

تحليل المشاعر على Twitter هو عملية تحديد وتصنيف التغريدات بشكل حسابي في جزء من النص، لا سيما من أجل تحديد ما إذا كان موقف الكاتب تجاه موضوع معين، أو منتج معين، وما إلى ذلك، إيجابيًا أم سلبيًا أم محايدًا.
في هذه المقالة سأقوم بتحليل المشاعر على تويتر باستخدام Natural Language Processing باستخدام مكتبة nltk مع بايثون.
تحليل المشاعر على تويتر
لنبدأ باستيراد المكتبات:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.model_selection import train_test_split # function for splitting data to train and test sets
import nltk
from nltk.corpus import stopwords
from nltk.classify import SklearnClassifier
from wordcloud import WordCloud,STOPWORDS
import matplotlib.pyplot as plt
بادئ ذي بدء، تقسيم مجموعة البيانات إلى مجموعة تدريب واختبار. مجموعة الاختبار هي 10٪ من مجموعة البيانات الأصلية.
بالنسبة لهذا التحليل الخاص، أسقطت التغريدات المحايدة، حيث كان هدفي هو التمييز بين التغريدات الإيجابية والسلبية فقط.
# Splitting the dataset into train and test set
train, test = train_test_split(data,test_size = 0.1)
# Removing neutral sentiments
train=train[train.sentiment!= "Neutral"]
كخطوة تالية، قمت بفصل التغريدات الإيجابية والسلبية لمجموعة التدريب من أجل رسم الكلمات المضمنة بسهولة.
بعد ذلك قمت بتنظيف النص من علامات التصنيف والإشارات والروابط. أصبحوا الآن جاهزين لرسم WordCloud الذي يعرض فقط الكلمات الأكثر تأكيدًا للتغريدات الإيجابية والسلبية.
train_pos = train[ train['sentiment'] == 'Positive']
train_pos = train_pos['text']
train_neg = train[ train['sentiment'] == 'Negative']
train_neg = train_neg['text']
def wordcloud_draw(data, color = 'black'):
words = ' '.join(data)
cleaned_word = " ".join([word for word in words.split()
if 'http' not in word
and not word.startswith('@')
and not word.startswith('#')
and word != 'RT'
])
wordcloud = WordCloud(stopwords=STOPWORDS,
background_color=color,
width=2500,
height=2000
).generate(cleaned_word)
plt.figure(1,figsize=(13, 13))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
print("Positive words")
wordcloud_draw(train_pos,'white')
print("Negative words")
wordcloud_draw(train_neg)
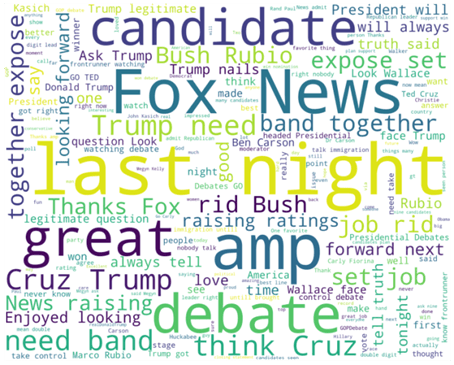
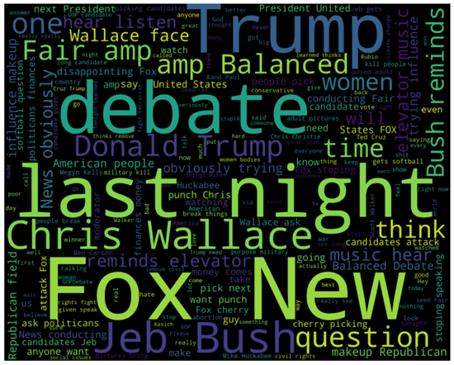
من المثير للاهتمام ملاحظة الكلمات والعبارات التالية في مجموعة الكلمات الإيجابية: truth، strong، legitimate، together، love، job
في تفسيري، يميل الناس إلى الاعتقاد بأن مرشحهم المثالي صادق truthful وشرعي legitimate وفوق الخير والشر.
في الوقت نفسه، تحتوي التغريدات السلبية على كلمات مثل: influence، news، elevatormusic، disappointing، softball، makeup، cherry picking، trying
حسب فهمي، فات الناس التمثيل الحاسم واعتبروا المرشحين الموبخين ضعيفين للغاية ويقطفون الكرز cherry picking.
بعد التحويل إلى رسم البيانات vizualization، قمت بإزالة علامات التوقف stopwords والإشارات والروابط وكلمات الإيقاف من مجموعة التدريب.
: Stop Words هي الكلمات التي لا تحتوي على أهمية مهمة لاستخدامها في استعلامات البحث.
عادةً ما يتم تصفية هذه الكلمات من استعلامات البحث لأنها تُرجع قدرًا هائلاً من المعلومات غير الضرورية. (the، for، this، إلخ.)
tweets =[]
stopwords_set = set(stopwords.words("english"))
for index, row in train.iterrows():
words_filtered = [e.lower() for e in row.text.split() if len(e) >= 3]
words_cleaned = [word for word in words_filtered
if 'http' not in word
and not word.startswith('@')
and not word.startswith('#')
and word != 'RT']
words_without_stopwords = [word for word in words_cleaned if not word in stopwords_set]
tweets.append((words_without_stopwords, row.sentiment))
test_pos = test[ test['sentiment'] == 'Positive']
test_pos = test_pos['text']
test_neg = test[ test['sentiment'] == 'Negative']
test_neg = test_neg['text']
كخطوة تالية، قمت باستخراج الميزات المسماة باستخدام nltk lib، أولاً عن طريق قياس التوزيع المتكرر واختيار المفاتيح الناتجة.
# Extracting word features
def get_words_in_tweets(tweets):
all = []
for (words, sentiment) in tweets:
all.extend(words)
return all
def get_word_features(wordlist):
wordlist = nltk.FreqDist(wordlist)
features = wordlist.keys()
return features
w_features = get_word_features(get_words_in_tweets(tweets))
def extract_features(document):
document_words = set(document)
features = {}
for word in w_features:
features['contains(%s)' % word] = (word in document_words)
return features
بموجب هذا قمت برسم الكلمات الأكثر انتشارًا. تتركز معظم الكلمات حول ليالي المناظرة debate nights.
wordcloud_draw(w_features)
باستخدام nltk NaiveBayes Classifier، قمت بتصنيف ميزات كلمات التغريدة المستخرجة.
# Training the Naive Bayes classifier
training_set = nltk.classify.apply_features(extract_features,tweets)
classifier = nltk.NaiveBayesClassifier.train(training_set)
أخيرًا، باستخدام مقاييس غير ذكية، حاولت قياس كيفية تسجيل خوارزمية المصنف.
neg_cnt = 0
pos_cnt = 0
for obj in test_neg:
res = classifier.classify(extract_features(obj.split()))
if(res == 'Negative'):
neg_cnt = neg_cnt + 1
for obj in test_pos:
res = classifier.classify(extract_features(obj.split()))
if(res == 'Positive'):
pos_cnt = pos_cnt + 1
print('[Negative]: %s/%s ' % (len(test_neg),neg_cnt))
print('[Positive]: %s/%s ' % (len(test_pos),pos_cnt))
[Negative]: 842/795
[Positive]: 220/74




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.