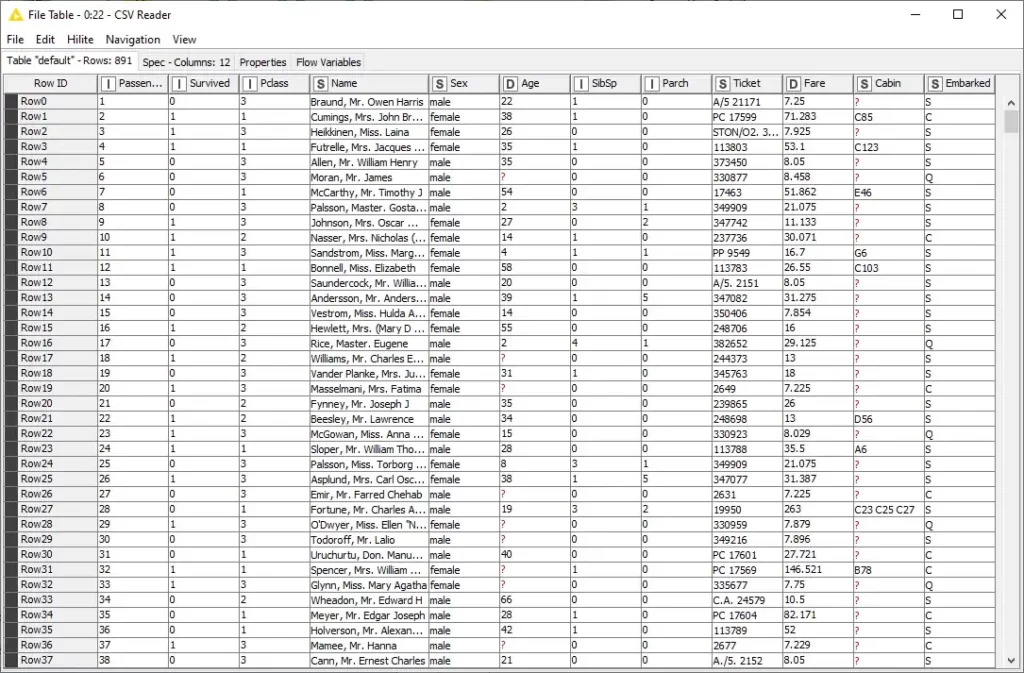
نعم، الأمر بهذه السهولة! الآن، نحتاج فقط إلى إضافة جميع العقد التي نحتاجها لتدريب نموذج التعلم الآلي وتطبيقه عن طريق ربط كل واحدة بالتسلسل من اليسار إلى اليمين. يمكننا بعد ذلك التحقق من دقة نموذجنا وكذلك مقارنة أداء نماذج التعلم الآلي المختلفة.
استكشاف البيانات والمعالجة المسبقة
قبل أن نبدأ في بناء نموذجنا، دعنا أولاً نتحقق من إحصائيات مجموعة البيانات الخاصة بنا باستخدام عقدة Statistics.
للقيام بذلك، ابحث عن عقدة Statistics في Node Repository واسحبها وأفلتها في Workflow Editor. بعد ذلك، قم بتوصيل منفذ الإخراج لعقدة قارئ CSV بمنفذ الإدخال لعقدة Statistics، وتنفيذ الأخير.
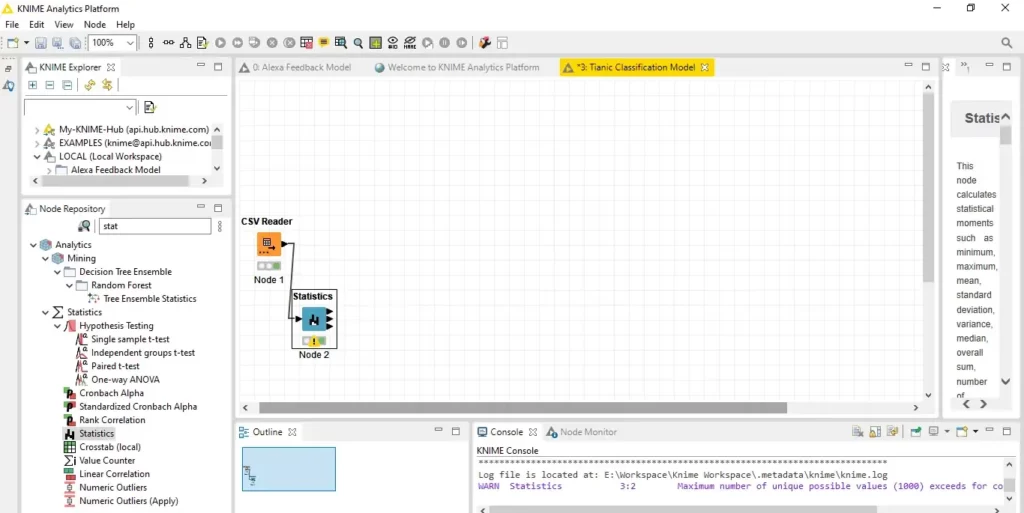
بمجرد نجاح التنفيذ، يمكننا التحقق من جدول الحالات كما هو موضح أدناه.
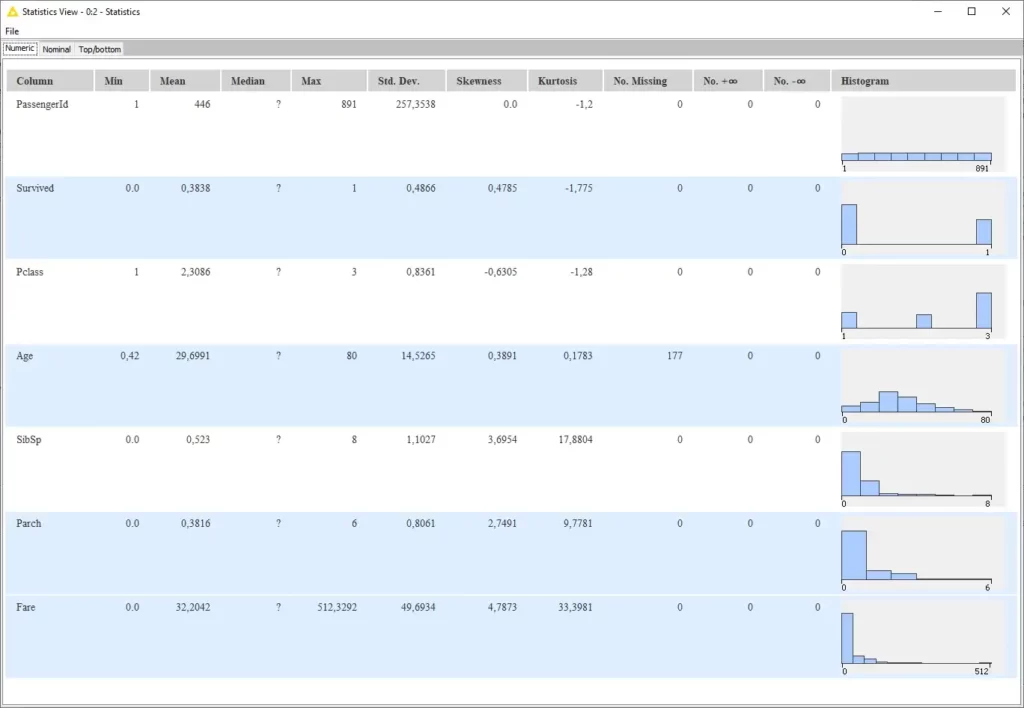
باستخدام عقدة Statistics، يمكننا التحقق من الإحصائيات – الحد الأدنى min، الحد الأقصى max، المتوسط mean، الانحراف المعياري SD ، kurtosis، الانحراف skewness، وما إلى ذلك – لكل ميزة في بياناتنا.
كما نرى، لدينا قيم مفقودة في بعض الميزات. قبل المضي قدمًا، نحتاج إلى التعامل معها.
على سبيل المثال، لدينا قيم مفقودة في الميزات الرقمية age، وفي الميزات الاسمية cabin وembarkedهذا يعني أننا بحاجة إلى تنفيذ بعض الاستراتيجيات إما لإسناد القيم المفقودة أو إسقاطها (في هذا البرنامج التعليمي سنناقش فقط احتساب القيم المفقودة في ميزة age).
لكتابة قواعد محددة من قبل المستخدم، يمكننا استخدام عقدة Rule Engine. ومع ذلك، قبل القفز إلى عقدة Rule Engine ، أود استخدام عقدة String Manipulation لإنشاء ميزة جديدة – من خلال إلحاقها بمجموعة البيانات الأصلية – تحتوي على الأحرف الأربعة الأولى الموجودة في اسم الركاب.
مثال. من “Mr. Ashish Kumar “، نحتفظ بـ” Mr. “في ميزتنا الجديدة.
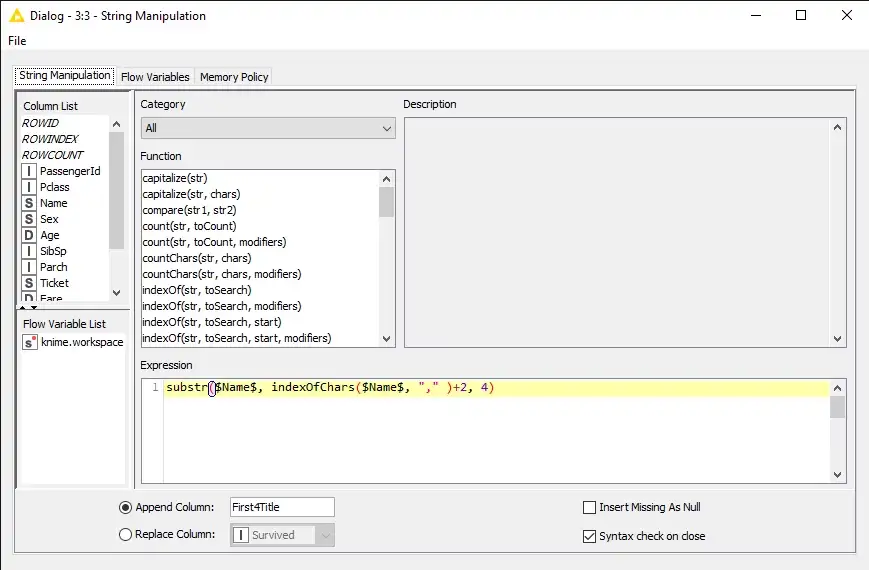
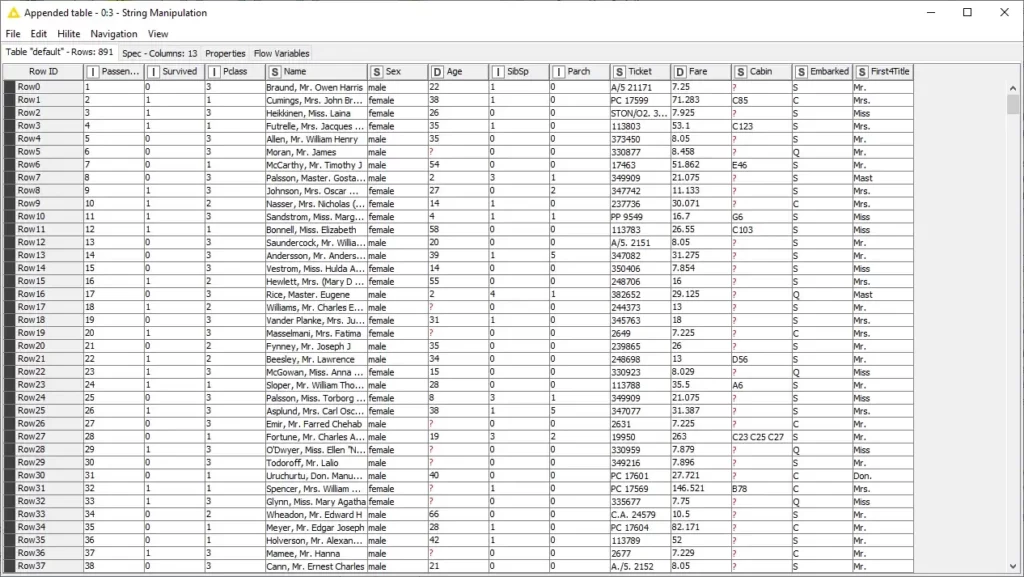
بمجرد تكوين العقدة ، يمكننا تنفيذها والتحقق من الميزة الملحقة في جدول الإخراج لعقدة String Manipulation.
الآن، يمكننا استخدام Rule Engine لكتابة قواعد معرّفة من قبل المستخدم من أجل البدء في إنشاء أقواس age ، وإلحاق العمود بمجموعة البيانات الخاصة بنا.
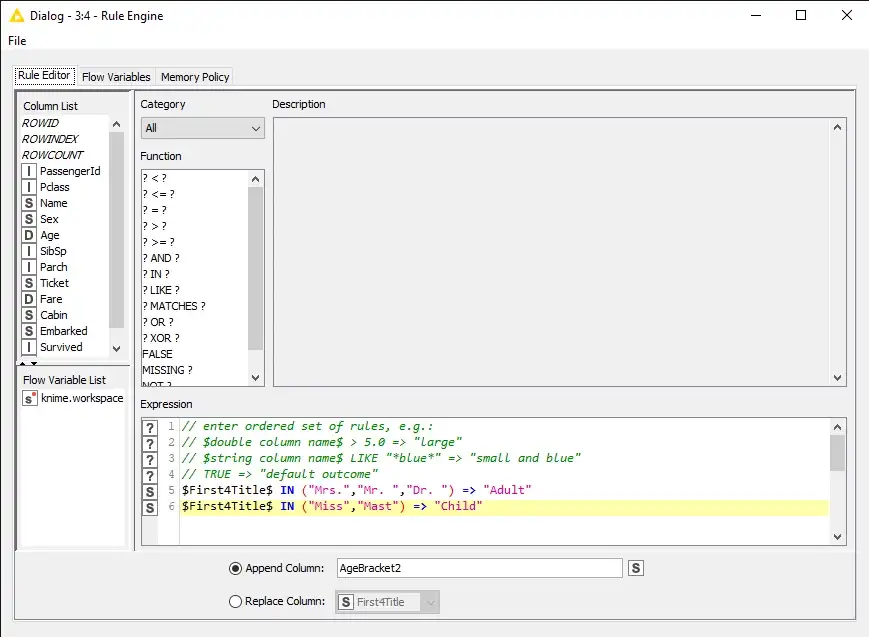
بعد تنفيذ عقدة Rule Engine ، يمكننا استكشاف جدول الإخراج. كما نرى، تم إنشاء ميزة جديدة تعكس القواعد التي حددناها في العقدة.
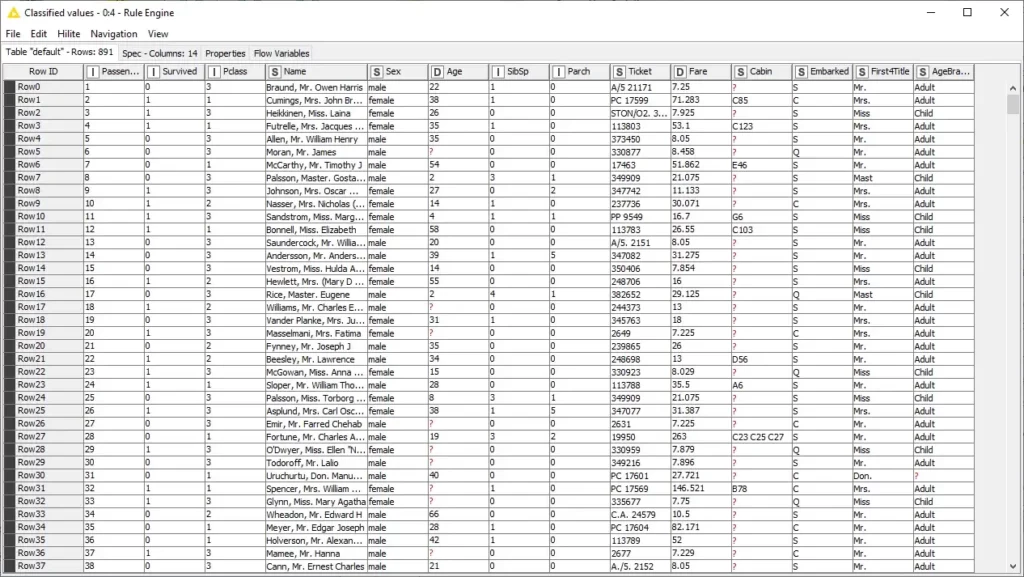
الآن، يمكننا إكمال إنشاء الفئات العمرية باستخدام ميزتنا الجديدة. يمكننا مرة أخرى كتابة قواعد يحددها المستخدم لإنشاء فئات عمرية وفقًا لفئة عمرية مختلفة.
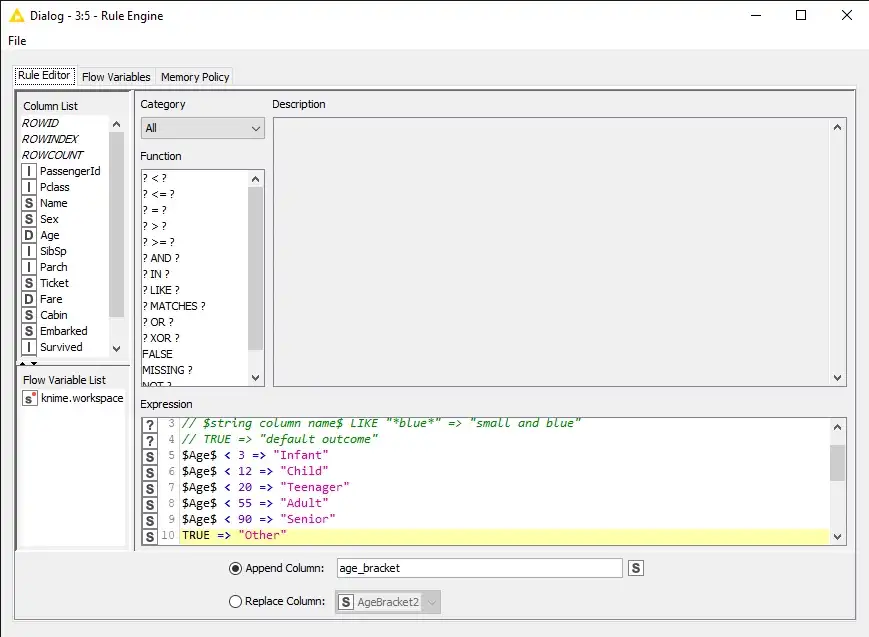
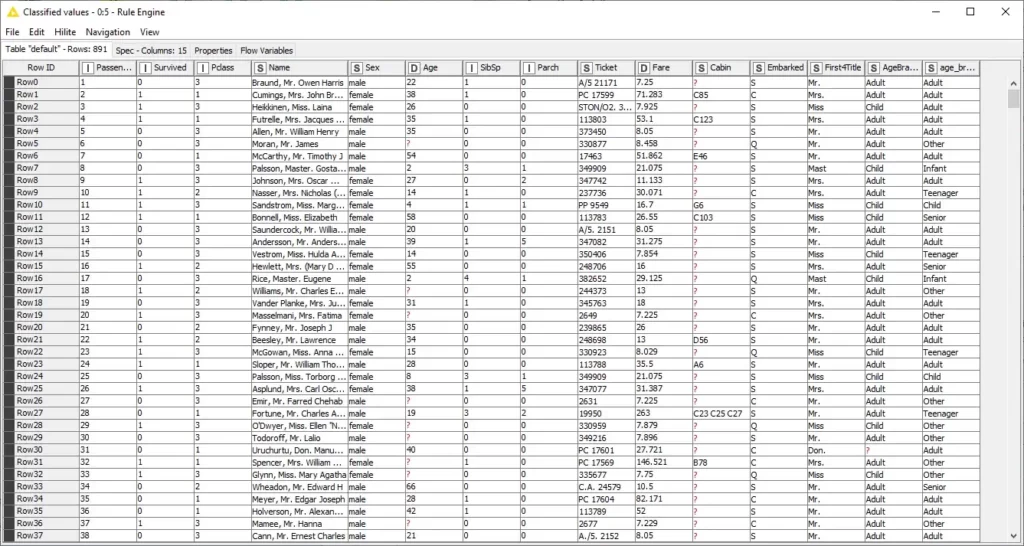
الآن، يمكننا استبدال جميع القيم المفقودة في الميزة AgeBracket2 باستخدام ميزة age_bracket الخاصة بنا ، وإلحاق النتائج في عمود جديد.
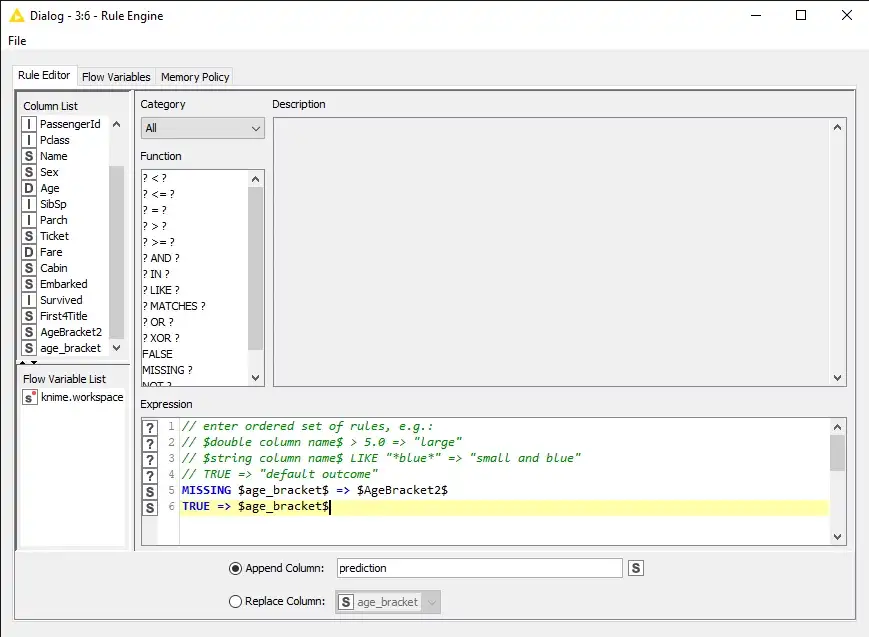
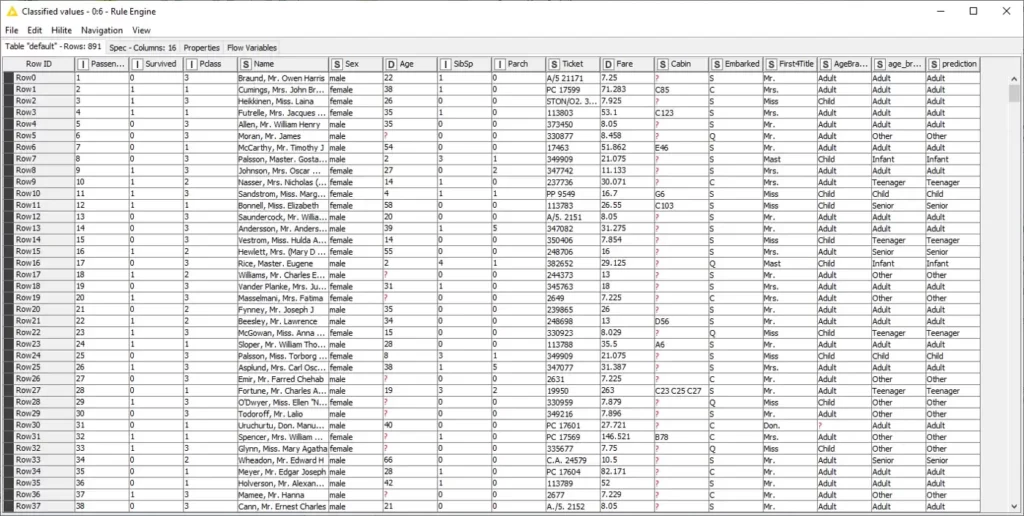
هناك خيار آخر للتعامل مع القيم المفقودة وهو استخدام عقدة القيمة المفقودة Missing Value. يتيح استخدام هذه العقدة احتسابًا سريعًا وبديهيًا ومباشرًا لكل من القيم العددية والاسمية المفقودة. اعتمادًا على حالة الاستخدام، يمكن أن تكون هذه العقدة حلاً مفضلاً على كتابة القواعد المعرفة من قبل المستخدم في عقدة Rule Engine. نستخدم الآن عقدة Missing Value لتحديد القيم الرقمية المفقودة في ميزة age.
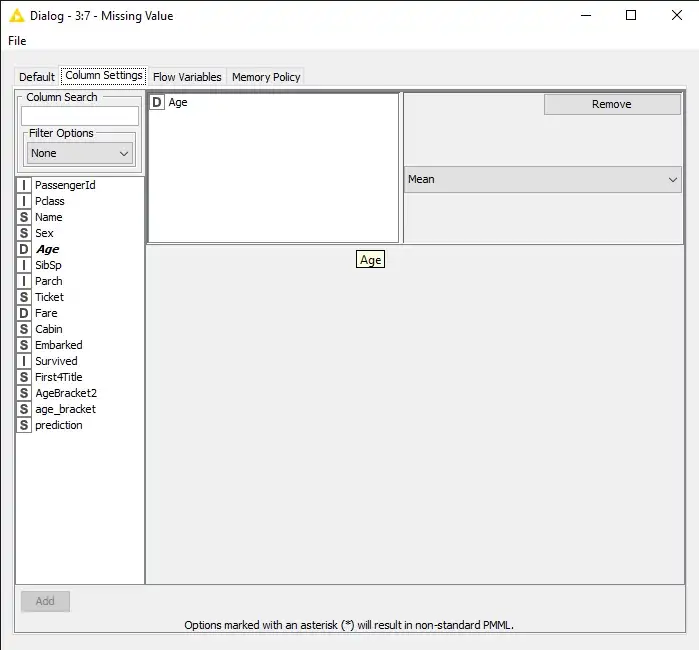
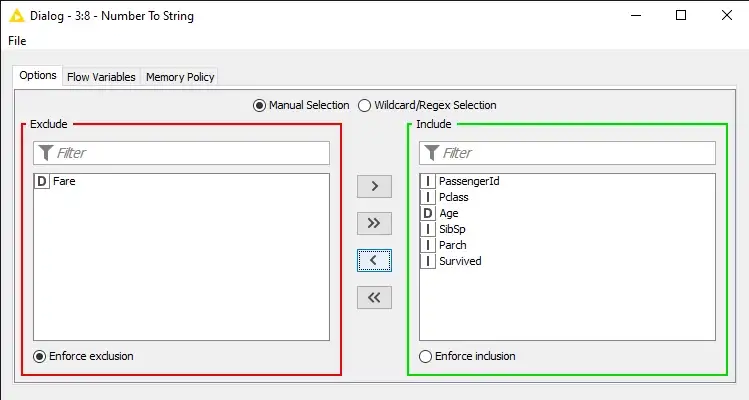
بالإضافة إلى ذلك، تتعامل KNIME مع تحويل نوع البيانات بسلاسة كبيرة بفضل ، على سبيل المثال ، عقدة Number to String لتحويل الميزات الرقمية إلى سلسلة ، وعقدة String to Number لتحويل الميزات الاسمية إلى أرقام.
في الشكل 18، أستبعد ميزة Fare من عملية تحويل السلسلة ، ولن أستخدمها لتدريب نموذجي لاحقًا.
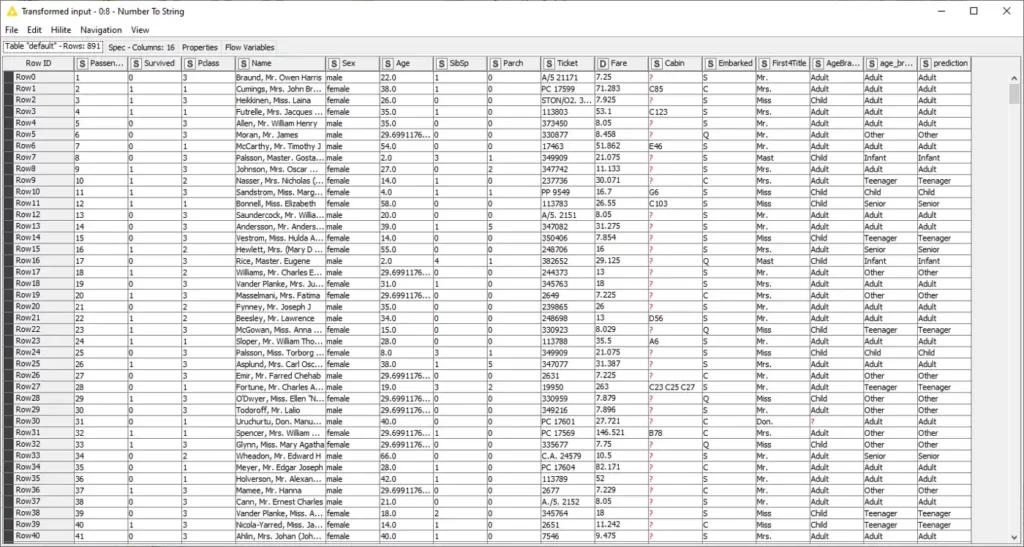
في جدول الإخراج أدناه، يمكننا أن نرى نوع البيانات “S” مكتوبًا بجوار كل اسم عمود يشير إلى أن جميع الميزات المحددة لدينا قد تم تحويلها إلى سلسلة
الآن، دعنا نربط منفذ الإخراج الخاص بالعقدة Number to String بمنفذ الإدخال لعقدة Domain Calculator.
عقدة Domain Calculator:
يقوم بمسح البيانات وتحديث قائمة القيم المحتملة و / أو الحد الأدنى والحد الأقصى لقيم الأعمدة المحددة. تكون هذه العقدة مفيدة عندما تتغير معلومات المجال الخاصة بالبيانات ويجب تحديثها في مواصفات الجدول، على سبيل المثال، قد تكون معلومات المجال كما هي واردة في مواصفات الجدول باطلة عند إجراء تصفية الصف (على سبيل المثال الإزالة الخارجية).”
لقد انتهينا من معالجة البيانات!
تقسيم البيانات
لتقسيم مجموعة البيانات الخاصة بنا، فهذا يعني أننا بحاجة إلى تقسيمها إلى مجموعة تدريب واختبار لتدريب نموذجنا
واختباره. لتقسيم مجموعة البيانات، نستخدم عقدة Partitioning.
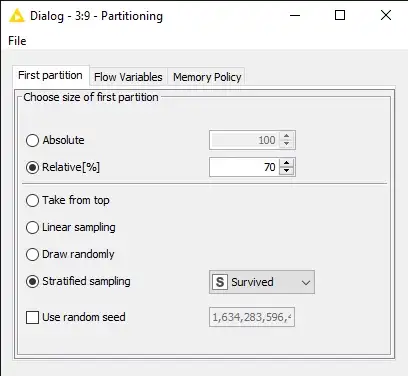
في هذه الحالة، نستخدم أخذ العينات الطبقية لضمان الاحتفاظ (تقريبًا) بتوزيع القيم في العمود ” Supervised ” في كل من مجموعة بيانات التدريب والاختبار.
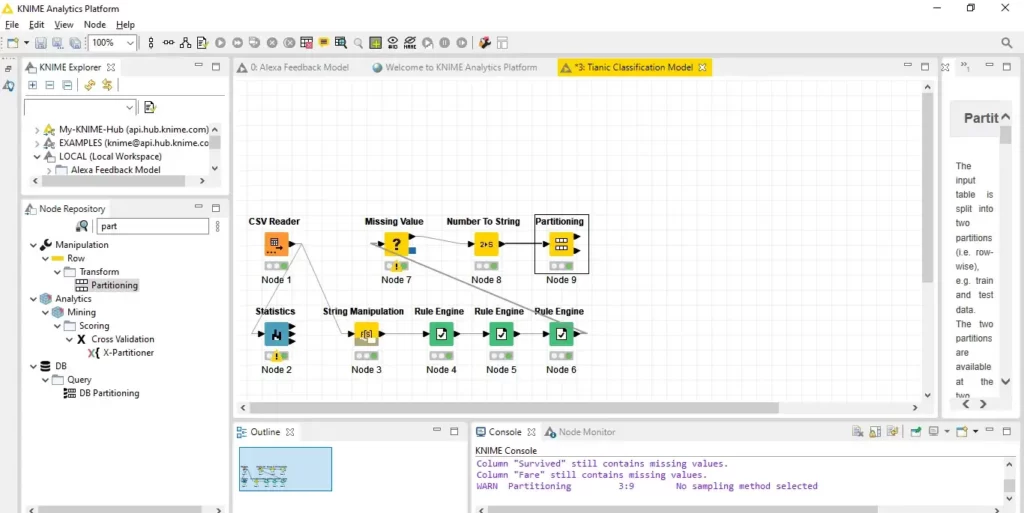
بمجرد توصيل كل شيء، يبدو سير العمل هكذا.
خط أنابيب التعلم الآلي: تدريب واختبار وتقييم
الآن، نحتاج فقط إلى اختيار خوارزمية التعلم الآلي وإدخال بياناتنا فيها. في هذا البرنامج التعليمي، سنستخدم خوارزميتين مختلفتين للتعلم الآلي:
- الغابة العشوائية Random Forest
- شجرة معزز بالتدرج Gradient Boosted Tree
لتدريب نماذجنا واختبارها. يمكننا أيضًا مقارنة أداء هذين النموذجين في وقت واحد.
أولاً، دعنا نبحث عن اسم خوارزمية التعلم الآلي في Node Repository، واسحب الملاحظة المطلوبة وأفلتها في Workflow Editor، وقم بتوصيل العقد كما هو موضح أدناه.
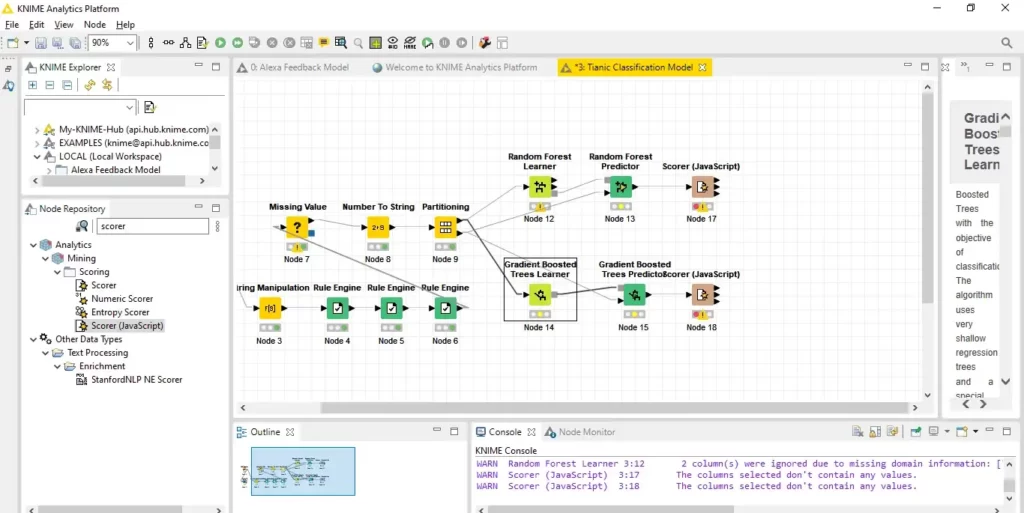
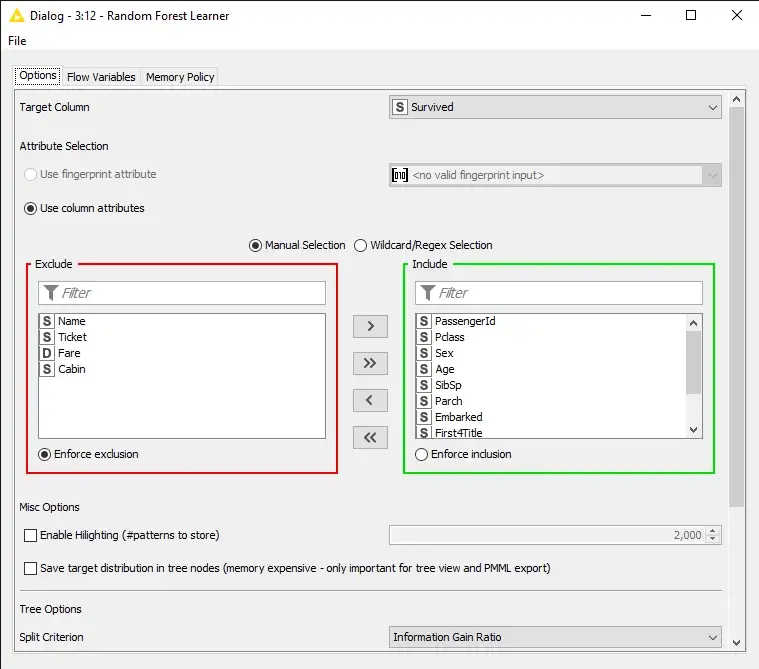
بعد ذلك، نستخدم مجموعة التدريب لتدريب نماذجنا. للقيام بذلك ، نحتاج إلى تكوين عُقد خوارزمية التعلم الآلي عن طريق تحديد العمود الهدف target column (الميزة التابعة Dependent feature) وتضمين الأعمدة ذات الصلة pertinent columns (الميزات المستقلة Independent features).
بعد اكتمال التدريب، يمكننا تطبيق النماذج على بيانات الاختبار الخاصة بنا باستخدام عقد Predictor وتقييم أدائها. لتقييم أداء النموذج، نحتاج إلى تكوين عقدة Scorer (JavaScript).
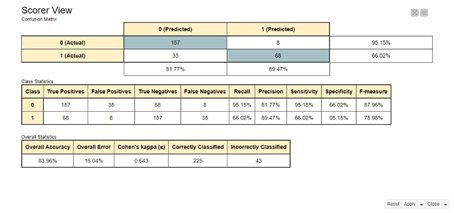
في عقدة Scorer (JavaScript) ، يمكننا ملاحظة مصفوفة الارتباك confusion matrix ، بالإضافة إلى إحصائيات الدقة accuracy الشاملة والفئة class.
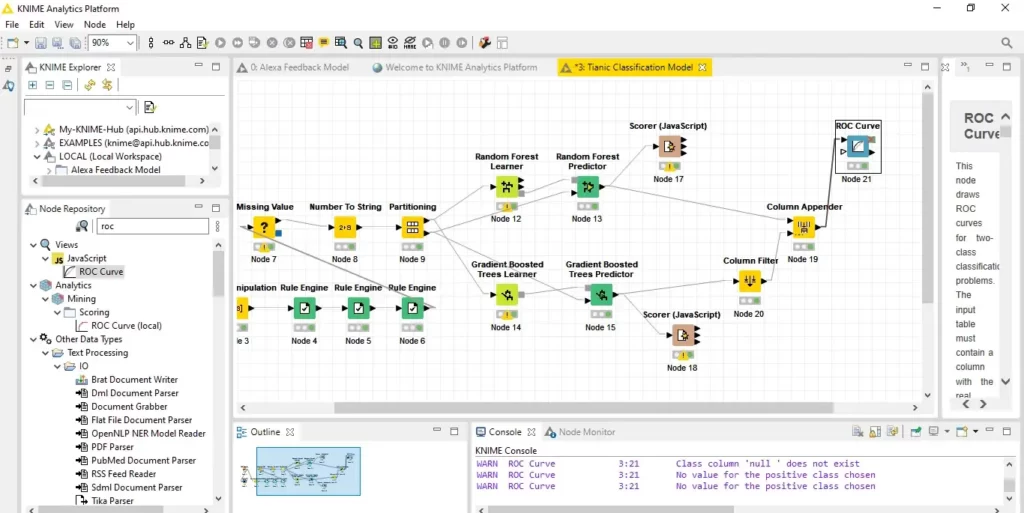
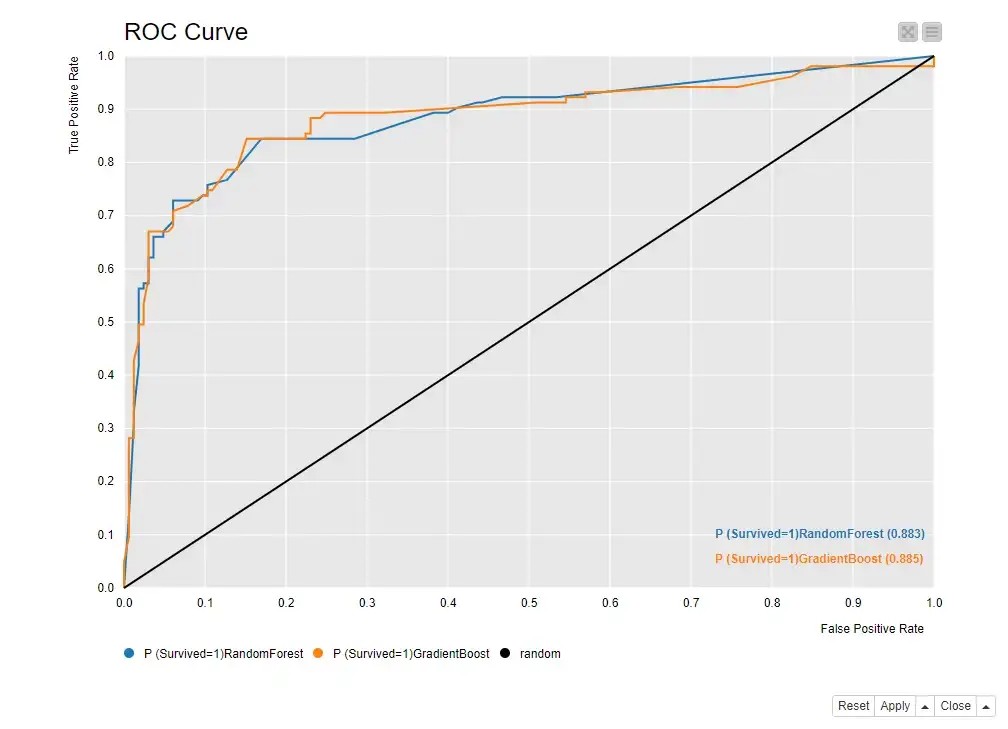
كمكافأة، سأوضح لك أنه يمكن تقييم أداء النموذج أيضًا من خلال رسم منحنى ROC ، والذي يمكن إنشاؤه باستخدام عقدة ROC Curve.
هذا دليل كامل لبدء استخدام KNIME للتعلم الآلي!
تعد KNIME مساعدة كبيرة لاستكشاف مجموعة البيانات الخاصة بنا عندما يكون لدينا القليل من المعرفة بها ، ولكنها تعمل أيضًا بشكل جيد بشكل مذهل لمعالجة البيانات ، أو لإجراء تحليلات على مجموعات بيانات مختلفة ، أو لمقارنة نماذج التعلم الآلي المختلفة في وقت واحد.
إذا كنت ترغب في البدء بالتعلم الآلي ولكن ليس لديك أي مهارات برمجة في Python و R ، فعليك بالتأكيد أن تبدأ بـ KNIME.