
- ما المقصود بالضبط الزائد والضبط الناقص في التعلم الآلي؟
- الضبط الزائد overfitting
- الضبط الناقص underfitting
- التعامل مع الضبط الزائد والضبط الناقص
- دراسة حالة
بنهاية هذه المقالة، ستفهم مفاهيم الضبط الزائد overfitting والضبط الناقص underfitting في التعلم الآلي، ويمكنك أيضًا تطبيق هذه المفاهيم لتدريب نماذج التعلم الآلي الخاصة بك بشكل أكثر دقة.
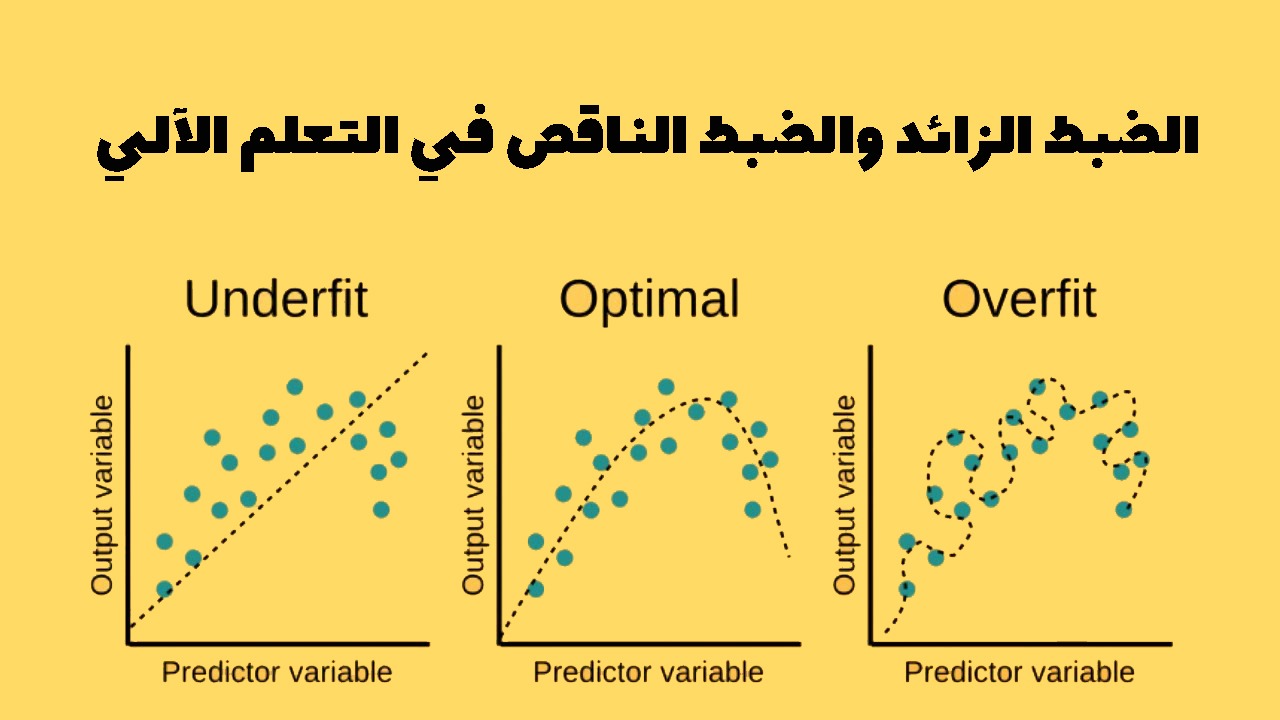
ما المقصود بالضبط الزائد والضبط الناقص في التعلم الآلي؟
الضبط الزائد overfitting:
لنفترض أنك تزور بلدًا أجنبيًا ويخدعك سائق التاكسي. قد تميل إلى القول إن جميع سائقي سيارات الأجرة في هذا البلد هم لصوص. الضبط الزائد هو شيء نفعله نحن البشر كثيرًا، ولسوء الحظ، يمكن للآلات أن تقع في نفس الفخ إذا لم نتوخ الحذر. في التعلم الآلي، هذا يسمى overfitting: هذا يعني أن النموذج يعمل بشكل جيد على بيانات التدريب، لكنه لا يعمم بشكل جيد.
يحدث الضبط الزائد عندما يكون النموذج معقدًا جدًا لمقدار وضوضاء بيانات التدريب. فيما يلي الحلول الممكنة:
- قم بتبسيط النموذج عن طريق اختيار نموذج بمعلمات parameters أقل (على سبيل المثال، نموذج خطي بدلاً من نموذج متعدد الحدود بدرجة عالية)، أو تقليل عدد السمات في بيانات التدريب، أو تقييد النموذج.
- جمع المزيد من بيانات التدريب.
- تقليل الضوضاء في بيانات التدريب (على سبيل المثال، تصحيح أخطاء البيانات وإزالة القيم المتطرفة outliers).
الضبط الناقص underfitting:
كما يمكنك أن تتخيل، فإن الضبط الناقص هو عكس الضبط الزائد: يحدث عندما يكون نموذجك بسيطًا جدًا لتعلم البنية الأساسية للبيانات.
فيما يلي الخيارات الرئيسية لحل مشكلة الضبط الناقص:
- حدد نموذجًا أكثر قوة، مع مزيد من المعلمات.
- جلب ميزات أفضل إلى خوارزمية التعلم (هندسة الميزات feature engineering).
- قم بتقليل القيود على النموذج (على سبيل المثال، تقليل تنظيم المعاملات الفائقة regularization hyperparameter).
أثناء تدريب نموذج التعلم الآلي، نهتم أكثر بشأن دقة أداء نموذجنا المُدرب على البيانات الجديدة، والتي يمكننا تقديرها من مجموعة التحقق من الصحة validation set، والفكرة هي تحقيق توازن بين الضبط الزائد والضبط الناقص.
التعامل مع الضبط الزائد والضبط الناقص
سأفكر في دراسة حالة لأخذك إلى كيفية التعامل عمليًا مع الضبط الزائد والضبط الناقص مع التعلم الآلي.
دراسة حالة:
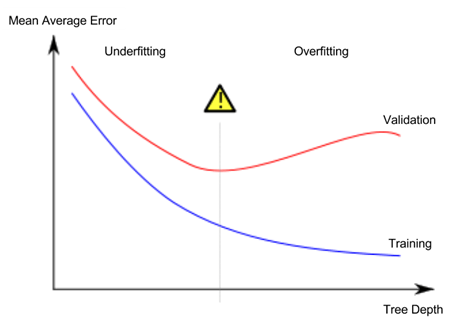
هناك عدد أقل من البدائل للتحكم في عمق الشجرة، والعديد منها يسمح بطرق معينة عبر الشجرة بأن يكون لها عمق أكبر من الطرق الأخرى. لكن الوسيطة max_leaf_nodes توفر طريقة جيدة جدًا للتحكم في الضبط الزائد مقابل الضبط الناقص. كلما سمحت للنموذج بعمل تنبؤات، كلما انتقلت من منطقة الضبط الناقص في الرسم البياني أعلاه إلى منطقة الضبط الزائد.
دعنا الآن نرى كيف يمكننا حل هذه المشكلة المتمثلة في الضبط الزائد والتناسب مع كود التعلم الآلي. سأستخدم دالة مساعدة للمساعدة في مقارنة نتائج MAE للقيم المختلفة لـ max_leaf_nodes:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
يمكن تنزيل مجموعة البيانات التي أستخدمها هنا بسهولة من هنا. الآن سأقوم بتحميل البيانات في train_X و val_X و train_y و val_y:
import pandas as pd
# Load data
melbourne_data = pd.read_csv("melb_data")
# Filter rows with missing values
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
يمكننا الآن استخدام حلقة for لمقارنة precision أو accuracy للنماذج المبنية بقيم مختلفة لـ max_leaf_nodes:
# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))

آمل أن تكون قد أحببت هذه المقالة حول مفاهيم الضبط الزائد والضبط الناقص مع التعلم الآلي.



