
- ما هو التحقق المتقاطع؟
- تنفيذ التحقق المتقاطع مع بايثون
- مزايا وعيوب استخدام التحقق المتقاطع
في التعلم الآلي، يعد التحقق المتقاطع Cross-validation طريقة إحصائية لتقييم أداء التعميم generalization الأكثر استقرارًا وشمولية من استخدام تقسيم مجموعة البيانات إلى مجموعة تدريب واختبار. في هذه المقالة، سوف نتعرف على ماهية التحقق المتقاطع وكيفية استخدامه للتعلم الآلي باستخدام لغة برمجة بايثون.
ما هو التحقق المتقاطع ؟
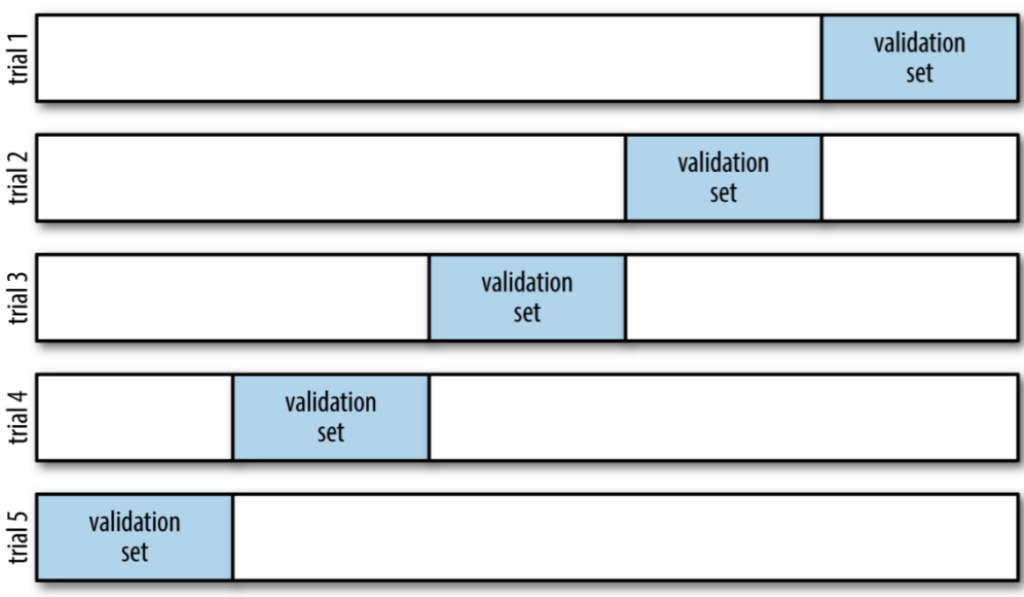
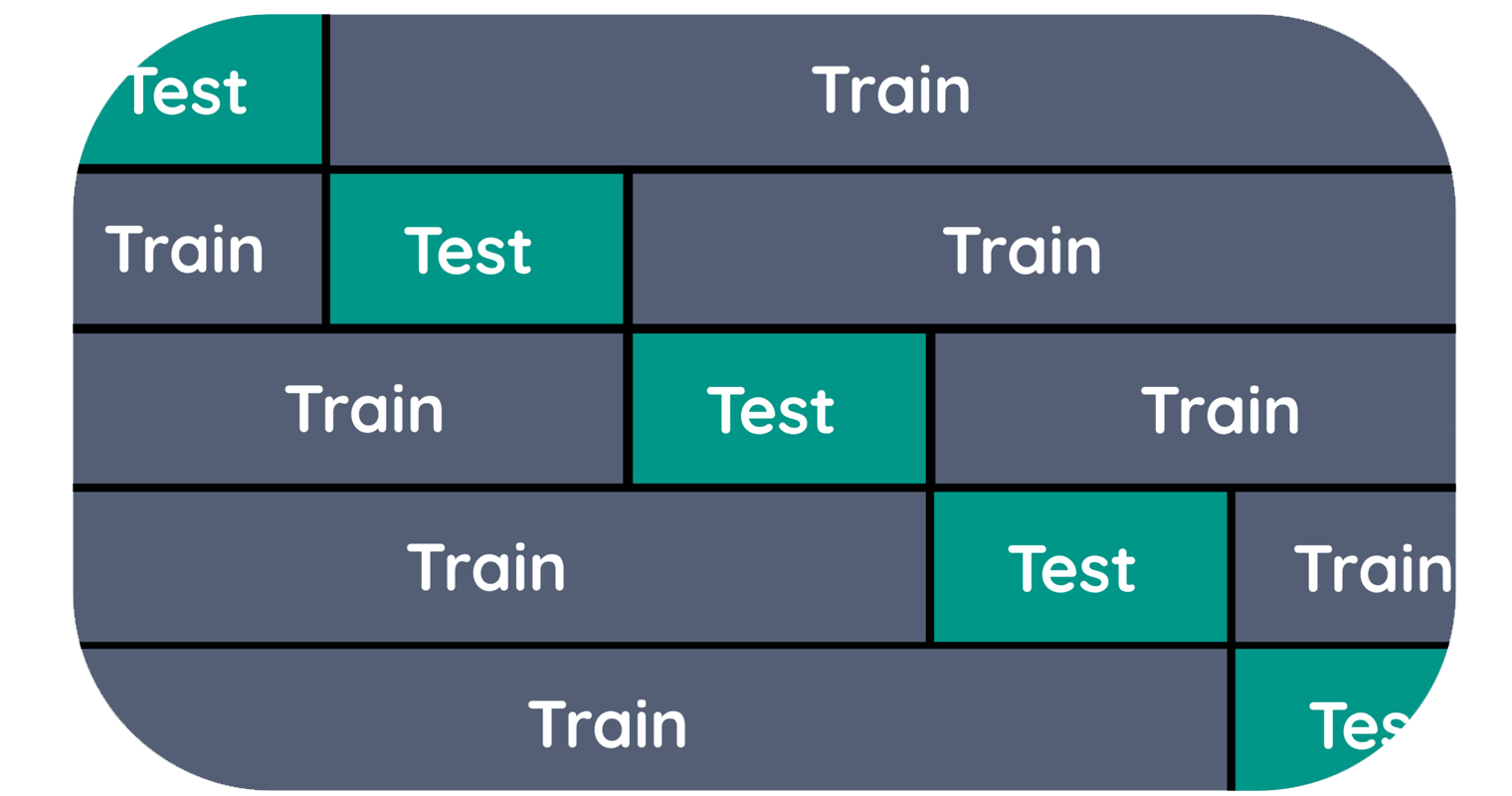
في التحقق المتقاطع، يتم تقسيم البيانات بدلاً من ذلك عدة مرات ويتم تدريب نماذج متعددة. الإصدار الأكثر استخدامًا من التحقق المتقاطع هو التحقق المتقاطع K من المرات k-times cross-validation، حيث k هو رقم يحدده المستخدم، عادةً 5 أو 10.
في عملية التحقق المتقاطع الخماسي five-way cross-validation، يتم تقسيم البيانات أولاً إلى خمسة أجزاء متساوية الحجم (تقريبًا) تسمى الطيات folds. ثم يتم تشكيل سلسلة من النماذج. يتم تدريب النموذج الأول باستخدام الطية الأولى كمجموعة اختبار، ويتم استخدام الطيات المتبقية (2-5) كمجموعة تدريب.
تم إنشاء النموذج باستخدام بيانات من الطيات من 2 إلى 5، ثم يتم تقييم الدقة في الطية 1. ثم يتم إنشاء نموذج آخر، هذه المرة باستخدام الطية 2 كمجموعة اختبار والبيانات من الطيات 1 و3 و4 و5 كمجموعة تدريب.
تتكرر هذه العملية باستخدام الطيات 3 و4 و5 كمجموعات اختبار. لكل قسم من هذه الأقسام الخمسة للبيانات في مجموعات التدريب والاختبار، نحسب الدقة. في النهاية، جمعنا خمس قيم للدقة.
تنفيذ التحقق المتقاطع مع بايثون
يمكننا بسهولة تنفيذ عملية التحقق المتقاطع باستخدام لغة برمجة بايثون باستخدام مكتبة Scikit-Learn في بايثون.
يتم تنفيذ التحقق المتقاطع في scikit-Learn باستخدام دالة cross_val_score للوحدة model_selection. معلمات دالة cross_val_score هي النموذج الذي نريد تقييمه، وبيانات التدريب، وتسميات الحقيقة الأساسية. دعونا نقيم الانحدار اللوجستي LogisticRegression في مجموعة بيانات iris:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
logreg = LogisticRegression()
scores = cross_val_score(logreg, iris.data, iris.target)
print("Cross-validation scores: {}".format(scores))

بشكل افتراضي، ينفذ cross_val_score تحققًا متقاطعاً ثلاثيًا، ويعيد ثلاث قيم للدقة. يمكننا تعديل عدد الطيات المستخدمة من خلال تعديل معامل cv:
scores = cross_val_score(logreg, iris.data, iris.target, cv=5)
print("Cross-validation scores: {}".format(scores))

من الطرق الشائعة لتلخيص دقة التحقق المتقاطع حساب المتوسط mean:
print("Average cross-validation score: {:.2f}".format(scores.mean()))

مزايا وعيوب استخدام التحقق المتقاطع
هناك العديد من المزايا لاستخدام التحقق المتقاطع بدلاً من قسم واحد في تدريب واحد ومجموعة اختبار واحدة. بادئ ذي بدء، تذكر أن train_test_split يقوم بتقسيم عشوائي للبيانات.
تخيل أننا “محظوظون” في تقسيم البيانات عشوائيًا، وتنتهي جميع الأمثلة التي يصعب تصنيفها في مجموعة التدريب. في هذه الحالة، ستحتوي مجموعة الاختبار فقط على أمثلة “بسيطة”، وستكون دقة مجموعة الاختبار الخاصة بنا غير واقعية.
على العكس من ذلك، إذا كنا “غير محظوظين”، فربما نكون قد وضعنا عشوائيًا جميع الأمثلة التي يصعب تصنيفها في مجموعة الاختبار وبالتالي نحصل على درجة غير واقعية.
ومع ذلك، عند استخدام التحقق المتقاطع، سيكون كل مثال في مجموعة الاختبار مرة واحدة بالضبط: كل مثال في إحدى الطيات، وكل طية هي مجموعة الاختبار مرة واحدة. لذلك، يجب أن يعمم النموذج جيدًا على جميع العينات في مجموعة البيانات حتى تكون جميع درجات التحقق المتقاطع (ومتوسطها) عالية.
يوفر وجود تقسيمات متعددة للبيانات أيضًا معلومات حول حساسية نموذجنا لاختيار مجموعة بيانات التدريب. بالنسبة لمجموعة بيانات iris، رأينا دقة تتراوح بين 90٪ و100٪. هذا نطاق كبير، ويعطينا فكرة عن كيفية عمل النموذج في أسوأ سيناريو وأفضل سيناريو عند تطبيقه على البيانات الجديدة.
ميزة أخرى للتحقق المتقاطع من استخدام قسم واحد للبيانات هي أننا نستخدم بياناتنا بكفاءة أكبر. عند استخدام train_test_split، فإننا عادةً ما نستخدم 75٪ من البيانات للتدريب و 25٪ من البيانات للتقييم.
عند استخدام التحقق المتقاطع الخماسي، في كل تكرار يمكننا استخدام أربعة أخماس البيانات (80٪) لتناسب النموذج. عند استخدام 10 عمليات تحقق متقاطعة، يمكننا استخدام تسعة أعشار البيانات (90٪) لملاءمة النموذج. ستؤدي المزيد من البيانات بشكل عام إلى نماذج أكثر دقة.
العيب الرئيسي هو الزيادة في التكاليف الحسابية. نظرًا لأننا نقوم حاليًا بتدريب نماذج k بدلاً من نموذج واحد، فإن التحقق المتقاطع سيكون أبطأ بحوالي k مرة من القيام بتقسيم واحد للبيانات.
الاستنتاج
باستخدام متوسط التحقق المتقاطع، يمكننا أن نستنتج أننا نتوقع أن يكون النموذج دقيقًا بنسبة 96٪ في المتوسط. بالنظر إلى الدرجات الخمسة الناتجة عن التحقق المتقاطع الخماسي، يمكننا أيضًا أن نستنتج أن هناك تباينًا كبيرًا نسبيًا في الدقة بين الطيات، تتراوح من دقة 100٪ إلى 90٪ دقة.
قد يعني هذا أن النموذج يعتمد بشكل كبير على الطيات المحددة المستخدمة للتدريب، ولكنه قد يكون أيضًا نتيجة لصغر حجم مجموعة البيانات.
أتمنى أن تكون قد أحببت هذه المقالة حول ما هو التحقق المتقاطع، وتنفيذه باستخدام بايثون وفوائده وعيوبه.



