
- ما هو اكتشاف المعالم؟
- اكتشاف معالم كوكل مع التعلم العميق
- تدريب النموذج
هل سبق لك أن نظرت في صور عطلتك وتساءلت: ما اسم هذا المعبد الذي زرته في الهند؟ من أنشأ هذا النصب الذي رأيته في كاليفورنيا؟ يمكن أن يساعدنا اكتشاف المعالم Landmark Detection في اكتشاف أسماء هذه الأماكن. لكن كيف يعمل الكشف عن المعالم؟ في هذه المقالة، سأقدم لك مشروع التعلم الآلي حول اكتشاف المعالم باستخدام بايثون.
ما هو اكتشاف المعالم؟
اكتشاف المعالم هي مهمة الكشف عن التماثيل والهياكل والمعالم الأثرية التي صنعها الإنسان داخل الصورة. لدينا بالفعل تطبيق مشهور جدًا لمثل هذه المهام والذي يُعرف عمومًا باسم Google Landmark Detection، والذي تستخدمه خرائط Google.
في نهاية هذه المقالة، ستتعرف على كيفية عمل اكتشاف معالم Google حيث سأأخذك عبر مشروع التعلم الآلي الذي يعتمد على دالة Google Landmark Detection. سأستخدم لغة برمجة بايثون لبناء شبكات عصبية لاكتشاف المعالم داخل الصور.
لنبدأ الآن في مهمة اكتشاف المعالم داخل الصورة. تتمثل أصعب مهمة في هذا المشروع في العثور على مجموعة بيانات تتضمن بعض الصور التي يمكننا استخدامها لتدريب شبكتنا العصبية.
نأمل، بعد الكثير من البحث، أن أكون قد صادفت مجموعة بيانات مقدمة من Google في مسابقات Kaggle. يمكنك تنزيل مجموعة البيانات التي سأستخدمها لاكتشاف المعالم باستخدام التعلم الآلي من هنا.
اكتشاف معالم كوكل مع التعلم العميق
الآن لبدء هذه المهمة، سأستورد جميع مكتبات بايثون الضرورية التي نحتاجها لإنشاء نموذج تعلم آلي لمهمة اكتشاف المعالم:
import numpy as np
import pandas as pd
import keras
import cv2
from matplotlib import pyplot as plt
import os
import random
from PIL import Image
لذلك بعد استيراد المكتبات المذكورة أعلاه، فإن الخطوة التالية في هذه المهمة هي استيراد مجموعة البيانات التي سأستخدمها لاكتشاف المعالم بالصور:
samples = 20000
df = pd.read_csv("train.csv")
df = df.loc[:samples,:]
num_classes = len(df["landmark_id"].unique())
num_data = len(df)
الآن دعونا نلقي نظرة على حجم بيانات التدريب وعدد الفئات الفريدة في بيانات التدريب:
print("Size of training data:", df.shape)
print("Number of unique classes:", num_classes)
Size of training data: (20001, 2)
Number of unique classes: 1020
هناك 20،001 عينة تدريب، تنتمي إلى 1020 فئةً، مما يعطينا متوسط 19.6 صورة لكل فئة، ومع ذلك، قد لا يكون هذا التوزيع هو الحال، لذلك دعونا نلقي نظرة على توزيع العينات حسب الفئة:
data = pd.DataFrame(df['landmark_id'].value_counts())
#index the data frame
data.reset_index(inplace=True)
data.columns=['landmark_id','count']
print(data.head(10))
print(data.tail(10))
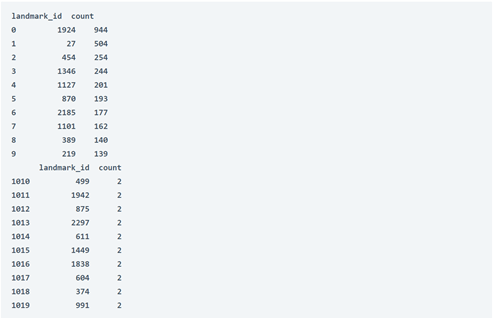
كما نرى، تتراوح المعالم العشرة الأكثر شيوعًا من 139 نقطة بيانات إلى 944 نقطة بيانات بينما تحتوي العشر الأخيرة جميعها على نقطتي بيانات.
print(data['count'].describe())#statistical data for the distribution
plt.hist(data['count'],100,range = (0,944),label = 'test')#Histogram of the distribution
plt.xlabel("Amount of images")
plt.ylabel("Occurences")

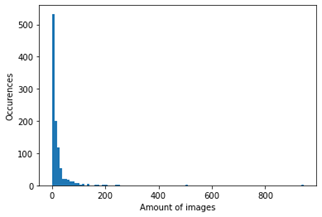
كما نرى في الرسم البياني أعلاه، فإن الغالبية العظمى من الفئات غير مرتبطة بالعديد من الصور.
print("Amount of classes with five and less datapoints:", (data['count'].between(0,5)).sum())
print("Amount of classes with with between five and 10 datapoints:", (data['count'].between(5,10)).sum())
n = plt.hist(df["landmark_id"],bins=df["landmark_id"].unique())
freq_info = n[0]
plt.xlim(0,data['landmark_id'].max())
plt.ylim(0,data['count'].max())
plt.xlabel('Landmark ID')
plt.ylabel('Number of images')
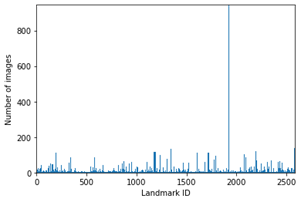
يوضح الرسم البياني أعلاه أن أكثر من 50٪ من فئات 1020 تحتوي على أقل من 10 صور، وهو ما قد يكون صعبًا عند تدريب المصنف.
هناك بعض “القيم المتطرفة outliers” من حيث عدد الصور لديهم، مما يعني أننا قد نكون منحازين تجاه هؤلاء، حيث قد تكون هناك فرصة أكبر للحصول على “تخمين guess” صحيح بأكبر قدر في هذه الفئات.
تدريب النموذج
الآن، سأقوم بتدريب نموذج التعلم الآلي على مهمة الكشف عن المعالم باستخدام لغة برمجة بايثون التي ستعمل بنفس نموذج اكتشاف معالم Google.
from sklearn.preprocessing import LabelEncoder
lencoder = LabelEncoder()
lencoder.fit(df["landmark_id"])
def encode_label(lbl):
return lencoder.transform(lbl)
def decode_label(lbl):
return lencoder.inverse_transform(lbl)
def get_image_from_number(num):
fname, label = df.loc[num,:]
fname = fname + ".jpg"
f1 = fname[0]
f2 = fname[1]
f3 = fname[2]
path = os.path.join(f1,f2,f3,fname)
im = cv2.imread(os.path.join(base_path,path))
return im, label
print("4 sample images from random classes:")
fig=plt.figure(figsize=(16, 16))
for i in range(1,5):
a = random.choices(os.listdir(base_path), k=3)
folder = base_path+'/'+a[0]+'/'+a[1]+'/'+a[2]
random_img = random.choice(os.listdir(folder))
img = np.array(Image.open(folder+'/'+random_img))
fig.add_subplot(1, 4, i)
plt.imshow(img)
plt.axis('off')
plt.show()

from keras.applications import VGG19
from keras.layers import *
from keras import Sequential
### Parameters
# learning_rate = 0.0001
# decay_speed = 1e-6
# momentum = 0.09
# loss_function = "sparse_categorical_crossentropy"
source_model = VGG19(weights=None)
#new_layer = Dense(num_classes, activation=activations.softmax, name='prediction')
drop_layer = Dropout(0.5)
drop_layer2 = Dropout(0.5)
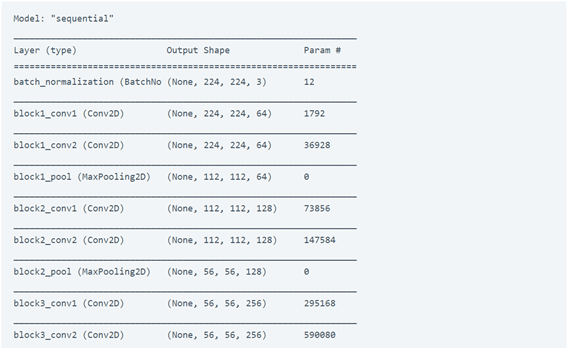
model = Sequential()
for layer in source_model.layers[:-1]: # go through until last layer
if layer == source_model.layers[-25]:
model.add(BatchNormalization())
model.add(layer)
# if layer == source_model.layers[-3]:
# model.add(drop_layer)
# model.add(drop_layer2)
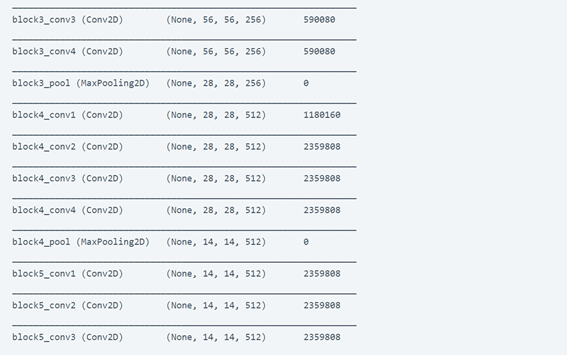
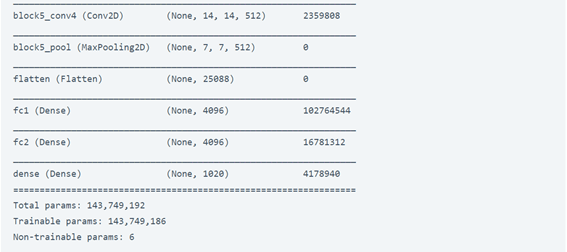
model.add(Dense(num_classes, activation="softmax"))
model.summary()
opt1 = keras.optimizers.RMSprop(learning_rate = 0.0001, momentum = 0.09)
opt2 = keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07)
model.compile(optimizer=opt1,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
#sgd = SGD(lr=learning_rate, decay=decay_speed, momentum=momentum, nesterov=True)
# rms = keras.optimizers.RMSprop(lr=learning_rate, momentum=momentum)
# model.compile(optimizer=rms,
# loss=loss_function,
# metrics=["accuracy"])
# print("Model compiled! \n")
### Function used for processing the data, fitted into a data generator.
def get_image_from_number(num, df):
fname, label = df.iloc[num,:]
fname = fname + ".jpg"
f1 = fname[0]
f2 = fname[1]
f3 = fname[2]
path = os.path.join(f1,f2,f3,fname)
im = cv2.imread(os.path.join(base_path,path))
return im, label
def image_reshape(im, target_size):
return cv2.resize(im, target_size)
def get_batch(dataframe,start, batch_size):
image_array = []
label_array = []
end_img = start+batch_size
if end_img > len(dataframe):
end_img = len(dataframe)
for idx in range(start, end_img):
n = idx
im, label = get_image_from_number(n, dataframe)
im = image_reshape(im, (224, 224)) / 255.0
image_array.append(im)
label_array.append(label)
label_array = encode_label(label_array)
return np.array(image_array), np.array(label_array)
batch_size = 16
epoch_shuffle = True
weight_classes = True
epochs = 15
# Split train data up into 80% and 20% validation
train, validate = np.split(df.sample(frac=1), [int(.8*len(df))])
print("Training on:", len(train), "samples")
print("Validation on:", len(validate), "samples")
for e in range(epochs):
print("Epoch: ", str(e+1) + "/" + str(epochs))
if epoch_shuffle:
train = train.sample(frac = 1)
for it in range(int(np.ceil(len(train)/batch_size))):
X_train, y_train = get_batch(train, it*batch_size, batch_size)
model.train_on_batch(X_train, y_train)
model.save("Model.h5")
الآن قمنا بتدريب النموذج بنجاح. الخطوة التالية هي اختبار النموذج، دعنا نرى كيف يمكننا اختبار نموذج اكتشاف المعالم لدينا:
### Test on training set
batch_size = 16
errors = 0
good_preds = []
bad_preds = []
for it in range(int(np.ceil(len(validate)/batch_size))):
X_train, y_train = get_batch(validate, it*batch_size, batch_size)
result = model.predict(X_train)
cla = np.argmax(result, axis=1)
for idx, res in enumerate(result):
print("Class:", cla[idx], "- Confidence:", np.round(res[cla[idx]],2), "- GT:", y_train[idx])
if cla[idx] != y_train[idx]:
errors = errors + 1
bad_preds.append([batch_size*it + idx, cla[idx], res[cla[idx]]])
else:
good_preds.append([batch_size*it + idx, cla[idx], res[cla[idx]]])
print("Errors: ", errors, "Acc:", np.round(100*(len(validate)-errors)/len(validate),2))
#Good predictions
good_preds = np.array(good_preds)
good_preds = np.array(sorted(good_preds, key = lambda x: x[2], reverse=True))
fig=plt.figure(figsize=(16, 16))
for i in range(1,6):
n = int(good_preds[i,0])
img, lbl = get_image_from_number(n, validate)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
fig.add_subplot(1, 5, i)
plt.imshow(img)
lbl2 = np.array(int(good_preds[i,1])).reshape(1,1)
sample_cnt = list(df.landmark_id).count(lbl)
plt.title("Label: " + str(lbl) + "\nClassified as: " + str(decode_label(lbl2)) + "\nSamples in class " + str(lbl) + ": " + str(sample_cnt))
plt.axis('off')
plt.show()
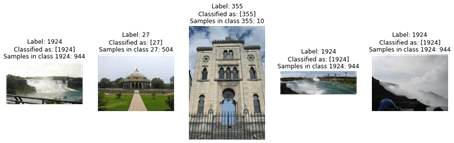
كما ترى في الصور أعلاه في المخرجات، فقد تم تصنيفها حسب تسمياتها وفئاتها. آمل أن تكون قد أحببت هذه المقالة حول مشروع التعلم الآلي على Google Landmark Detection باستخدام لغة برمجة بايثون.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.