
- ما هو نقل التعلم؟
- تنفيذ هذا البرنامج التعليمي
- عدة أدوات
- VGG16
- استخراج الميزة مع VGG16
- التصنيف المخصص مع VGG16
- استطرادية موجزة حول عدم اليقين الإحصائي
- VGG19
- ResNet50
- حفظ وتحميل نموذج Keras
- تقييم النموذج
- النظر إلى الصور المصنفة بشكل خاطئ
- الخلاصة
- ماذا الان؟
في هذه المقالة، ستتعلم كيفية استخدام نقل التعلم transfer learning للتعرف على الصور بشكل فعال، باستخدام keras وTensorFlow والشبكات العصبية المدربة مسبقًا: VGG16 وVGG19 وResNet50.
في هذه العملية سوف تفهم ما هو نقل التعلم، وكيفية القيام ببعض الأشياء التقنية:
- إضافة طبقات إلى شبكة عصبية حالية مدربة مسبقًا لتكييفها مع احتياجاتك.
- احفظ نموذج keras بحيث يمكنك إعادة استخدامه لاحقًا، دون الحاجة إلى إعادة التدريب.
- تقييم أداء النموذج وإلقاء نظرة على الصور التي تم التعرف عليها بشكل خاطئ.
(يُرجى الانتباه إلى أن هذا المنشور لا يقدم مقارنة للأداء بين النماذج الثلاثة. سيكون من الصعب جدًا القيام بذلك بطريقة مناسبة وعادلة).
لكن اولا …
ما هو نقل التعلم؟
في المقال السابق التعرف على الصور: الكلاب مقابل القطط!، لقد رأينا كيفية بناء شبكة تلافيفية بسيطة من البداية لتصنيف صور الكلاب والقطط بدقة 92٪.
الشبكات العصبية التلافيفية الحديثة مثل VGG أو ResNet أو Inception، ستكون قادرة على أداء هذه المهمة بدقة تزيد عن 99٪. لكن هذه النماذج عميقة ومعقدة. لذلك من الصعب تدريبهم، وهناك عدد كبير جدًا من الصور ضرورية لتدريب هذه الشبكات دون تعرضها للضبط الزائد overfitting.
في الواقع، يتم تدريب هذه النماذج الآن على مجموعة بيانات ImageNet، والتي تضم أكثر من 14 مليون صورة مصنفة في 1000 فئة. بالمقارنة مع ذلك، فإن مجموعة بيانات الكلاب والقطط، التي تحتوي على 25000 صورة، صغيرة بشكل يبعث على السخرية. وقد رأينا في المقالة السابقة أنه حتى مع شبكتنا البسيطة، فنحن مضطرون إلى استخدام زيادة قوية للبيانات للحد من الضبط الزائد. لذا فإن تدريب نموذج معقد على مجموعة البيانات هذه أمر غير وارد.
إذن كيف يمكننا تحسين أداء التصنيف في مجموعة البيانات الصغيرة الخاصة بنا إذا لم تكن هناك طريقة لتدريب نموذج معقد على مجموعة البيانات هذه؟
الحل هو نقل التعلم ، ومن السهل جدًا تنفيذه تقنيًا كما سنرى!
ها هي الفكرة.
أولاً، ضع في اعتبارك بنية الشبكة التلافيفية VGG16، الموضحة أدناه.
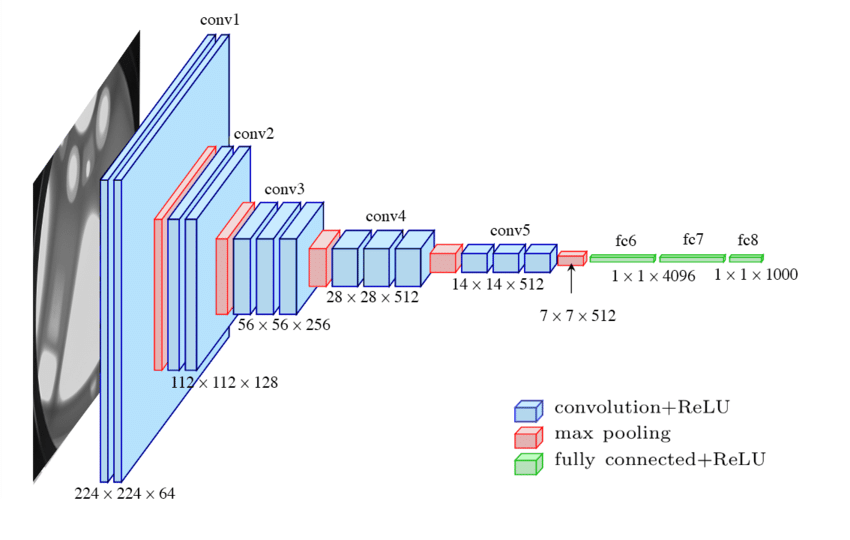
في الجزء الأول من الشبكة، نرى خمس كتل تلافيفية convolutional blocks (من 1 إلى 5)، والتي تتكون في طبقات تلافيفية convolutional layers مكدسة تليها طبقة تجميع قصوى max pooling layer (يمكنك العثور على شرح حول هذه الطبقات هنا). لذلك سنسمي هذا الجزء الجزء التلافيفي convolutional part.
ينتج هذا الجزء موترًا بقيم 7x7x512 لكل صورة. يتماشى البعدان الأولان (7،7) مع أبعاد الصورة الأصلية، ويمكننا التفكير في هذا كنسخة خشنة للغاية من الصورة، مع 7 × 7 = 49 بكسل فقط. ولكن لكل بكسل، بدلاً من وجود 3 قنوات ملونة، لدينا 512 ميزة تصف ما تراه الشبكة في هذا البكسل (وأيضًا حوله).
لذلك يحتوي هذا الموتر على 7 7x7x512 = 25 088 رقمًا وهي الميزات المستخرجة بواسطة الشبكة للصورة.
ولكن ما هي بالضبط هذه “الميزات features”؟
في منشوري حول Real Time Human Detection with OpenCV، استخدمنا خوارزمية ذكية (ومعقدة إلى حد ما)، الرسوم البيانية للتدرجات الموجهة (HOG)، لاستخراج ميزات الصورة (أساسًا الحواف في الصورة). يتم بعد ذلك تفسير هذه الميزات بواسطة Support Vector Machine (SVM) لتحديد ما إذا كان هناك إنسان في نافذة الكشف أم لا.
هنا، وبشكل عام في التعلم العميق، ندع الشبكة تكتشف الميزات من تلقاء نفسها أثناء التدريب! لا حاجة لتصميم وترميز خوارزمية استخراج ميزة معقدة، فنحن فقط نعطي الشبكة بُنية ذات مرونة كافية ونقوم بتدريبها بالأمثلة.
فكر في طفل.
لا أعرف الكثير عن الدماغ البشري ولا عن الرؤية البشرية، ولدي خبرة محدودة فقط مع الأطفال! (حصلت على اثنين.) على أي حال هنا ما أعتقد. اعتبرها تشبيهًا، ربما يكون صحيحًا، ربما يكون خاطئًا، لكنني أجده مثيرًا للاهتمام.
خلال الساعات الأولى من حياته، يجب أن يتعلم الطفل كيف يرى. وأعني بذلك أن أفهم تدفقات الإشارات الغامرة التي تأتي من عينيها. أظن أنه في البداية، يتعلم الطفل كيفية رؤية الخطوط، عن طريق توصيل المعلومات من قضبان الشبكية والمخاريط المجاورة. ثم تبدأ في رؤية الأشكال والتعرف على الأشياء. هذا نوع من عملية التعلم غير الخاضع للإشراف: تحتاج فقط إلى تحريك عينيك لترى أن الأشياء متصلة، ولا داعي لعرض أمثلة. وبعد ذلك بكثير، سيتمكن الطفل من استخدام التعلم الخاضع للإشراف: القط! تقول. لا، هذا نمر.
تم تدريب VGG16 على مجموعة بيانات ImageNet الكبيرة وهو قادر بالفعل على الرؤية.
ولكن تم تدريبه أيضًا على تصنيف الصور في 1000 فئة من ImageNet.
يحدث التصنيف في الجزء الثاني من النموذج، والذي يأخذ ميزات الصورة في الإدخال ويختار فئة. يحتوي جزء المصنف هذا على:
- طبقتان مخفيتان متصلتان بالكامل fully connected (أو كثيفتان dense)، تحتوي كل منهما على 4096 خلية عصبية.
- طبقة كثيفة تحتوي على 1000 خلية عصبية، واحدة لكل فئة من فئات ImageNet. يتم استخدام دالة تنشيط softmax لهذه الخلايا العصبية، بحيث تصل القيم الألف التي يصدرونها إلى الوحدة، ويمكن اعتبارها احتمالات.
ما سنفعله، بالنسبة لـ VGG16 والنماذج الأخرى المدربة مسبقًا، هو تنزيل النموذج بالأوزان الناتجة عن التدريب على ImageNet. بعد ذلك، سنقوم باستبدال جزء المصنف بمصنف بسيط خاص بنا، يتكيف مع مشكلتنا. على سبيل المثال، سيحتوي هذا المصنف على خليتين عصبيتين فقط في الطبقة الأخيرة، واحدة للكلب والأخرى للقطة. أخيرًا، سنقوم بتجميد جميع طبقات الجزء التلافيفي، بحيث يكون علينا فقط تدريب معلمات المصنف الخاص بنا على مجموعة البيانات الصغيرة الخاصة بنا.
لذلك دعونا نرى كيفية القيام بذلك تقنيًا باستخدام keras.
تنفيذ هذا البرنامج التعليمي
لتشغيل هذا البرنامج التعليمي، سوف تحتاج إلى:
- جهاز كمبيوتر يعمل بنظام Linux أو Windows مزود بوحدة معالجة رسوميات GPU.
- حزم بايثون محددة للتعلم العميق (Keras ، TensorFlow) ولتحليل النتائج (numpy ، matplotlib)
- مجموعة بيانات الكلاب والقطط.
إذا كنت ترغب في إعداد هذا، يرجى الرجوع إلى التعليمات الواردة في منشوري الأولى التعرف على الصور: الكلاب مقابل القطط! (92٪).
عند الانتهاء، حدد الخلية الموجودة أسفل موقع دليل مجموعة البيانات، أي الخلية التي تحتوي على الدلائل الفرعية للكلاب والقطط. ثم قم بتنفيذ الخلية لاستيراد الحزم المطلوبة.
# define and move to dataset directory
datasetdir = '/data2/cbernet/maldives/dogs_vs_cats'
import os
os.chdir(datasetdir)
# import the needed packages
import matplotlib.pyplot as plt
import matplotlib.image as img
import tensorflow.keras as keras
import numpy as np
عدة أدوات
سنبدأ بتحديد دالتي سنحتاجهما لاحقًا.
تقوم الدالة الأولى، المولداتgenerators ، بإرجاع اثنين من مكررات الصور التي سنستخدمها لإنتاج مجموعات من الصور للتدريب والتحقق من صحة شبكاتنا العصبية.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 30
def generators(shape, preprocessing):
'''Create the training and validation datasets for
a given image shape.
'''
imgdatagen = ImageDataGenerator(
preprocessing_function = preprocessing,
horizontal_flip = True,
validation_split = 0.1,
)
height, width = shape
train_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'training',
)
val_dataset = imgdatagen.flow_from_directory(
os.getcwd(),
target_size = (height, width),
classes = ('dogs','cats'),
batch_size = batch_size,
subset = 'validation'
)
return train_dataset, val_dataset
تحتوي الدوال على معلمتين، الشكل shape والمعالجة المسبقة preprocessing ، والتي تعتمد على النموذج المستخدم مسبقًا.
تقوم iterators load بتحميل صور القطط والكلاب من القرص وتحويل هذه الصور إلى مصفوفات بالشكل المحدد. إذا كان الشكل خاطئًا، فلن يتم تكييف الصور مع النموذج، وسوف يتعطل الكود. لذلك علينا توخي الحذر لاختيار الشكل الصحيح لكل نموذج مدرب مسبقًا سنستخدمه. تلتقط كل من VGG16 وVGG19 وResNet50 صورًا ذات شكل (224،224،3)، لذلك مع ثلاث قنوات ملونة في 224 × 224 بكسل. لكن InceptionV3، على سبيل المثال، قد يلتقط صورًا للشكل (299،299،3).
يتم إنشاء التكرارات بواسطة ImageDataGenerator من keras الذي يقوم بما يلي:
- لديها فرصة 50٪ لقلب اليسار واليمين في الصورة. يوفر هذا زيادة أساسية للبيانات دون تكلفة كبيرة من حيث الحوسبة. في الواقع، يتم تنفيذ التقليب بسهولة تحت الغطاء بواسطة numpy بطريقة فعالة للغاية.
- ثم يقوم بتطبيق دالة preprocessingعلى الصورة. يجب تكييف هذه الدالة مع النموذج المدرب مسبقًا المستخدم، ويتم تمريرها إلى دالة generators كوسيطة. في الواقع، في لغة بايثون، الدالة هي كائن، يمكن أن تنتقل بسهولة إلى دوال أخرى).
- يحتفظ بـ 90٪ من الصور للتدريب، ويحجز 10٪ من الصور للتحقق من صحتها. نظرًا لأن لدينا حوالي 25000 صورة في مجموعة البيانات الخاصة بنا إجمالاً، فإن هذا يترك 2500 صورة للتحقق الدقيق إلى حد ما (المزيد حول هذا لاحقًا).
سيتم استخدام الدالة الثانية لرسم الدقة accuracy والخطأ loss كدالة للفترة epoch، حتى نتمكن من رؤية كيفية عمل التدريب. للحصول على شعور بالضبط الزائد، سيتم رسم هذه الكميات لكل من مجموعات بيانات التدريب training والتحقق من الصحة validation:
def plot_history(history, yrange):
'''Plot loss and accuracy as a function of the epoch,
for the training and validation datasets.
'''
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
# Get number of epochs
epochs = range(len(acc))
# Plot training and validation accuracy per epoch
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
plt.title('Training and validation accuracy')
plt.ylim(yrange)
# Plot training and validation loss per epoch
plt.figure()
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')
plt.show()
نحن الآن جاهزون للبدء بأول نموذج مدرب مسبقًا.
VGG16
تم إنشاء أول نماذج VGG بواسطة Karen Simonyan و Andrew Zisserman، وتم تقديمها لأول مرة في ورقة شبكات تلافيفية عميقة للغاية للتعرف على الصور على نطاق واسع في عام 2015. VGG16 بها 16 طبقة مع أوزان ، و VGG99 بها 19 طبقة مع أوزان.
في ذلك الوقت، كانت طرازات VGG بمثابة اختراق حقيقي لعدد من الأسباب. أولاً، كان المؤلفون قادرين على التفوق في الأداء على المنافسة بنسبة كبيرة في تحدي التعرف المرئي على نطاق واسع Image Net (ILSVRC). بعد ذلك، أظهروا أنه مع نقل التعلم، فإن نماذجهم تعمم جيدًا على مهام التعرف على الصور الأخرى على مجموعات بيانات أصغر (انظر الملحق B في المقالة)، مما يحقق أداءً متطورًا على مجموعات البيانات هذه أيضًا. أخيرًا، أتاحوا أفضل شبكاتهم أداءً للجمهور لمزيد من البحث والتطبيقات العملية.
من المثير للدهشة أن بُنية VGG واضحة تمامًا وتشبه إلى حد كبير الشبكات التلافيفية الأصلية. كانت الفكرة الرئيسية وراء VGG هي جعل الشبكة أعمق من خلال تكديس المزيد من الطبقات التلافيفية. وقد أصبح هذا ممكنًا من خلال قصر حجم النوافذ التلافيفية على 3 × 3 بكسل فقط.
استخراج الميزة مع VGG16
لذلك دعونا نلقي نظرة على بُنية VGG16. لهذا، قمنا بإنشاء مثيل من طراز VGG16 باستخدام keras، ونطبع الملخص:
vgg16 = keras.applications.vgg16
vgg = vgg16.VGG16(weights='imagenet')
vgg.summary()
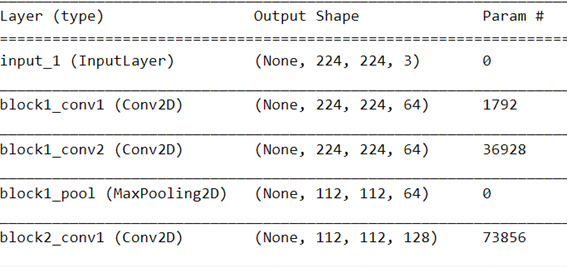


نرى بوضوح الجزء التلافيفي وجزء المصنف. بين الاثنين، تقوم الطبقة المسطحة Flatten layer بتحويل موتر الميزة للشكل (7،7،512) إلى مصفوفة 1D مع 7x7x512 = 25088 قيم، والتي يمكن إرسالها كمدخلات إلى أول طبقة كثيفة Dense layer من المصنف.
تم تكييف المصنف مع 1000 فئة من ImageNet. ومع ذلك، فإن مهمتنا هي تصنيف صور الكلاب والقطط، لذلك لدينا فئتان فقط.
ماذا نستطيع ان نفعل؟ باستخدام keras، من السهل استيراد الجزء التلافيفي فقط من VGG16، عن طريق تعيين المعلمة include_top على False :
vgg16 = keras.applications.vgg16
conv_model = vgg16.VGG16(weights='imagenet', include_top=False)
conv_model.summary()


يمكنك التحقق في الملخص من أن المصنف قد تمت إزالته بالفعل.
يمكن استخدام النموذج التلافيفي بالفعل لاستخراج الميزات لصورة معينة:
from keras.preprocessing import image
img_path = 'dogs/dog.1.jpg'
# loading the image:
img = image.load_img(img_path, target_size=(224, 224))
# turn it into a numpy array
x = image.img_to_array(img)
print(np.min(x), np.max(x))
print(x.shape)
# expand the shape of the array,
# a new axis is added at the beginning:
xs = np.expand_dims(x, axis=0)
print(xs.shape)
# preprocess input array for VGG16
xs = vgg16.preprocess_input(xs)
# evaluate the model to extract the features
features = conv_model.predict(xs)
print(features.shape)

دعونا نلقي نظرة فاحصة على هذا الكود.
أول شيء مهم يجب ملاحظته هو أن طريقة التنبؤ predict لنموذجنا مصممة للعمل على عدة صور. من المفترض أن يتم تخزين هذه الصور في مصفوفة numpy ذات شكل (n,224,224,3))، حيث n هو عدد الصور المراد معالجتها. لذلك أولاً، قمنا بتحميل صورة، وقمنا بتحويلها إلى مصفوفة متعددة الأشكال (224,224,3). لمطابقة توقيع طريقة predict، أنشأنا بعد ذلك مصفوفة من الأشكال (1,224,224,3) باستخدام np.expand_dims .
النقطة المهمة الأخرى هي أن VGG16 قد تم تدريبه على الصور المعالجة مسبقًا. نقلا عن مقالة VGG.
“المعالجة الوحيدة التي نقوم بها هي طرح متوسط قيمة RGB ، المحسوبة في مجموعة التدريب من كل بكسل”
للوصول إلى أقصى أداء، من المهم تطبيق نفس المعالجة المسبقة بالضبط قبل تقييم الشبكة. يدعو Keras إلى استخدام vgg16.preprocess_inputs لهذا الغرض، لذلك هذا ما سنفعله.
يمكنك طباعة موتر الميزة feature tensor إذا كنت ترغب في ذلك، لكن هذا لن يخبرك كثيرًا. هذه في الحقيقة مجرد مجموعة (كبيرة) من الأرقام. لفهم هذه الأرقام، نحتاج إلى إنشاء المصنف الخاص بنا.
يمكن أن يكون أحد الاحتمالات تخزين الميزات في مصفوفات البيانات لكل صورة. بعد ذلك، يمكننا تدريب شبكة عصبية صغيرة على هذه المصفوفات. سيكون هذا النهج قابلاً للتطبيق تمامًا. ومع ذلك، هذا ليس ما سنفعله. بدلاً من ذلك، سنقوم بتمديد VGG16 باستخدام المصنف الخاص بنا. هذا الحل أسهل في التنفيذ وهو أيضًا أكثر مرونة.
التصنيف المخصص مع VGG16
في وثائق Keras لـ VGG16، وكذلك في المقال الأصلي، نرى أن إدخال VGG16 يجب أن يكون صورًا بدقة 224 × 224 بكسل. ونعلم أيضًا أنه يجب معالجة الصور بالطريقة الصحيحة لهذا النموذج. لذلك قمنا بإنشاء مكررات للتدريب والتحقق من الصحة لإنتاج مثل هذه الصور، مع الدالة التي حددناها في بداية هذا المنشور:
train_dataset, val_dataset = generators((224,224), preprocessing=vgg16.preprocess_input)

كما ترون، ليس لدي كل 25000 صورة لمجموعة بيانات الكلاب والقطط. هذا لأنني قمت بتنظيف مجموعة البيانات لإزالة بعض الأمثلة السيئة حقًا، كما هو موضح في التعرف على الصور: الكلاب والقطط. إذا لم تكن قد فعلت ذلك، فلا تقلق، فسيعمل هذا البرنامج التعليمي بشكل جيد.
نقوم بإنشاء الجزء التلافيفي مرة أخرى، حيث نحتاج إلى تحديد شكل الإدخال input_shape هذه المرة حتى نتمكن من إنشاء النموذج الكامل:
conv_model = vgg16.VGG16(weights='imagenet', include_top=False, input_shape=(224,224,3))
إذا لم تحدد input_shape، تظل أبعاد الشبكة غير محددة، وينتهي بك الأمر برسالة الخطأ التالية عندما تحاول إنشاء أول طبقة كثيفة من المصنف أدناه.

ثم نقوم بتوصيل ناتج الجزء التلافيفي بالمصنف:
# flatten the output of the convolutional part:
x = keras.layers.Flatten()(conv_model.output)
# three hidden layers
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
# final softmax layer with two categories (dog and cat)
predictions = keras.layers.Dense(2, activation='softmax')(x)
# creating the full model:
full_model = keras.models.Model(inputs=conv_model.input, outputs=predictions)
full_model.summary()

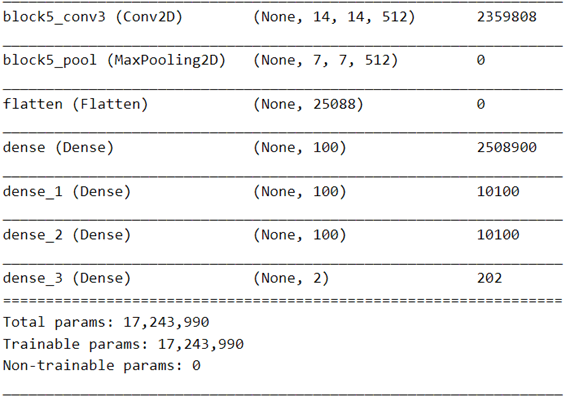
نقوم بإغلاق جميع طبقات الجزء التلافيفي:
for layer in conv_model.layers:
layer.trainable = False
ونتحقق من أن الطبقات الوحيدة التي سيتم تدريبها هي طبقات المصنف الكثيف dense classifier:
full_model.summary()


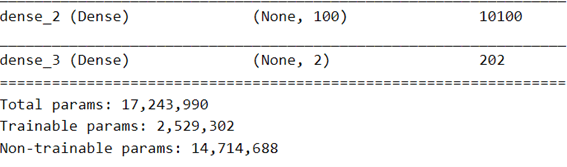
في الواقع، نرى أن عدد المعلمات القابلة للتدريب هو العدد الإجمالي للمعلمات في آخر 4 طبقات كثيفة:
2508900+10100*2+202
يمكننا الآن تجميع النموذج وتدريبه:
full_model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adamax(lr=0.001),
metrics=['acc'])
history = full_model.fit_generator(
train_dataset,
validation_data = val_dataset,
workers=10,
epochs=5,
)

plot_history(history, yrange=(0.9,1))
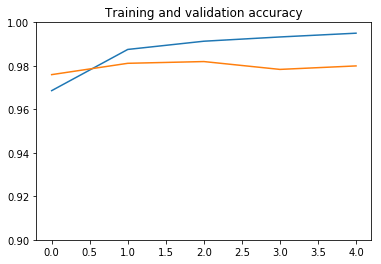
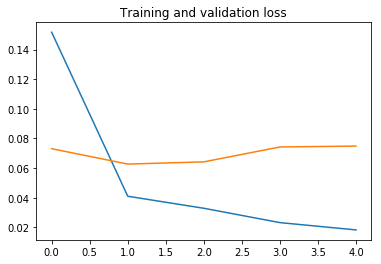
نرى أن النموذج سريع جدًا في التدريب، حيث نحتاج فقط إلى تدريب جزء المصنف. فترة واحدة تكفي في الواقع للوصول إلى دقة تحقق تبلغ حوالي 98٪، وهي نسبة أعلى بكثير من 92٪ التي حصلنا عليها عندما قمنا بتدريب شبكة تلافيفية بسيطة من الصفر بمفردنا في التعرف على الصور: الكلاب مقابل القطط!.
بعد ذلك، الضبط الزائد overfitting معتدل ويحد من الأداء. ربما يمكننا العمل على الضبط الزائد عن طريق تبسيط المصنف، أو عن طريق إضافة طبقة تسرب dropout layer قبل المصنف مباشرة. لكن هذا خارج نطاق هذا المنشور.
استطرادية موجزة حول عدم اليقين الإحصائي
لاحظ أن قيمة الدقة لا ينبغي أن تؤخذ على محمل الجد. تعتمد دقة التحقق على عينة التحقق المحددة التي اختارها المولد، ويتأثر هذا الرقم بعدم اليقين الإحصائي statistical uncertainty. بشكل تقريبي، لدينا 2500 صورة في مجموعة بيانات التحقق من الصحة. عدم دقة 2٪ يعني أننا أخطأنا في تصنيف 50 صورة.
نظرًا لأن هذا الرقم صغير إلى حد ما، فإنه يتأثر بعدم اليقين الإحصائي الكبير إلى حد ما. ويمكننا تقدير عدم اليقين النسبي على هذا الرقم على أنه . كما أن عدم اليقين النسبي بشأن عدم الدقة يبلغ 15٪. لذلك بالنسبة لعدم الدقة بنسبة 2٪، لدينا عدم يقين مطلق قدره 2 × 0.15 = 0.3٪.
لذلك، عندما نتحدث عن دقة 98٪، يجب أن تتذكر أن الدقة الحقيقية يجب أن تكون في حدود .
يمكننا استخدام مجموعة بيانات تحقق أكبر لتقليل عدم اليقين، لكن هذا سيترك صورًا أقل لتدريب شبكاتنا العصبية.
VGG19
VGG19 هو أحدث إصدار من طرازات VGG وهو مشابه جدًا لـ VGG16. إذا قارنت ملخص النموذج أدناه بملخص VGG16، فسترى أن البُنية هي نفسها، ولا تزال تعتمد على خمس كتل تلافيفية.
ومع ذلك، فقد تم زيادة عمق الشبكة عن طريق إضافة طبقة تلافيفية في الكتل الثلاثة الأخيرة.
لا يزال الإدخال عبارة عن صورة RGB للشكل (224،224،3)، والإخراج هو ميزة موتر للشكل (7،7،512). يوفر Keras دالة معالجة مسبقة محددة لـ VGG19، ولكن إذا نظرت إلى الكود، فسترى أنها نفس الدالة تمامًا مثل VGG 16. لذلك لا نحتاج إلى إعادة تعريف مكررات مجموعة البيانات الخاصة بنا.
لنقم الآن ببناء النموذج الكامل والتحقق منه:
vgg19 = keras.applications.vgg19
conv_model = vgg19.VGG19(weights='imagenet', include_top=False, input_shape=(224,224,3))
for layer in conv_model.layers:
layer.trainable = False
x = keras.layers.Flatten()(conv_model.output)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
predictions = keras.layers.Dense(2, activation='softmax')(x)
full_model = keras.models.Model(inputs=conv_model.input, outputs=predictions)

full_model.summary()
full_model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adamax(lr=0.001),
metrics=['acc'])
history = full_model.fit_generator(
train_dataset,
validation_data = val_dataset,
workers=10,
epochs=5,
)
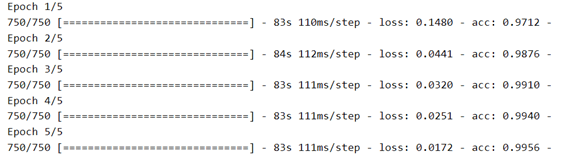
plot_history(history, yrange=(0.9,1))
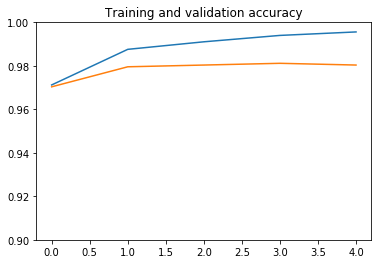
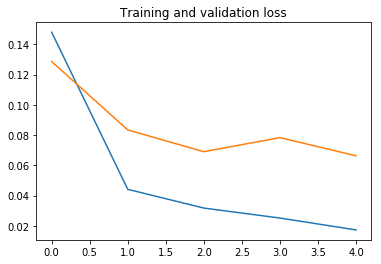
ResNet50
تم تقديم ResNet لأول مرة في عام 2015 بواسطة Kaiming He و Xiangyu Zhang و Shaoqing Ren و Jian Sun في ورقتهم الممتازة Deep Residual Learning للتعرف على الصور.
من بين الإنجازات الأخرى، تمكن المؤلفون من تأمين المركز الأول في تحدي ILSVRC 2015!
كما أشار مؤلفو VGG بالفعل، فإن عمق التمثيل مهم للغاية. في حالة VGG، يمكن بناء شبكات أعمق باستخدام مرشحات تلافيفية أصغر.
من ناحية أخرى، كان لمؤلفي ResNet فكرة ذكية أخرى: يتم تدريب كتل من بضع طبقات مكدسة على تعلم دالة متبقية residual function فيما يتعلق بإدخال الكتلة، بدلاً من تعلم دالة عامة دون الرجوع في سياق هندسة الشبكات.
طيب ولكن ماذا يعني هذا؟
من أجل فهم جيد لشبكة ResNet، أنصح بشدة بقراءة الورقة البحثية المكتوبة جيدًا والتعليمية والمفصلة. إذا كنت ترغب في بدء قراءة الأوراق حول التعلم الآلي (وربما حتى الأوراق العلمية بشكل عام)، فهذا مرشح جيد!
لكن هذا ليس ضروريًا في الواقع لمجرد استخدام ResNet. سألخص هنا وأبسط قليلًا.
أولاً، تذكر أن الشبكات العصبية هي مجرد دوال، ويمكنك العثور على مناقشة حول ذلك في The 1-Neuron Network: Logistic Regression. إنها متعددة الأبعاد (كل رقم في صورة الإدخال هو بُعد) وقد تحتوي على ملايين المعلمات والعديد من قيم الإخراج (هنا واحد لكل فئة). ومع ذلك، فهي دوال. يعني تدريب الشبكة ملاءمة الدالة للبيانات عن طريق ضبط معلماتها.
بدلاً من التفكير في شبكة ResNet بأكملها، دعنا نركز على إحدى اللبنات الأساسية الخاصة بها مع هذه الصورة المستخرجة من الورقة:
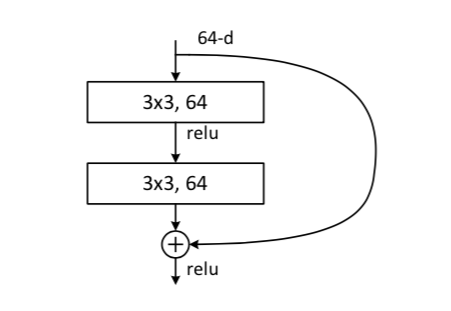
التعلم المتبقي Residual learning، هو وحدة بناء. تأخذ الطبقة التلافيفية الأولى في الجزء العلوي خريطة معالم بها بكسلات nxn ، ولكل منها 64 معلمًا. يقوم اختصار الهوية identity shortcut بنسخ بيانات الإدخال، والتي يتم جمعها مع إخراج الطبقة التلافيفية الثانية.
إذا كانت صورة الإدخال ، فيمكننا التفكير في دالة الشبكة بأكملها كتكوين لدوال وحدات البناء ،
في الشبكات الكلاسيكية، لا يوجد اختصار للتعريف، ويجب على الكتلة أن تتعلم الدالة مباشرة. في ResNet ، مع اختصار الهوية ، لدينا:
حيث f_i (x) هي الدالة المتبقية. بهذه الطريقة، يجب أن تتعلم الكتلة فقط الدالة المتبقية، والتي توفر انحرافات صغيرة فيما يتعلق بالمدخلات. لا يتعين على الكتلة إعادة إنتاج مدخلاتها بعد الآن، بالإضافة إلى نمذجة الانحرافات الصغيرة.
علاوة على ذلك، لا تؤدي إضافة اختصار الهوية إلى زيادة عدد معلمات الكتلة، لأن اختصار الهوية لا يحتوي على معلمة! انها مجرد نسخة.
كما هو موضح في الورقة، فإن هذا التغيير هو الذي جعل من الممكن إنشاء شبكات عميقة للغاية. على سبيل المثال، يحتوي الجزء التلافيفي لشبكة ResNet50 التي سنستخدمها على 50 طبقة، بينما يحتوي VGG19 على 22 طبقة. وهناك أيضًا إصداران أعمق من ResNet وResNet101 وResNet152.
في الوقت نفسه، يتم الاحتفاظ بعدد المعلمات في ResNet50 إلى 34 مليون يمكن التحكم فيها، مقارنة بـ 23 مليون معلمة من VGG19! هذا ما يجعل من الممكن تعلم تمثيل عميق جدًا بسهولة من مجموعة بيانات “محدودة” تضم حوالي مليون صورة.
لذلك دعونا نبني شبكة ResNet50 باستخدام keras. أولاً، نقوم بإنشاء مكررات مجموعة البيانات الخاصة بنا، مع شكل الإدخال الصحيح ودوال المعالجة المسبقة:
resnet50 = keras.applications.resnet50
train_dataset, val_dataset = generators((224,224), preprocessing=resnet50.preprocess_input)
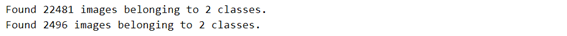
بعد ذلك، نقوم بإنشاء نموذجنا الكامل، وهو الجزء التلافيفي من ResNet50 متبوعًا بمصنفنا البسيط، تمامًا مثل VGG ، ونقوم بتدريبه.
conv_model = resnet50.ResNet50(weights='imagenet', include_top=False, input_shape=(224,224,3))
for layer in conv_model.layers:
layer.trainable = False
x = keras.layers.Flatten()(conv_model.output)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
predictions = keras.layers.Dense(2, activation='softmax')(x)
full_model = keras.models.Model(inputs=conv_model.input, outputs=predictions)
full_model.summary()

full_model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adamax(lr=0.001),
metrics=['acc'])
history = full_model.fit_generator(
train_dataset,
validation_data = val_dataset,
workers=10,
epochs=5,
)
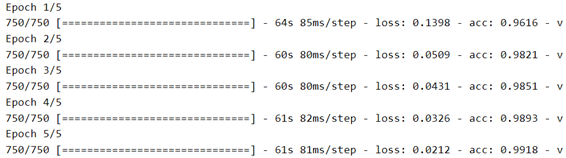
plot_history(history, yrange=(0.9,1))
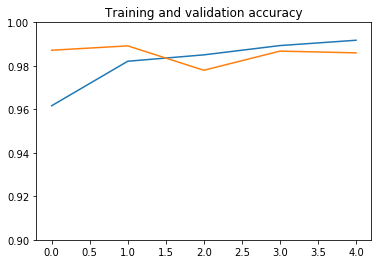
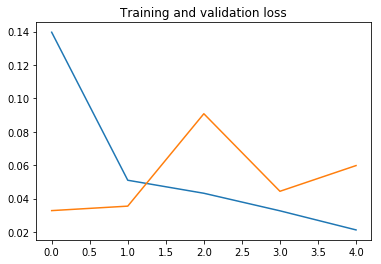
حفظ وتحميل نموذج Keras
لنفترض أنك حصلت على أداء ممتاز باستخدام نموذج معين. أنت بالتأكيد تريد حفظ هذا النموذج للاستخدام في المستقبل. لنفعل هذا الآن مع نموذجنا القائم على ResNet50، وهو آخر نموذج قمنا بتدريبه.
باستخدام Keras ، من الممكن جعل النموذج الكامل ثابتًا على القرص ، ولكن قد تصبح النماذج غير قابلة للقراءة عند استخدام طبقات غير قياسية.
أجد حفظ أوزان النموذج (المعلمات) أسهل:
full_model.save_weights('resnet50.h5')
لقراءتها مرة أخرى، نقوم بإنشاء نموذج جديد مطابق للنموذج الذي قمنا بتدريبه:
conv_model = resnet50.ResNet50(weights='imagenet', include_top=False, input_shape=(224,224,3))
for layer in conv_model.layers:
layer.trainable = False
x = keras.layers.Flatten()(conv_model.output)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
x = keras.layers.Dense(100, activation='relu')(x)
predictions = keras.layers.Dense(2, activation='softmax')(x)
full_model = keras.models.Model(inputs=conv_model.input, outputs=predictions)
ونقوم بتحميل الأوزان:
full_model.load_weights('resnet50.h5')
تقييم النموذج
يمكننا البدء بتقييم صورة واحدة (لاحظ أننا نستخدم الآن النموذج الذي تم حفظه وإعادة تحميله):
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input
img_path = 'dogs/dog.1.jpg'
img = image.load_img(img_path, target_size=(224,224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print(full_model.predict(x))
plt.imshow(img)
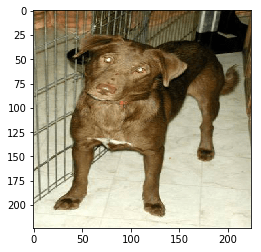
تعطي شبكتنا العصبية هذه الصورة احتمالية هائلة بنسبة 99.993٪. هذا في الواقع ليس مفاجئًا للغاية: هذا كلب نموذجي، لذلك لا توجد صعوبة هنا.
ولكن ماذا عن الصور الأخرى في مجموعة البيانات؟ سيكون من الممتع للغاية النظر إلى الصور التي تم التعرف عليها بشكل خاطئ، لمعرفة ما يحدث معها. لنبدأ بتقييم النموذج لجميع الصور في مجموعة بيانات التدريب training dataset:
import sys
def true_and_predicted_labels(dataset):
labels = np.zeros((dataset.n,2))
preds = np.zeros_like(labels)
for i in range(len(dataset)):
sys.stdout.write('evaluating batch {}\r'.format(i))
sys.stdout.flush()
batch = dataset[i]
batch_images = batch[0]
batch_labels = batch[1]
batch_preds = full_model.predict(batch_images)
start = i*batch_size
labels[start:start+batch_size] = batch_labels
preds[start:start+batch_size] = batch_preds
return labels, preds
train_labels, train_preds = true_and_predicted_labels(train_dataset)
الآن بعد أن أصبح لدينا تنبؤات النموذج، يمكننا توضيح كيف يمكن للنموذج فصل الفئتين. لهذا، سننظر فقط في درجة القط، مع تذكر أن درجة الكلب تساوي واحدًا مطروحًا منه درجة القط. وسنقوم برسم نقاط القط للفئتين. بالنسبة للقطط، نتوقع أن تكون درجة القط قريبة من واحدة. بالنسبة للكلاب، ستكون قريبة من الصفر.
def plot_cat_score(preds, labels, range=(0,1)):
# get the cat score for all images
cat_score = preds[:,1]
# get the cat score for dogs
# we use the true labels to select dog images
dog_cat_score = cat_score[labels[:,0]>0.5]
# and for cats
cat_cat_score = cat_score[labels[:,0]<0.5]
# just some plotting parameters
params = {'bins':100, 'range':range, 'alpha':0.6}
plt.hist(dog_cat_score, **params)
plt.hist(cat_cat_score, **params)
plt.yscale('log')
plot_cat_score(train_preds, train_labels)
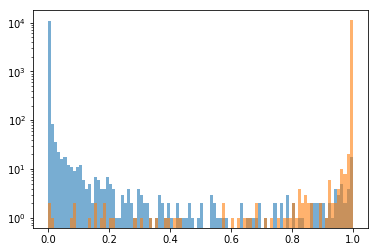
يرجى ملاحظة أنني استخدمت مقياسًا لوغاريتميًا على المحور y. لقد فعلت ذلك لأنه، مع دقة التصنيف الممتازة هذه، انتهى بنا المطاف بمعظم الصور التي تحتوي إما على درجة قريبة جدًا من 1 (قطط واضحة)، أو قريبة جدًا من 0 (كلاب شفافة)، مثل المثال الذي رسمناه أعلاه. سنرى هذه فقط في مقياس خطي. في المنتصف نرى الحالات الأكثر صعوبة وإثارة للاهتمام.
يمكننا الآن حساب الدقة.
لهذا نحتاج إلى حساب التسميات المتوقعة ومقارنتها بالتسميات الحقيقية. لحساب التسميات المتوقعة، نأخذ درجة القط، ونقرر أن الشبكة تتوقع قطة إذا كانت هذه الدرجة أكبر من عتبة threshold معينة.
يوفر Keras تقديرًا للدقة أثناء التدريب. بالنسبة لهذا التقدير، تستخدم keras عتبة 0.5، لذلك دعونا نفعل ذلك أيضًا:
threshold = 0.5
def predicted_labels(preds, threshold):
'''Turn predictions (floats in the last two dimensions)
into labels (0 or 1).'''
pred_labels = np.zeros_like(preds)
# cat score lower than threshold: set dog label to 1
# cat score higher than threshold: set dog label to 0
pred_labels[:,0] = preds[:,1]<threshold
# cat score higher than threshold: set cat label to 1
# cat score lower than threshold: set cat label to 0
pred_labels[:,1] = preds[:,1]>=threshold
return pred_labels
train_pred_labels = predicted_labels(train_preds, threshold)
print('predicted labels:')
print(train_pred_labels)
print('true labels:')
print(train_labels)

نرى أن التسميات المتوقعة تبدو مشابهة جدًا للتسميات الحقيقية. هذا لأن الدقة قريبة من 100٪، وهناك أمثلة قليلة فقط معروضة في النسخة المطبوعة أعلاه. دعنا نحدد جزء الأمثلة المصنفة بشكل خاطئ:
def misclassified(labels, pred_labels, print_report=True):
def report(categ, n_misclassified, n_examples):
print('{:<4} {:>3} misclassified samples ({:4.2f}%)'.format(
categ,
n_misclassified,
100*(1-float(n_misclassified)/n_examples))
)
# total number of examples
n_examples = len(labels)
# total number of cats
n_cats = sum(labels[:,0])
# total number of dogs
n_dogs = sum(labels[:,1])
# boolean mask for misidentified examples
mask_all = pred_labels[:,0] != labels[:,0]
# boolean mask for misidentified cats
mask_cats = np.logical_and(mask_all,labels[:,1]>0.5)
# boolean mask for misidentified dogs
mask_dogs = np.logical_and(mask_all,labels[:,1]<0.5)
if print_report:
report('all', sum(mask_all), n_examples)
report('cats', sum(mask_cats), n_cats)
report('dogs', sum(mask_dogs), n_dogs)
return mask_all, mask_cats, mask_dogs
_ = misclassified(train_labels, train_pred_labels)

من خلال التدريب، نرى أن تصنيف الكلاب أكثر صعوبة. ومع ذلك، يمكن أن يؤدي كل تدريب إلى نتائج مختلفة. فعلت القليل، وحصلت على أداء تصنيف متماثل مرة واحدة فقط.
الآن، هل هناك سبب لاختيار عتبة عند 0.5 للتصنيف؟ دعنا نرسم نقاط القط مرة أخرى:
plot_cat_score(train_preds, train_labels)

من الواضح، مع عتبة 0.9 أو نحو ذلك، سنقوم فقط بتصنيف عدد قليل من القطط الأخرى، لكننا سنكتسب الكثير من الكلاب. بعد قليل من التحسين، وصلنا إلى تصنيف متماثل بحد أدنى قدره 0.85:
threshold = 0.85
train_pred_labels = predicted_labels(train_preds, threshold)
_ = misclassified(train_labels, train_pred_labels)

من خلال اختيار العتبة هذا، نقوم بتحسين دقة التصنيف العالمي بنسبة 0.02٪. هذا ليس مكسبًا كبيرًا في هذه الحالة، لكن تذكر أنه اعتمادًا على التدريب، قد تحصل على المزيد من التوزيعات غير المتكافئة. يمكنك محاولة إعادة تدريب ResNet50 مرة أخرى للتحقق من ذلك.
لذلك تذكر:
تحقق من درجة التصنيف وقم بضبط العتبة الخاصة بك بشكل صحيح.
الآن، قمنا بتحسين العتبة على مجموعة بيانات التدريب. ما الذي نحصل عليه من مجموعة بيانات التحقق؟
val_labels, val_preds = true_and_predicted_labels(val_dataset)
val_pred_labels = predicted_labels(val_preds, threshold)
_ = misclassified(val_labels, val_pred_labels)

هنا أيضًا، التصنيف متماثل إلى حد ما، ودقة التحقق من الصحة هي 98.6٪. مع عتبة تصنيف عند 0.5، سنحصل على:
val_pred_labels = predicted_labels(val_preds, 0.5)
_ = misclassified(val_labels, val_pred_labels)
النظر إلى الصور المصنفة بشكل خاطئ
توجد مشكلة بسيطة في واجهة ImageDataGenerator: فهي لا تسمح لنا بالعثور على الصور التي تم تصنيفها بشكل خاطئ، حتى نتمكن من تحميلها من القرص والنظر إليها. لذلك نحن بحاجة إلى إعادة تقييم الشبكة مرة أخرى، وتخزين الصور التي تم تحديدها بشكل خاطئ لعرضها لاحقًا.
import sys
dataset = val_dataset
misclassified_imgs = dict(dogs=[], cats=[])
for i in range(len(dataset)):
if i%100:
sys.stdout.write('evaluating batch {}\r'.format(i))
sys.stdout.flush()
batch = dataset[i]
batch_images = batch[0]
batch_labels = batch[1]
batch_preds = full_model.predict(batch_images)
batch_pred_labels = predicted_labels(batch_preds, threshold=0.85)
mask_all, mask_cats, mask_dogs = misclassified(
batch_labels,
batch_pred_labels,
print_report=False
)
misclassified_imgs['dogs'].extend(batch_images[mask_dogs])
misclassified_imgs['cats'].extend(batch_images[mask_cats])

فيما يلي عدد الصور المصنفة بشكل خاطئ في كل فئة:
print([(label, len(imgs)) for label,imgs in misclassified_imgs.items()])

لقد لاحظت بالتأكيد أن هذه الأرقام لا تتوافق تمامًا مع الأرقام التي رأيناها أعلاه (17 قطط مصنفة بشكل خاطئ و18 كلبًا تم تصنيفها بشكل خاطئ). أعتقد أن هذا قد يكون بسبب قدر من العشوائية في تقييم الشبكة، أو إلى الدقة العددية، وليس لدي أي فكرة من أين يأتي هذا.
لنكتب الآن دالة صغيرة لرسم مجموعة من الصور، حتى نتمكن من إلقاء نظرة على الصور المصنفة بشكل خاطئ:
def plot_images(imgs, i):
ncols, nrows = (5, 2)
start = i*ncols*nrows
fig = plt.figure( figsize=(ncols*5, nrows*5), dpi=50)
for i, img in enumerate(imgs[start:start+ncols*nrows]):
plt.subplot(nrows, ncols, i+1)
plt.imshow(img)
plt.axis('off')

واو ما هذا؟؟ الألوان فاسدة تمامًا …
ويرجع ذلك إلى المعالجة المسبقة للصورة التي يقوم بها مكرر مجموعة البيانات. تذكر أننا نستخدم ResNet50 وقد طلبنا معالجة صورنا مسبقًا باستخدام keras.applications.resnet50.preprocess_input. هل لدينا طريقة للتراجع عن هذه العملية؟ لذلك نحتاج أولاً إلى إيجاد هذه الدالة لفهم ما تفعله.
نبدأ بالتحقق من إصدارنا من keras_applications:
import keras_applications
keras_applications.__version__

ثم ننظر إلى الكود المصدري لـ resnet50 ونرى أن هذه الدالة مأخوذة من imagenet_utils، حيث تم تعريفها هنا.
نحن ندعو الدالة دون أي حجة بصرف النظر عن الصورة إلى المعالجة المسبقة. لذلك نحن في وضع “caffe”. أيضًا، نوفر مصفوفة numpy للدالة، لذلك نحن في الواقع نستدعي _preprocess_numpy_input ، هنا.
في وضع caffe ، تقوم الدالة بما يلي:
- قم بالتبديل من تمثيل ألوان RGB إلى BGR.
- اطرح متوسط قيم BGR المحسوبة لمجموعة بيانات ImageNet بأكملها لتوسيط قيم BGR على 0.
يمكننا بسهولة كتابة دالة للتراجع عن هذه العملية:
def undo_preprocessing(x):
mean = [103.939, 116.779, 123.68]
x[..., 0] += mean[0]
x[..., 1] += mean[1]
x[..., 2] += mean[2]
x = x[..., ::-1]
تضيف دالتنا أولاً متوسط قيم BGR مرة أخرى، نظرًا لأن هذه كانت آخر عملية للمعالجة المسبقة. ثم نعيد ترتيب مستويات اللون مرة أخرى. ما قد لا يكون واضحًا بالنسبة لك هو السطر الأخير، الذي يعيد ترتيب مستويات اللون. لذلك دعونا نلقي نظرة في التفاصيل.
- التدوين notation … يعني: إضافة العديد من الأبعاد حسب الضرورة. لذلك نترك الأبعاد الأولى للصور كما هي، للعمل فقط على البعد الأخير، أحد مستويات اللون (يرجى ملاحظة أنني أستخدم keras في الوضع الأخير للقنوات).
- يعمل التدوين ::-1على البعد الأخير ، ويعيد ترتيب الأرقام هناك.
لنأخذ مثال بسيط. نبني مصفوفة بالشكل (2،2،3). يمكنك التفكير في الأمر كصورة 2 × 2 بكسل و3 مستويات لونية:
a = np.arange(12).reshape(2,2,3)
print(a)
في الجزء العلوي الأيسر من البكسل، يتم تعيين مستويات الألوان الثلاثة على [0 1 2]على التوالي، وفي الجزء السفلي الأيمن من البكسل على [9 10 11]يمكننا أن نرى أن عملية الإرجاع لها التأثير المتوقع:
a[...,::-1]

لنجرب الآن دالة غير المعالجة الخاصة بنا على صورة واحدة:
img = misclassified_imgs['cats'][5]
plt.imshow(img)
import copy
new_img = copy.copy(img)
undo_preprocessing(new_img)
plt.imshow(new_img.astype('int'))

أفضل بكثير! يبدو أن الدالة تعمل كما هو متوقع. لذلك نقوم بتعديل دالة الرسم لدينا لرسم صور غير معالجة:
def plot_images(imgs, i):
ncols, nrows = (5, 2)
start = i*ncols*nrows
fig = plt.figure( figsize=(ncols*5, nrows*5), dpi=50)
for i, img in enumerate(imgs[start:start+ncols*nrows]):
img_unproc = copy.copy(img)
undo_preprocessing(img_unproc)
plt.subplot(nrows, ncols, i+1)
plt.imshow(img_unproc.astype('int'))
plt.axis('off')
plot_images(misclassified_imgs['dogs'],0)

في الواقع، لا تزال الألوان تبدو مضحكة بعض الشيء … لا أعرف حقًا لماذا وأكون مصابًا بعمى الألوان، لست متأكدًا تمامًا! على أي حال، يمكننا على الأقل فهم الصور الآن.
يمكننا محاولة تخمين سبب سوء تصنيف هذه الصور. يمكن أن يكون الناس هم الذين يحملون القطط في كثير من الأحيان، مما قد يؤدي إلى تحيز الشبكة نحو إساءة تصنيف الكلاب عندما يكون الناس في الصورة. أيضًا، ربما لا يساعد الاتجاه الخاطئ لصورة واحدة. بعد ذلك، غالبًا ما تنام القطط على ظهورها، في حين أن هذا الوضع ليس شائعًا للكلاب. أخيرًا، الجراء بالتأكيد أكثر صعوبة.
الخلاصة
في هذا المنشور، تعلمت ما هو نقل التعلم وكيفية:
- استخدم نماذج VGG16 وVGG19 وResNet50 المدربة مسبقًا في keras للوصول إلى دقة 98.5٪ في تصنيف الكلاب مقابل القطط.
- إضافة طبقات إلى نموذج موجود لتكييفه مع احتياجاتك.
- احفظ نموذج keras بحيث يمكنك إعادة استخدامه لاحقًا، دون الحاجة إلى إعادة التدريب.
- قم بإنشاء أدواتك الخاصة لتقييم أداء النموذج وإلقاء نظرة على الصور التي تم التعرف عليها بشكل خاطئ، باستخدام python و numpy.
ماذا الان؟
يمكن للشبكات العصبية العميقة المدربة على مجموعة بيانات ImageNet الكبيرة رؤيتها! ويمكننا استخدامها لتصنيف الصور في فئات مختلفة، وباستخدام مجموعة بيانات أصغر.
لنفترض أن لديك مجموعة الصور الخاصة بك التي ترغب في تصنيفها. ربما تريد التعرف على الفطر؟ أم حشرات؟ أو معرفة ما إذا كانت الصورة الطبية مشبوهة؟ من المحتمل أن يكون نقل التعلم هو السبيل للذهاب.
بعد ذلك، سننشئ مجموعة بيانات من البداية من خلال جمع الصور على الإنترنت. باستخدام مجموعة البيانات هذه، سنتمكن من اختبار مهارات التعلم الخاصة بنا على فئات مختلفة ولكنها غير معروفة. بعد كل شيء، مميزات ImageNet للكلاب والقطط).
وسوف ندرس أيضًا نقل التعلم في سياق معالجة اللغة الطبيعية.

