

- تحليل المشاعر ومجموعة البيانات
- تحليل المشاعر: استخدام الشبكات العصبية المتكررة
- تحليل المشاعر: استخدام الشبكات العصبية التلافيفية
- الاستنباط اللغوي الطبيعي ومجموعة البيانات
- الاستدلال اللغوي الطبيعي: استخدام الانتباه
- الضبط الدقيق لـ BERT لتطبيقات مستوى التسلسل ومستوى الرمز
- استدلال اللغة الطبيعية: الضبط الدقيق لـ BERT
لقد رأينا كيفية تمثيل الرموز في تسلسلات نصية وتدريب تمثيلاتها في القسم 15. يمكن تغذية تمثيلات النص المدربة مسبقًا لنماذج مختلفة لمهام المعالجة اللغوية الطبيعية المختلفة.
في الواقع، لقد ناقشت الفصول السابقة بالفعل بعض تطبيقات المعالجة اللغوية الطبيعية دون الحاجة إلى تدريب مسبق، فقط لشرح هياكل التعلم العميق. على سبيل المثال، في القسم 9، اعتمدنا على RNNs لتصميم نماذج اللغة لإنشاء نص يشبه الرواية. في القسم 10 والقسم 11، قمنا أيضًا بتصميم نماذج تستند إلى RNNs وآليات الانتباه للترجمة الآلية.
ومع ذلك، لا ينوي هذا الكتاب تغطية جميع هذه التطبيقات بطريقة شاملة. بدلاً من ذلك، ينصب تركيزنا على كيفية تطبيق التعلم التمثيلي representation learning (العميق) للغات لمعالجة مشاكل المعالجة اللغوية الطبيعية. بالنظر إلى تمثيلات النص المدربة مسبقًا، سيستكشف هذا الفصل مهمتين شائعتين وتمثيليتين للمعالجة اللغوية الطبيعية: تحليل المشاعر sentiment analysis واستنتاج اللغة الطبيعية natural language inference، والتي تحلل النص الفردي وعلاقات أزواج النص، على التوالي.
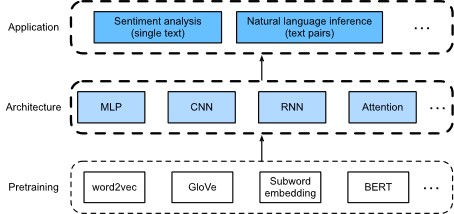
كما هو موضح في الشكل 16.1، يركز هذا الفصل على وصف الأفكار الأساسية لتصميم نماذج المعالجة اللغوية الطبيعية باستخدام أنواع مختلفة من بُنى التعلم العميق، مثل MLPs و CNNs و RNNs والانتباه attention. على الرغم من أنه من الممكن دمج أي تمثيلات نصية سابقة التدريب مع أي معمارية لأي تطبيق في الشكل 16.1، فإننا نختار بعض التوليفات التمثيلية. على وجه التحديد، سوف نستكشف البنى الشعبية القائمة على شبكات RNN وCNN لتحليل المشاعر. لاستدلال اللغة الطبيعية، نختار الانتباه وMLPs لشرح كيفية تحليل أزواج النص. في النهاية، نقدم كيفية ضبط نموذج BERT مسبق التدريب لمجموعة واسعة من تطبيقات المعالجة اللغوية الطبيعية، على سبيل المثال على مستوى التسلسل sequence level (تصنيف النص الفردي وتصنيف أزواج النص) ومستوى الرمز token level (وضع علامات على النص والإجابة على الأسئلة). كحالة تجريبية ملموسة، سنقوم بضبط BERT لاستنتاج اللغة الطبيعية.
كما قدمنا في القسم 15.8، تتطلب BERT تغييرات طفيفة في البُنية لمجموعة واسعة من تطبيقات معالجة اللغة الطبيعية. ومع ذلك، تأتي هذه الميزة على حساب ضبط عدد كبير من معلمات BERT لتطبيقات المصب. عندما تكون المساحة أو الوقت محدودة، فإن تلك النماذج المصممة بناءً على MLPs وCNNs وRNNs والاهتمام تكون أكثر جدوى. فيما يلي، نبدأ بتطبيق تحليل المشاعر ونوضح تصميم النموذج بناءً على شبكات RNN وCNN، على التوالي.
