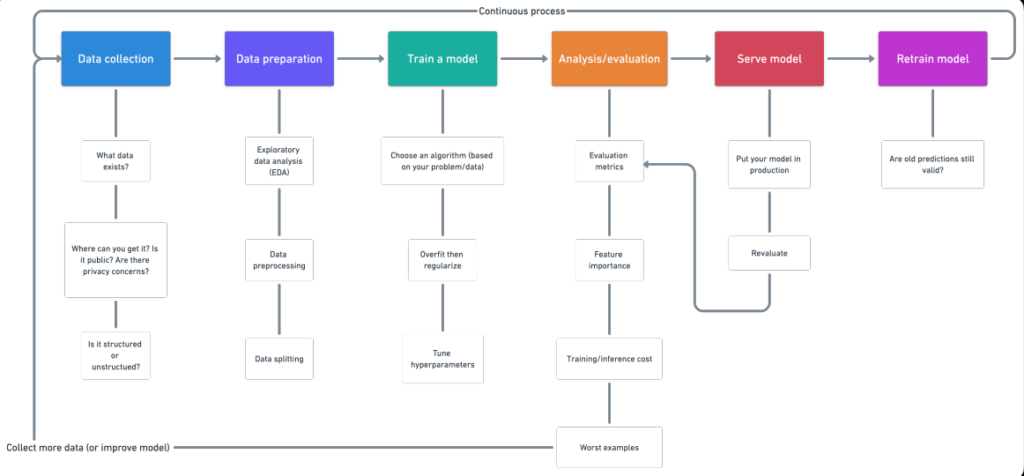
- مقدمة
- 1. جمع البيانات
- 2. إعداد البيانات
- 3. تدريب نموذج على البيانات (3 خطوات: اختر خوارزمية، وطبق النموذج، وتقليل الضبط الزائد overfitting مع التنظيم regularization)
- 4. التحليل Analysis / التقييم Evaluation
- 5. نشر النموذج
- 6. إعادة تدريب النموذج Retrain model
- 7. أدوات التعلم الآلي Machine Learning Tools
توضح هذه المقالة مختلف الخطوات المتضمنة في مشروع التعلم الآلي machine learning. هناك خطوات قياسية عليك اتباعها لمشروع علم البيانات data science. بالنسبة لأي مشروع، علينا أولاً جمع البيانات وفقًا لاحتياجات أعمالنا. الخطوة التالية هي تنظيف البيانات مثل إزالة القيم، وإزالة القيم المتطرفة outliers، والتعامل مع مجموعات البيانات غير المتوازنة imbalanced datasets، وتغيير المتغيرات الفئوية categorical variables إلى قيم عددية numerical values، إلخ.
بعد هذا التدريب للنموذج، استخدم خوارزميات التعلم الآلي والتعلم العميق المختلفة. بعد ذلك، يتم تقييم النموذج باستخدام مقاييس مختلفة مثل الاستدعاء recall وf1 scoreوالدقة accuracy وما إلى ذلك. وأخيرًا، نشر النموذج على السحابة وإعادة تدريب النموذج. دعنا نبدأ:
1. جمع البيانات
أسئلة يجب طرحها؟
- ما نوع المشكلة التي نحاول حلها؟
- ما هي مصادر البيانات الموجودة بالفعل؟
- ما هي مخاوف الخصوصية الموجودة؟
- هل البيانات عامة؟
- أين يجب أن نخزن الملفات؟
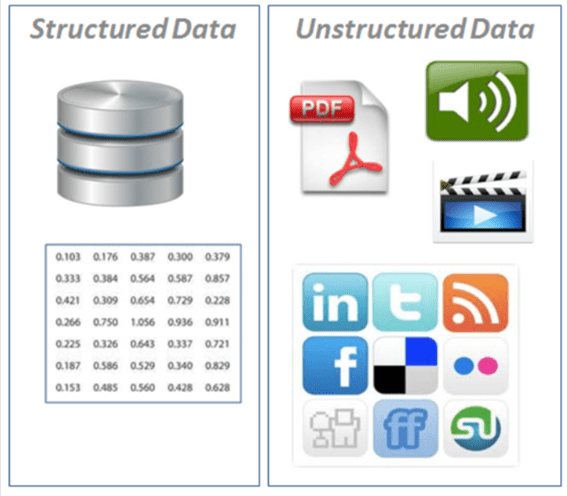
أنواع البيانات
1. البيانات المهيكلة Structured data: تظهر بتنسيق مجدول (نمط الصفوف والأعمدة، مثل ما تجده في جدول بيانات Excel). يحتوي على أنواع مختلفة من البيانات، على سبيل المثال السلاسل الزمنية العددية والفئوية.
- اسمي / فئوي Nominal/categorical: شيء أو آخر. على سبيل المثال، بالنسبة لموازين السيارات، يعتبر اللون فئة. قد تكون السيارة زرقاء وليست بيضاء. أمر لا يهم.
- العددية Numerical: أي قيمة مستمرة يكون الاختلاف بينها مهمًا. على سبيل المثال، عند بيع المنازل، يكون مبلغ 107،850 دولارًا أمريكيًا هو أكثر من 56400 دولارًا أمريكيًا.
- ترتيبي Ordinal: البيانات التي لها ترتيب ولكن المسافة بين القيم غير معروفة. على سبيل المثال، سؤال مثل، كيف تقيم صحتك من 1-5؟ 1 أن تكون فقيرًا، 5 أن تكون بصحة جيدة. يمكنك الإجابة عن 1،2،3،4،5 لكن المسافة بين كل قيمة لا تعني بالضرورة أن الإجابة 5 هي خمسة أضعاف الإجابة.
- السلاسل الزمنية Time-series: البيانات عبر الزمن. على سبيل المثال، قيم البيع التاريخية للجرافات من 2012-2018.
2. بيانات غير مهيكلة Unstructured data: بيانات بدون بُنية صلبة (صور ، فيديو ، كلام ، نص لغة طبيعية)
2. إعداد البيانات
- تحليل البيانات الاستكشافية Exploratory data analysis(EDA)، التعرف على البيانات التي تعمل بها
- ما هي متغيرات الميزة (الإدخال) والمتغير المستهدف (الإخراج) على سبيل المثال، للتنبؤ بأمراض القلب، قد تكون متغيرات الميزة هي عمر الشخص ووزنه ومتوسط معدل ضربات القلب ومستوى النشاط البدني. وسيكون المتغير المستهدف هو ما إذا كان لديهم مرض أم لا.
- أي نوع لديك؟ سلاسل زمنية مهيكلة، غير مهيكلة، رقمية. هل هناك قيم مفقودة missing values؟ يجب عليك إزالتها أو ملء لهم ميزة التضمين.
- أين القيم المتطرفة outliers؟ كم منهم هناك؟ لماذا هم هناك؟ هل هناك أي أسئلة يمكن أن تطرحها على خبير المجال حول البيانات؟ على سبيل المثال، هل يمكن لطبيب أمراض القلب إلقاء بعض الضوء على مجموعة بيانات أمراض القلب؟
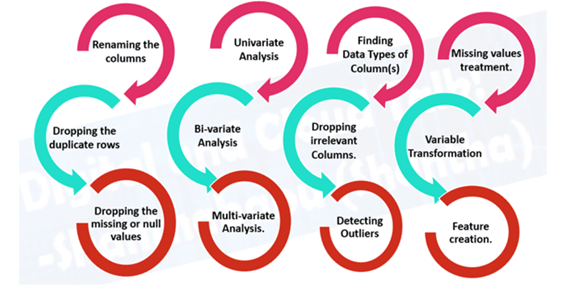
- المعالجة المسبقة للبيانات Data preprocessing، وإعداد البيانات الخاصة بك لتكون على غرار.
- · تضمين الميزات Feature imputation: ملء القيم المفقودة (لا يمكن لنموذج التعلم الآلي التعلم من البيانات غير الموجودة)
- التضمين الفردي Single imputation: املأ بمتوسط mean، وسيط median العمود.
- التضمين المتعدد Multiple imputations: نمذجة القيم الأخرى المفقودة وما يكتشفه نموذجك.
- KNN (k- أقرب جيران): املأ البيانات بقيمة من مثال آخر مشابه.
- أكثر من ذلك، مثل التضمين العشوائي random imputation، والملاحظة الأخيرة التي تم ترحيلها (للسلسلة الزمنية)، ونافذة متحركة، والأكثر تكرارًا.
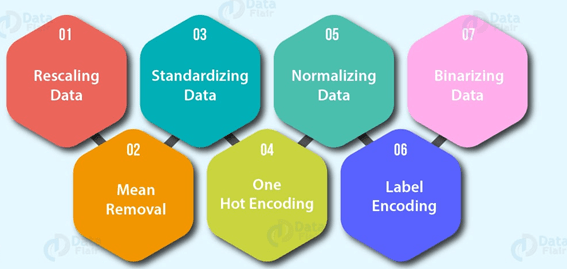
- ترميز الميزة Feature encoding (تحويل القيم إلى أرقام). يتطلب نموذج التعلم الآلي أن تكون جميع القيم رقمية.
- ترميز واحد ساخن One hot encoding: تحويل جميع القيم الفريدة إلى قوائم من 0 و 1 حيث تكون القيمة المستهدفة 1 والباقي 0. على سبيل المثال، عندما تتلون السيارة باللون الأخضر والأحمر والأزرق والأخضر، فسيتم تمثيل لون السيارة المستقبلي بالشكل [1 و 0 و 0] والأحمر سيكون [0 و 1 و 0].
- ترميز التسمية Label Encoder: تحويل التسميات إلى قيم عددية مميزة. على سبيل المثال، إذا كانت المتغيرات المستهدفة حيوانات مختلفة، مثل كلب، قطة، طائر، يمكن أن تصبح 0 و 1 و 2 على التوالي.
- ترميز التضمين Embedding encoding: تعرف على التمثيل بين جميع نقاط البيانات المختلفة. على سبيل المثال، نموذج اللغة هو تمثيل لكيفية ارتباط الكلمات المختلفة ببعضها البعض. أصبح التضمين متاحًا على نطاق واسع للبيانات المهيكلة (الجدولية tabular).
- تسوية الميزة (التحجيم) Feature normalization (scaling) أو التوحيد القياسي standardization: عندما تكون المتغيرات الرقمية على مستويات مختلفة (على سبيل المثال، يكون عدد_الحمامات بين 1 و 5 و size_of_land بين 500 و 20000 قدم مربع) ، فإن بعض خوارزميات التعلم الآلي لا تعمل بشكل جيد. يساعد التحجيم والتوحيد القياسي في إصلاح هذا.
- · هندسة الميزات Feature engineering: تحويل البيانات إلى (من المحتمل) تمثيل أكثر وضوحا عن طريق إضافة معرفة المجال:
- تتحلل Decompose.
- التكتم Discretization: تحويل المجموعات الكبيرة إلى مجموعات أصغر
- ميزات التقاطع والتفاعل Crossing and interaction features: الجمع بين ميزتين أو أكثر.
- ميزات المؤشر The indicator features: استخدام أجزاء أخرى من البيانات للإشارة إلى شيء يحتمل أن يكون ذا أهمية
- اختيار الميزة Feature selection: تحديد أهم ميزات مجموعة البيانات الخاصة بك لوضع نموذج لها. من المحتمل تقليل وقت التجهيز والتدريب (بيانات إجمالية أقل وبيانات زائدة عن الحاجة للتدريب عليها) وتحسين الدقة.
- تقليل الأبعاد Dimensionality reduction: طريقة شائعة لتقليل الأبعاد، PCA أو تحليل المكون الرئيسي principal component analysis يأخذ عددًا كبيرًا من الأبعاد (الميزات) ويستخدم الجبر الخطي لتقليلها إلى أبعاد أقل. على سبيل المثال، لنفترض أن لديك 10 ميزات رقمية، فيمكنك تشغيل PCA لتقليلها إلى 3.
- أهمية الميزة Feature importance (النمذجة اللاحقة post modelling): قم بملاءمة نموذج لمجموعة من البيانات ، ثم افحص الميزات الأكثر أهمية للنتائج ، وقم بإزالة أقلها أهمية.
- تتضمن طرق الالتفاف Wrapper methods مثل الخوارزميات الجينية وإزالة الميزات التكرارية إنشاء مجموعات فرعية كبيرة من خيارات الميزات ثم إزالة الخيارات غير المهمة.
- · التعامل مع عدم التوازن Dealing with imbalances: هل تحتوي بياناتك على 10000 مثال لفئة واحدة و 100 مثال لفئة أخرى فقط؟
- اجمع المزيد من البيانات (إذا استطعت).
- استخدم حزمة scikit-Learn-Contributed-Learn
- استخدم SMOTE: تقنية الإفراط في أخذ العينات الاصطناعية للأقلية. يقوم بإنشاء عينات تركيبية من فئتك الثانوي لمحاولة تسوية الحقل.
- مقالة مفيدة للنظر في “التعلم من البيانات غير المتوازنة Learning from imbalanced Data “.
- تقسيم البيانات Data splitting
- مجموعة التدريب Training set (عادة 70-80٪ من البيانات): يتعلم النموذج عن هذا.
- مجموعة التحقق من الصحة Validation set (عادةً 10-15٪ من البيانات): يتم ضبط المعلمات الفائقة hyperparameters للنموذج على هذا
- مجموعة الاختبار Test set (عادةً 10-15٪ من البيانات): يتم تقييم الأداء النهائي للنماذج بناءً على ذلك. إذا كنت قد فعلت ذلك بشكل صحيح، نأمل أن تعطي النتائج في مجموعة الاختبار مؤشرًا جيدًا على كيفية أداء النموذج في العالم الحقيقي. لا تستخدم مجموعة البيانات هذه لضبط النموذج.

3. تدريب نموذج على البيانات (3 خطوات: اختر خوارزمية، وطبق النموذج، وتقليل الضبط الزائد overfitting مع التنظيم regularization)
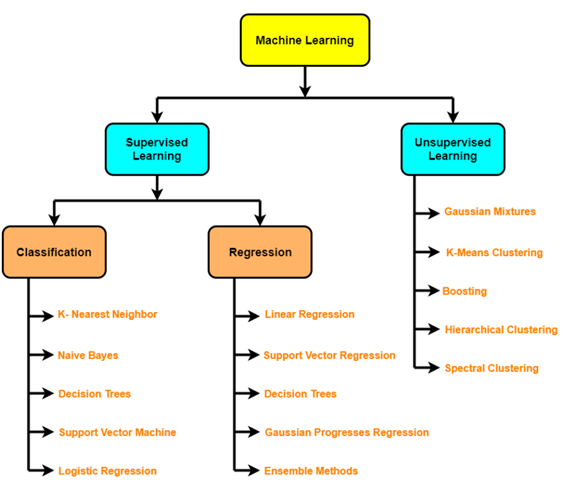
- اختيار الخوارزميات Choosing an algorithms
- الخوارزميات الخاضعة للإشراف Supervised algorithms: الانحدار الخطي Linear Regression ، الانحدار اللوجستي Logistic Regression ، KNN ، SVMs ، شجرة القرار Decision tree والغابات العشوائية andom forests ، AdaBoost / آلة تعزيز التدرج Gradient Boosting Machine (التعزيز boosting)
- الخوارزميات غير الخاضعة للإشراف Unsupervised algorithms: التجميع Clustering، تقليل الأبعاد (PCA، المشفر التلقائي Autoencoders، t-SNE)، اكتشاف الشذوذ anomaly detection.
- انواع التعلم Type of learning
- التعلم بالدفعات Batch learning.
- التعلم الاونلاين Online learning.
- نقل التعلم Transfer learning.
- التعلم النشط Active learning.
- التعلم الجماعي Ensembling.
- الضبط الناقص Underfitting: يحدث عندما لا يعمل نموذجك بالشكل الذي تريده على بياناتك. جرب التدريب على نموذج أطول أو أكثر تقدمًا.
- الضبط الزائد Overfitting : يحدث عندما تبدأ خطأ التحقق من الصحة في الزيادة أو عندما يكون أداء النموذج في مجموعة التدريب أفضل منه في مجموعة الاختبار.
- التنظيم Regularization: مجموعة من التقنيات لمنع / تقليل الضبط الزائد (مثل L1 ، L2 ، التسرب Dropout ، التوقف المبكر Early stopping ، زيادة البيانات Data augmentation ، التسوية بالدفعات Batch normalization)
- ضبط المعالمات الفائقة Hyperparameter : قم بإجراء مجموعة من التجارب بإعدادات مختلفة ومعرفة أيها يعمل بشكل أفضل.
4. التحليل Analysis / التقييم Evaluation
- مقاييس التقييم Evaluation metrics
- التصنيف Classification: الدقة Accuracy، الدقة Precision، الاسترجاع Recall، F1، مصفوفة الارتباك Confusion matrix، متوسط الدقة Mean average precision (اكتشاف الكائن)
- الانحدار: MSE، MAE، R ^ 2
- المقياس المستند إلى المهام Task-based metric: على سبيل المثال بالنسبة للسيارة ذاتية القيادة، قد ترغب في معرفة عدد حالات فك الارتباط.
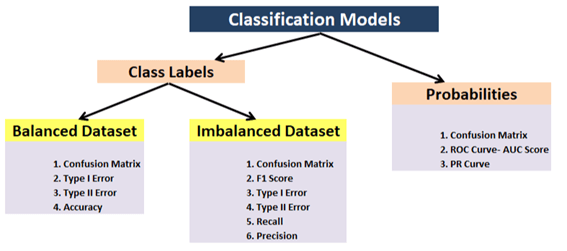
- أهمية الميزة Feature importance.
- التدريب Training / وقت الاستدلال inference time / الكلفة cost.
- أداة ماذا لو What if tool: كيف يقارن نموذجي بالنماذج الأخرى؟
- أمثلة غير موثوقة Least confident examples: ما الخطأ الذي يخطئ فيه النموذج؟
- مقايضة التحيز / التباين Bias/variance trade-off.
5. نشر نموذج
- ضع النموذج في مرحلة الإنتاج وانظر كيف ستسير الأمور.
- الأدوات التي يمكنك استخدامها: TensorFlow Servinf و PyTorch Serving و Google AI Platform و Sagemaker
MLOps: حيث تلتقي هندسة البرمجيات مع التعلم الآلي، بشكل أساسي كل التكنولوجيا المطلوبة حول نموذج التعلم الآلي لجعله يعمل في الإنتاج

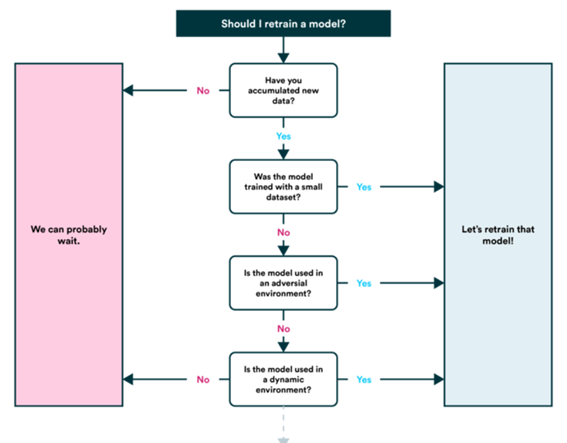
6. إعادة تدريب النموذج Retrain model
تعرف على كيفية أداء النموذج بعد النشر (أو قبل النشر) استنادًا إلى مقاييس التقييم المختلفة وإعادة النظر في الخطوات المذكورة أعلاه كما هو مطلوب (تذكر أن التعلم الآلي تجريبي للغاية ، لذلك هذا هو المكان الذي تريد تتبع بياناتك وتجاربك.
ستجد أيضًا أن تنبؤات نموذجك تبدأ في “العمر age ” (عادةً ليس بأسلوب النبيذ الجيد) أو “الانجراف drift “، كما هو الحال عند تغيير مصادر البيانات أو ترقيتها (أجهزة جديدة، وما إلى ذلك). هذا هو الوقت الذي تريد إعادة تدريبه فيه.
7. أدوات التعلم الآلي Machine Learning Tools