

لقد اتصلت بالخدمات المصرفية عبر الهاتف مؤخرًا وتم تشجيعي على “استخدام صوتي ككلمة المرور الخاصة بي”. قالوا إنه أسرع وأكثر أمانًا. كل ما عليك فعله هو أن تقول شيئًا مثل “صوتي هو كلمة المرور الخاصة بي” وتمرير الأمان.
لقد جعلني أفكر باستخدام الذكاء الاصطناعي التوليدي واستنساخ الصوت، ما مدى سهولة القيام به وما مدى خطورة ذلك؟ تمكنت من معرفة ذلك في غضون ساعتين واستنساخ صوت شخص ما من الملاحظات الصوتية في WhatsApp! وغني عن القول إن استخدام صوتي ككلمة مرور للخدمات المصرفية عبر الهاتف معطل الآن.
هناك ضجة كبيرة حول الذكاء الاصطناعي في الوقت الحالي ويشعر الكثير من الناس بالقلق بشأن ما قد يعنيه ذلك لنا ولأطفالنا. الجزء الذي يثير قلقي حقًا الآن هو استنساخ الصوت voice cloning. يمكن استخدامه بسهولة لأغراض ضارة وأعتقد أنه يجب أن يكون هناك طريقة ما للحماية منه.
كل ما تحتاجه هو ما لا يقل عن ثلاث عينات لأكثر من 10 ثوانٍ ويمكنك استنساخ صوت شخص ما. يمكن أن تأتي عينات الصوت من أي مكان. رسائل البريد الصوتي والملاحظات الصوتية والبودكاست ومقاطع الفيديو والخطب وأي شيء حقًا.
المتطلبات الاساسية
- نظام مع Python 3.8 عليه. أنا أستخدم iMac الخاص بي مع Python 3.11 ولكنه لم يعمل. كان على استخدام Python 3.8 على وجه التحديد.
- ستحتاج إلى PIP، وهو مدير حزم Python.
- سوف تحتاج إلى إعداد بيئة افتراضية Python. أستخدم “venv” الذي يمكنك تثبيته باستخدام PIP إذا لم تكن قد قمت بتثبيته بالفعل.
- ستحتاج إلى تثبيت “git”.
- أنت بحاجة إلى مكتبة Python تسمى “tortoise-tts”. لا يمكنك فقط “pip install”. تحتاج إلى تثبيته بطريقة محددة للغاية وسأغطيها بعد قليل.
- تحتاج إلى تثبيت بعض التبعيات. اضطررت إلى تثبيت “lapack” و “hiredis” باستخدام Homebrew على iMac. نجح مجرد “brew install <package>”. قد تكون قد قمت بتثبيتها أو لا تكون مثبتة بالفعل، لذا قد يكون من المفيد محاولة تثبيت “tortoise-tts” ومعرفة كيف تحصل عليه. إذا واجهت مشكلة، فمن المرجح أن يكون ذلك بسبب هذا.
- تحتاج إلى تثبيت مكتبة تسمى “six” باستخدام PIP.
- سوف تحتاج إلى الحصول على بعض الملفات الصوتية. لقد قمت بتسجيل الدخول إلى WhatsApp على الويب ووجدت للتو بعض الملاحظات الصوتية من شخص ما. تمكنت من تنزيله كملفات ogg على سطح المكتب.
- ستحتاج إلى محرر صوت وقد استخدمت Audacity. إنه مجاني وقوي بشكل مذهل.
التثبيت
استنساخ مستودع “tortoise-tts“.
% git clone https://github.com/neonbjb/tortoise-tts
قم بإعداد البيئة الافتراضية باستخدام “venv”.
% python3 -m venv tortoise-tts
% source tortoise-tts/bin/activate
(venv) % cd tortoise-tts
(venv) tortoise-tts %
كما ذكرت، سوف تحتاج إلى Python 3.8 لهذا الغرض. لقد قمت بالفعل بتثبيته على iMac الخاص بي، لذا أشرت إليه بالضبط مع المسار.
ترقية PIP وsetuptools وwheel.
(venv) tortoise-tts % python3.8 -m pip --upgrade pip
(venv) tortoise-tts % python3.8 -m pip install --upgrade setuptools wheel
كنت بحاجة إلى تثبيت “lapack” و “hiredis” باستخدام Homebrew على iMac. قد لا تكون هذه الخطوة ضرورية في نظامك، لكن كان على القيام بها على نظامي.
(venv) tortoise-tts % brew install lapack
(venv) tortoise-tts % brew install hiredis
كنت بحاجة إلى تثبيت “six” و “python-dateutil” مسبقًا أيضًا.
(venv) tortoise-tts % python3.8 -m pip install six python-dateutil
قم بتثبيت حزم تبعية التطبيق.
(venv) tortoise-tts % python3.8 -m pip install -r requirements.txt
أكمل تثبيت “tortoise-tts”.
(venv) tortoise-tts % python3.8 setup.py install
نأمل أن يتم تثبيت كل شيء بدون مشكلة. كان من الصعب بعض الشيء أن أجعلها تعمل ولكن استخدام Python 3.8 وإعادة تثبيت التبعيات المذكورة أعلاه ساعدا.
الاختبار
تطبيق “tortoise-tts” يأتي مع عدد من الأصوات المدرجة. يجدر إجراء اختبار بسيط للتأكد من أنه يعمل.
(venv) tortoise-tts % ls -la tortoise/voices
total 16
drwxr-xr-x 34 user group 1088 16 Jun 17:48 .
drwxr-xr-x 15 user group 480 16 Jun 16:30 ..
-rw-r--r--@ 1 user group 6148 16 Jun 18:20 .DS_Store
drwxr-xr-x 5 user group 160 16 Jun 15:42 angie
drwxr-xr-x 5 user group 160 16 Jun 15:42 applejack
drwxr-xr-x 3 user group 96 16 Jun 15:42 cond_latent_example
drwxr-xr-x 6 user group 192 16 Jun 15:42 daniel
drwxr-xr-x 6 user group 192 16 Jun 15:42 deniro
drwxr-xr-x 5 user group 160 16 Jun 15:42 emma
drwxr-xr-x 5 user group 160 16 Jun 15:42 freeman
drwxr-xr-x 5 user group 160 16 Jun 15:42 geralt
drwxr-xr-x 5 user group 160 16 Jun 15:42 halle
drwxr-xr-x 6 user group 192 16 Jun 15:42 jlaw
drwxr-xr-x 4 user group 128 16 Jun 15:42 lj
drwxr-xr-x 4 user group 128 16 Jun 15:42 mol
drwxr-xr-x 5 user group 160 16 Jun 15:42 myself
drwxr-xr-x 6 user group 192 16 Jun 15:42 pat
drwxr-xr-x 6 user group 192 16 Jun 15:42 pat2
drwxr-xr-x 7 user group 224 16 Jun 15:42 rainbow
drwxr-xr-x 5 user group 160 16 Jun 15:42 snakes
drwxr-xr-x 6 user group 192 16 Jun 15:42 tim_reynolds
drwxr-xr-x 6 user group 192 16 Jun 15:42 tom
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_atkins
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_daws
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_dotrice
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_dreams
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_empire
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_grace
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_kennard
drwxr-xr-x 7 user group 224 16 Jun 15:42 train_lescault
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_mouse
drwxr-xr-x 5 user group 160 16 Jun 15:42 weaver
drwxr-xr-x 6 user group 192 16 Jun 15:42 william
ربما شيء من هذا القبيل:
(venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "I'm going to say this" --voice random --preset fast
سيستخدم هذا أحد الأصوات المذكورة أعلاه بشكل عشوائي ويقول ““I’m going to say this”. يرجى ملاحظة أن الأمر يستغرق بعض الوقت للمعالجة. لدي حاسبة قوية بشكل معقول واستغرق الأمر حوالي 20-30 دقيقة لتوليد هذه الجملة المفردة.
سيتم تخزين النتائج في الدليل التالي:
(venv) tortoise-tts % ls -la results
total 3272
drwxr-xr-x 8 user group 256 16 Jun 18:48 .
drwxr-xr-x 25 user group 800 16 Jun 16:30 ..
-rw-r--r--@ 1 user group 178234 16 Jun 16:29 random_0_0.wav
-rw-r--r--@ 1 user group 182330 16 Jun 16:29 random_0_1.wav
-rw-r--r--@ 1 user group 186426 16 Jun 16:29 random_0_2.wav
يمكنك أيضًا تمرير ملف نصي إليه أيضًا، لكنني أتوقع أنك ستنتظر عدة ساعات ما لم يكن لديك وحدة معالجة الرسومات (GPU) للمعالجة.
هذه هي الأساسيات، وأنا متأكد من أن الجزء التالي هو ما تهتم به!
استنساخ الصوت
افتح ملف الصوت الخاص بك في Audacity.
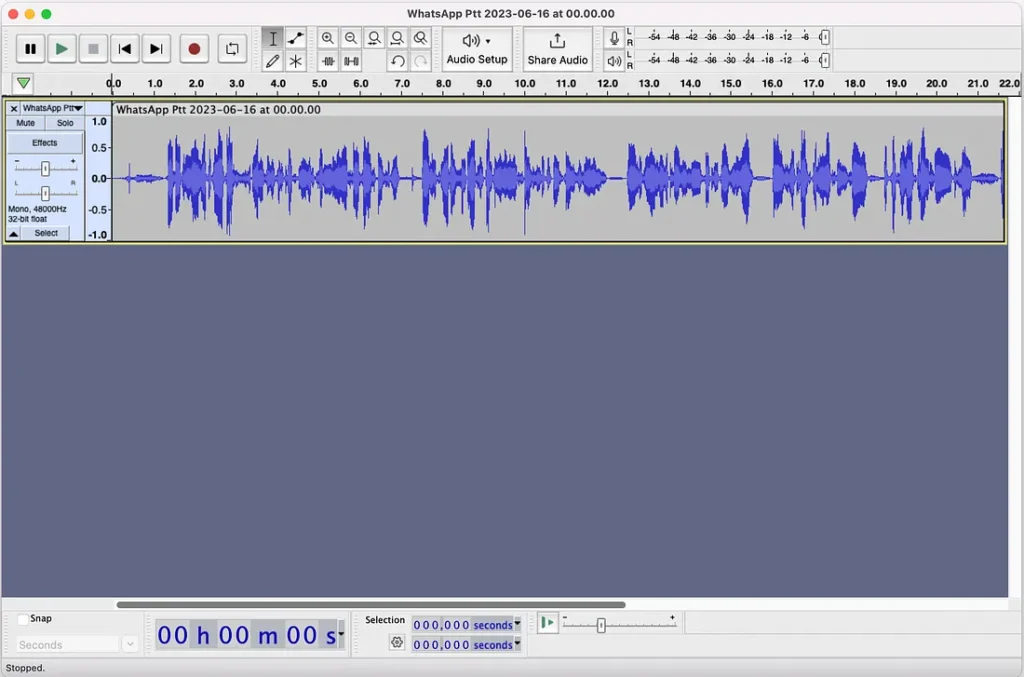
أنت فقط بحاجة إلى ما لا يقل عن ثلاث عينات 10+ ثانية. أفترض أنه كلما قدمت أكثر كلما كانت النتائج أفضل، لكن الأمر سيستغرق وقتًا أطول.
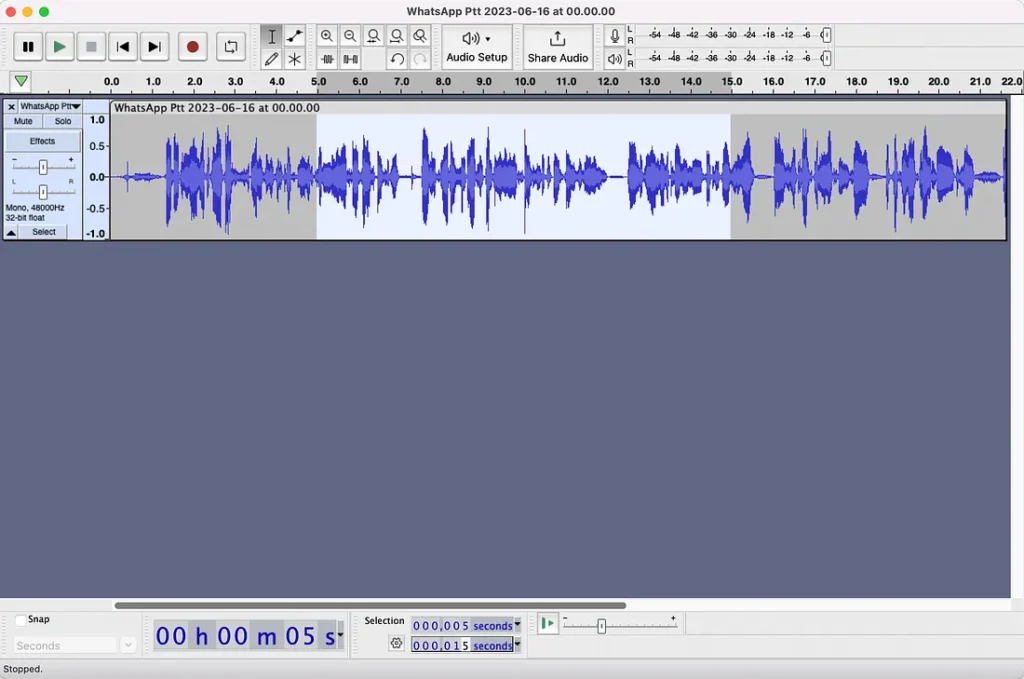
ألق نظرة على ” Selection” في الأسفل. لقد قمت بتعيينه للاختيار من 5 ثوان إلى 15 ثانية. تريد حقًا أن تحتوي عينتك على أكبر قدر ممكن من الكلام.
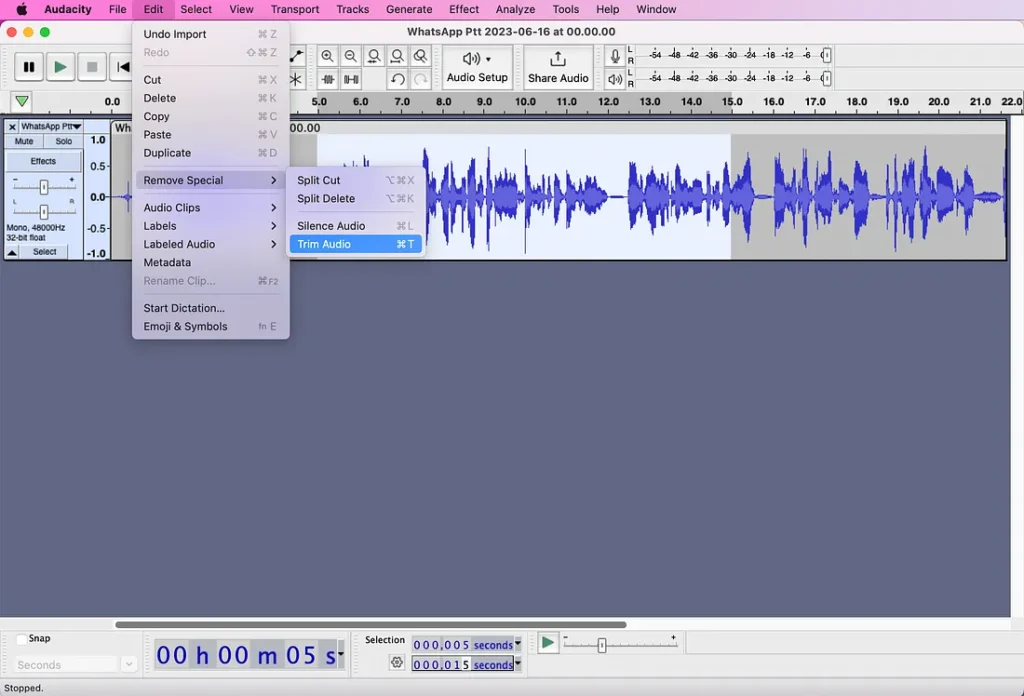
ستلاحظ أن الصورة قد تم اقتطاعها إلى 10 ثوانٍ قمت بتحديدها.
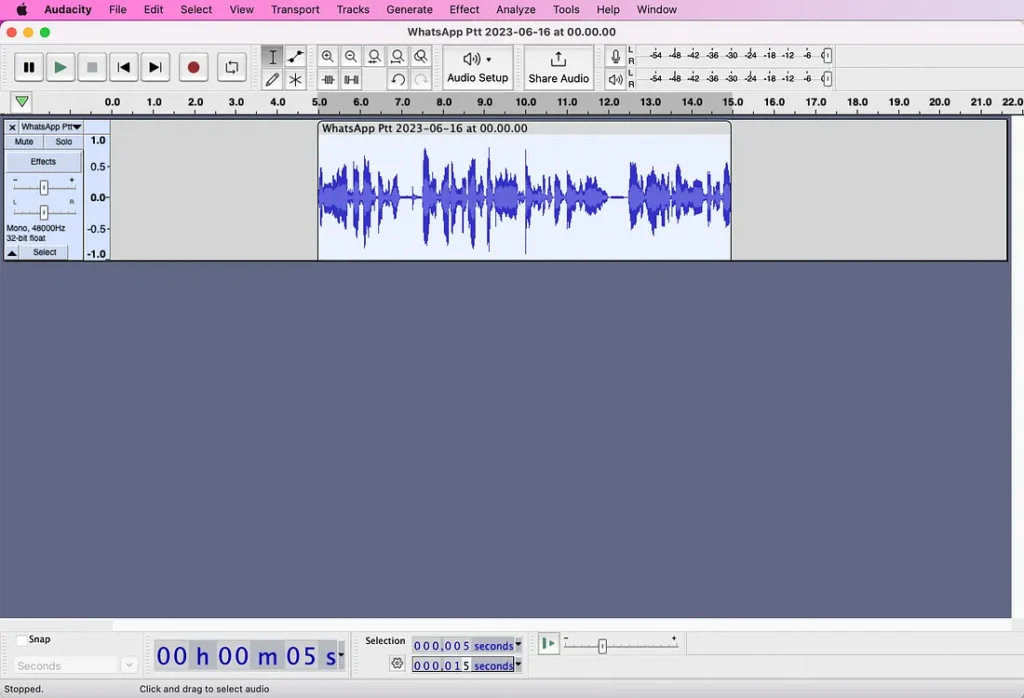
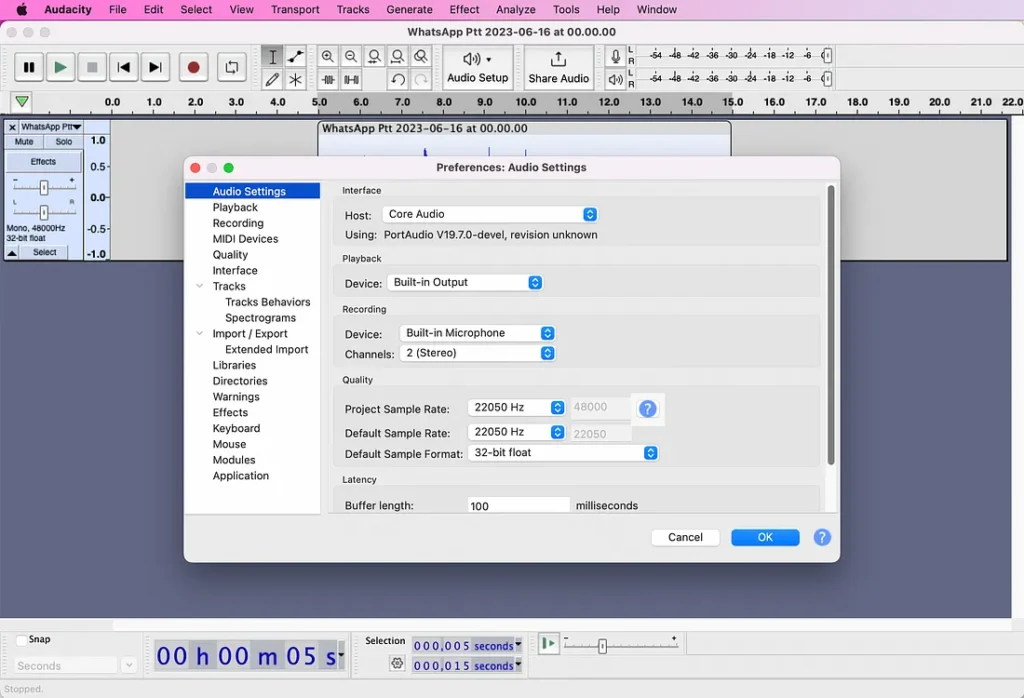
ستلاحظ على اليسار أن العينة هي 48000 هرتز، ويجب أن تكون 22050 هرتز. انتقل إلى تفضيلات Audacity، ضمن ” Audio Settings”، وتأكد من أن كلا من ” Project Sample Rate” و “Default Sample Rate” يبلغان 22050 هرتز. الرجاء ملاحظة أنه عند النقر فوق “OK”، لن يتم التحديث على اليسار. ستظل تقول 48000 هرتز، لكنني أعتقد أن هذا خطأ. سيتم تحديثه بالفعل.
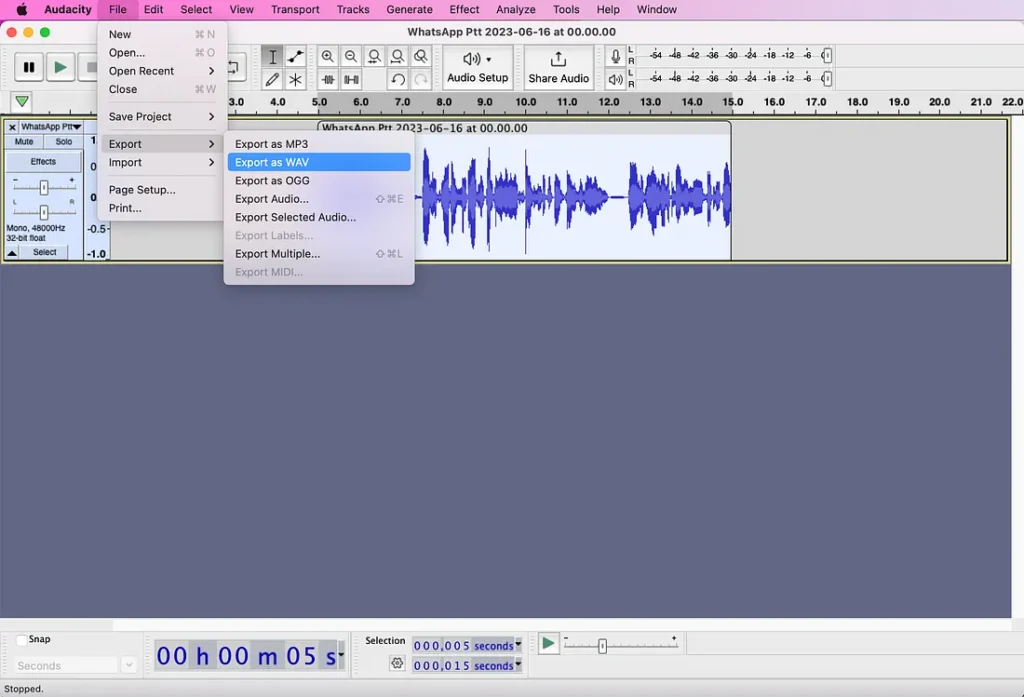
أنت الآن تريد تصدير ملفك المعد كملف WAV.
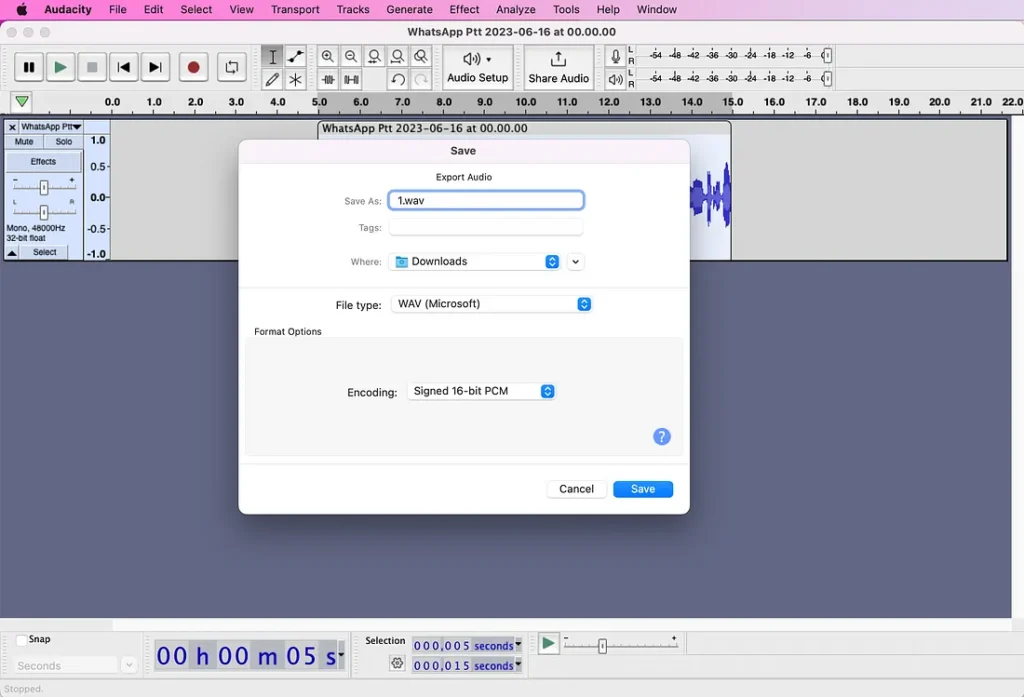
ستحتاج إلى تكرار هذه العملية لإنشاء ثلاث عينات منفصلة تسمى 1.wav و 2.wav و 3.wav. قم بإنشاء دليل تحت عنوان “voices” وانسخ ملفاتك الثلاثة هناك. انا استدعيت، “mytest”.
(venv) tortoise-tts % ls -la tortoise/voices/mytest
total 4064
drwxr-xr-x 5 user group 160 16 Jun 22:15 .
drwxr-xr-x 34 user group 1088 16 Jun 22:15 ..
-rw-r--r-- 1 user group 661544 16 Jun 22:11 1.wav
-rw-r--r-- 1 user group 485144 16 Jun 22:13 2.wav
-rw-r--r-- 1 user group 928518 16 Jun 22:14 3.wav
وأنت تنفذها هكذا …
(venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "This is an A.I. generated voice, what do you think?" --voice mytest --preset fast
يستغرق الأمر بعض الوقت قبل أن يظهر أي تقدم، ولكن عندما ينتهي سيبدو هكذا.
(venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "This is an AI generated voice, what do you think?" --voice mytest --preset fast
Generating autoregressive samples..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 96/96 [12:54<00:00, 8.07s/it]
Computing best candidates using CLVP
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 96/96 [03:53<00:00, 2.43s/it]
Transforming autoregressive outputs into audio..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [04:19<00:00, 3.24s/it]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [02:57<00:00, 2.22s/it]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [02:41<00:00, 2.02s/it]
كما كان من قبل، سيتم تخزين النتائج في “results”.
اضطررت إلى تكرار العملية مرتين للعثور على ثلاث عينات تلتقط الصوت بشكل صحيح لكنها كانت جيدة بشكل مخيف.



