
- تحميل البيانات الخاصة بالتعرف على الكيان المحدد (NER)
- تحضير البيانات للشبكات العصبية
- تدريب الشبكة العصبية للتعرف على الكيانات المسماة (NER)
- اختبار نموذج التعرف على الكيان المسماة (NER):
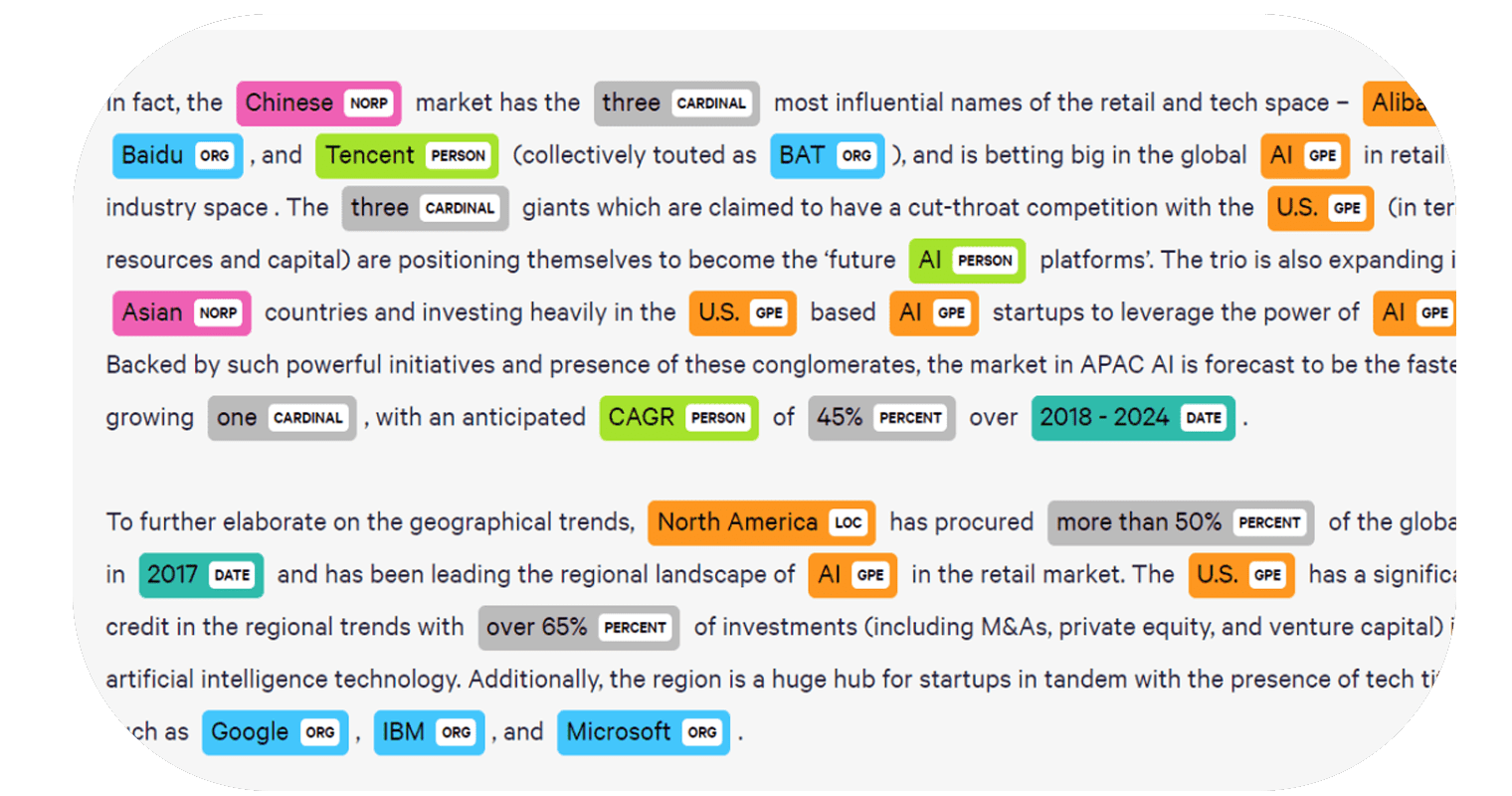
الكيان المسمى Named Entity يعني أي شيء يمثل كائنًا حقيقيًا مثل شخص أو مكان أو أي منظمة أو أي منتج له اسم. على سبيل المثال – “اسمي أمان وأنا مدرب تعلم الآلة”. في هذه الجملة، يُطلق على اسم “أمان” والحقل أو الموضوع “التعلم الآلي” والمهنة “المدرب” كيانات.
في التعرف على الكيانات المسماة (NER) في التعلم الآلي، يعد التعرف على الكيانات المسماة (NER) مهمة معالجة اللغة الطبيعية لتحديد الكيانات المسماة في جزء معين من النص.
هل سبق لك استخدام برنامج يعرف باسم Grammarly؟ يحدد جميع التهجئات وعلامات الترقيم غير الصحيحة في النص ويصححها. لكنها لا تفعل شيئًا مع الكيانات المسماة، لأنها تستخدم نفس التقنية أيضًا. في هذه المقالة، سوف آخذك خلال مهمة التعرف على الكيانات المسماة (NER) باستخدام التعلم الآلي.
تحميل البيانات الخاصة بالتعرف على الكيان المحدد (NER)
يمكن تنزيل مجموعة البيانات التي سأستخدمها لهذه المهمة بسهولة من هنا. الآن أول شيء سأفعله هو تحميل البيانات وإلقاء نظرة عليها لمعرفة ما أعمل به. لذلك دعونا نستورد مكتبة pandas وتحميل البيانات:
from google.colab import files
uploaded = files.upload()
import pandas as pd
data = pd.read_csv('ner_dataset.csv', encoding= 'unicode_escape')
data.head()
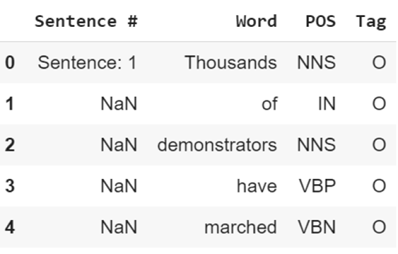
في البيانات، يمكننا أن نرى أن الكلمات مقسمة إلى أعمدة تمثل ميزتنا X، وسيمثل عمود العلامة في اليمين التسمية Y.
تحضير البيانات للشبكات العصبية
سأقوم بتدريب شبكة عصبية على مهمة التعرف على الكيان المحدد (NER). لذلك نحن بحاجة إلى إجراء بعض التعديلات على البيانات لإعدادها بهذه الطريقة بحيث يمكن أن تتناسب بسهولة مع شبكة محايدة. سأبدأ هذه الخطوة باستخراج التعيينات المطلوبة لتدريب الشبكة العصبية:
from itertools import chain
def get_dict_map(data, token_or_tag):
tok2idx = {}
idx2tok = {}
if token_or_tag == 'token':
vocab = list(set(data['Word'].to_list()))
else:
vocab = list(set(data['Tag'].to_list()))
idx2tok = {idx:tok for idx, tok in enumerate(vocab)}
tok2idx = {tok:idx for idx, tok in enumerate(vocab)}
return tok2idx, idx2tok
token2idx, idx2token = get_dict_map(data, 'token')
tag2idx, idx2tag = get_dict_map(data, 'tag')
سأقوم الآن بتحويل الأعمدة في البيانات لاستخراج البيانات المتسلسلة لشبكتنا العصبية:
data['Word_idx'] = data['Word'].map(token2idx)
data['Tag_idx'] = data['Tag'].map(tag2idx)
data_fillna = data.fillna(method='ffill', axis=0)
# Groupby and collect columns
data_group = data_fillna.groupby(
['Sentence #'],as_index=False
)['Word', 'POS', 'Tag', 'Word_idx', 'Tag_idx'].agg(lambda x: list(x))
الآن سأقسم البيانات إلى مجموعات تدريب واختبار. سأقوم بإنشاء دالة لتقسيم البيانات لأن طبقات LSTM تقبل تسلسلات من نفس الطول فقط. لذلك يجب أن تكون كل جملة تظهر على هيئة عدد صحيح في البيانات مبطن بنفس الطول:
from sklearn.model_selection import train_test_split
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
def get_pad_train_test_val(data_group, data):
#get max token and tag length
n_token = len(list(set(data['Word'].to_list())))
n_tag = len(list(set(data['Tag'].to_list())))
#Pad tokens (X var)
tokens = data_group['Word_idx'].tolist()
maxlen = max([len(s) for s in tokens])
pad_tokens = pad_sequences(tokens, maxlen=maxlen, dtype='int32', padding='post', value= n_token - 1)
#Pad Tags (y var) and convert it into one hot encoding
tags = data_group['Tag_idx'].tolist()
pad_tags = pad_sequences(tags, maxlen=maxlen, dtype='int32', padding='post', value= tag2idx["O"])
n_tags = len(tag2idx)
pad_tags = [to_categorical(i, num_classes=n_tags) for i in pad_tags]
#Split train, test and validation set
tokens_, test_tokens, tags_, test_tags = train_test_split(pad_tokens, pad_tags, test_size=0.1, train_size=0.9, random_state=2020)
train_tokens, val_tokens, train_tags, val_tags = train_test_split(tokens_,tags_,test_size = 0.25,train_size =0.75, random_state=2020)
print(
'train_tokens length:', len(train_tokens),
'\ntrain_tokens length:', len(train_tokens),
'\ntest_tokens length:', len(test_tokens),
'\ntest_tags:', len(test_tags),
'\nval_tokens:', len(val_tokens),
'\nval_tags:', len(val_tags),
)
return train_tokens, val_tokens, test_tokens, train_tags, val_tags, test_tags
train_tokens, val_tokens, test_tokens, train_tags, val_tags, test_tags = get_pad_train_test_val(data_group, data)
train_tokens length: 32372
train_tokens length: 32372
test_tokens length: 4796
test_tags: 4796
val_tokens: 10791 val_tags: 10791
تدريب الشبكة العصبية للتعرف على الكيانات المسماة (NER)
الآن، سأشرع في تدريب بُنية الشبكة العصبية لنموذجنا. فلنبدأ باستيراد جميع الحزم التي نحتاجها لتدريب شبكتنا العصبية:
import numpy as np
import tensorflow
from tensorflow.keras import Sequential, Model, Input
from tensorflow.keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.utils import plot_model
from numpy.random import seed
seed(1)
tensorflow.random.set_seed(2)
ستأخذ الطبقة أدناه الأبعاد من طبقة LSTM وستعطي الحد الأقصى للطول والحد الأقصى للعلامات كإخراج:
input_dim = len(list(set(data['Word'].to_list())))+1
output_dim = 64
input_length = max([len(s) for s in data_group['Word_idx'].tolist()])
n_tags = len(tag2idx)
الآن سوف أقوم بإنشاء دالة مساعدة والتي ستساعدنا في إعطاء ملخص لكل طبقة من نموذج الشبكة العصبية للتعرف على الكيانات المسماة (NER):
def get_bilstm_lstm_model():
model = Sequential()
# Add Embedding layer
model.add(Embedding(input_dim=input_dim, output_dim=output_dim, input_length=input_length))
# Add bidirectional LSTM
model.add(Bidirectional(LSTM(units=output_dim, return_sequences=True, dropout=0.2, recurrent_dropout=0.2), merge_mode = 'concat'))
# Add LSTM
model.add(LSTM(units=output_dim, return_sequences=True, dropout=0.5, recurrent_dropout=0.5))
# Add timeDistributed Layer
model.add(TimeDistributed(Dense(n_tags, activation="relu")))
#Optimiser
# adam = k.optimizers.Adam(lr=0.0005, beta_1=0.9, beta_2=0.999)
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
سأقوم الآن بإنشاء دالة مساعدة لتدريب نموذج التعرف على الكيان المحدد:
def train_model(X, y, model):
loss = list()
for i in range(25):
# fit model for one epoch on this sequence
hist = model.fit(X, y, batch_size=1000, verbose=1, epochs=1, validation_split=0.2)
loss.append(hist.history['loss'][0])
return loss
سيعطي النموذج الناتج النهائي بعد تشغيله لمدة 25 حقبة. لذلك سوف يستغرق الأمر بعض الوقت للتشغيل.
اختبار نموذج التعرف على الكيان المسماة (NER):
الآن دعنا نختبر نموذجنا على جزء من النص:
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
text = nlp('Hi, My name is Aman Kharwal \n I am from India \n I want to work with Google \n Steve Jobs is My Inspiration')
displacy.render(text, style = 'ent', jupyter=True)
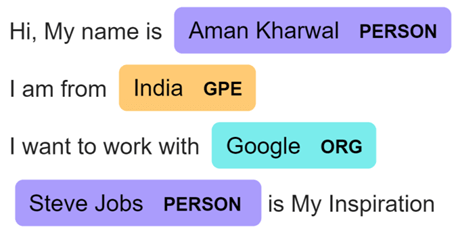
يمكننا أن نرى نتيجة جيدة جدًا من نموذجنا. آمل أن تكون قد أحببت هذه المقالة حول التعرف على الكيانات المسماة (NER) باستخدام التعلم الآلي.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.