

- معالجة البيانات الفئوية في التعلم الآلي
- LabelEncoder
- LabelBinarizer
- الملخص
أثناء حل المشكلات بناءً على التصنيف باستخدام التعلم الآلي machine learning، نجد في الغالب مجموعات بيانات مكونة من تسميات فئوية categorical labels لا يمكن معالجتها بواسطة جميع خوارزميات التعلم الآلي. لذلك، إذا كنت تريد معرفة كيفية التعامل مع البيانات الفئوية categorical data في التعلم الآلي، فهذه المقالة مناسبة لك. في هذه المقالة، سأقدم لك تقنيات معالجة البيانات الفئوية في التعلم الآلي وتنفيذها باستخدام بايثون.
معالجة البيانات الفئوية في التعلم الآلي
لا يمكن لجميع خوارزميات التعلم الآلي التعامل مع البيانات الفئوية، لذلك من المهم للغاية تحويل الميزات الفئوية categorical features لمجموعة البيانات إلى قيم رقمية numeric values. توفر مكتبة scikit-Learn في بايثون العديد من الطرق للتعامل مع البيانات الفئوية. بعض أفضل التقنيات لمعالجة البيانات الفئوية هي:
- LabelEncoder
- LabelBinarizer
لاستخدام هاتين الطريقتين للتعامل مع البيانات الفئوية، نحتاج أولاً إلى مجموعة بيانات ذات ميزات فئوية. فلننشئ واحدًا:
import numpy as np
x = np.random.uniform(0.0, 1.0, size=(10, 2))
y = np.random.choice(("Male", "Female"), size=(10))
print(x[0])
print(y[0])

لذا، كما ترون، لقد أنشأت مجموعة بيانات صغيرة جدًا تتكون من 10 عينات فئوية كذكر Male وأنثى Female. في القسم أدناه، سأوضح لك كيفية التعامل مع هذه الميزات الفئوية في التعلم الآلي باستخدام LabelEncoder و LabelBinarizer.
LabelEncoder:
تأخذ كلاس LabelEncoder في مكتبة scikit-Learn في بايثون منهجًا موجهًة بالقاموس dictionary-oriented approach لربط كل قيمة فئوية بقيمة عدد صحيح تدريجي. فيما يلي كيفية استخدام LabelEncoder للتعامل مع البيانات الفئوية في التعلم الآلي:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y1 = le.fit_transform(y)
print(y1)

هذه هي الطريقة التي يمكننا بها استخدام LabelEncoder للتعامل مع الميزات الفئوية، يمكنك أيضًا فك ترميز هذه القيم المحولة إلى التسميات الفئوية الأصلية كما هو موضح أدناه:
output = [1, 0, 1, 0, 1, 0, 0, 1, 1, 1]
output1 = [le.classes_[int(i)] for i in output]
print(output1)

LabelBinarizer:
تعمل طريقة LabelEncoder في كثير من الحالات عند تحويل البيانات الفئوية إلى قيم رقمية. لكن من العيوب أن يتم تحويل جميع التسميات إلى أرقام متسلسلة sequential numbers. لهذا السبب، من الأفضل استخدام ترميز واحد-ساخن one-hot-encoding يقوم بترميز البيانات الفئوية بالثنائي. إليك كيفية استخدام فئة LabelBinarizer في scikit-Learn للتعامل مع البيانات الفئوية:
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
y2 = lb.fit_transform(y)
print(y2)
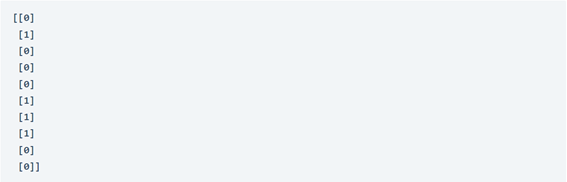
إليك كيفية فك ترميز هذه القيم المحولة transformed values إلى التسميات الفئوية الأصلية:
output2 = lb.inverse_transform(y2)
print(output2)

الملخص
عند حل المشكلات بناءً على التصنيف باستخدام التعلم الآلي، نجد في الغالب مجموعات بيانات مكونة من تسميات فئوية لا يمكن معالجتها بواسطة جميع خوارزميات التعلم الآلي. هذا هو السبب في أننا نحتاج إلى تحويل السمات الفئوية إلى قيم عددية. آمل أن تكون قد أحببت هذه المقالة حول كيفية التعامل مع البيانات الفئوية في التعلم الآلي.



