

- تحديد نموذج تقطيع الصورة
- تدريب نموذج تقطيع الصورة
- عمل تنبؤات باستخدام تقطيع الصورة
لكونك ممارسًا في التعلم العميق، يجب أن تكون قد مررت بتصنيف للصور image classification، حيث يكون الهدف هو تعيين تسمية أو فئة للصورة المدخلة. الآن، لنفترض أنك تريد الوصول إلى مكان وجود الكائن داخل الصورة، أو شكل الكائن، أو ما هو البكسل الذي يمثل الكائن. في مثل هذه الحالة، يجب عليك اللعب بجزء من الصورة، والذي أقصد منه إعطاء تسمية لكل بكسل من الصورة. الهدف من تقطيع الصورة Image Segmentation هو تدريب شبكة عصبية يمكنها إرجاع قناع الصورة من خلال البكسل.
في العالم الحقيقي، يساعد تقطيع الصور في العديد من التطبيقات في العلوم الطبية والسيارات ذاتية القيادة وتصوير الأقمار الصناعية وغيرها الكثير. يعمل تقطيع الصورة من خلال دراسة الصورة في أدنى مستوى.
في هذه المقالة، سوف آخذك من خلال تقطيع الصور باستخدام التعلم العميق. دعنا الآن نتعرف على تقطيع الصورة من خلال التعمق فيها. سأبدأ بمجرد استيراد المكتبات التي نحتاجها لتقطيع الصور.
import tensorflow as tf
from tensorflow_examples.models.pix2pix import pix2pix
import tensorflow_datasets as tfds
from IPython.display import clear_output
import matplotlib.pyplot as plt
سأستخدم مجموعة بيانات Oxford-IIIT Pets المضمنة بالفعل في Tensorflow:
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
يقوم الكود أدناه بإجراء تكبير بسيط للصورة. مثلما نقوم بإعداد البيانات قبل القيام بأي مهمة تعلم آلي بناءً على تحليل النص. أنا هنا فقط أقوم بتحضير الصور لتقطيع الصور:
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
@tf.function
def load_image_train(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
if tf.random.uniform(()) > 0.5:
input_image = tf.image.flip_left_right(input_image)
input_mask = tf.image.flip_left_right(input_mask)
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
def load_image_test(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
في مجموعة البيانات، لدينا بالفعل العدد المطلوب من مجموعات التدريب والاختبار. لذلك سأستمر في استخدام هذا التقسيم من مجموعات التدريب والاختبار:
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train = dataset['train'].map(load_image_train, num_parallel_calls=tf.data.AUTOTUNE)
test = dataset['test'].map(load_image_test)
train_dataset = train.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
train_dataset = train_dataset.prefetch(buffer_size=tf.data.AUTOTUNE)
test_dataset = test.batch(BATCH_SIZE)
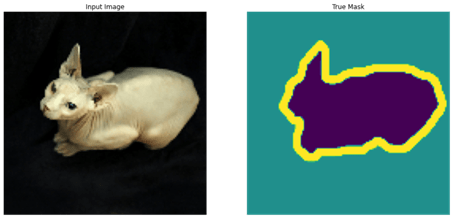
الآن دعنا نلقي نظرة سريعة على صورة وقناعها من البيانات:
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.preprocessing.image.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for image, mask in train.take(1):
sample_image, sample_mask = image, mask
display([sample_image, sample_mask])
تحديد نموذج تقطيع الصورة
النموذج الذي سأستخدمه هنا هو U-Net معدل. يحتوي U-Net على جهاز مشفر encoder ومفكك شفرة decoder. من أجل تعلم الميزات القوية وتقليل جميع المعلمات القابلة للتدريب، يمكن استخدام نموذج تم اختباره مسبقًا بكفاءة كمشفر.
OUTPUT_CHANNELS = 3
كما ذكرت أعلاه، فإن المشفر الخاص بنا هو نموذج تم اختباره مسبقًا وهو متاح وجاهز للاستخدام في تطبيقات tf.keras.applications. يحتوي هذا المشفر على بعض المخرجات المحددة من الطبقات الوسيطة للنموذج. يرجى ملاحظة أنه لن يتم تدريب المشفر أثناء عملية التدريب.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
decoder/upsampler هي ببساطة سلسلة من الكتل التي يتم تنفيذها في أمثلة TensorFlow:
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
output_channels, 3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
تدريب نموذج تقطيع الصورة
model = unet_model(OUTPUT_CHANNELS)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy’])
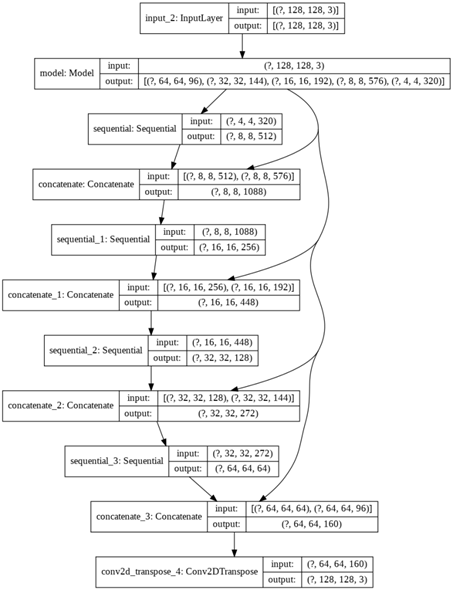
الآن قبل المضي قدمًا، دعنا نلقي نظرة سريعة على الاخراج الناتج للنموذج المدرب:
tf.keras.utils.plot_model(model, show_shapes=True)
دعونا نجرب النموذج لنرى ما يتوقعه قبل التدريب:
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

الآن، دعونا نلاحظ كيف يتحسن نموذج تقطيع الصور أثناء التدريب. لإنجاز هذه المهمة، تم تحديد دالة callback أدناه:
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_dataset, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_dataset,
callbacks=[DisplayCallback()])

الآن، دعنا نلقي نظرة سريعة على أداء النموذج:
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
epochs = range(EPOCHS)
plt.figure()
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()

عمل تنبؤات باستخدام تقطيع الصورة
دعونا نقدم بعض التوقعات. حرصًا على توفير الوقت، ظل عدد الفترات epochs صغيراً، ولكن يمكنك تعيين هذا أعلى لتحقيق نتائج أكثر دقة:
show_predictions(test_dataset, 3)



