

تقرير صدر السعادة العالمي World Happiness Report الأول في 1 أبريل 2012 كنص تأسيسي لا اجتماع الأمم المتحدة رفيع المستوى: الرفاهية Well-being والسعادة Happiness: تحديد نموذج اقتصادي جديد، وجذب الانتباه الدولي.
حدد التقرير حالة السعادة في العالم، وأسباب السعادة والبؤس، والآثار السياسية التي أبرزتها دراسات الحالة. في عام 2013، تم إصدار التقرير الثاني للسعادة العالمية، وذلك تم إصداره على أساس سنوي عام 2014.
يستخدم التقرير بشكل أساسي بيانات استطلاع غالوب العالمي. كل تقرير سنوي متاح للجمهور لتنزيله على موقع تقرير السعادة العالمي.
الطرق والفلسفة
تستند تصنيفات السعادة الوطنية على مسح سلم كانتريل Cantrell ladder survey. يُطلب من العينات الممثلة على المستوى الوطني من المستجيبين التفكير في سلم، بحيث تكون أفضل حياة ممكنة لهم هي 10، وأسوأ حياة ممكنة هي 0.
ثم يُطلب منهم تقييم حياتهم الحالية على مقياس من 0 إلى 10. يربط التقرير النتائج بعوامل الحياة المختلفة.
في التقارير، يصف الخبراء في المجالات بما في ذلك الاقتصاد وعلم النفس وتحليل المسح والإحصاءات الوطنية كيف يمكن استخدام قياسات الرفاهية بشكل فعال لتقييم تقدم الدول ومواضيع أخرى.
يتم تنظيم كل تقرير من خلال فصول تتعمق في القضايا المتعلقة بالسعادة، بما في ذلك المرض العقلي، والفوائد الموضوعية للسعادة، وأهمية الأخلاق، والآثار السياسية، والروابط مع نهج منظمة التعاون الاقتصادي والتنمية (OECD) قياس الرفاه الشخصي والجهود الدولية والوطنية الأخرى.
في مشروع علوم البيانات هذا، سأُنشئ تقريرًا عن سعادة العالم باستخدام لغة بايثون حول بيانات عام 2019 التي قدمتها الأمم المتحدة.
لنبدأ باستيراد المكتبات:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
قم بتنزيل مجموعة البيانات.
إبراز القيم القصوى maximum values لكل سمة attribute في مجموعة البيانات
df=pd.read_csv('2019.csv')
df.head()
def highlight_max(s):
is_max = s == s.max()
return ['background-color: limegreen' if v else '' for v in is_max]
df.style.apply(highlight_max)
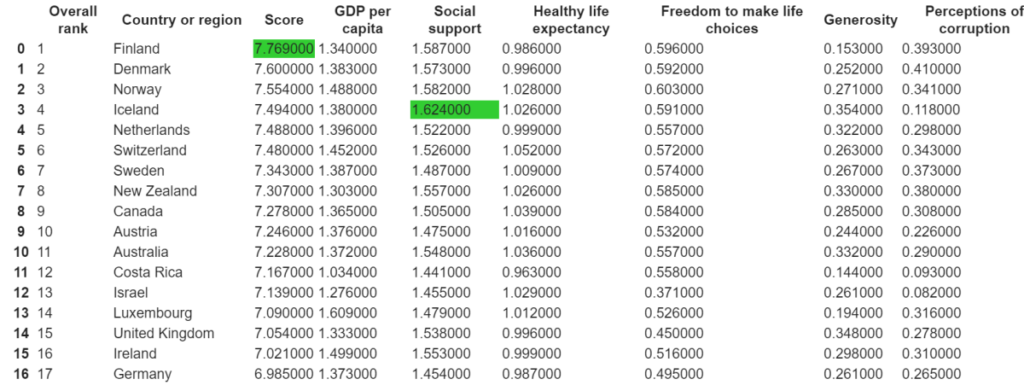
التحقق من شكل مجموعة البيانات الخاصة بنا:
df.shape
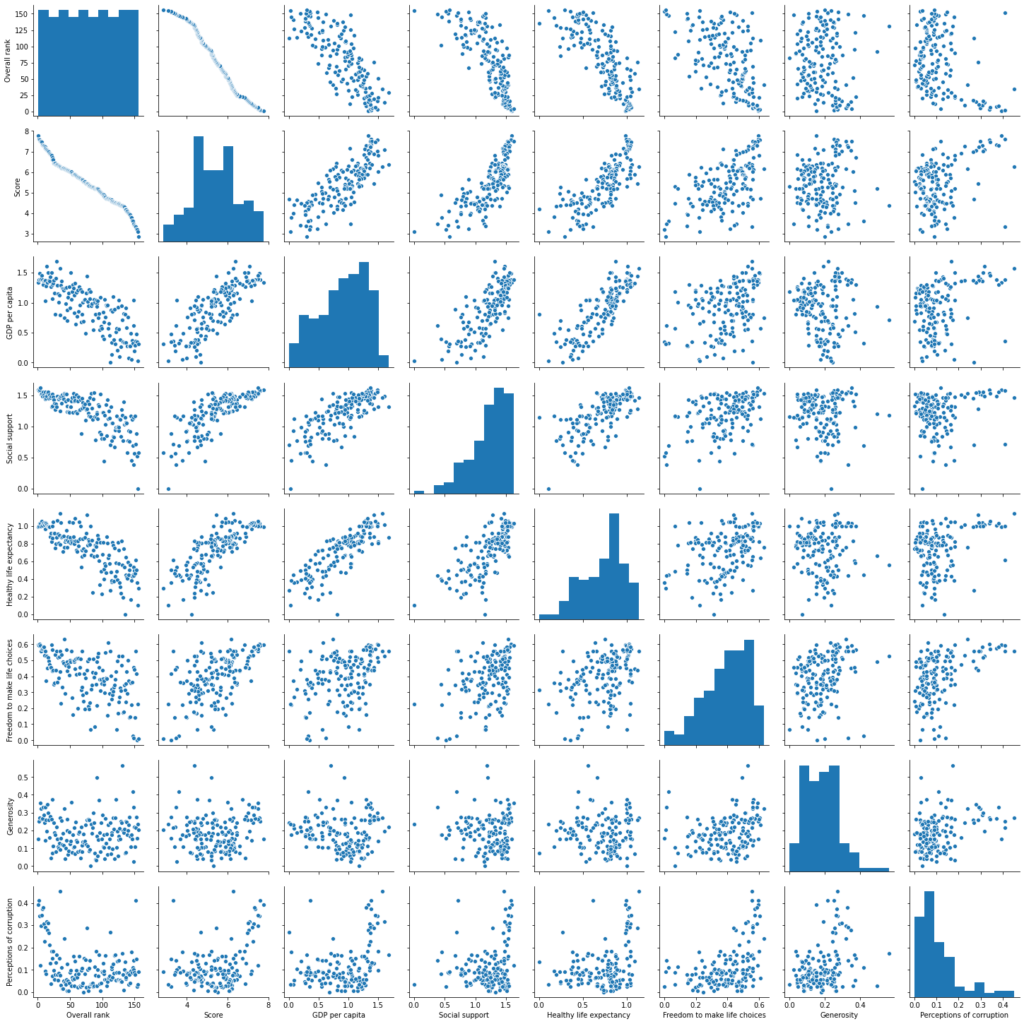
رسم العلاقات الزوجية في مجموعة البيانات:
import seaborn as sns
sns.pairplot(df)
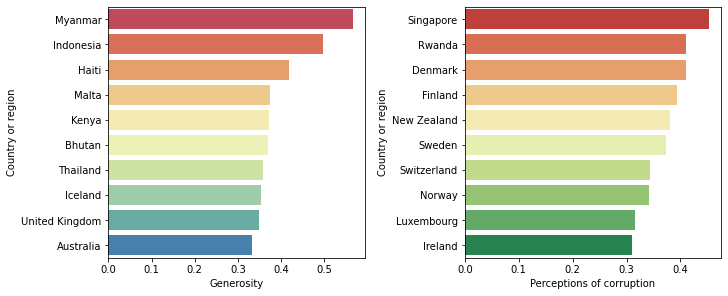
أهم 10 دول لكل سمة:
fig, axes = plt.subplots(nrows=2, ncols=2,constrained_layout=True,figsize=(12,8))
sns.barplot(x='GDP per capita',y='Country or region',data=df.nlargest(10,'GDP per capita'),ax=axes[0,0],palette="Blues_d")
sns.barplot(x='Social support' ,y='Country or region',data=df.nlargest(10,'Social support'),ax=axes[0,1],palette="YlGn")
sns.barplot(x='Healthy life expectancy' ,y='Country or region',data=df.nlargest(10,'Healthy life expectancy'),ax=axes[1,0],palette='OrRd')
sns.barplot(x='Freedom to make life choices' ,y='Country or region',data=df.nlargest(10,'Freedom to make life choices'),ax=axes[1,1],palette='YlOrBr')

fig, axes = plt.subplots(nrows=1, ncols=2,constrained_layout=True,figsize=(10,4))
sns.barplot(x='Generosity' ,y='Country or region',data=df.nlargest(10,'Generosity'),ax=axes[0],palette='Spectral')
sns.barplot(x='Perceptions of corruption' ,y='Country or region',data=df.nlargest(10,'Perceptions of corruption'),ax=axes[1],palette='RdYlGn')
الآن أريد أن أعطي تصنيفًا لكل بلد على أنه مرتفع High ومتوسط Mid ومنخفض Low وفقًا لدرجات السعادة الخاصة بهم، وبالتالي علينا معرفة الحد الذي يجب أن تكمن فيه هذه الفئات.
print('max:',df['Score'].max())
print('min:',df['Score'].min())
add=df['Score'].max()-df['Score'].min()
grp=round(add/3,3)
print('range difference:',(grp))

low=df['Score'].min()+grp
mid=low+grp
print('upper bound of Low grp',low)
print('upper bound of Mid grp',mid)
print('upper bound of High grp','max:',df['Score'].max())
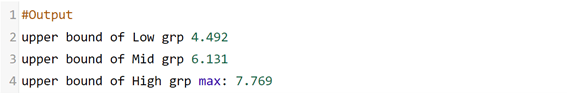
أخيرًا إضافة عمود جديد Category إلى مجموعة البيانات وتوزيع المستويات عالية High ومنخفضة Low ومتوسطة Mid.
cat=[]
for i in df.Score:
if(i>0 and i<low):
cat.append('Low')
elif(i>low and i<mid):
cat.append('Mid')
else:
cat.append('High')
df['Category']=cat
كما سنصمم مجموعة البيانات كمنطقة خضراء green zone ومنطقة حمراء red zone. إذا كانت الدولة تنتمي إلى فئة عالية فهي تقع تحت المنطقة الخضراء وإذا كانت ضمن الفئة المتوسطة أو المنخفضة فستكون المنطقة الحمراء.
color = (df.Category == 'High' ).map({True: 'background-color: limegreen',False:'background-color: red'})
df.style.apply(lambda s: color)
الآن بما أنني من الهند، أود أن أرى موقع بلدي في القائمة وأيضًا التحقق من بعض البلدان الأخرى حيث يستقر الأشخاص من الهند عادةً للحصول على منافع اقتصادية. لذلك دعونا نتحقق منها:
df.loc[df['Country or region']=='India']

لنحصل على مقارنة وجهاً لوجه مع بعض البلدان العشوائية لفهم سبب حصولهم على مثل هذا التصنيف الجيد أو رتبة الفرقة في جميع أنحاء العالم والحصول على بعض البصيرة.
data={
'Country or region':['Canada','US','UK','India'],
'Score':[7.278,6.892,7.054,4.015],
'GDP per capita':[1.365,1.433,1.333,0.755],
'Social support':[1.505,1.457,1.538,0.765],
'Healthy life expectancy':[1.039,0.874,0.996,0.588],
'Freedom to make life choices':[0.584,0.454,0.45,0.498],
'Generosity':[0.285,0.28,0.348,0.2],
'Perceptions of corruption':[0.308,0.128,0.278,0.085]
}
d=pd.DataFrame(data)
d

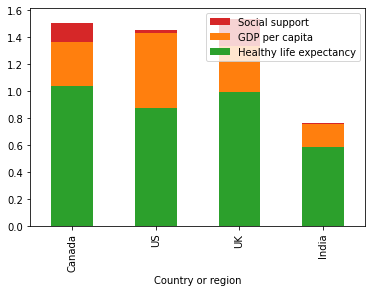
الدعم الاجتماعي Social Support مقابل نصيب الفرد من الناتج المحلي الإجمالي GDP مقابل متوسط الحياة الصحية المتوقعة.
ax = d.plot(y="Social support", x="Country or region", kind="bar",color='C3')
d.plot(y="GDP per capita", x="Country or region", kind="bar", ax=ax, color="C1")
d.plot(y="Healthy life expectancy", x="Country or region", kind="bar", ax=ax, color="C2")
plt.show()
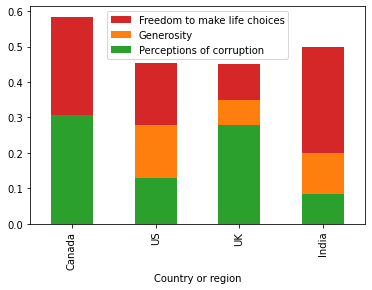
حرية اتخاذ خيارات الحياة مقابل الكرم Generosity مقابل الفساد Corruption.
ax = d.plot(y="Freedom to make life choices", x="Country or region", kind="bar",color='C3')
d.plot(y="Generosity", x="Country or region", kind="bar", ax=ax, color="C1",)
d.plot(y="Perceptions of corruption", x="Country or region", kind="bar", ax=ax, color="C2",)
plt.show()
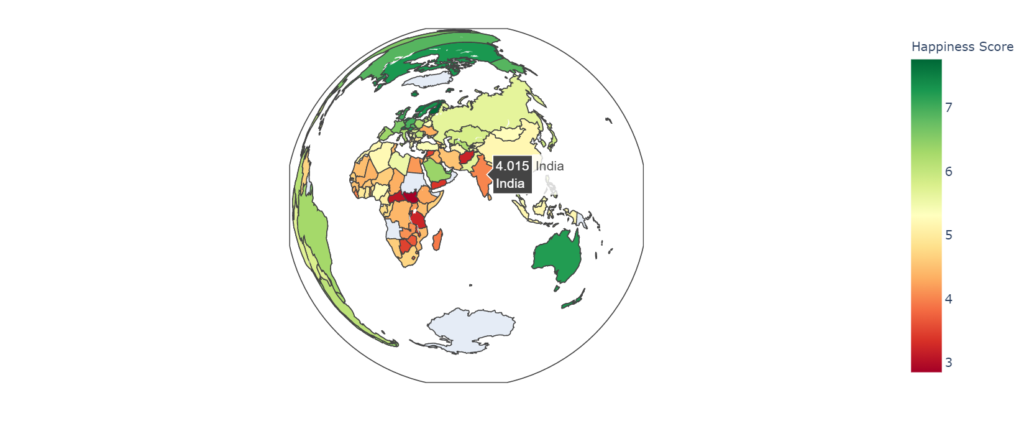
التصور الجغرافي Geographic Visualization لدرجة السعادة Happiness Score:
import plotly.graph_objs as go
from plotly.offline import iplot
data = dict(type = 'choropleth',
locations = df['Country or region'],
locationmode = 'country names',
colorscale='RdYlGn',
z = df['Score'],
text = df['Country or region'],
colorbar = {'title':'Happiness Score'})
layout = dict(title = 'Geographical Visualization of Happiness Score',
geo = dict(showframe = True, projection = {'type': 'azimuthal equal area'}))
choromap3 = go.Figure(data = [data], layout=layout)
iplot(choromap3)
السلام عليكم دكتور علاء
هل ممكن استخدم المشروع في مشاريعي الخاصة وأضعه في ملفي الشخصي !!
ماذا تقصد بمشاريعك الخاصة واين هو ملفك الشخصي
تحياتي