- تحليل المشاعر مع التعلم الآلي
- معالجة البيانات
- الترميز Tokenization
- نموذج التعلم الآلي لتحليل المشاعر
- تقييم النموذج في مجموعة الاختبار
تحليل المشاعر Sentiment analysis هو العملية التي يمكن من خلالها قياس كل المحتوى كمياً لتمثيل أفكار ومعتقدات وآراء قطاعات كاملة من الجمهور. من الصعب التقليل من الآثار المترتبة على تحليل المشاعر لزيادة إنتاجية العمل. يعد تحليل المشاعر إحدى مهام البرمجة اللغوية العصبية NLP الشائعة التي يحتاج كل عالم بيانات لأدائها.
على سبيل المثال، أنت طالب في دورة تدريبية عبر الإنترنت ولديك مشكلة. قمت بنشره في منتدى الفصل. لن يكون تحليل المشاعر قادرًا على تحديد الموضوع الذي تعاني منه فحسب، بل أيضًا تحديد مدى إحباطك، وتخصيص تعليقاتهم وفقًا لهذا الشعور. هذا يحدث بالفعل لأن التكنولوجيا موجودة بالفعل.
تحليل المشاعر مع التعلم الآلي
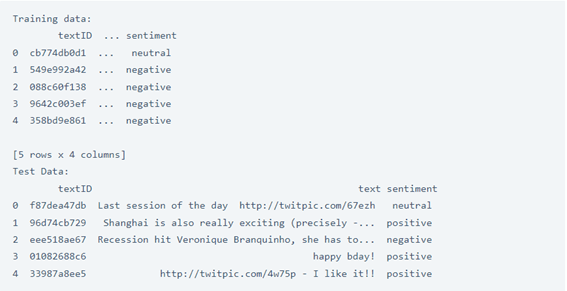
آمل أن تكون قد فهمت ما يعنيه تحليل المشاعر. سأقدم لك الآن طريقة سهلة للغاية لتحليل المشاعر باستخدام التعلم الآلي. تتضمن البيانات التي سأستخدمها 27481 تغريدة تم وضع علامة عليها في مجموعة التدريب و3534 تغريدة في مجموعة الاختبار. يمكنك بسهولة تنزيل البيانات من هنا. لنبدأ الآن بهذه المهمة من خلال النظر إلى البيانات باستخدام Pandas:
import pandas as pd
training = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
print("Training data: \n",training.head())
print("Test Data: \n",test.head())
معالجة البيانات
من أجل البساطة، لا نريد المبالغة في التعامل مع جانب تنظيف البيانات data cleaning، ولكن هناك بعض الأشياء البسيطة التي يمكننا القيام بها لمساعدة نموذج التعلم الآلي الخاص بنا على تحديد المشاعر. عملية تنظيف البيانات كالتالي:
- إزالة جميع الارتباطات التشعبية (hyperlinks) من التغريدات.
- استبدال الاختصارات (contractions) الشائعة.
- إزالة علامات الترقيم (punctuation).
كعملية لإعداد البيانات، يمكننا إنشاء دالة لتعيين تسميات المشاعر إلى الأعداد الصحيحة وإعادتها من الدالة:
import re
contractions_dict = {"can`t": "can not",
"won`t": "will not",
"don`t": "do not",
"aren`t": "are not",
"i`d": "i would",
"couldn`t": "could not",
"shouldn`t": "should not",
"wouldn`t": "would not",
"isn`t": "is not",
"it`s": "it is",
"didn`t": "did not",
"weren`t": "were not",
"mustn`t": "must not",
}
def prepare_data(df:pd.DataFrame) -> pd.DataFrame:
df["text"] = df["text"] \
.apply(lambda x: re.split('http:\/\/.*', str(x))[0]) \
.str.lower() \
.apply(lambda x: replace_words(x,contractions_dict))
df["label"] = df["sentiment"].map(
{"neutral": 1, "negative":0, "positive":2 }
)
return df.text.values, df.label.values
def replace_words(string:str, dictionary:dict):
for k, v in dictionary.items():
string = string.replace(k, v)
return string
train_tweets, train_labels = prepare_data(train_df)
test_tweets, test_labels = prepare_data(test_df)
الترميز Tokenization
نحتاج الآن إلى تحويل كل تغريدة إلى رمز متجه واحد ذي طول ثابت – على وجه التحديد تكامل TFIDF. للقيام بذلك، يمكننا استخدام Tokenizer() المدمج في Keras ، وهو مناسب لبيانات التدريب:
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(train_tweets)
train_tokenized = tokenizer.texts_to_matrix(train_tweets,mode='tfidf')
test_tokenized = tokenizer.texts_to_matrix(test_tweets,mode='tfidf')
نموذج التعلم الآلي لتحليل المشاعر
الآن، سأقوم بتدريب نموذجنا على تحليل المشاعر باستخدام خوارزمية تصنيف الغابات Random Forest Classification العشوائية المقدمة من Scikit-Learn:
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=500, min_samples_leaf=2,oob_score=True,n_jobs=-1,)
forest.fit(train_tokenized,train_labels)
print(f"Train score: {forest.score(train_tokenized,train_labels)}")
print(f"OOB score: {forest.oob_score_}")

تقييم النموذج في مجموعة الاختبار
تسهل Scikit-Learn استخدام كل من المصنف وبيانات الاختبار لإنتاج خوارزمية مصفوفة ارتباك confusion matrix تظهر الأداء في مجموعة الاختبار على النحو التالي:
print("Test score: ",forest.score(test_tokenized,test_labels))

معدل الدقة accuracy rate ليس كبيرًا لأن معظم أخطائنا تحدث عند توقع الفرق بين المشاعر الإيجابية والحيادية والسلبية والحيادية، والتي في المخطط الكبير للأخطاء ليست أسوأ شيء يمكن أن نمتلكه. على الرغم من أننا لحسن الحظ، نادرًا ما نخلط بين الشعور الإيجابي والشعور السلبي والعكس صحيح.
أتمنى أن تكون قد أحببت هذا المقال عن تحليل المشاعر.