

- كيف يعمل Chatbot؟
- إنشاء Chatbot باستخدام بايثون والتعلم العميق
- تحديد نوايا Chatbot
- تحضير البيانات
- الترميز Tokenization
- تدريب شبكة عصبية
- حفظ الشبكة العصبية
- بناء Chatbot باستخدام بايثون ونموذج التعلم العميق المدرب
إذا كنت مهتمًا بتطوير بوت محادثة (المتحدث الآلي) Chatbot، فقد تجد أن هناك العديد من أطر تطوير البوتات القوية والأدوات والأنظمة الأساسية التي يمكن استخدامها لتنفيذ برامج بوتات الدردشة الذكية. في هذه المقالة، سوف أطلعك على كيفية إنشاء Chatbot باستخدام بايثون والتعلم العميق.
كيف يعمل Chatbot؟
نظرًا لأننا سنطور بوت محادثة Chatbot مع بايثون باستخدام التعلم الآلي، فنحن بحاجة إلى بعض البيانات لتدريب نموذجنا. لكننا لن نقوم بجمع أو تنزيل مجموعة بيانات كبيرة لأن هذا مجرد برنامج محادثة. يمكننا فقط إنشاء مجموعة البيانات الخاصة بنا لتدريب النموذج.
لإنشاء مجموعة البيانات هذه لإنشاء بوت محادثة باستخدام بايثون، نحتاج إلى فهم النوايا التي سنقوم بتدريبها. “النية intention ” هي نية المستخدم للتفاعل مع روبوت محادثة أو النية وراء كل رسالة يتلقاها روبوت المحادثة من مستخدم معين.
لذلك، من المهم أن تفهم النوايا الحسنة لبرنامج chatbot الخاص بك اعتمادًا على المجال الذي ستعمل معه. فلماذا يحتاج إلى تحديد هذه النوايا؟ هذه نقطة مهمة للغاية يجب فهمها.
للإجابة على الأسئلة التي يطرحها المستخدمون وأداء العديد من المهام الأخرى لمواصلة المحادثات مع المستخدمين، يحتاج برنامج الدردشة الآلي حقًا إلى فهم ما يقوله المستخدمون أو لديهم نية في القيام به. هذا هو السبب في أن برنامج الدردشة الآلي الخاص بك يجب أن يفهم النوايا الكامنة وراء رسائل المستخدمين.
كيف يمكنك جعل chatbot الخاص بك يفهم النوايا حتى يشعر المستخدمون أنهم يعرفون ما يريدون ويقدمون إجابات دقيقة؟ تتمثل الإستراتيجية هنا في تعيين نوايا مختلفة وإنشاء عينات تدريب لهذه النوايا وتدريب نموذج chatbot الخاص بك باستخدام بيانات التدريب النموذجية هذه كبيانات تدريب نموذجية (X) والنوايا في فئات تدريب نموذجية (Y).
إنشاء Chatbot باستخدام بايثون والتعلم العميق
لإنشاء بوت محادثة باستخدام بايثون وتعلم آلي، تحتاج إلى تثبيت بعض الحزم. جميع الحزم التي تحتاج إلى تثبيتها لإنشاء بوت محادثة مع التعلم الآلي باستخدام لغة برمجة بايثون مذكورة أدناه:
تحديد نوايا Chatbot
نحتاج الآن إلى تحديد بعض النوايا البسيطة ومجموعة من الرسائل التي تطابق تلك النوايا وأيضًا تعيين بعض الردود بناءً على كل فئة نوايا. سأقوم بإنشاء ملف JSON باسم “intents.json” بما في ذلك هذه البيانات على النحو التالي:
{"intents": [
{"tag": "greeting",
"patterns": ["Hi", "Hey", "Is anyone there?", "Hello", "Hay"],
"responses": ["Hello", "Hi", "Hi there"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye"],
"responses": ["See you later", "Have a nice day", "Bye! Come back again"]
},
{"tag": "thanks",
"patterns": ["Thanks", "Thank you", "That's helpful", "Thanks for the help"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "You're most welcome!"]
},
{"tag": "about",
"patterns": ["Who are you?", "What are you?", "Who you are?" ],
"responses": ["I.m Joana, your bot assistant", "I'm Joana, an Artificial Intelligent bot"]
},
{"tag": "name",
"patterns": ["what is your name", "what should I call you", "whats your name?"],
"responses": ["You can call me Joana.", "I'm Joana!", "Just call me as Joana"]
},
{"tag": "help",
"patterns": ["Could you help me?", "give me a hand please", "Can you help?", "What can you do for me?", "I need a support", "I need a help", "support me please"],
"responses": ["Tell me how can assist you", "Tell me your problem to assist you", "Yes Sure, How can I support you"]
},
{"tag": "createaccount",
"patterns": ["I need to create a new account", "how to open a new account", "I want to create an account", "can you create an account for me", "how to open a new account"],
"responses": ["You can just easily create a new account from our web site", "Just go to our web site and follow the guidelines to create a new account"]
},
{"tag": "complaint",
"patterns": ["have a complaint", "I want to raise a complaint", "there is a complaint about a service"],
"responses": ["Please provide us your complaint in order to assist you", "Please mention your complaint, we will reach you and sorry for any inconvenience caused"]
}
]
}
تحضير البيانات
تتمثل الخطوة الثانية من هذه المهمة لإنشاء بوت محادثة باستخدام بايثون والتعلم الآلي في إعداد البيانات لتدريب بوت المحادثة الخاص بنا. سأبدأ هذه الخطوة عن طريق استيراد المكتبات والحزم الضرورية:
import json
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
الآن سأقرأ ملف JSON وأعالج الملفات المطلوبة:
with open('intents.json') as file:
data = json.load(file)
training_sentences = []
training_labels = []
labels = []
responses = []
for intent in data['intents']:
for pattern in intent['patterns']:
training_sentences.append(pattern)
training_labels.append(intent['tag'])
responses.append(intent['responses'])
if intent['tag'] not in labels:
labels.append(intent['tag'])
num_classes = len(labels)
نحتاج الآن إلى استخدام طريقة ترميز التسمية label encoder التي توفرها مكتبة Scikit-Learn في بايثون:
lbl_encoder = LabelEncoder()
lbl_encoder.fit(training_labels)
training_labels = lbl_encoder.transform(training_labels)
الترميز Tokenization
نحتاج الآن إلى ترميز البيانات باستخدام طريقة Tokenization لإنشاء بوت محادثة باستخدام بايثون والتعلم العميق:
vocab_size = 1000
embedding_dim = 16
max_len = 20
oov_token = "<OOV>"
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_token)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded_sequences = pad_sequences(sequences, truncating='post', maxlen=max_len)
تدريب شبكة عصبية
الآن الخطوة التالية والأكثر أهمية في عملية بناء بوت محادثة باستخدام بايثون والتعلم الآلي هي تدريب شبكة عصبية. الآن، سأتدرب وأنشئ شبكة عصبية لتدريب بوت المحادثة الخاص بنا:
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim, input_length=max_len))
model.add(GlobalAveragePooling1D())
model.add(Dense(16, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.summary()
epochs = 500
history = model.fit(padded_sequences, np.array(training_labels), epochs=epochs)
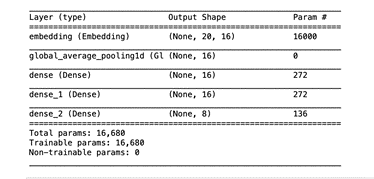
حفظ الشبكة العصبية:
لقد قمنا بتدريب النموذج، ولكن قبل أن نذهب إلى أبعد من ذلك في عملية إنشاء بوت محادثة باستخدام بايثون والتعلم الآلي، دعنا نحفظ النموذج حتى نتمكن من استخدام هذه الشبكة العصبية في المستقبل أيضًا:
# to save the trained model
model.save("chat_model")
import pickle
# to save the fitted tokenizer
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
# to save the fitted label encoder
with open('label_encoder.pickle', 'wb') as ecn_file:
pickle.dump(lbl_encoder, ecn_file, protocol=pickle.HIGHEST_PROTOCOL)
بناء Chatbot باستخدام بايثون ونموذج التعلم العميق المدرب
سأقوم الآن بتنفيذ وظيفة الدردشة للتفاعل مع مستخدم حقيقي. عندما يتم استلام الرسالة من المستخدم، يقوم بوت المحادثة بحساب التشابه بين تسلسل النص الجديد وبيانات التدريب.
مع الأخذ في الاعتبار درجات الثقة التي تم الحصول عليها لكل فئة، فإنه يصنف رسالة المستخدم وفقًا لنية مع أعلى درجة ثقة:
import json
import numpy as np
from tensorflow import keras
from sklearn.preprocessing import LabelEncoder
import colorama
colorama.init()
from colorama import Fore, Style, Back
import random
import pickle
with open("intents.json") as file:
data = json.load(file)
def chat():
# load trained model
model = keras.models.load_model('chat_model')
# load tokenizer object
with open('tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)
# load label encoder object
with open('label_encoder.pickle', 'rb') as enc:
lbl_encoder = pickle.load(enc)
# parameters
max_len = 20
while True:
print(Fore.LIGHTBLUE_EX + "User: " + Style.RESET_ALL, end="")
inp = input()
if inp.lower() == "quit":
break
result = model.predict(keras.preprocessing.sequence.pad_sequences
(tokenizer.texts_to_sequences([inp]),
for i in data['intents']:
if i['tag'] == tag:
print(Fore.GREEN + "ChatBot:" + Style.RESET_ALL , np.random.choice(i['responses']))
# print(Fore.GREEN + "ChatBot:" + Style.RESET_ALL,random.choice(responses))
print(Fore.YELLOW + "Start messaging with the bot (type quit to stop)!" + Style.RESET_ALL)
chat()
truncating='post', maxlen=max_len))
هذه هي الطريقة التي يمكننا بها إنشاء chatbot باستخدام بايثون والتعلم العميق. آمل أن تكون قد أحببت هذه المقالة حول كيفية إنشاء Chatbot باستخدام بايثون والتعلم الآلي.العميق




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.