

- تنزيل مجموعة بيانات DLIB
- التمثيل البياني لمجموعة البيانات
- تكوين فئات مجموعة البيانات
- رسم تحويلات التدريب
- تقسيم مجموعة البيانات للتدريب والتنبؤ بمعالم الوجه
- اختبار شكل بيانات الإدخال
- تعريف نموذج اكتشاف معالم الوجه
- دوال المساعدة
- تدريب الشبكة العصبية لاكتشاف معالم الوجه
- توقع معالم الوجه
هل فكرت يومًا في كيفية تمكن Snapchat من تطبيق فلاتر مذهلة وفقًا لوجهك؟ تمت برمجته لاكتشاف بعض العلامات على وجهك لإبراز فلتر وفقًا لتلك العلامات. في التعلم الآلي، تُعرف هذه العلامات باسم معالم الوجه Face Landmarks. في هذه المقالة، سأوجهك إلى كيفية اكتشاف معالم الوجوه باستخدام التعلم الآلي.
الآن، سأبدأ ببساطة باستيراد جميع المكتبات التي نحتاجها لهذه المهمة. سأستخدم PyTorch في هذه المقالة لمواجهة اكتشاف المعالم باستخدام التعلم العميق. لنستورد جميع المكتبات:
import time
import cv2
import os
import random
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import imutils
import matplotlib.image as mpimg
from collections import OrderedDict
from skimage import io, transform
from math import *
import xml.etree.ElementTree as ET
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms.functional as TF
from torchvision import datasets, models, transforms
from torch.utils.data import Dataset
تنزيل مجموعة بيانات DLIB
مجموعة البيانات التي سأختارها هنا لاكتشاف معالم الوجه في مجموعة بيانات DLIB الرسمية التي تتكون من أكثر من 6666 صورة بأبعاد مختلفة. سيقوم الكود أدناه بتنزيل مجموعة البيانات وفك الضغط لمزيد من الاستكشاف:
%%capture
if not os.path.exists('/content/ibug_300W_large_face_landmark_dataset'):
!wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
!tar -xvzf 'ibug_300W_large_face_landmark_dataset.tar.gz'
!rm -r 'ibug_300W_large_face_landmark_dataset.tar.gz'
التمثيل البياني لمجموعة البيانات
الآن، دعنا نلقي نظرة على ما نعمل معه، لنرى جميع تنظيف البيانات وفرص المعالجة المسبقة التي نحتاج إلى خوضها. فيما يلي مثال على صورة من مجموعة البيانات التي أخذناها لهذه المهمة.
file = open('ibug_300W_large_face_landmark_dataset/helen/trainset/100032540_1.pts')
points = file.readlines()[3:-1]
landmarks = []
for point in points:
x,y = point.split(' ')
landmarks.append([floor(float(x)), floor(float(y[:-1]))])
landmarks = np.array(landmarks)
plt.figure(figsize=(10,10))
plt.imshow(mpimg.imread('ibug_300W_large_face_landmark_dataset/helen/trainset/100032540_1.jpg'))
plt.scatter(landmarks[:,0], landmarks[:,1], s = 5, c = 'g')
plt.show()

يمكنك أن ترى أن الوجه يغطي مساحة أقل بكثير في الصورة. إذا كنا سنستخدم هذه الصورة في الشبكة العصبية، فستأخذ الخلفية أيضًا. لذا، مثلما نقوم بإعداد بيانات نصية، سنقوم بإعداد مجموعة بيانات الصور هذه لمزيد من الاستكشاف.
تكوين فئات مجموعة البيانات
دعنا الآن نتعمق أكثر في الفئات والتسميات في مجموعة البيانات. يتكون labels_ibug_300W_train.xml من الصور المدخلة والمعالم والمربع المحيط لاقتصاص الوجه. سوف أقوم بتخزين كل هذه القيم في القائمة حتى نتمكن من الوصول إليها بسهولة أثناء عملية التدريب.
class Transforms():
def __init__(self):
pass
def rotate(self, image, landmarks, angle):
angle = random.uniform(-angle, +angle)
transformation_matrix = torch.tensor([
[+cos(radians(angle)), -sin(radians(angle))],
[+sin(radians(angle)), +cos(radians(angle))]
])
image = imutils.rotate(np.array(image), angle)
landmarks = landmarks - 0.5
new_landmarks = np.matmul(landmarks, transformation_matrix)
new_landmarks = new_landmarks + 0.5
return Image.fromarray(image), new_landmarks
def resize(self, image, landmarks, img_size):
image = TF.resize(image, img_size)
return image, landmarks
def color_jitter(self, image, landmarks):
color_jitter = transforms.ColorJitter(brightness=0.3,
contrast=0.3,
saturation=0.3,
hue=0.1)
image = color_jitter(image)
return image, landmarks
def crop_face(self, image, landmarks, crops):
left = int(crops['left'])
top = int(crops['top'])
width = int(crops['width'])
height = int(crops['height'])
image = TF.crop(image, top, left, height, width)
img_shape = np.array(image).shape
landmarks = torch.tensor(landmarks) - torch.tensor([[left, top]])
landmarks = landmarks / torch.tensor([img_shape[1], img_shape[0]])
return image, landmarks
def __call__(self, image, landmarks, crops):
image = Image.fromarray(image)
image, landmarks = self.crop_face(image, landmarks, crops)
image, landmarks = self.resize(image, landmarks, (224, 224))
image, landmarks = self.color_jitter(image, landmarks)
image, landmarks = self.rotate(image, landmarks, angle=10)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
return image, landmarks
class FaceLandmarksDataset(Dataset):
def __init__(self, transform=None):
tree = ET.parse('ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml')
root = tree.getroot()
self.image_filenames = []
self.landmarks = []
self.crops = []
self.transform = transform
self.root_dir = 'ibug_300W_large_face_landmark_dataset'
for filename in root[2]:
self.image_filenames.append(os.path.join(self.root_dir, filename.attrib['file']))
self.crops.append(filename[0].attrib)
landmark = []
for num in range(68):
x_coordinate = int(filename[0][num].attrib['x'])
y_coordinate = int(filename[0][num].attrib['y'])
landmark.append([x_coordinate, y_coordinate])
self.landmarks.append(landmark)
self.landmarks = np.array(self.landmarks).astype('float32')
assert len(self.image_filenames) == len(self.landmarks)
def __len__(self):
return len(self.image_filenames)
def __getitem__(self, index):
image = cv2.imread(self.image_filenames[index], 0)
landmarks = self.landmarks[index]
if self.transform:
image, landmarks = self.transform(image, landmarks, self.crops[index])
landmarks = landmarks - 0.5
return image, landmarks
dataset = FaceLandmarksDataset(Transforms())
رسم تحويلات التدريب:
الآن دعونا نلقي نظرة سريعة على ما قمنا به حتى الآن. سوف نرسم مجموعة البيانات فقط من خلال إجراء التحويل الذي ستوفره الفئات المذكورة أعلاه لمجموعة البيانات:

تقسيم مجموعة البيانات للتدريب والتنبؤ بمعالم الوجه
الآن، للمضي قدمًا، سأقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة بيانات التحقق من الصحة:
# split the dataset into validation and test sets
len_valid_set = int(0.1*len(dataset))
len_train_set = len(dataset) - len_valid_set
print("The length of Train set is {}".format(len_train_set))
print("The length of Valid set is {}".format(len_valid_set))
train_dataset , valid_dataset, = torch.utils.data.random_split(dataset , [len_train_set, len_valid_set])
# shuffle and batch the datasets
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=8, shuffle=True, num_workers=4)
The length of Train set is 6000
The length of Valid set is 666
الآن سأستخدم ResNet18 كإطار عمل أساسي لدينا. سوف أقوم بتعديل الطبقتين الأولى والأخيرة بحيث تتناسب الطبقات بسهولة مع غرضنا:
class Network(nn.Module):
def __init__(self,num_classes=136):
super().__init__()
self.model_name='resnet18'
self.model=models.resnet18()
self.model.conv1=nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.model.fc=nn.Linear(self.model.fc.in_features, num_classes)
def forward(self, x):
x=self.model(x)
return x
import sys
def print_overwrite(step, total_step, loss, operation):
sys.stdout.write('\r')
if operation == 'train':
sys.stdout.write("Train Steps: %d/%d Loss: %.4f " % (step, total_step, loss))
else:
sys.stdout.write("Valid Steps: %d/%d Loss: %.4f " % (step, total_step, loss))
sys.stdout.flush()
تدريب الشبكة العصبية لاكتشاف معالم الوجه
سأستخدم الآن الخطأ التربيعي المتوسط بين معالم الوجه الحقيقية والمتوقعة:
torch.autograd.set_detect_anomaly(True)
network = Network()
network.cuda()
criterion = nn.MSELoss()
optimizer = optim.Adam(network.parameters(), lr=0.0001)
loss_min = np.inf
num_epochs = 10
start_time = time.time()
for epoch in range(1,num_epochs+1):
loss_train = 0
loss_valid = 0
running_loss = 0
network.train()
for step in range(1,len(train_loader)+1):
images, landmarks = next(iter(train_loader))
images = images.cuda()
landmarks = landmarks.view(landmarks.size(0),-1).cuda()
predictions = network(images)
# clear all the gradients before calculating them
optimizer.zero_grad()
# find the loss for the current step
loss_train_step = criterion(predictions, landmarks)
# calculate the gradients
loss_train_step.backward()
# update the parameters
optimizer.step()
loss_train += loss_train_step.item()
running_loss = loss_train/step
print_overwrite(step, len(train_loader), running_loss, 'train')
network.eval()
with torch.no_grad():
for step in range(1,len(valid_loader)+1):
images, landmarks = next(iter(valid_loader))
images = images.cuda()
landmarks = landmarks.view(landmarks.size(0),-1).cuda()
predictions = network(images)
# find the loss for the current step
loss_valid_step = criterion(predictions, landmarks)
loss_valid += loss_valid_step.item()
running_loss = loss_valid/step
print_overwrite(step, len(valid_loader), running_loss, 'valid')
loss_train /= len(train_loader)
loss_valid /= len(valid_loader)
print('\n--------------------------------------------------')
print('Epoch: {} Train Loss: {:.4f} Valid Loss: {:.4f}'.format(epoch, loss_train, loss_valid))
print('--------------------------------------------------')
if loss_valid < loss_min:
loss_min = loss_valid
torch.save(network.state_dict(), '/content/face_landmarks.pth')
print("\nMinimum Validation Loss of {:.4f} at epoch {}/{}".format(loss_min, epoch, num_epochs))
print('Model Saved\n')
print('Training Complete')
print("Total Elapsed Time : {} s".format(time.time()-start_time))
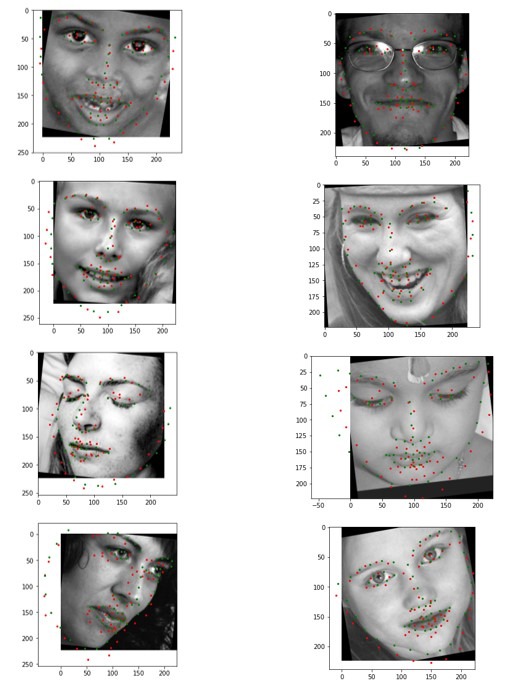
توقع معالم الوجه
دعنا الآن نستخدم النموذج الذي دربناه أعلاه على الصور التي لم يتم مشاهدتها مسبقاً في مجموعة البيانات:
start_time = time.time()
with torch.no_grad():
best_network = Network()
best_network.cuda()
best_network.load_state_dict(torch.load('/content/face_landmarks.pth'))
best_network.eval()
images, landmarks = next(iter(valid_loader))
images = images.cuda()
landmarks = (landmarks + 0.5) * 224
predictions = (best_network(images).cpu() + 0.5) * 224
predictions = predictions.view(-1,68,2)
plt.figure(figsize=(10,40))
for img_num in range(8):
plt.subplot(8,1,img_num+1)
plt.imshow(images[img_num].cpu().numpy().transpose(1,2,0).squeeze(), cmap='gray')
plt.scatter(predictions[img_num,:,0], predictions[img_num,:,1], c = 'r', s = 5)
plt.scatter(landmarks[img_num,:,0], landmarks[img_num,:,1], c = 'g', s = 5)
print('Total number of test images: {}'.format(len(valid_dataset)))
end_time = time.time()
print("Elapsed Time : {}".format(end_time - start_time))




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.