
- استيراد المكتبات
- تدريب النموذج
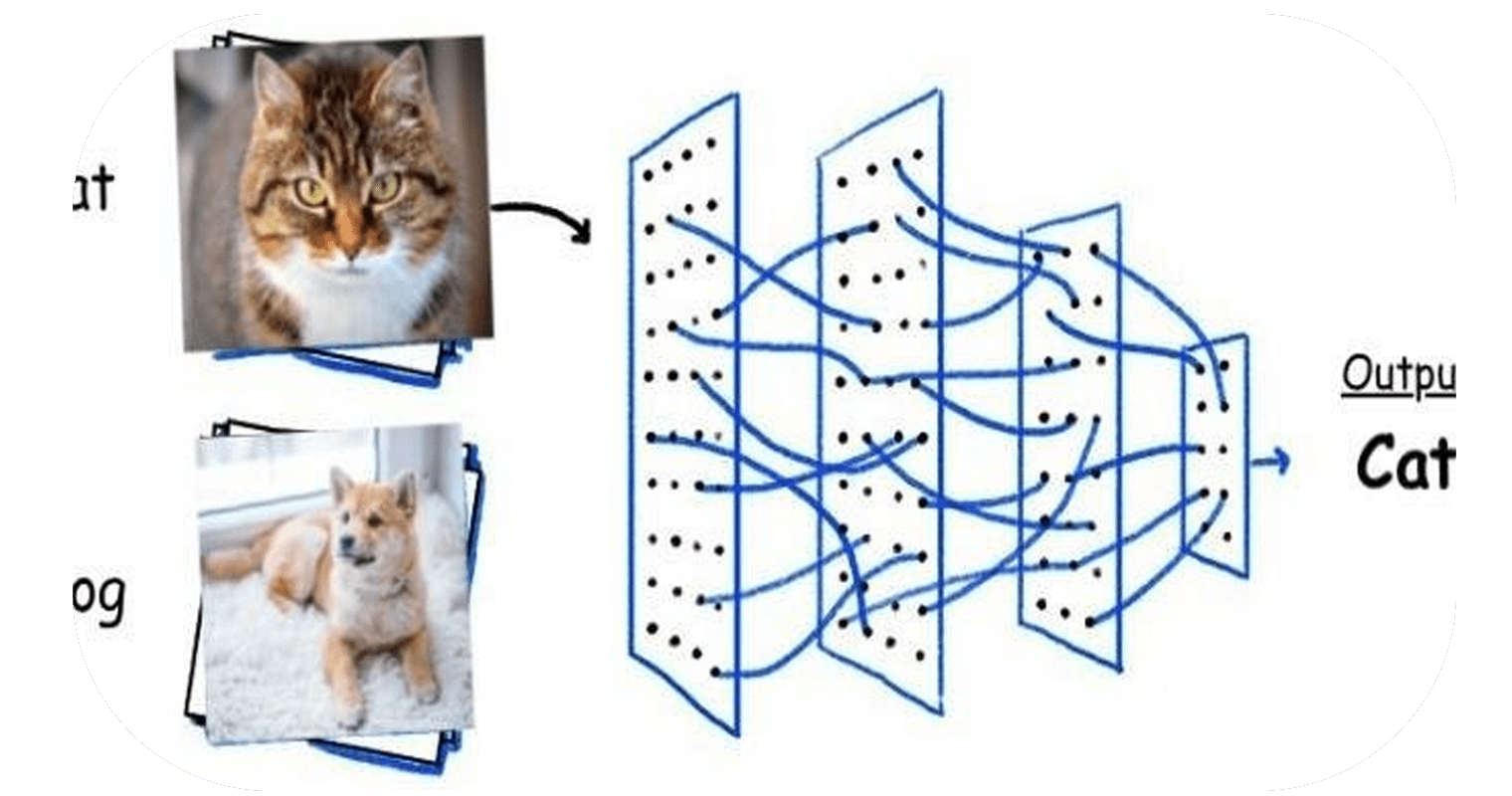
تُستخدم الشبكات العصبية التلافيفية (CNN) بشكل أساسي لتصنيف الصور أو تحديد أوجه التشابه في الأنماط بينها.
لذلك تستقبل الشبكة التلافيفية صورة ملونة عادية كمربع مستطيل يقاس عرضه وارتفاعه بعدد البكسل على طول تلك الأبعاد، وعمقها ثلاث طبقات، واحدة لكل حرف في RGB.
عندما تتحرك الصور عبر شبكة تلافيفية، يتم التعرف على أنماط مختلفة تمامًا مثل الشبكة العصبية العادية.
ولكن هنا بدلاً من التركيز على بكسل واحد في كل مرة، تأخذ الشبكة التلافيفية رقع مربعة square patches من البكسلات وتمررها عبر فلتر filter.
هذا الفلتر هو أيضًا مصفوفة مربعة أصغر من الصورة نفسها، ويساوي حجمها الرقعة patch. ويسمى أيضًا الكيرنل kernel.
لنبدأ الآن باستيراد المكتبات
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import cv2
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout, Activation, Conv2D
نحتاج إلى تدريب نموذج أولاً حتى نتحقق من بيانات التدريب في الكود أدناه، نقوم بالتكرار خلال جميع الصور الموجودة في مجلد التدريب ثم نقوم بتقسيم اسم الصورة باستخدام المحدد “.”
لدينا أسماء مثل dog.0، وdog.1، وcat.2، وما إلى ذلك.. ومن ثم بعد التقسيم، سنحصل على نتائج مثل ” dog”، و ” cat” كقيمة فئة للصورة. لجعل هذا المثال أكثر سهولة، سننظر إلى الكلب على أنه “1” والقط على أنه “0”.
الآن كل صورة هي في الواقع مجموعة من البكسل، فكيف نجعل جهاز الكمبيوتر الخاص بنا يعرف ذلك. إنه بسيط يحول كل تلك البكسلات إلى مصفوفة.
لذلك سنستخدم هنا مكتبة cv2 لقراءة صورتنا في مصفوفة وأيضًا ستقرأ كصورة ذات مقياس رمادي.
train_dir = # your path to train dataset
path = os.path.join(main_dir,train_dir)
for p in os.listdir(path):
category = p.split(".")[0]
img_array = cv2.imread(os.path.join(path,p),cv2.IMREAD_GRAYSCALE)
new_img_array = cv2.resize(img_array, dsize=(80, 80))
plt.imshow(new_img_array,cmap="gray")
break
حسنًا، كان الرمز أعلاه أكثر لفهم الغرض. الآن سوف نصل إلى الجزء الحقيقي من البرمجة هنا.
أعلن عن مجموعة التدريب الخاصة بك X والمصفوفة المستهدفة y. هنا ستكون X عبارة عن مجموعة من وحدات البكسل وستكون y هي القيمة 0 أو 1 للإشارة إلى كلب أو قطة. اكتب دالة تحويل إلى مطابقة الفئة ” dog” أو ” cat” في 1 و0.
قم بإنشاء دالة create_test_data تأخذ كل صور التدريب في حلقة. يتحول إلى مجموعة صور. قم بتغيير حجم الصورة إلى 80 × 80. قم باضافة صورة في مجموعة X. وقم باضافة قيمة الفئة في المصفوفة y.
X = []
y = []
convert = lambda category: int(category == 'dog')
def create_test_data(path):
for p in os.listdir(path):
category = p.split(".")[0]
category = convert(category)
img_array = cv2.imread(os.path.join(path,p),cv2.IMREAD_GRAYSCALE)
new_img_array = cv2.resize(img_array, dsize=(80, 80))
X.append(new_img_array)
y.append(category)
الآن استدعي الدالة، ولكن أيضًا لاحقًا حول X وy إلى مصفوفة numpy، وعلينا أيضًا إعادة تشكيل X بالكود أدناه:
create_test_data(path)
X = np.array(X).reshape(-1, 80,80,1)
y = np.array(y)
إذا رأيت قيم X، يمكنك رؤية مجموعة متنوعة من القيم بين 0-255. ذلك لأن كل بكسل له كثافة مختلفة من الأبيض والأسود. ولكن مع وجود مجموعة كبيرة من القيم، يصبح من الصعب على نموذج التدريب التعلم (حفظه أحيانًا).
كيف تحل هذا وقد خمنت ذلك بشكل صحيح. يمكنك تسوية normalize البيانات. يمكننا استخدام تسوية Keras هنا أيضًا. لكننا نعلم جيدًا أن جميع القيم لها نطاق يتراوح بين 0-255، لذا يمكننا فقط تقسيمها على 255 والحصول على جميع القيم بقياس ما بين 0-1
هذا ما فعلناه أدناه. يمكنك تخطي هذه الخطوة لمعرفة الفرق بين الدقة. لا تصدق كل ما أقوله. جرب وانظر بنفسك:
#Normalize data
X = X/255.0
model = Sequential()
# Adds a densely-connected layer with 64 units to the model:
model.add(Conv2D(64,(3,3), activation = 'relu', input_shape = X.shape[1:]))
model.add(MaxPooling2D(pool_size = (2,2)))
# Add another:
model.add(Conv2D(64,(3,3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
# Add a softmax layer with 10 output units:
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer="adam",
loss='binary_crossentropy',
metrics=['accuracy'])
الآن سوف نلائم نموذجنا مع بيانات التدريب.
الفترات Epochs: كم مرة سوف يمر نموذجنا بالبيانات.
حجم الدُفعة Batch size: مقدار البيانات التي تريد تمريرها عبر النموذج دفعة واحدة.
Validation_split: ما مقدار البيانات (في هذه الحالة 20٪) الذي ستحتاجه للتحقق من خطأ التحقق من الصحة.
model.fit(X, y, epochs=10, batch_size=32, validation_split=0.2)
حان الوقت الآن للتنبؤ PREDICT أخيرًا، لذا قم بتغذية نموذج CNN الخاص بك ببيانات الاختبار للتنبؤ.
predictions = model.predict(X_test)
نحن نقرب النتيجة هنا حيث استخدمنا دالة sigmoid وحصلنا على قيم الاحتمال في مجموعة البيانات المتوقعة لدينا:
predicted_val = [int(round(p[0])) for p in predictions]
الآن عليك أن تجعل إطار بيانات الإرسال لإرسال مجموعة النتائج الخاصة بك.
submission_df = pd.DataFrame({'id':id_line, 'label':predicted_val})
اكتب إطار البيانات الخاص بك إلى ملف csv:
submission_df.to_csv("submission.csv", index=False)




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.