

- ما هو PyTorch؟
- توقع أسعار السيارات باستخدام PyTorch
- تحضير البيانات
- إنشاء نموذج PyTorch
- تدريب النموذج للتنبؤ بأسعار السيارات
- استخدام النموذج للتنبؤ بأسعار السيارات
في هذه المقالة، سوف أطلعك على كيفية تدريب نموذج يساعدنا في التنبؤ بأسعار السيارات باستخدام التعلم الآلي باستخدام PyTorch. مجموعة البيانات التي سأستخدمها هنا للتنبؤ بأسعار السيارات عبارة عن بيانات مجدولة مع أسعار السيارات المختلفة فيما يتعلق بالمتغيرات الأخرى، وتحتوي مجموعة البيانات على 258 صفًا و9 أعمدة، والمتغير الذي نريد توقعه هو سعر بيع السيارات.
ما هو PyTorch؟
PyTorch هي مكتبة في بايثون توفر أدوات لبناء نماذج التعلم العميق. ما يفعله Python في البرمجة يفعله PyTorch للتعلم العميق. بايثون هي لغة مرنة للغاية للبرمجة ومثل لغة بايثون، توفر مكتبة PyTorch أدوات مرنة للتعلم العميق. إذا كنت تتعلم التعلم العميق أو تتطلع إلى البدء به، فإن معرفة PyTorch ستساعدك كثيرًا في إنشاء نماذج التعلم العميق الخاصة بك.
توقع أسعار السيارات باستخدام PyTorch
الآن، لنبدأ بمهمة التعلم الآلي للتنبؤ بأسعار السيارات باستخدام PyTorch. سأبدأ باستيراد جميع المكتبات الضرورية التي نحتاجها لهذه المهمة. يمكن تنزيل مجموعة البيانات التي أستخدمها في هذه المهمة بسهولة من هنا:
import torch
import jovian
import torch.nn as nn
import pandas as pd
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset, random_split
الآن، دعنا نقرأ البيانات:
DATA_FILENAME = "car_data.csv"
dataframe_raw = pd.read_csv (DATA_FILENAME)
dataframe_raw.head ()
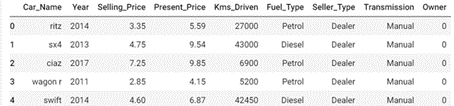
يمكنك رؤية شكل البيانات، ولكن قبل استخدامها، نحتاج إلى تخصيصها وفرز الأسهم وإزالة الأعمدة التي لا تساعد في التنبؤ، وهنا نقوم بإسقاط أسماء السيارات، وللقيام بهذا التخصيص، نستخدم الدالة التالية:
your_name = "Aman Kharwal" # at least 5 characters
def customize_dataset(dataframe_raw, rand_str):
dataframe = dataframe_raw.copy(deep=True)
# drop some rows
dataframe = dataframe.sample(int(0.95*len(dataframe)), random_state=int(ord(rand_str[0])))
# scale input
dataframe.Year = dataframe.Year * ord(rand_str[1])/100.
# scale target
dataframe.Selling_Price = dataframe.Selling_Price * ord(rand_str[2])/100.
# drop column
if ord(rand_str[3]) % 2 == 1:
dataframe = dataframe.drop(['Car_Name'], axis=1)
return dataframe
dataframe = customize_dataset(dataframe_raw, your_name)
dataframe.head()
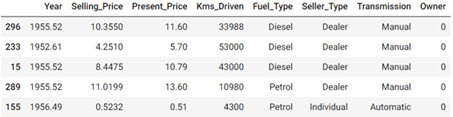
في هذه الدالة أعلاه كما نرى أنها تحتاج إلى كلمة لاستخدامها كسلسلة عشوائية لفرز البيانات بشكل عشوائي، استخدمت اسمي كسلسلة عشوائية. بعد ذلك يمكننا استخدام مجموعة البيانات المخصصة، للتبسيط يمكننا إنشاء متغيرات تحتوي على عدد الصفوف والأعمدة والمتغيرات التي تحتوي على أعمدة رقمية أو فئوية أو ناتجة:
input_cols = ["Year","Present_Price","Kms_Driven","Owner"]
categorical_cols = ["Fuel_Type","Seller_Type","Transmission"]
output_cols = ["Selling_Price"]
تحضير البيانات
كما هو مذكور في بداية المقال، سأستخدم PyTorch للتنبؤ بأسعار السيارات باستخدام التعلم الآلي، لذلك لاستخدام البيانات للتدريب نحتاج إلى تحويلها من إطار البيانات إلى PyTorch Tensors، فإن الخطوة الأولى هي التحويل إلى مصفوفات NumPy:
def dataframe_to_arrays(dataframe):
# Make a copy of the original dataframe
dataframe1 = dataframe.copy(deep=True)
# Convert non-numeric categorical columns to numbers
for col in categorical_cols:
dataframe1[col] = dataframe1[col].astype('category').cat.codes
# Extract input & outupts as numpy arrays
inputs_array = dataframe1[input_cols].to_numpy()
targets_array = dataframe1[output_cols].to_numpy()
return inputs_array, targets_array
inputs_array, targets_array = dataframe_to_arrays(dataframe)
inputs_array, targets_array
تقوم الدالة المذكورة أعلاه بتحويل أعمدة الإدخال والإخراج إلى مصفوفات NumPy، للتحقق من إمكانية عرض النتيجة وكما يمكنك رؤية كيفية تحويل البيانات إلى مصفوفات. الآن بوجود هذه المصفوفات، يمكننا تحويلها إلى موترات PyTorch، واستخدام تلك الموترات لإنشاء مجموعة بيانات متغيرة تحتوي عليها:
inputs = torch.Tensor(inputs_array)
targets = torch.Tensor(targets_array)
dataset = TensorDataset(inputs, targets)
train_ds, val_ds = random_split(dataset, [228, 57])
batch_size = 128
train_loader = DataLoader(train_ds, batch_size, shuffle=True)
val_loader = DataLoader(val_ds, batch_size)
إنشاء نموذج PyTorch
الآن، سأقوم بإنشاء نموذج انحدار خطي باستخدام PyTorch للتنبؤ بأسعار السيارات:
input_size = len(input_cols)
output_size = len(output_cols)
class CarsModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(input_size, output_size) # fill this (hint: use input_size & output_size defined above)
def forward(self, xb):
out = self.linear(xb) # fill this
return out
def training_step(self, batch):
inputs, targets = batch
# Generate predictions
out = self(inputs)
# Calcuate loss
loss = F.l1_loss(out, targets) # fill this
return loss
def validation_step(self, batch):
inputs, targets = batch
# Generate predictions
out = self(inputs)
# Calculate loss
loss = F.l1_loss(out, targets) # fill this
return {'val_loss': loss.detach()}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
return {'val_loss': epoch_loss.item()}
def epoch_end(self, epoch, result, num_epochs):
# Print result every 20th epoch
if (epoch+1) % 20 == 0 or epoch == num_epochs-1:
print("Epoch [{}], val_loss: {:.4f}".format(epoch+1, result['val_loss']))
model = CarsModel()
list(model.parameters())
في هذه الدالة أعلاه، استخدمت الدالة nn.Linear التي ستسمح لنا باستخدام الانحدار الخطي حتى نتمكن الآن من حساب التنبؤات والخسارة باستخدام دالة F.l1_loss. يمكن لدالة F.l1_loss أن ترى تحيزًا لمعامل الوزن واحد، مع هذا النموذج سوف نحصل على التنبؤات، ولكن لا يزال يتعين علينا الخضوع للتدريب.
تدريب النموذج للتنبؤ بأسعار السيارات
نحتاج الآن إلى تقييم الخسارة ومعرفة مقدارها، وبعد القيام بالتدريب، انظر إلى أي مدى تتناقص الخسارة مع التدريب:
# Eval algorithm
def evaluate(model, val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
# Fitting algorithm
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
model.epoch_end(epoch, result, epochs)
history.append(result)
return history
# Check the initial value that val_loss have
result = evaluate(model, val_loader)
print(result)
{'val_loss': 2300.039306640625}
# Start with the Fitting
epochs = 90
lr = 1e-8
history1 = fit(epochs, lr, model, train_loader, val_loader)
Epoch [20], val_loss: 1692.0131
Epoch [40], val_loss: 1119.7253
Epoch [60], val_loss: 638.9708
Epoch [80], val_loss: 357.3529
Epoch [90], val_loss: 317.1693
# Train repeatdly until have a 'good' val_loss
epochs = 20
lr = 1e-9
history1 = fit(epochs, lr, model, train_loader, val_loader)
Epoch [20], val_loss: 7.9774
كما ترون، من أجل التقييم، يتم استخدام دوال النموذج الملائم، للقيام بالتدريب، نستخدم دوال التحسين، في هذه الحالة على وجه التحديد تحسين SGD، باستخدام محمل التدريب يتم حساب الخسارة والتدرجات، لتحسينها بعد ذلك وتقييم نتيجة كل تكرار لرؤية الخسارة.
استخدام النموذج للتنبؤ بأسعار السيارات
أخيرًا، نحتاج إلى اختبار النموذج ببيانات محددة، للتنبؤ بضرورة استخدام المدخلات التي ستكون قيم الإدخال التي نراها في مجموعة البيانات، والنموذج هو نموذج Cars الذي نقوم به، من أجل المرور في النموذج ضروري للتسطيح، لذلك مع كل هذا توقع أسعار البيع:
# Prediction Algorithm
def predict_single(input, target, model):
inputs = input.unsqueeze(0)
predictions = model(inputs) # fill this
prediction = predictions[0].detach()
print("Input:", input)
print("Target:", target)
print("Prediction:", prediction)
# Testing the model with some samples
input, target = val_ds[0]
predict_single(input, target, model)
Input: tensor([1.9565e+03, 1.7800e+00, 4.0000e+03, 0.0000e+00])
Target: tensor([1.7985])
Prediction: tensor([1.4945])
كما ترى، فإن التنبؤات قريبة جدًا من الهدف المتوقع، وليست دقيقة ولكنها مشابهة لما هو متوقع. مع هذا الآن يمكنك اختبار نتائج مختلفة ومعرفة مدى جودة النموذج:
input, target = val_ds[10]
predict_single(input, target, model)
Input: tensor([1.9555e+03, 8.4000e+00, 1.2000e+04, 0.0000e+00])
Target: tensor([6.9760])
Prediction: tensor([-0.4069])
آمل أن تكون قد أحببت هذه المقالة حول كيفية التنبؤ بأسعار السيارات باستخدام التعلم العميق باستخدام نموذج الانحدار الخطي المدرب باستخدام PyTorch.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.