

هل تساءلت يومًا كيف تعرف ما إذا كان النص قد كتبه إنسان أم ذكاء اصطناعي؟ هل تعتقد أنك تستطيع معرفة الفرق؟ “هل يمكن أن تخبرني عن فصة ماسة كوهينور ؟”. حاول تخمين من أنتج هذا السؤال: إنسان أم ذكاء اصطناعي. مع التقدم في توليد اللغة الطبيعية، أصبح من الصعب تحديد الفرق. في هذه المقالة، سنبني نموذجًا للتعلم الآلي سيحدد ما إذا كان الإنسان أو ChatGPT قد قام بإنشاء النص. تبدو مثيرة للاهتمام، أليس كذلك؟ هيا بنا نبدأ.
جدول المحتويات
- ChatGPT
- تنفيذ نماذج التعلم الآلي
- مصنف الأشجار الاضافية
- خاتمة
ChatGPT
ChatGPT هو نظام ذكاء اصطناعي للمحادثة أو نظام تعلم آلي. يستمع ويتعلم ويتحدى. يأخذ هذا النظام نصًا بلغة طبيعية كمدخلات ويقدم ردودًا. يبدو الأمر كما لو كنت تتحدث مع شخص يتمتع بذكاء أكثر منك يمكنه الإجابة على جميع استفساراتك تقريبًا. هل تتخيل حتى أننا سنحصل على شيء كهذا في المستقبل؟ تم تطوير ChatGPT بواسطة OpenAI وتم إطلاقه في نوفمبر 2022. وهو يستخدم عملية تكرارية تأخذ في الاعتبار سياق مدخلات المستخدم، وتأخذ من المحادثات التي تم عرضها مسبقًا، وتستفيد من فهمها الجماعي لتلك المحادثات لتقديم استجابة جديدة. يستخدم التعليقات البشرية لتقليل الإجابات الضارة أو غير الصادقة أو المنحازة.
دعنا الآن نرى بعض الأمثلة لفهم كيفية استجابة ChatGPT.
المستخدم: ما رأيك في الأناناس على البيتزا؟
ChatGPT: أعتقد أن الأناناس على البيتزا هو مزيج مثير للاهتمام من النكهات. بعض الناس قد يعجبهم والبعض الآخر قد لا. ذلك يعتمد على الذوق الشخصي.
المستخدم: أحب القطط أكثر من الكلاب.
ChatGPT: فهمت. لماذا تحب القطط أكثر من الكلاب؟
المستخدم: أعتقد أن تغير المناخ مشكلة خطيرة.
ChatGPT: أتفق معك. تغير المناخ مشكلة خطيرة تؤثر على كل شخص على هذا الكوكب.
لنبدأ في بناء نموذجنا.
بيان المشكلة: سنبني نموذجًا للتعلم الآلي يمكنه تصنيف النص على أنه مكتوب بواسطة الإنسان أو يتم إنشاؤه بواسطة ChatGPT. يجب أن يكون قادرًا على التعامل مع أنواع متعددة من النصوص مثل الأسئلة والمقالات والقصص والنكات والرموز وما إلى ذلك.
وصف مجموعة البيانات
- إليك رابط مجموعة البيانات التي استخدمتها في هذا المشروع: Dataset
- تحتوي مجموعة البيانات هذه على أربعة أعمدة: نص text وإعادة صياغة paraphrases وفئة category ومصدر source.
- هذه النصوص مأخوذة من مصادر مختلفة.
- تمت إعادة صياغة كل من هذه النصوص لإنتاج خمسة نصوص أخرى.
- يحتوي على 419197 صفًا و 4 أعمدة.
تنفيذ نماذج التعلم الآلي
لنبدأ باستيراد مكتبات التعلم الآلي الأساسية الضرورية مثل numpy و pandas.
import numpy as np
import pandas as pd
استخدم pandas لتحميل مجموعة البيانات وإنشاء إطار بيانات.
df=pd.read_csv(r'C:\Users\Admin\Downloads\chatgpt_paraphrases.csv')
print(df)
print(df.shape)
#(419197, 4)

دعنا نعرض نصًا واحدًا ونقابله معاد صياغته لفهم مجموعة البيانات. في الإخراج، يمكننا أن نرى أن النص عبارة عن سؤال يسأل عن قصة ألماسة كوهينور. تمت إعادة صياغة الجملة نفسها بخمس طرق مختلفة بواسطة ChatGPT.
df['text'][1]
df['paraphrases'][1]

قم بإنشاء قاموس مع النصوص والفئات المقابلة لها مثل تحديد ما إذا كان النص قد تم إنشاؤه بواسطة البشر أو ChatGPT. سيتم تصنيفها بناءً على ما إذا كانت نصًا text أم إعادة صياغة paraphrase. إذا كان نصًا، فهذا يعني أنه تم إنشاؤه بواسطة الإنسان إذا كان معاد صياغته، فهذا يعني أنه تم إنشائه باستخدام ChatGPT. إذا قمت بعرض هذه الفئة، فستحصل على قاموس كما هو موضح في الصورة.
category={}
for i in range(len(df)):
chatgpt=df.iloc[i]["paraphrases"][1:-1].split(', ')
for j in chatgpt[:1]:
category[j[1:-1]]='chatgpt'
category[df.iloc[i]['text']]="human"
category

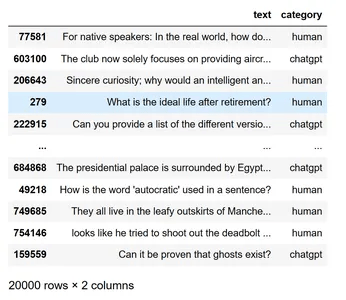
نحول قاموس الفئة هذا إلى إطار بيانات باستخدام pandas. قم بإنشاء عمودين كنص text وفئة category حيث تحتوي الفئة على قيمتين فريدتين مثل human و ChatGPT. قم بتبديل كل الصفوف في إطار البيانات لتجنب الضبط الزائد overfitting. سنأخذ أول 20000 صف بعد الخلط لتسهيل الأمر. دعونا نعرض إطار البيانات الذي تم إنشاؤه.
df=pd.DataFrame(category.items(),columns=["text","category"])
df=df.sample(frac=1)
df=df[:20000]
df
نعرض القيم الفريدة للبشر و ChatGPT. هناك 10340 نصًا تم إنشاؤها بواسطة البشر و 9660 نصًا تم إنشاؤها بواسطة ChatGPT.
df["category"].value_counts()

نأخذ متغيرين من المصفوفة X و Y. سيحتوي X على عمود النص في إطار البيانات وسيكون Y له عمود الفئة لإطار البيانات. هذا هو في الأساس المدخلات والمخرجات للنموذج. سنقدم X كمدخلات وسوف نتوقع Y كناتج.
X=df['text']
y=df['category']
تقسيم مجموعة البيانات إلى مجموعات بيانات التدريب والاختبار
بعد ذلك، قسّم مجموعة البيانات بأكملها باستخدام train_test_split إلى X_train و X_test و y_train و y_test لمزيد من المعالجة.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
دعونا نوجههم vectorize باستخدام متجه TF-IDF. إنها إحصائية رقمية تعكس مدى أهمية كلمة ما لمستند في مجموعة corpus. في استرجاع المعلومات والتنقيب عن النص، غالبًا ما يتم استخدامه كعامل ترجيح weighting factor. لهذا استوردنا TfidfVectorizer.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
اختيار أفضل مصنف
بدلاً من استخدام مصنف واحد محدد وبنائه، دعنا نأخذ مجموعة من المصنفات ونحسب درجة الدقة ودرجة f1 لمعرفة أفضل مصنف بينهم. استخدمنا هنا الانحدار اللوجستي logistic regression ، ومصنف المتجهات الداعمة support vector classifier، ومصنف شجرة القرار decision tree classifier ، ومصنف التصويت voting classier ، ومصنف KNN ، والغابة العشوائية Random forest ، والأشجار الإضافية Extra trees ، و Adaboost ، ومصنف التعبئة bagging classifier ، ومصنف تعزيز الانحدار gradient boosting classifier.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import GradientBoostingClassifier
lg = LogisticRegression(penalty='l1',solver='liblinear')
sv = SVC(kernel='sigmoid',gamma=1.0)
mnb = MultinomialNB()
dtc = DecisionTreeClassifier(max_depth=5)
knn = KNeighborsClassifier()
rfc = RandomForestClassifier(n_estimators=50,random_state=2)
etc = ExtraTreesClassifier(n_estimators=50,random_state=2)
abc = AdaBoostClassifier(n_estimators=50,random_state=2)
bg = BaggingClassifier(n_estimators=50,random_state=2)
gbc = GradientBoostingClassifier(n_estimators=50,random_state=2)
نحسب الآن درجة الدقة ودرجة f1 لهذه المصنفات.
def prediction(model,X_train,X_test,y_train,y_test):
model.fit(X_train,y_train)
pr = model.predict(X_test)
acc_score = metrics.accuracy_score(y_test,pr)
f1= metrics.f1_score(y_test,pr,average="binary", pos_label="chatgpt")
return acc_score,f1
acc_score = {}
f1_score={}
clfs= {
'LR':lg,
'SVM':sv,
'DTC':dtc,
'KNN':knn,
'RFC':rfc,
'ETC':etc,
'ABC':abc,
'BG':bg,
'GBC':gbc,
}
for name,clf in clfs.items():
acc_score[name],f1_score[name]= prediction(clf,X_train_tfidf,X_test_tfidf,y_train,y_test)
#View those scores
acc_score
f1_score

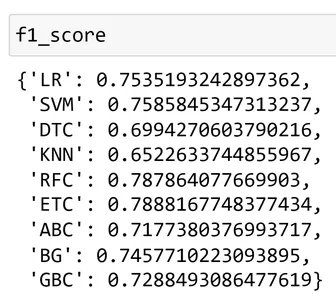
إذا قارنا هذه الدرجات، فقد حصلنا على أعلى تصنيف لـ ExtraTrees Classifier (ETC). لذلك سنستخدم مصنف الأشجار الإضافي هذا لتدريب النموذج والتنبؤ بالمستقبل. لتدريب النموذج باستخدام طريقة fit.
نموذج التعلم الآلي – مصنف الأشجار الإضافية
مصنف الأشجار الإضافية ExtraTrees Classifier (ETC): يعتبر مصنف الأشجار الإضافي نوعًا من أساليب تعلم المجموعات التي تستخدم عدة أشجار قرار عشوائية لتحسين الدقة التنبؤية والتحكم في الضبط الزائد overfitting. ويسمى أيضًا مصنف الأشجار العشوائية للغاية Extremely Randomized Trees Classifier. إنه يختلف عن أشجار القرار الكلاسيكية في طريقة بنائها. تحتوي أشجار القرار العادية على بعض العيوب مثل الضبط الزائد والتباين العالي high variance. لذلك لتجنبها يتم تقديم طرق مختلفة للتعلم الجماعي ensemble learning. مصنف الأشجار الإضافية هو واحد من بينها. بدلاً من استخدام عينات التمهيد bootstrap samples، يستخدم برنامج Extra Trees Classifier مجموعة البيانات الأصلية الكاملة لكل شجرة، ولكن مع أخذ عينات عشوائية من الميزات لكل تقسيم. وأيضًا بدلاً من العثور على نقطة الانقسام المثلى لكل ميزة، يقوم برنامج Extra Trees Classifier بتحديد عشوائي لنقطة الانقسام من توزيع منتظم داخل نطاق الميزة. هذه تقنية قوية لتعلم الآلة يمكنها التعامل مع مشاكل التصنيف المعقدة بدقة عالية وضبط زائد قليل.
etc.fit(X_train_tfidf,y_train)
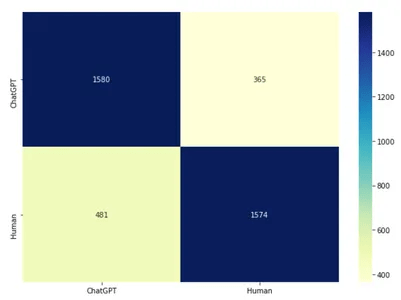
مصفوفة الارتباك
توقع مجموعة بيانات الاختبار واحصل على مصفوفة الارتباك confusion matrix. مصفوفة الارتباك هذه هي في الأساس جدول يحدد أداء الخوارزمية. هنا بالنسبة لمسألة التصنيف لدينا، ستعطي أربع قيم. القيم الموجبة الكاذبة (FP) والموجبة الحقيقية (TP) والسلبية الكاذبة (FN) والسلبية الحقيقية (TN) هي القيم الأربع التي ستعطيها. سنقوم أيضًا برسم مصفوفة الارتباك هذه. لاستيراد matplotlib و seaborn للتصورات المرئية.
from sklearn.metrics import confusion_matrix
y_pred =etc.predict(X_test_tfidf)
cm = confusion_matrix(y_test, y_pred)
print(cm)
import seaborn as sn
import matplotlib.pyplot as plt
confusion_matrix = pd.DataFrame(cm, index = [i for i in ["ChatGPT","Human"]],
columns = [i for i in ["ChatGPT","Human"]])
plt.figure(figsize = (20,14))
sn.heatmap(confution_matrix, annot=True,cmap="YlGnBu", fmt='g')
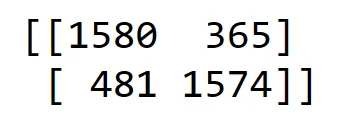
الآن دعونا نرى النتائج المتوقعة بواسطة النموذج. في الخطوة السابقة، توقعنا النتائج وحفظناها في y_pred. هذا y_pred عبارة عن مصفوفة. لذا قمنا بتحويله إلى إطار بيانات باستخدام pandas وأعدنا تسمية العمود من 0 إلى “الفئة المتوقعة category predicted” ونعرضه.
y_preddf=pd.DataFrame(y_pred)
y_preddf.rename(columns={0:'category predicted'},inplace=True)
y_preddf
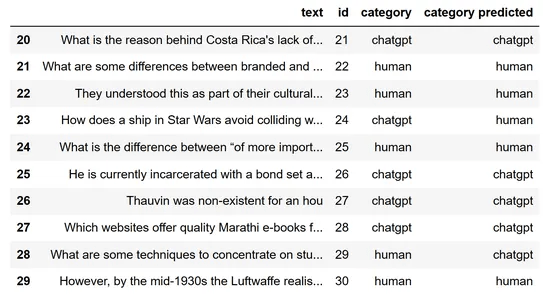
المقارنة
لمقارنة النتائج الفعلية والنتائج المتوقعة، دعنا ننضم إلى إطارات البيانات. وعرض إطار البيانات. شاهدت هنا الصفوف من 20 إلى 30. في النتائج، يمكنك أن ترى أنه تم توقع جميع الصفوف تقريبًا بشكل صحيح بينما تم توقع بعضها بشكل غير صحيح. بالنسبة للنص الثالث والعشرين، توقع نموذجنا أنه تم إنشاؤه بواسطة إنسان ولكن في الواقع، تم إنشاؤه بواسطة ChatGPT.
x_testdf=pd.DataFrame(X_test)
y_testdf=pd.DataFrame(y_test)
x_testdf['id'] = range(1, len(x_testdf) + 1)
y_testdf['id'] = range(1, len(y_testdf) + 1)
y_preddf['id'] = range(1, len(y_preddf) + 1)
join1=y_testdf.merge(x_testdf, how = 'inner' ,indicator=False)
join_df=join1.merge(y_preddf, how = 'inner' ,indicator=False)
join_df[20:30]
إيجاد الدقة
لذا فإن هذه النصوص المصنفة بشكل غير صحيح هي إيجابيات كاذبة وسلبيات كاذبة. دعونا نرى دقة نموذجنا. حصلنا على دقة 78.7٪. يمكن تحسين ذلك باستخدام عدد كبير من الصفوف أثناء التدريب وعن طريق زيادة عدد الفترات (epochs). لقد أخذنا 20000 صف و 10 فترات فقط لتجربتنا.
accuracy_score=metrics.accuracy_score(y_pred,y_test)*100
accuracy_score
#78.7
حان الوقت الآن لاختبار نموذجنا بنصوصنا الخاصة بدلاً من نصوص من مجموعة البيانات. لقد قدمت أربعة نصوص مختلفة. أولاً، أعطاني النصان الأولان البشر على الرغم من إعطائي ChatGPT في المثال الثاني. يخبرنا هذا بمدى دقة توقع نموذجنا. في المثال الثالث، استخدمت بعض الكلمات مثل دليل خطوة بخطوة step-by-step guide، وفي المثال الأخير قدمت نصًا مثل التوصية ببعض مواقع الويب التي تشبه ChatGPT وتنبأ نموذجنا أيضًا باسم ChatGPT.
input=['Hello!! This is Amrutha']
vect_input=vectorizer.transform(input)
etc.predict(vect_input)
#array(['human'], dtype=object)
input=['Hello!! This is chatgpt']
vect_input=vectorizer.transform(input)
etc.predict(vect_input)
#array(['human'], dtype=object)
input=['Can you please provide a step by step guide for writing articles on analytics vidhya']
vect_input=vectorizer.transform(input)
etc.predict(vect_input)
#array(['chatgpt'], dtype=object)
input=['These are the websites for watching movies that I can recommend you']
vect_input=vectorizer.transform(input)
etc.predict(vect_input)
#array(['chatgpt'], dtype=object)
الخاتمة
في الوقت الحاضر، الكلمة التي نستمع إليها كثيرًا هي ChatGPT. يتم استخدام هذا حرفياً في كل مكان بما في ذلك من قبل الطلاب والمهندسين والكتاب والمعلمين والجميع. بسبب الإمكانات التي يتمتع بها في توليد إجابات رائعة على استفساراتهم. تبدو هذه النصوص التي تم إنشاؤها بواسطة ChatGPT تمامًا مثل البشر ولا يمكننا نحن البشر معرفة الفرق بمجرد النظر إلى تلك النصوص. لذا لتمييز النصوص التي تم إنشاؤها بواسطة ChatGPT ، قمنا ببناء نموذج يخبر بنجاح إما “الإنسان” أو “ChatGPT”.
- ChatGPT هو نموذج لغة ذكاء اصطناعي يمكنه إنشاء نصوص شبيهة بالبشر حول مواضيع ومهام مختلفة.
- لقد استخدمنا مجموعة بيانات تحتوي على عدد كبير من النصوص البشرية والنصوص التي تم إنشاؤها بواسطة ChatGPT لتدريب نموذجنا.
- لقد اخترنا أفضل مصنف وهو مصنف الأشجار الإضافي لتدريب نموذجنا.
- نحن بحاجة إلى توخي الحذر من الآثار الأخلاقية والاجتماعية لـ ChatGPT وإمكانية الإيجابيات الكاذبة والسلبيات الكاذبة في نموذج التعلم الآلي الخاص بنا.
آمل أن تكون قد وجدت هذه المقالة مفيدة.



