- تصنيف زهرة Iris
- تصنيف زهرة Iris باستخدام بايثون
- الخطوة 1 : تحميل البيانات:
- الخطوة 2: تحليل مجموعة البيانات وتصورها:
- الخطوة 3: نموذج التدريب:
- الخطوة 4: تقييم النموذج:
- الخطوة 5: اختبار النموذج:
- الملخص
يعد تصنيف زهرة Iris أحد أكثر دراسات الحالة شيوعًا بين مجتمع علوم البيانات. قام كل مبتدئ في علم البيانات تقريبًا بحل دراسة الحالة هذه مرة واحدة في حياتهم. هنا، يتم إعطاؤك القياسات المرتبطة بكل نوع من أنواع زهرة Iris وبناءً على هذه البيانات، يجب عليك تدريب نموذج التعلم الآلي لمهمة تصنيف زهور Iris. لذلك إذا كنت جديدًا على التعلم الآلي ولم تحاول أبدًا حل دراسة الحالة هذه، فهذه المقالة مناسبة لك. في هذه المقالة، سوف أطلعك على تصنيف زهرة Iris مع التعلم الآلي باستخدام Python.
تصنيف زهرة Iris
زهرة القزحية لها ثلاثة أنواع. setosa و versicolor و virginica ، والتي تختلف حسب قياساتها. افترض الآن أن لديك قياسات زهور Iris وفقًا لنوعها، وهنا تتمثل مهمتك في تدريب نموذج تعلم آلي يمكنه التعلم من قياسات أنواع Iris وتصنيفها.
آمل أن تكون قد فهمت الآن دراسة الحالة الخاصة بتصنيف زهرة Iris. على الرغم من أن مكتبة Scikit-Learn توفر مجموعة بيانات لتصنيف زهرة Iris، يمكنك أيضًا تنزيل مجموعة البيانات نفسها من هنا لمهمة تصنيف زهرة Iris باستخدام التعلم الآلي. الآن في القسم أدناه، سأطلعك على كيفية تصنيف أنواع زهرة Iris بالتعلم الآلي باستخدام لغة برمجة Python.

تصنيف زهرة Iris باستخدام بايثون
خطوات تصنيف زهرة Iris:
- تحميل البيانات.
- تحليل ورسم مجموعة البيانات.
- تدريب النموذج.
- تقييم النموذج.
- اختبار النموذج.
الخطوة 1 : تحميل البيانات:
# DataFlair Iris Flower Classification
# Import Packages
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
%matplotlib inline
أولاً، قمنا باستيراد بعض الحزم الضرورية للمشروع.
- سيتم استخدام Numpy لأي عمليات حسابية.
- سنستخدم Matplotlib و seaborn لرسم البيانات.
- تساعد Pandas في تحميل البيانات من مصادر مختلفة مثل التخزين المحلي وقاعدة البيانات وملف Excel وملف CSV وما إلى ذلك.
columns = ['Sepal length', 'Sepal width', 'Petal length', 'Petal width', 'Class_labels']
# Load the data
df = pd.read_csv('iris.data', names=columns)
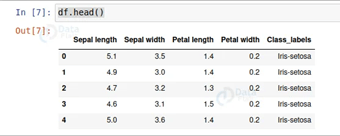
df.head()
بعد ذلك، نقوم بتحميل البيانات باستخدام pd.read_csv() وتعيين اسم العمود وفقًا لمعلومات بيانات Iris.
- يقرأ Pd.read_csv ملفات CSV. يشير CSV إلى قيمة مفصولة بفاصلة.
- يعرض df.head() الصفوف الخمسة الأولى فقط من جدول مجموعة البيانات.
- جميع القيم العددية بالسنتيمتر.
الخطوة 2: تحليل مجموعة البيانات وتصورها:
دعنا نرى بعض المعلومات حول مجموعة البيانات.
# Some basic statistical analysis about the data
df.describe()
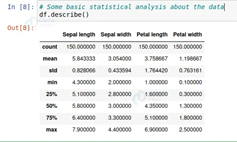
من هذا الوصف، يمكننا رؤية جميع الأوصاف المتعلقة بالبيانات، مثل متوسط الطول والعرض، والحد الأدنى للقيمة، والحد الأقصى للقيمة، وقيمة التوزيع 25٪، و 50٪، و 75٪، إلخ.
دعونا نرسم مجموعة البيانات.
# Visualize the whole dataset
sns.pairplot(df, hue='Class_labels')
لنرسم مجموعة البيانات بأكملها، استخدمنا طريقة مخطط الزوج من seaborn. يرسم معلومات مجموعة البيانات بأكملها.
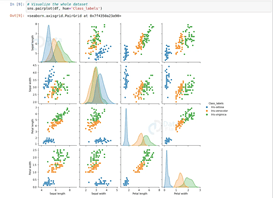
- من هذا الرسم، يمكننا أن نقول أن iris-setosa منفصلة جيدًا عن الزهرتين الأخريين.
- و iris virginica هي أطول زهرة و iris setosa هي الأقصر.
- دعنا الآن نرسم متوسط كل ميزة لكل فئة.
# Separate features and target
data = df.values
X = data[:,0:4]
Y = data[:,4]
هنا قمنا بفصل الميزات عن القيمة المستهدفة.
# Calculate average of each features for all classes
Y_Data = np.array([np.average(X[:, i][Y==j].astype('float32')) for i in range (X.shape[1])
for j in (np.unique(Y))])
Y_Data_reshaped = Y_Data.reshape(4, 3)
Y_Data_reshaped = np.swapaxes(Y_Data_reshaped, 0, 1)
X_axis = np.arange(len(columns)-1)
width = 0.25
- يحسب Np.average المتوسط من المصفوفة.
- استخدمنا هنا حلقتين for داخل قائمة. هذا هو المعروف باسم list comprehension.
- يساعد list comprehension على تقليل عدد أسطر الكود.
- Y_Data عبارة عن مصفوفة احادية البعد، لكن لدينا 4 ميزات لكل 3 فئات. لذلك قمنا بإعادة تشكيل Y_Data إلى مصفوفة على شكل (3 ، 4).
- ثم نقوم بتغيير محور المصفوفة المعاد تشكيلها.
# Plot the average
plt.bar(X_axis, Y_Data_reshaped[0], width, label = 'Setosa')
plt.bar(X_axis+width, Y_Data_reshaped[1], width, label = 'Versicolour')
plt.bar(X_axis+width*2, Y_Data_reshaped[2], width, label = 'Virginica')
plt.xticks(X_axis, columns[:4])
plt.xlabel("Features")
plt.ylabel("Value in cm.")
plt.legend(bbox_to_anchor=(1.3,1))
plt.show()
استخدمنا matplotlib لإظهار المتوسطات في مخطط شريطي.

استخدمنا matplotlib لإظهار المتوسطات في مخطط شريطي.
الخطوة3: نموذجالتدريب:
# Split the data to train and test dataset.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
باستخدام train_test_split، قمنا بتقسيم البيانات بأكملها إلى مجموعات بيانات تدريب واختبار. سنستخدم لاحقًا مجموعة بيانات الاختبار للتحقق من دقة النموذج.
# Support vector machine algorithm
from sklearn.svm import SVC
svn = SVC()
svn.fit(X_train, y_train)
- هنا قمنا باستيراد مصنف آلة المتجهات الداعمة SVM من scikit-Learn.
- ثم أنشأنا كائنًا وأطلقنا عليه اسم svn.
- بعد ذلك، نقوم بتغذية مجموعة بيانات التدريب في الخوارزمية باستخدام طريقة svn.fit().
الخطوة4: تقييمالنموذج:
# Predict from the test dataset
predictions = svn.predict(X_test)
# Calculate the accuracy
from sklearn.metrics import accuracy_score
accuracy_score(y_test, predictions)
- الآن نتوقع الفئات من مجموعة بيانات الاختبار باستخدام نموذجنا المدرب.
- ثم نتحقق من درجة الدقة للفئات المتوقعة.
- accuracy_score() تأخذ القيم الحقيقية والقيم المتوقعة وتعيد النسبة المئوية للدقة.
المخرجات:
0.9666666666666667
الدقة أعلى من 96٪.
دعنا الآن نرى تقرير التصنيف المفصل بناءً على مجموعة بيانات الاختبار.
# A detailed classification report
from sklearn.metrics import classification_report
print(classification_report(y_test, predictions))
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 9
Iris-versicolor 1.00 0.83 0.91 12
Iris-virginica 0.82 1.00 0.90 9
accuracy 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.95 0.93 0.93 30
- يقدم تقرير التصنيف تقريرًا مفصلاً عن التنبؤ.
- تحدد precision نسبة الإيجابيات الحقيقية إلى مجموع الإيجابيات الحقيقية الإيجابية والخاطئة.
- يحدد Recall نسبة الموجب الحقيقي إلى مجموع الموجب الحقيقي والسالب الخاطئ.
- F1-score هي متوسط precision وقيمة recall.
- Support هو عدد التكرارات الفعلية للفئة في مجموعة البيانات المحددة.
الخطوة 5: اختبار النموذج:
X_new = np.array([[3, 2, 1, 0.2], [ 4.9, 2.2, 3.8, 1.1 ], [ 5.3, 2.5, 4.6, 1.9 ]])
#Prediction of the species from the input vector
prediction = svn.predict(X_new)
print("Prediction of Species: {}".format(prediction))
- يمكننا حفظ النموذج باستخدام شكل pickle.
- ومرة أخرى يمكننا تحميل النموذج في أي برنامج آخر باستخدام pickle واستخدامه باستخدام model.prict للتنبؤ ببيانات Iris.
الملخص
في هذا المشروع، تعلمنا تدريب نموذج التعلم الآلي الخاص بنا تحت الإشراف باستخدام مشروع Iris Flower Classification مع التعلم الآلي. من خلال هذا المشروع، تعرفنا على التعلم الآلي، وتحليل البيانات، والتمثيل المرئي للبيانات، وإنشاء النماذج، وما إلى ذلك.