

بعد حركة #MeToo، انفتح الكثير من الأشخاص حول حوادث التحرش الجنسي sexual harassment incidents، ولكن كما هو الحال مع أي حركة منتشرة على الإنترنت، تلاشت مع مرور الوقت. ومع ذلك، يمكن استخدام هذا الكم الهائل من المعلومات بشكل فعال لتصنيف حوادث الإساءة تلقائيًا إلى فئات مناسبة، وستساعدنا هذه المقالة في فهم كيف يمكننا تقليل حوادث التحرش الجنسي باستخدام التعلم الآلي.
الفهرست:
- المشكلة.
- صياغة التعلم الآلي للمشكلة.
- تحليل مجموعة البيانات.
- مقاييس الأداء.
- الهدف من دراسة الحالة.
- تحليل البيانات الاستكشافية.
- المعالجة المسبقة لنص الوصف.
- تضمين نص الوصف.
- النماذج المستخدمة.
- تحقيق أداء المقاييس.
- المناهج التي لم تنجح.
- نشر النموذج
المشكلة
التصنيف التلقائي لنوع التحرش الجنسي سيمكن الأشخاص الذين يرغبون في إجراء تغيير في المجتمع من تحليل البيانات بشكل أفضل، ولهذا السبب بالذات، فإن تحديد التحرش الجنسي باستخدام التعلم الآلي سيغير قواعد اللعبة ويضمن عدم وقوع حوادث غير متوقعة. يمكن أيضًا تجميع البيانات من خلال التصنيف الذي يمكن أن يثبت أنه حالة استخدام مهمة في تمكين اتخاذ إجراءات أسرع من قبل السلطات. نظرًا لأن لدينا بالفعل العديد من القصص الشخصية حول الاعتداء الجنسي التي تمت مشاركتها عبر الإنترنت من خلال دراسة الحالة هذه، فسنستخدم البيانات علميًا.
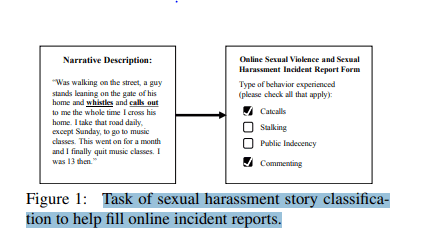
صياغة التعلم الآلي للمشكلة
سنستفيد من المعالجة اللغوية الطبيعية NLP لتصنيف أنواع التحرش الجنسي بشكل صحيح باستخدام التعلم الآلي (نظرًا لأن الفرز اليدوي لكل منها واتخاذ الإجراءات يمكن أن يستغرق قدرًا هائلاً من الوقت والجهد). يتم استخدام التصنيف الفردي والمتعدد للمهمة للمساعدة في ملء تقارير الحوادث عبر الإنترنت تلقائيًا وتصنيف البيانات وتلخيصها بناءً على نوع الإساءة.
تحليل مجموعة البيانات
تم جمع البيانات من Safecity، التي تجمع تقارير مجهولة المصدر عن الجرائم في الأماكن العامة. الفئات الثلاث الأكثر كثافة تلمس groping / تلامس touching، وتحدقstaring / تغمز ogling، وتعليقcommenting، لاستخدامها كمجموعة بيانات من إجمالي 13 فئة مختلفة، حيث كانت الفئات الأخرى أكثر ندرة. قد يقع كل وصف في لا شيء أو بعض أو كل الفئات. البيانات المقدمة إلينا مقسمة بالفعل لمجموعات التدريب والاختبار والتحقق من الصحة، وقد استخدمنا نفس المجموعة من التقسيمات لنماذجنا.
تتكون مجموعة بيانات التدريب من عمودين
لتصنيف التسمية الواحدة single-label classification: –
- وصف الحادث: – لدينا بيانات موجودة باللغة الإنجليزية.
- الفئة: – المتغير الثنائي 1 الذي يشير إلى أن التحرش و 0 تشير إلى لا شيء.
مثال على التغمز ogling:
” My college was nearby. This happened all the time. Guys passing comments, staring, trying to touch. Frustrating “
”كانت كليتي قريبة. حدث هذا طوال الوقت. رفاق يمررون التعليقات، يحدقون، يحاولون اللمس. محبطة “→ مصنفة على أنها 1، مما يدل على أنه قد تم تحديد التحرش الجنسي باستخدام التعلم الآلي
” I witnessed an incident when a chain was brutally snatched from an elderly lady “
لقد شاهدت حادثة اختطفت فيها سلسلة بوحشية من سيدة عجوز. وقع الحادث خلال المساء. → مصنفة على أنها 0
لتصنيف متعدد التصنيفات multi-label classification: –
- وصف الحادث: – لدينا بيانات موجودة باللغة الإنجليزية.
- الفئة: – جميع التسميات المطبقة موجودة.
مثال:
“During the morning, a woman was walking by and a thin guy came around and called her names, and commented and stared”
“خلال الصباح، كانت امرأة تسير بجانبها وجاء رجل نحيف ونادى باسمها، وعلق عليها وحدق بها”
هو إيجابي لفئتين: التعليق commenting، التغمز ogling
مقاييس الأداء
سنستخدم مقاييس التقييم التالية من أجل: –
- التصنيف الثنائي: – الدقة Accuracy.
- تصنيف متعدد التسمية: – خطأ هامينك Hamming Loss.
يمكن تعريف Hamming Loss على أنه (المصدر: ويكيبيديا) جزء التسميات الخاطئة إلى العدد الإجمالي للتسميات.
الهدف من دراسة الحالة
تم تطوير دراسة الحالة باستخدام مرجع الورقة (SafeCity: فهم الأشكال المتنوعة للقصص الشخصية للتحرش الجنسي (https://arxiv.org/pdf/1809.04739.pdf)). كان هدفي أثناء العمل في دراسة الحالة هو مطابقة نتائج الورقة (التي تستخدم التعلم العميق) أثناء اتباع مسار مختلف (باستخدام نماذج التعلم الآلي الكلاسيكية)، دون مزيد من اللغط، دعنا نبدأ في وصف عملي.
تحليل البيانات استكشافية
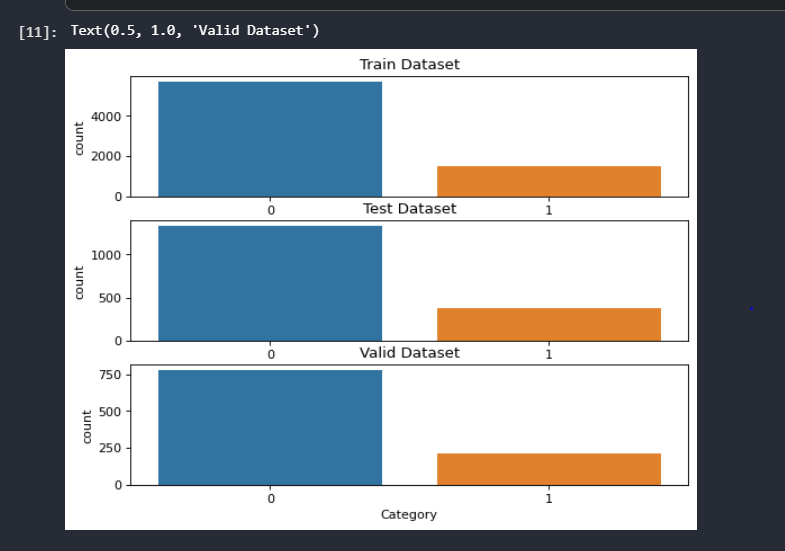
ننظر أولاً إلى توازن الفئات المستهدفة. كما يتضح من الرسم البياني أدناه، فإن البيانات غير متوازنة إلى حد كبير في جميع مجموعات البيانات الثلاث (التدريب، والاختبار، والتحقق من الصحة) لدينا أوصافًا ليست حوادث فعلية أكثر من تلك التي هي أوصاف حادثة تحرش.
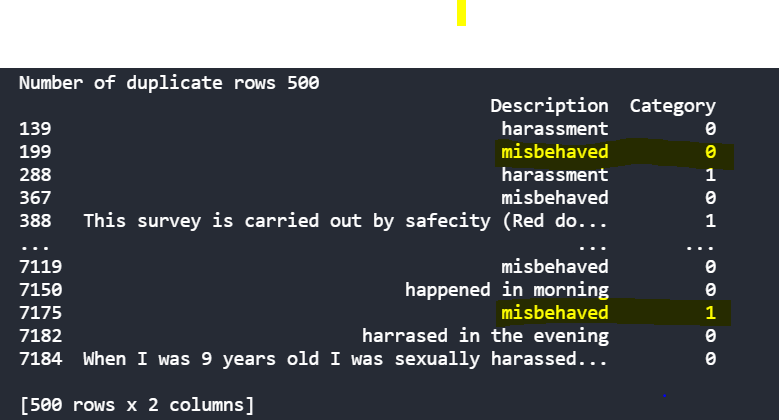
عند إجراء مزيد من التحليل للبيانات النصية، لوحظ أنها تحتوي على بيانات مكررة خاطئة، ويتم تكرار نفس الوصف للنص وتعيينه إلى فئة مختلفة. كما يمكنك أن ترى أدناه، يحتوي وصف سوء التصرف على فئة 0 في الصف 199 وفئة 1 في الصف 7175.
كما لوحظ أن بعض نصوص الوصف لم تكن غنية بالمعلومات.
- كان سيئا حقا it was really bad.
- تم إجراء هذا المسح بواسطة مدينة آمنة (Red Do … This survey is carried out by safe city (Red Do…
- أساء التصرف misbehaved.
- التحرش harassment.
المعالجة المسبقة لنص الوصف
كجزء من المعالجة المسبقة، اتخذت الخطوات التالية. كود لكل خطوة متبوعًا بوصف قصير. (تتم مشاركة رابط قاعدة البيانات بالكامل في نهاية المقالة للرجوع إليها).
1) إلغاء البيانات المكررة Deduplication
df_train_og.drop_duplicates(subset="Description",keep= False, inplace = True)
df_train_go.drop_duplicates(subset="Description",keep= False, inplace = True)
df_train_co.drop_duplicates(subset="Description",keep= False, inplace = True)
train_df.drop_duplicates(subset="Description",keep= False, inplace = True)
نستخدم دالة pandas drop_duplicates لإزالة البيانات المكررة.
2) إزالة علامات الترقيم Punctuation وكلمات التوقف stopword.
puncts = [',', '.', '"', ':', ')', '(', '-', '!', '?', '|', ';', "'", '$', '&', '/', '[', ']', '>', '%', '=', '#', '*', '+', '\', '•', '~', '@', '£',
'·', '_', '{', '}', '©', '^', '®', '`', '<', '→', '°', '€', '™', '›', '♥', '←', '×', '§', '″', '′', 'Â', '█', '½', 'à', '…',
'“', '★', '”', '–', '●', 'â', '►', '−', '¢', '²', '¬', '░', '¶', '↑', '±', '¿', '▾', '═', '¦', '║', '―', '¥', '▓', '—', '‹', '─',
'▒', ':', '¼', '⊕', '▼', ' ', '†', '■', '’', '▀', '¨', '▄', '♫', '☆', 'é', '¯', '♦', '¤', '▲', 'è', '¸', '¾', 'Ã', '⋅', '‘', '∞',
'∙', ')', '↓', '、', '│', '(', '»', ',', '♪', '╩', '╚', '³', '・', '╦', '╣', '╔', '╗', '▬', ' ', 'ï', 'Ø', '¹', '≤', '‡', '√', ]
def clean_text(data):
stop = stopwords.words('english')
res = []
data['Description'] = data['Description'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
for x in data['Description']:
x = str(x)
for punct in puncts:
if punct in x:
x = x.replace(punct,' ')
res.append(x)
return res
نستخدم كلمات التوقف المحددة مسبقًا بواسطة مكتبة nltk، في حالة وجود أي كلمة من الوصف في مجموعة كلمات الإيقاف، نقوم بإزالتها. السبب الرئيسي لإزالة كلمات التوقف هو أنها لا تقدم قيمة كبيرة للنص. أمثلة Stopword هي ، is ، at ، on إلخ.
وبالمثل، حددنا قائمة بعلامات الترقيم، وفي حالة وجود أي من رموز الترقيم، نقوم بإزالتها أيضًا. المنطق هو نفسه قد لا يوفر رمز الترقيم قيمة إدخال مهمة في مهمة التصنيف الخاصة بنا.
تضمين نص الوصف
الغرض من تضمين embedding حقل الوصف هو أن نموذج التعلم الآلي لن يفهم الكلمات التي نحتاجها إلى طريقة لتضمين معناها في المتجهات وتقديم نفس الشيء للنموذج.
جربنا استراتيجيتين للتضمين: –
- متجه TF IDF مع ميزات trigram وbigram وunigram مع 50 ميزة كحد أقصى و min_df من 15. تم تحديد هذه القيم عن طريق التجربة.
- استخدام ترميز الجملة العالمية universal sentence encoding لتضمين الجملة. يقوم بتحويل نص الإدخال متغير الطول إلى متجه 512 بعد. لقد ورد في العديد من الأوراق البحثية أن استخدام مشفر على مستوى الجملة أفضل من استخدام مشفر على مستوى الكلمة لأنه يحافظ على المعلومات السياقية.
النماذج المستخدمة
لقد استخدمنا نماذج التعلم الآلي أدناه للتصنيف أحادي التسمية:
- الانحدار اللوجستي Logistic Regression (كنموذج أساسي).
- XGBoost.
- LightGBM.
لتصنيف متعدد التسميات، استخدمنا الصلة الثنائية Binary Relevance مع المتعلمين الأساسيين لمصنفات ناقلات الدعم support vector classifiers و XGBoost.
الصلة الثنائية Binary Relevance: – هو يحل التصنيف متعدد التسميات عن طريق تحويلها إلى مشاكل تصنيف ذات تسمية واحدة L ويكون الناتج اتحادًا على جميع تصنيفات التسمية المفردة L. يمكنك الرجوع إلى الوثائق هنا.
تحقيق أداء المقاييس
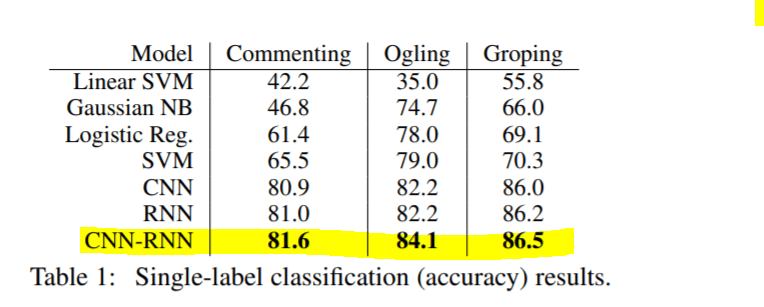
بالنسبة لتصنيف التسمية الفردي، وصلنا إلى المقاييس التالية، فهذه النتائج قابلة للمقارنة مع مخرجات المقالة الأصلية، ولكل فئة في بيانات الاختبار، فنحن أقل دقة بنسبة 2٪ فقط من الورقة لأن الورقة تستخدم تقنيات معقدة للتعلم العميق ولدينا استخدمت نماذج التعلم الآلي الكلاسيكية في دراسة الحالة الخاصة بنا.
تم تحقيق مقياس دراسة الحالة:
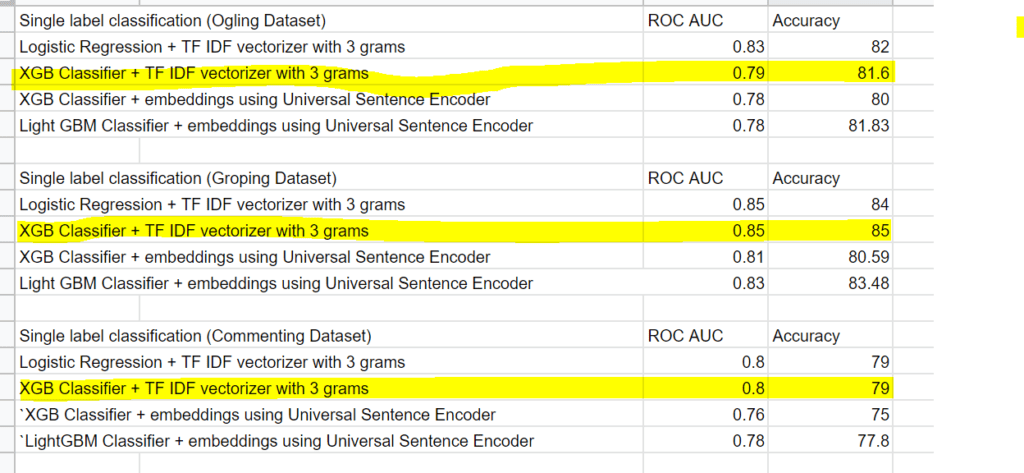
مقياس المقالة الأصلية:
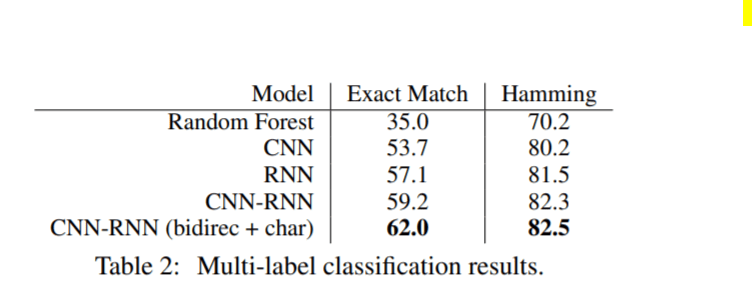
بالنسبة للتصنيف متعدد التسميات، فإن دراسة الحالة الخاصة بنا تؤدي بشكل أفضل قليلاً من المقالة كما يتضح من درجات الطرق أدناه.
تم تحقيق مقياس دراسة الحالة:

مقياس المقالة الأصلية:
مقاربات لم تنجح
حاولت SMOTE لعدم التوازن في البيانات، ولم يحسن الدقة.
نشر النموذج
لقد استخدمت Flask API و Heroku لنشر نموذجي. متاح للوصول.
https://predict-abuse.herokuapp.com/index
يوجد أدناه عرض توضيحي مباشر للنموذج الذي تم نشره:
رابط الكود الكامل: –



