

- الفصل الأول: مقدمة في التعلم العميق
- الفصل الثاني: الأساسيات
- الفصل الثالث: الشبكات العصبية امامية التغذية
- الفصل الرابع: الشبكة العصبية الالتفافية
- الفصل الخامس: الشبكة العصبية المتكررة
- الفصل السادس: شبكات الخصومة التوليدية
مقدمة
التعلم العميق هو مجموعة فرعية من التعلم الآلي الذي يركز على استخدام الشبكات العصبية لحل المشكلات المعقدة. اليوم، أصبح أكثر شيوعًا بفضل التطورات في البرامج والأجهزة التي تسمح لنا بجمع ومعالجة كميات كبيرة من البيانات. لأن الشبكات العصبية العميقة توفر كميات كبيرة من البيانات للأداء الجيد الذي نتوقعه، وبالتالي تتطلب أجهزة قوية لمعالجة هذه الكمية الكبيرة من البيانات.
ما هو التعلم العميق؟
الذكاء الاصطناعي هو في الأساس محاكاة للبشر وسلوكياتهم العقلية بواسطة برنامج كمبيوتر يمكنه القيام بأشياء تتطلب عادة ذكاء بشري. بعبارات أبسط، نظام يمكنه محاكاة السلوك البشري. تشمل هذه السلوكيات حل المشكلات والتعلم والتخطيط التي يتم تحقيقها من خلال تحليل البيانات وتحديد الأنماط بداخلها من أجل تكرار تلك السلوكيات.
الكود أو التقنية أو الخوارزمية أو أي نظام يمكنه محاكاة فئة الفهم المعرفي التي تظهر في حد ذاتها أو في إنجازاته هو الذكاء الاصطناعي. يتضمن ذلك التعلم الآلي، حيث يمكن للآلات التعلم من خلال الخبرة واكتساب المهارات دون تدخل بشري. ومن ثم، فإن الذكاء الاصطناعي هو لبنة بناء التعلم الآلي. في الواقع، يعد التعلم الآلي مجموعة فرعية رئيسية من الذكاء الاصطناعي ويمكنه تمكين الآلات من استخدام الأساليب الإحصائية لجعل تجاربهم أكثر جودة ودقة. يسمح هذا لأجهزة الكمبيوتر والآلات بتنفيذ الأوامر بناءً على بياناتهم وتعلمهم. تم تصميم هذه البرامج أو الخوارزميات لمعرفة المزيد بمرور الوقت والتكيف مع البيانات الجديدة.
الفكرة الرئيسية لاختراع التعلم الآلي القائم على العينة هو أن عملية التفكير في المشكلة أصبحت ممكنة من خلال الإشارة إلى أمثلة مماثلة سابقة. تسمى الأمثلة السابقة المستخدمة لبناء القدرات أمثلة تعليمية، وتسمى عملية القيام بذلك التعلم. في أنظمة الكمبيوتر، هناك خبرة في شكل البيانات، والمهمة الرئيسية للتعلم الآلي هي تطوير خوارزميات التعلم التي تقوم بنمذجة البيانات. من خلال تغذية البيانات التجريبية إلى خوارزمية التعلم الآلي، نحصل على نموذج يمكنه عمل تنبؤات في الملاحظات الجديدة.
التعلم العميق هو أيضًا مجموعة فرعية من الذكاء الاصطناعي والتعلم الآلي حيث تكتسب الشبكات العصبية الاصطناعية، والخوارزميات المستوحاة من الدماغ البشري، القدرة على التعلم من كميات كبيرة من البيانات. تقوم خوارزمية التعلم العميق، على غرار الطريقة التي نتعلم بها من التجارب والأمثلة، بعمل شيء واحد مرارًا وتكرارًا، وتغييره قليلاً في كل مرة لتحسين النتيجة. من خلال القيام بذلك، فإنه يساعد أجهزة الكمبيوتر في العثور على خصائص من البيانات والتكيف مع التغييرات. يساعد التعرض المتكرر لمجموعات البيانات الآلات على فهم الاختلافات ومناطق البيانات والوصول إلى نتيجة موثوقة. في أبسط أشكاله، يمكن اعتبار التعلم العميق وسيلة لأتمتة التحليلات التنبؤية (predictive analytics).
| التعريف 1.1 | التعلم العميق | |
| التعلم العميق عبارة عن مجموعة من الخوارزميات التي “تتعلم من خلال الطبقات“. بمعنى آخر، يتضمن التعلم من خلال الطبقات التي تمكن الخوارزمية من إنشاء تسلسل هرمي للمفاهيم المعقدة من مفاهيم أبسط. | ||
لفهم التعلم العميق بشكل أفضل، تخيل طفلًا صغيرًا يتعلم ماهية القطة. يتعلم الطفل الصغير ما هي القطة وما هي القطة من خلال الإشارة إلى الأشياء وقول كلمة “قطة”. يقول الآباء، “نعم، إنها قطة” أو “لا، إنها ليست قطة”. مع استمرار الطفل الدارج في الإشارة إلى الأشياء، فإنه يصبح أكثر وعيًا بالخصائص التي تتمتع بها جميع القطط؛ ما الذي يفعله الطفل دون أن يعرف ذلك. هذه هي الطريقة التي يخلق بها تجريدًا معقدًا (مفهوم القطة) من خلال إنشاء تسلسل هرمي يكون فيه كل مستوى من التجريد مع المعرفة المكتسبة من الطبقة السابقة للتسلسل الهرمي، لجعل هذا التجريد المعقد بسيطًا وواضحًا.
نشأة التعلم العميق؟
منذ بداية عصر الكمبيوتر، كان الباحثون يضعون نظريات حول ذكاء الآلة ويحلمون بامتلاك أجهزة كمبيوتر ذكية يمكنها تعلم وفهم الحلول للمشكلات المعقدة. في الخمسينيات والستينيات من القرن الماضي، ظهرت أولى الشبكات العصبية، بما في ذلك خوارزمية بيرسبترون لتصنيف الصور. ومع ذلك، كانت هذه الحالات المبكرة بسيطة للغاية ولا يمكن أن تكون شائعة على نطاق واسع.
عادت الشبكات العصبية إلى الظهور في الثمانينيات عندما طور الباحثون طرقًا لإعادة إرسال المعاملات لبناء وتدريب شبكات عصبية متعددة المستويات.
مع التطورات التي حدثت في العقد الأول من القرن الحادي والعشرين، ظهرت تقنيات تجعل من الممكن زيادة طبقات الشبكات العصبية. أدت هذه الشبكات متعددة الطبقات إلى تسمية مجال أبحاث الذكاء الاصطناعي “التعلم العميق” لأن الخوارزميات تعالج البيانات في طبقات متعددة للاستجابة.
في عام 2012، بدأت الشبكات العصبية العميقة في الأداء بشكل أفضل من خوارزميات التصنيف التقليدية، بما في ذلك خوارزميات التعلم الآلي. ترجع هذه الزيادة في الأداء إلى حد كبير إلى زيادة أداء معالجات الكمبيوتر (GPUs) والكمية الكبيرة من البيانات المتوفرة الآن. أدت الرقمنة السريعة إلى إنتاج بيانات واسعة النطاق، وهي الأكسجين المستخدم في تدريس نماذج التعلم العميق. منذ ذلك الحين، في كل عام، استمر التعلم العميق في التحسن وأصبح أفضل نهج لحل المشكلات في العديد من المجالات المختلفة.
| يرجع هذا الارتفاع في الشعبية واستخدام التعلم العميق إلى حد كبير إلى التقدم في الأجهزة ومجموعات البيانات الموسومة الضخمة التي تسمح لنماذج التعلم العميق بالتعافي بسرعة بمرور الوقت. |
سبب شعبية التعلم العميق؟
تتجه صناعة البرمجيات اليوم نحو الذكاء الآلي، والتعلم الآلي هو الذي مهد الطريق للآلات الذكية. ببساطة، التعلم الآلي عبارة عن مجموعة من الخوارزميات التي تحلل البيانات، وتتعلم منها، ثم تطبق ما تعلموه لاتخاذ قرارات ذكية. الشيء الذي يميز خوارزميات التعلم الآلي التقليدية هو أنها، بغض النظر عن مدى تعقيدها، لا تزال شبيهة بالآلة. بمعنى آخر، يحتاجون إلى خبراء في هذا المجال للتعلم. بالنسبة لخبراء الذكاء الاصطناعي، هذه هي النقطة التي يعد بها التعلم العميق. وذلك لأن الشبكات العصبية العميقة تتعلم ميزات عالية المستوى من البيانات بشكل تدريجي (هرميًا) دون الحاجة إلى تدخل بشري. هذا يلغي الحاجة إلى خبراء المجال واستخراج الميزات يدويًا. اختيار السمات لمجموعة البيانات له تأثير كبير على نجاح نموذج التعلم الآلي، في حين أن استخراج السمات يدويًا سيكون عملية معقدة وتستغرق وقتًا طويلاً.
اليوم، بالإضافة إلى الشركات والمؤسسات، حتى الأشخاص في الجوانب التكنولوجية يميلون إلى التعلم العميق، وعدد هذه الشركات والأفراد الذين يستخدمون التعلم العميق يتزايد يومًا بعد يوم. لفهم هذا السبب، يجب على المرء أن ينظر إلى الفوائد التي يمكن اكتسابها باستخدام نهج التعلم العميق. يمكن تلخيص الفوائد الرئيسية لاستخدام هذه التقنية على النحو التالي:
- لا حاجة لهندسة الميزات: في التعلم الآلي، تعد هندسة الميزات مهمة أساسية وهامة. هذا لأنه يحسن الدقة، وفي بعض الأحيان قد تتطلب هذه العملية معرفة المجال حول مشكلة معينة. تتمثل إحدى أكبر مزايا استخدام نهج التعلم العميق في قدرته على أداء هندسة الميزات تلقائيًا. في هذا النهج، تقوم الخوارزمية بمسح البيانات لتحديد الميزات ذات الصلة ثم دمجها لتسريع التعلم، دون إخبارها صراحة. تساعد هذه الإمكانية علماء البيانات على توفير قدر كبير من الوقت ثم تحقيق نتائج أفضل.
- الاستخدام الاقصى للبيانات غير المهيكلة: تظهر الأبحاث أن نسبة كبيرة من بيانات المؤسسة غير المهيكلة ، لأن معظمها في تنسيقات مختلفة مثل الصور والنصوص وما إلى ذلك. بالنسبة لمعظم خوارزميات التعلم الآلي، يعد تحليل البيانات غير المهيكلة أمرًا صعبًا. هذا هو المكان الذي يكون فيه التعلم العميق مفيدًا. لأنه يمكنك استخدام تنسيقات بيانات مختلفة لتعليم خوارزميات التعلم العميق وأيضًا اكتساب رؤى تتعلق بالغرض من التدريب. على سبيل المثال ، يمكنك استخدام خوارزميات التعلم العميق لاكتشاف العلاقات بين تحليل الصناعة ودردشة الوسائط الاجتماعية والمزيد للتنبؤ بأسعار الأسهم المستقبلية للمؤسسة.
- تقديم نتائج عالية الجودة: يصاب البشر بالجوع أو التعب وأحيانًا يرتكبون أخطاء. في المقابل، ليس هذا هو الحال عندما يتعلق الأمر بالشبكات العصبية. يمكن لنموذج التعلم العميق المدرب بشكل صحيح أن ينجز آلاف المهام الروتينية والمتكررة في فترة زمنية قصيرة نسبيًا مقارنة بما يحتاجه الإنسان. بالإضافة إلى ذلك ، لن تنخفض جودة العمل أبدًا ، ما لم تحتوي بيانات التدريب على بيانات أولية لا تشير إلى مشكلة تريد حلها.
- التعلم الانتقالي: يحتوي التعلم العميق على العديد من النماذج المدربة مسبقًا بأوزان وتحيزات ثابتة ، وبعضها ممتاز في التنبؤ.
- دقة عالية في النتائج: عندما يتم تعليم التعلم العميق بكميات هائلة من البيانات، يمكن أن يكون دقيقًا للغاية مقارنة بخوارزميات التعلم الآلي التقليدية.
بالنظر إلى المزايا المذكورة أعلاه والاستفادة بشكل أكبر من نهج التعلم العميق، يمكن القول إن التأثير الكبير للتعلم العميق على التقنيات المتقدمة المختلفة مثل إنترنت الأشياء في المستقبل واضح. لقد قطع التعلم العميق شوطًا طويلاً وأصبح سريعًا تقنية حيوية يتم استخدامها باستمرار من قبل مجموعة من الشركات في مجموعة متنوعة من الصناعات.
| ومع ذلك، تجدر الإشارة إلى أن التعلم العميق قد لا يكون أيضًا الخيار الأفضل استنادًا إلى البيانات. على سبيل المثال، إذا كانت مجموعة البيانات صغيرة، فقد تؤدي أحيانًا نماذج تعلم الآلة الخطية الأبسط إلى نتائج أكثر دقة. ومع ذلك، يجادل بعض خبراء التعلم الآلي بأن شبكة عصبية عميقة جيدة التدريب لا يزال بإمكانها العمل بشكل جيد مع كميات صغيرة من البيانات. |
كيف يعمل التعلم العميق؟
تكتسب نماذج التعلم العميق القدرة على التعلم من خلال التحليل المستمر للبيانات واكتشاف الهياكل المعقدة في البيانات. تتحقق عملية التعلم من خلال بناء نماذج حسابية تسمى الشبكات العصبية المستوحاة من بنية الدماغ. في صميم هذا التعلم يوجد نهج متكرر لتدريب الآلات لتقليد الذكاء البشري. تقوم الشبكة العصبية الاصطناعية بتنفيذ هذه الطريقة التكرارية من خلال عدة مستويات هرمية، حيث تكون قادرة على حل مفاهيم أكثر تعقيدًا للمشكلة من خلال الانتقال إلى طبقات المستوى التالي. تساعد المستويات الأساسية الآلات على تعلم معلومات بسيطة. كلما انتقلت إلى كل مستوى جديد، تجمع الأجهزة المزيد من المعلومات وتدمجها مع ما تعلمته في المستوى الأخير. في نهاية العملية، يجمع النظام جزءًا أخيرًا من المعلومات يمثل إدخالًا مختلطًا. تمر هذه المعلومات بعدة تسلسلات هرمية وتشبه التفكير المنطقي المعقد.
دعنا نقسمها أكثر بمساعدة مثال. ضع في اعتبارك مساعدًا صوتيًا مثل Alexa أو Siri لترى كيف يستخدم التعلم العميق لتجارب المحادثة الطبيعية. في المراحل الأولى من الشبكة العصبية، عندما يتغذى المساعد الصوتي على البيانات، فإنه يحاول تحديد الأصوات والأشياء الأخرى. في المستويات العليا، يلتقط معلومات المفردات ويضيف النتائج من المستويات السابقة. في المستويات التالية، يحلل الإعلانات (الأوامر) ويجمع كل نتائجها. بالنسبة لأعلى مستوى من الهيكل الهرمي، يتم تدريب المساعد الصوتي بدرجة كافية ليكون قادرًا على تحليل الحوار وتقديم المدخلات بناءً على تلك المدخلات.
| في التعلم العميق، لا نحتاج إلى برمجة صريحة لكل شيء. يمكنهم التعرف تلقائيًا على تمثيلات البيانات مثل الصور أو الفيديو أو النص، دون تقديم قواعد يدوية. يمكن أن تتعلم البنى شديدة المرونة الخاصة بهم مباشرة من البيانات الخام ويمكن أن تزيد من الأداء إذا تم توفير المزيد من البيانات. |
عيوب وتحديات التعلم العميق
على الرغم من تزايد أهمية التعلم العميق وتطوراته، إلا أن هناك بعض الجوانب أو التحديات السلبية التي يجب معالجتها لتطوير نموذج التعلم العميق. أكبر قيود على نماذج التعلم العميق هو أنها تتعلم من خلال الملاحظة. هذا يعني أنهم يعرفون فقط ما هو موجود في البيانات التي يقومون بتعليمها وأنهم جيدون فقط في التعيين بين المدخلات والمخرجات. بمعنى آخر، لا يعرفون شيئًا عن سياق البيانات التي يستخدمونها. في الواقع، تشير كلمة “عميق” في التعلم العميق إلى مرجع هندسة التكنولوجيا وعدد الطبقات المخفية في هيكلها أكثر من كونها تشير إلى فهم عميق لما يتم القيام به.
تعد نماذج التعلم العميق واحدة من أسوأ نماذج البيانات في عالم التعلم الآلي. إنهم بحاجة إلى قدر هائل من البيانات لتحقيق الأداء المطلوب وخدمتنا بالقدر التي نتوقعها منهم. ومع ذلك، فإن الحصول على هذا القدر من البيانات ليس بالأمر السهل دائمًا. بالإضافة إلى ذلك، في حين أنه يمكننا الحصول على كميات كبيرة من البيانات حول موضوع ما، إلا أنه غالبًا لا يتم تصنيفها، لذلك لا يمكننا استخدامها لتعليم أي نوع من خوارزمية التعلم الخاضع للإشراف. باختصار، لا تتعلم هذه النماذج بطريقة قابلة للتعميم إذا كان لدى المستخدم كمية صغيرة من البيانات. يمكن أن يعمل التعلم العميق بشكل أفضل عند توفر كمية كبيرة من البيانات عالية الجودة. مع زيادة البيانات المتاحة، يزداد أداء نظام التعلم العميق.
| عندما لا يتم إدخال بيانات ذات جودة في النظام، يمكن أن يفشل نظام التعلم العميق فشلاً ذريعاً. |
تعد قضية التحيزات (biases) أيضًا مشكلة رئيسية لنماذج التعلم العميق. إذا تم تدريب نموذج على بيانات متحيزة، فإن النموذج يعيد إنتاج تلك التحيزات في تنبؤاته.
على الرغم من أن نماذج التعلم العميق فعالة للغاية ويمكنها صياغة حل مناسب لمشكلة معينة بعد التدريب مع البيانات، إلا أنها غير قادرة على القيام بذلك لحل مشكلة مماثلة وتحتاج إلى إعادة التدريب. لتوضيح ذلك، ضع في اعتبارك خوارزمية التعلم العميق التي تتعلم أن الحافلات المدرسية دائمًا ما تكون صفراء، ولكن فجأة تتحول الحافلات المدرسية إلى اللون الأزرق. ومن ثم، يجب إعادة تدريبها. على العكس من ذلك، ليس لدى الطفل البالغ من العمر خمس سنوات مشكلة في التعرف على السيارة كحافلة مدرسية زرقاء. بالإضافة إلى ذلك، فهي أيضًا لا تعمل بشكل جيد في المواقف التي قد تكون مختلفة قليلاً عن البيئة التي مارسوا فيها. على سبيل المثال، في DeepMind دربت Google على هزيمة 49 لعبة Atari. ومع ذلك، في كل مرة يهزم فيها النظام مباراة واحدة، يجب إعادة تدريبه لهزيمة المباراة التالية. يقودنا هذا إلى تحديد آخر للتعلم العميق، وهو أنه في حين أن النموذج قد يكون جيدًا للغاية في تعيين المدخلات إلى المخرجات، فقد لا يكون جيدًا في فهم سياق البيانات التي يديرونها.
يتعلم نمط التعلم العميق أو بشكل عام خوارزميات التعلم الآلي الحالية بشكل منفصل: وفقًا لمجموعة بيانات التدريب، تعمل خوارزمية التعلم الآلي على مجموعة البيانات لإنتاج نموذج ولا تبذل أي جهد للحفاظ على المعرفة المكتسبة واستخدامها في تفعيل التعلم في المستقبل. على الرغم من أن نموذج التعلم المنفصل هذا كان ناجحًا للغاية، إلا أنه يتطلب عددًا كبيرًا من أمثلة التدريب وهو مناسب فقط للمهام المحددة والمحدودة جيدًا. مع توفر مجموعات بيانات أكبر وخفض التكاليف الحسابية، أصبحت النماذج القادرة على حل المهام الأكبر متاحة. ومع ذلك، قد يكون تعليم نموذج في كل مرة يحتاج فيها لتعلم مهمة جديدة أمرًا مستحيلًا. نظرًا لأن البيانات القديمة قد لا تكون متاحة، فقد لا يتم تخزين البيانات الجديدة بسبب مشكلات الخصوصية، أو قد لا يدعم تكرار تحديث النظام تدريب نموذج جديد مع تكرار جميع البيانات بشكل كافٍ. عندما تتعلم الشبكات العصبية العميقة مهامًا جديدة، فإن المعرفة الجديدة لها الأسبقية على المعرفة القديمة إذا لم يتم استخدام معايير معينة، مما يؤدي غالبًا إلى نسيان المعرفة الثانوية. يُعرف هذا بالنسيان الكارثي catastrophic forgetting)) (انظر الشكل 1-1). يحدث النسيان الكارثي عندما تكون الشبكة العصبية المدربة غير قادرة على الحفاظ على قدرتها على أداء المهام التي تعلمتها بالفعل عندما تتكيف مع المهام الجديدة.
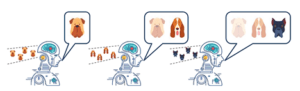
الشكل 1-1. صورة النسيان الكارثي. تُنسى المعرفة التي تم تعلمها سابقًا (تختفي تدريجياً) عند تعلم فئات جديدة لم تتم رؤيتها لفترة من الوقت.
مشكلة أخرى مع الشبكات العصبية العميقة هي أنها غالبًا ما يتم تدريبها على افتراضات العالم المغلق، أي أنه من المفترض أن يكون توزيع البيانات التجريبية مشابهًا لتوزيع بيانات التدريب. ومع ذلك، عند استخدامه في العمل الواقعي، يكون هذا الافتراض غير صحيح ويؤدي إلى انخفاض كبير في أدائهم. عندما تعالج الشبكات العصبية العميقة البيانات التي لا تشبه التوزيع الذي لوحظ أثناء التدريب، ما يسمى خارج التوزيع (Out-of-distribution)، فإنها غالبًا ما تقدم تنبؤات خاطئة وتفعل ذلك بثقة كبيرة. (انظر الشكل 1-2). في هذه الحالات ، يرتبط إخراج الشبكة ارتباطًا مباشرًا بحل المشكلة ، أي احتمال كل فئة. ومع ذلك، يجب أن يكون مجموع تمثيلات متجه الإخراج واحدًا دائمًا. هذا يعني أنه عندما يتم عرض إدخال على الشبكة ليس جزءًا من توزيع التدريب ، فإنه لا يزال يعطي الاحتمال لأقرب فئة بحيث يصل مجموع الاحتمالات إلى واحد. أدت هذه الظاهرة إلى المشكلة المعروفة المتمثلة في الإفراط في الثقة (overconfident) في الشبكات العصبية بمحتوى لم يسبق لهم رؤيته من قبل.
على الرغم من أن هذا الانخفاض في الأداء مقبول لتطبيقات مثل التوصية بالمنتجات، إلا أن استخدام مثل هذه الأنظمة في مجالات مثل الطب والروبوتات المنزلية يعد أمرًا خطيرًا ، حيث يمكن أن يتسببوا في حوادث خطيرة. ينبغي ، إن أمكن ، تعميم نظام الذكاء الاصطناعي المثالي على عينات خارج التوزيع. لذلك ، تعد القدرة على الكشف عن التوزيعات أمرًا بالغ الأهمية للعديد من تطبيقات العالم الحقيقي وهي ضرورية لضمان موثوقية وسلامة أنظمة التعلم الآلي. في القيادة الذاتية، على سبيل المثال ، نريد أن يقوم نظام القيادة بالتحذير وتسليم السيطرة عندما يكتشف مشاهد أو أشياء غير عادية لم يراها من قبل ولا يمكنه اتخاذ قرار آمن.
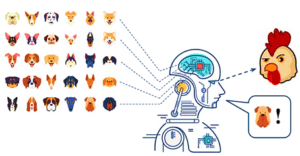
الشکل 1-2. عندما يتم تقديم عينة جديدة خارج التوزيع المكتسب، فإن الشبكات العصبية العميقة لفئة معينة تتنبأ بثقة بالتوزيع المكتسب.
أخيرًا، يتمثل أكثر نقاط الضعف المعروفة في الشبكات العصبية في افتقارها إلى الشفافية. بينما يمكن تتبع القرارات التي تتخذها النماذج المستندة إلى القواعد من خلال عبارات if and else، فإن هذا لن يكون ممكنًا في التعلم العميق. هذا النقص في الشفافية هو ما يشار إليه في التعلم العميق باسم “الصندوق الأسود”.
ببساطة، أنت لا تعرف كيف ولماذا حصلت شبكتك العصبية على ناتج معين. على سبيل المثال، عندما تقوم بإدخال صورة قطة إلى شبكة عصبية ويتنبأ بها الجهاز، فمن الصعب جدًا فهم سبب هذا التوقع. سيكون هذا السيناريو مهمًا في قرارات العمل. هل يمكنك أن تتخيل أن الرئيس التنفيذي لشركة كبيرة يتخذ قرارًا بشأن ملايين الدولارات دون أن تفهم سبب قيامه بذلك؟ فقط لأن “الكمبيوتر” يقول إنه يجب أن يفعل ذلك؟ بالمقارنة، الخوارزميات مثل أشجار القرار قابلة للتفسير بشكل كبير.
تجد خوارزميات التعلم العميق الأنماط والارتباطات من خلال البيانات التي يتم تغذيتها بها، وفي بعض الأحيان تتخذ قرارات مربكة حتى للمهندسين الذين قاموا بإنشائها. لن تكون هذه مشكلة عندما يقوم التعلم العميق بشيء ذي أهمية ثانوية. ولكن عندما يتعلق الأمر بتقرير مصير المتهم في المحكمة أو العلاج الطبي لمريض، فقد يكون ذلك أمرًا بالغ الأهمية. لأن الأخطاء يمكن أن يكون لها عواقب كثيرة. بحسب ماركوس:
“لا تزال مشكلة الشفافية دون حل ، ويريد المستخدمون فهم كيفية اتخاذ نظام معين لقرار محدد عند استخدام التعلم العميق للعمل في مجالات التشخيص الطبي والأعمال المالية.”
بشكل عام ، وفقًا لأندرو آنج ، يعد التعلم العميق طريقة رائعة “لبناء مجتمع قائم على الذكاء الاصطناعي”، والتغلب على أوجه القصور هذه بمساعدة التقنيات الأخرى هو الطريق الصحيح للوصول الى الهدف.
مستقبل التعلم العميق؟
يعد التعلم العميق حاليًا أكثر تقنيات الذكاء الاصطناعي فاعلية لتطبيقات متعددة. ومع ذلك، هناك آراء مختلفة حول قدرات التعلم العميق. بينما يعتقد بعض الباحثين في التعلم العميق أنه يمكن حل جميع المشكلات عن طريق التعلم العميق، هناك العديد من العلماء الذين يشيرون إلى أوجه القصور في التعلم العميق.
عالم النفس البحثي غاري ماركوس، أحد الرواد في مجال التعلم العميق !!!، يقترح طرقًا جديدة لتحسين حلول التعلم العميق. تتضمن هذه الأساليب تقديم المنطق أو المعرفة السابقة للتعلم العميق، وتعلم المراقبة الذاتية، وشبكات الكبسولة، وما إلى ذلك. يؤكد جاري ماركوس أن تقنيات التعلم العميق كثيفة البيانات وهشة، وأن قدرتها على التعميم محدودة.
يقول عالم الكمبيوتر إيان لاكان: “لا يمكن لأي من تقنيات الذكاء الاصطناعي التي نمتلكها إنشاء تمثيلات للعالم قريبة مما نراه في الحيوانات والبشر، من خلال البنية أو التعلم”. ومن ثم، فإن تقنيات الذكاء الاصطناعي الحالية مثل التعلم العميق لا تزال غير قادرة على إنشاء ذكاء اصطناعي عام يتمتع بذكاء يمكن مقارنته بالحيوانات أو البشر. ومع ذلك، يعتقد لاكان أن الذكاء الاصطناعي يمكن أن يعزز تطوير الذكاء العام على أساس التعلم العميق دون إشراف. يلبي التقدم الحديث الحاجة البشرية إلى البيانات ذات العلامات اليدوية التي تتعلم منها الآلات.
يقترح غاري ماركوس، مؤيد للنهج الهجين للتعلم العميق، خطة من أربع خطوات لمستقبل التعلم العميق:
- الاتصال بعالم الذكاء الاصطناعي الكلاسيكي. لا يقترح ماركوس تحرير التعلم العميق، لكنه يجادل بأنه يجب علينا استخدام مناهج أخرى للذكاء الاصطناعي مثل المعرفة السابقة، والتفكير، والنماذج المعرفية الغنية جنبًا إلى جنب مع التعلم العميق من أجل التغيير التحويلي.
- بناء أطر معرفية ثرية وقواعد بيانات معرفية واسعة النطاق. تمتلئ أنظمة التعلم العميق إلى حد كبير فقط بالارتباطات بين أشياء محددة. لذلك هم بحاجة إلى الكثير من المعرفة.
- أدوات للتفكير المجرد من أجل التعميم الفعال. يجب أن نكون قادرين على الجدال حول هذه الأشياء. لنفترض أن لدينا معلومات عن الأشياء المادية وموقعها في الكون، على سبيل المثال الكوب. يحتوي الكأس على قلم رصاص. يجب أن تكون أنظمة التعلم العميق قادرة بعد ذلك على اكتشاف أن أقلام الرصاص قد تسقط إذا قمنا بعمل ثقب في قاع الكوب. يقوم البشر دائمًا بهذا النوع من الاستنتاجات، لكن أنظمة التعلم العميق الحالية، أو الذكاء الاصطناعي بشكل عام ، لا تملك هذه القدرة.
- آليات تمثيل واستقراء النماذج المعرفية.
| لا يزال أمام التعلم العميق طريق طويل للوصول إلى قدرات نظرائه من البشر. |
التفكير الرمزي (symbolic reasoning)
يوصف تاريخ أبحاث الذكاء الاصطناعي أحيانًا بأنه تضارب بين نهجين مختلفين للتفكير الرمزي والتعلم الآلي. في العقد الأول، ساد التفكير الرمزي، لكن التعلم الآلي بدأ يتخلل التسعينيات وانتشر في جميع أنحاء المجال مع ثورة التعلم العميق. ومع ذلك، يبدو أن التفكير الرمزي هو مجرد مجموعة أخرى من الأساليب التي قد تؤدي إلى توسيع وتمكين التعلم العميق.
يقول نيكو ستروم: “تمتلك شبكات المحولات (Transformer networks) شيئًا يسمى الانتباه”(attention). يمكنك تعبئتها مسبقًا بالمتجهات التي تمثل الحقيقة في قاعدة المعرفة هذه، وبعد ذلك يمكنك مطالبة الشبكة بالاهتمام بالمعرفة الصحيحة اعتمادًا على المدخلات، لذلك يمكنك محاولة هيكلة معرفة العالم من خلال الجمع بين نظام التعلم العميق.
هناك أيضًا شبكات عصبية للرسم البياني يمكنها تمثيل المعرفة حول العالم. لديك عقد وحواف بين هذه العقد تشير إلى العلاقات بينها. لذلك، على سبيل المثال، يمكنك إظهار الكيانات في العقد ثم العلاقات بين الكيانات. يمكننا استخدام الانتباه في جزء من الرسم البياني المعرفي ذي صلة بالسياق أو السؤال الحالي.
يبدو أنه يمكن تمثيل كل المعارف في رسم بياني واحد. ومع ذلك، فإن النقطة المهمة هي، كيف يمكن القيام بذلك بكفاءة وبشكل مناسب؟
“كانت لدى هينتون هذه الفكرة منذ وقت طويل. وقد أطلق عليها اسم ناقل الفكر (thought vector). يمكن تمثيل أي فكرة لديك بواسطة ناقل. الشيء المثير للاهتمام هو أنه يمكننا إظهار أي شيء على رسم بياني. ولكن لكي يعمل هذا بشكل جيد باستخدام نموذج التعلم العميق، يجب أن يكون لدينا شيء من ناحية أخرى يمكننا تمثيل كل شيء به، وهذا متجه، حتى نتمكن من إنشاء خريطة بين الاثنين. “
تطبيقات التعلم العميق؟
يستخدم التعلم العميق الآن كأداة قوية وشائعة لحل المشاكل البشرية في كل مجال. يستخدم التعلم العميق لمئات المشاكل، من رؤية الكمبيوتر إلى معالجة اللغة الطبيعية. في كثير من الحالات، كان التعلم العميق أفضل من ذي قبل. يستخدم التعلم العميق على نطاق واسع في الجامعات لدراسة الذكاء وفي الصناعة لبناء أنظمة ذكية لمساعدة البشر في مجموعة متنوعة من المهام. في هذا القسم، سوف نلقي نظرة على بعض تطبيقات التعلم العميق التي من المؤكد أنها ستدهشك. بالطبع، هناك العديد من البرامج المختلفة وهذه القائمة ليست شاملة بأي حال من الأحوال.
المساعدين الافتراضيين
أشهر المساعدين الافتراضيين هما Siri و Alexa و Google Assistant . يوفر كل تفاعل مع هؤلاء المساعدين فرصة لهم لمعرفة المزيد عن صوتك ولغتك، مما يؤدي إلى تجربة ثانوية للتفاعل البشري. يستخدم المساعدون الافتراضيون التعلم العميق لمعرفة المزيد حول موضوعاتهم، من تفضيلات الطعام الخاصة بك إلى النقاط الساخنة أو الموسيقى المفضلة لديك. سوف يتعلمون فهم أوامرك من خلال تقييم اللغة البشرية الطبيعية لتنفيذها.
هناك ميزة أخرى تُمنح للمساعدين الافتراضيين وهي ترجمة كلامك إلى نص وتدوين الملاحظات نيابة عنك وحجز موعد. المساعدون الافتراضيون موجودون في خدمتك حرفيًا، حيث يمكنهم التعامل مع كل شيء بدءًا من المهام وحتى الرد التلقائي على مكالماتك المحددة وتنسيق المهام بينك وبين أعضاء فريقك.
جمع الأخبار واكتشاف أخبار الاحتيال
توجد الآن طريقة لتصفية جميع الأخبار السيئة والقبيحة من اختيارك للأخبار. يعزز الاستخدام المكثف للتعلم العميق في تجميع الأخبار الجهود المبذولة لتخصيص الأخبار وفقًا للقراء. على الرغم من أن هذا قد لا يبدو جديدًا، فقد تم تطوير مستويات جديدة من التعقيد لتحديد شخصيات القارئ لتصفية الأخبار بناءً على المعايير الجغرافية والاجتماعية والاقتصادية جنبًا إلى جنب مع التفضيلات الفردية للقارئ. من ناحية أخرى، يعد اكتشاف الاحتيال من الأصول المهمة في عالم اليوم حيث أصبح الإنترنت المصدر الأساسي لجميع المعلومات الصحيحة والكاذبة.
من الصعب جدًا اكتشاف الأخبار المزيفة لأن الروبوتات تكررها تلقائيًا على القنوات. يساعد التعلم العميق في تطوير الفئات التي يمكنها اكتشاف الأخبار الزائفة أو المتحيزة وإزالتها من مقتطفات الأخبار الخاصة بك وتحذيرك من انتهاكات الخصوصية المحتملة.
الذكاء العاطفي
في حين أن أجهزة الكمبيوتر قد لا تكون قادرة على تكرار المشاعر البشرية، فإنها تكتسب فهمًا أفضل لمواقفنا بفضل التعلم العميق. أنماط مثل التغييرات في النغمة، أو التجهم الخفيف، أو البحة كلها إشارات بيانات قيّمة يمكن أن تساعد الذكاء الاصطناعي واكتشاف الحالة المزاجية لدينا. يمكن استخدام مثل هذه البرامج لمساعدة الشركات على ربط البيانات العاطفية بالإعلانات، أو حتى لإعلام الأطباء بحالة المريض العاطفية.
الرعاية الصحية
لا يمكن للأطباء أن يكونوا مع مرضاهم على مدار 24 ساعة في اليوم، ولكن الشيء الوحيد الذي نحمله معنا دائمًا هو هواتفنا. بفضل التعلم العميق، يمكن للأدوات الطبية فحص البيانات التي نأخذها وبيانات الحركة لتشخيص المشاكل الصحية المحتملة. يستخدم برنامج رؤية الكمبيوتر Robbie.AI هذه البيانات لتتبع أنماط حركة المريض للتنبؤ بالسقوط بالإضافة إلى التغيرات في الحالة العقلية للمستخدم. أثبت التعلم العميق أيضًا أنه يشخص سرطان الجلد من خلال الصور.
يستخدم التعلم العميق أيضًا على نطاق واسع في التجارب السريرية لإيجاد حلول للأمراض المستعصية، لكن شكوك الأطباء ونقص قواعد البيانات الشاملة لا يزالان يشكلان تحديات لاستخدام التعلم العميق في الطب.
كشف الاحتيال
مع استمرار البنوك في رقمنة عمليات معاملاتها، تزداد احتمالية الاحتيال الرقمي، لذلك يلعب التعلم العميق دورًا مهمًا في منع هذا النوع من الاحتيال. يمكن الكشف عن الاحتيال بسرعة من خلال تقنيات التعلم المتعمق.
خلاصه الفصل
- الذكاء الاصطناعي هو نظام يمكنه محاكاة السلوك البشري.
- في أنظمة الكمبيوتر، هناك خبرة في شكل بيانات.
- تقوم خوارزمية التعلم العميق، على غرار الطريقة التي نتعلم بها من التجارب والأمثلة، بعمل شيء واحد مرارًا وتكرارًا ، وتغييره قليلاً في كل مرة لتحسين النتيجة.
- تعد نماذج التعلم العميق واحدة من أسوأ نماذج البيانات في عالم التعلم الآلي.
- أكثر نقاط الضعف المعروفة في الشبكات العصبية هي عدم وجود الشفافية.
اختبار
- عرف الذكاء الاصطناعي والتعلم الآلي والتعلم العميق.
- متى يحدث النسيان الكارثي في الشبكات العصبية؟
- ما هي الميزة المهمة للتعلم العميق مقارنة بالتعلم الآلي؟
- صف بعض القيود والتحديات في التعلم العميق.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.