

لنفترض أنك كنت تنشئ متجرًا للهدايا وقام المورد الخاص بك بتفريغ جميع الألعاب التي طلبتها في الغرفة. سيبدو شيء من هذا القبيل. فوضى عارمة! تخيل نفسك الآن تقف أمام هذه الكومة الضخمة من الألعاب تحاول العثور على اللعبة المناسبة للعميل!

أنت تعلم أنه موجود هناك، لكنك لا تعرف مكان البحث عنه! محبط أليس كذلك؟
في السيناريو الثاني، تقوم أولاً بتنظيم الألعاب قبل فتح المتجر. قد ترغب في تجميع الألعاب في فئات أو حتى اختيار استبدال بعض الألعاب المكسورة بأخرى أحدث. قد تدرك حتى أن بعض الألعاب التي طلبتها مفقودة وتتخذ الإجراءات اللازمة.
هذا يبدو وكأنه نهج أكثر تنظيماً وعقلانية، أليس كذلك؟
حسنًا، عندما نبني نماذج التعلم الآلي، في معظم الحالات، تبدو البيانات التي نتعامل معها مثل هذه الفوضى غير المنظمة للألعاب. يجب تنظيف هذه البيانات ومعالجتها مسبقًا قبل استخدامها، وهنا يأتي دور هندسة الميزات Feature Engineering. إنها عملية تهدف إلى إعادة النظام إلى الفوضى.
لذلك دعونا نتعمق ونلقي نظرة على الموضوعات التي سنغطيها!
جدول المحتويات
- ما هي هندسة الميزات؟
- لماذا تعتبر هندسة الميزات مهمة جدًا؟
- تحليل ميزات مجموعة البيانات
- معالجة البيانات المفقودة
- احذف الأعمدة.
- تضمين القيم المفقودة للمتغير المستمر.
- تضمين القيم المفقودة للمتغير الفئوي.
- توقع القيم المفقودة.
- ترميز البيانات الفئوية.
- ترميز المتغيرات المستقلة.
- ترميز المتغيرات التابعة.
- تحجيم الميزة.
- الاستنتاج.
ما هي هندسة الميزات؟
هندسة الميزات هي عملية استخراج وتنظيم الميزات المهمة من البيانات الأولية بطريقة تناسب الغرض من نموذج التعلم الآلي. يمكن اعتباره فن اختيار الميزات المهمة وتحويلها إلى ميزات منقحة وذات مغزى تتناسب مع احتياجات النموذج.
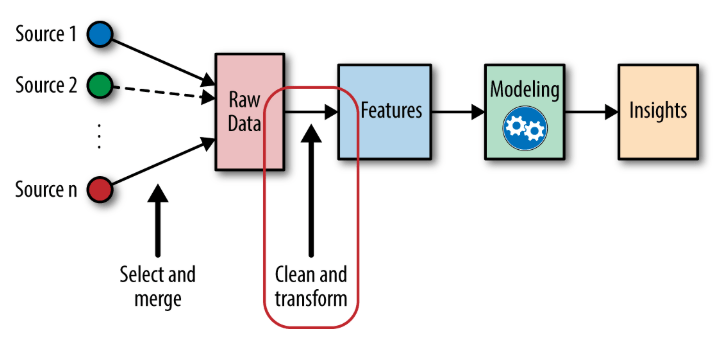
تتضمن هندسة الميزات تقنيات هندسة البيانات المختلفة مثل تحديد الميزات ذات الصلة ومعالجة البيانات المفقودة وترميز البيانات وتطبيعها.
إنها واحدة من أهم المهام وتلعب دورًا رئيسيًا في تحديد نتيجة النموذج. من أجل ضمان أن الخوارزمية المختارة يمكن أن تؤدي إلى قدرتها المثلى، من المهم هندسة ميزات بيانات الإدخال بشكل فعال.
لماذا تعتبر هندسة الميزات مهمة جدًا؟
هل تعرف ما الذي يتطلب أقصى قدر من الوقت والجهد في سير عمل التعلم الآلي؟
حسنًا لتحليل ذلك، دعونا نلقي نظرة على هذا الرسم التخطيطي.
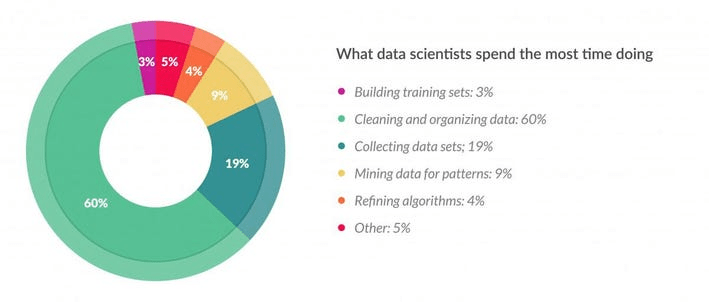
يُظهر هذا المخطط الدائري pie-chart نتائج استطلاع أجرته فوربس. من الواضح تمامًا من الأرقام أن إحدى الوظائف الرئيسية لعالم البيانات هي تنظيف البيانات الأولية ومعالجتها. يمكن أن يستغرق هذا ما يصل إلى 80٪ من وقت عالم البيانات. هذا هو المكان الذي تدخل فيه هندسة الميزات. بعد تنظيف البيانات ومعالجتها، تصبح جاهزة بعد ذلك لتغذيتها في نماذج التعلم الآلي للتدريب وإنشاء المخرجات.
لقد أثبتنا حتى الآن أن هندسة البيانات هي جزء مهم للغاية من خط أنابيب التعلم الآلي، ولكن لماذا هناك حاجة إليها في المقام الأول؟
لفهم ذلك، دعونا نفهم كيف نجمع البيانات في المقام الأول. في معظم الحالات، يتعامل علماء البيانات مع البيانات المستخرجة من مصادر البيانات المفتوحة الضخمة مثل الإنترنت أو الدراسات الاستقصائية أو المراجعات. هذه البيانات خام وتُعرف بالبيانات الخام raw data. قد يحتوي على قيم مفقودة missing values وبيانات غير مهيكلة unstructured data ومدخلات غير صحيحة incorrect inputs وقيم متطرفة outliers. إذا استخدمنا هذه البيانات الأولية غير المعالجة مباشرة لتدريب نماذجنا، فسنصل إلى نموذج ذي كفاءة رديئة للغاية.
وبالتالي تلعب هندسة الميزات دورًا محوريًا للغاية في تحديد أداء أي نموذج للتعلم الآلي.
فوائد هندسة الميزات
تعني هندسة الميزات الفعالة ما يلي:
- كفاءة أعلى للنموذج.
- خوارزميات أسهل تناسب البيانات.
- أسهل للخوارزميات لاكتشاف الأنماط في البيانات.
- مرونة أكبر في الميزات.
حسنًا، قد يبدو تنظيف كميات كبيرة من البيانات الخام وغير المهيكلة والقذرة مهمة شاقة، ولكن هذا هو بالضبط ما يدور حوله هذا الدليل.
فلنبدأ الآن ونزيل الغموض عن هندسة الميزات!
تحليل ميزات مجموعة البيانات
عندما تحصل على مجموعة بيانات، أنصحك بشدة بقضاء بعض الوقت أولاً في تحليل مجموعة البيانات. سيساعدك هذا في فهم نوع الميزات والبيانات التي تتعامل معها. سيساعدك تحليل مجموعة البيانات أيضًا في إنشاء خريطة ذهنية لتقنيات هندسة الميزات التي ستحتاجها لمعالجة بياناتك.
لذلك دعونا نستورد المكتبات ونلقي نظرة على مجموعة البيانات الخاصة بنا.
هكذا تبدو مجموعة البيانات الخاصة بنا. بمجرد تحديد ميزات الإدخال والقيم التي سيتم توقعها (في حالتنا، يكون المشتراة “Purchased” هو العمود الذي سيتم توقعه والباقي هي ميزات الإدخال)، دعنا نحلل البيانات التي لدينا.
نرى أيضًا أن لدينا عمود الاسم “Name” والذي لا يلعب أي دور في تحديد ناتج نموذجنا. لذلك يمكننا استبعاده بأمان من مجموعة التدريب. ويمكن القيام بذلك على النحو التالي.
x= dataset.iloc[:,1:-1].values
y= dataset.iloc[:,-1].values
print (x

print (y)

يجب أن يحتوي المتغير “x” على المدخلات ويجب أن يحتوي المتغير “y” على المخرجات.
معالجة البيانات المفقودة – خطوة مهمة في هندسة الميزات
الآن دعنا نتحقق مما إذا كان لدينا أي بيانات مفقودة.
تتمثل إحدى الطرق الرائعة للقيام بذلك في عرض مجموع جميع القيم الخالية في كل عمود من مجموعة البيانات الخاصة بنا. يساعدنا السطر التالي من التعليمات البرمجية على القيام بذلك.
dataset.isnull().sum()
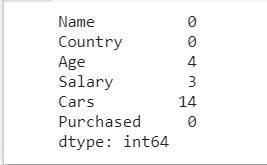
هذا يعطينا تمثيلًا واضحًا جدًا للعدد الإجمالي للقيم المفقودة الموجودة في كل عمود. الآن دعونا نرى كيف يمكننا التعامل مع هذه القيم المفقودة.
حذف الأعمدة
في بعض الأحيان قد تكون هناك ميزات معينة في مجموعة البيانات الخاصة بنا والتي تحتوي على عدة إدخالات فارغة أو قيم خالية. غالبًا ما لا تساهم هذه الأعمدة التي تحتوي على عدد كبير جدًا من القيم الخالية كثيرًا في الإخراج المتوقع. في مثل هذه الحالات، قد نختار حذف العمود تمامًا.
يمكننا إصلاح قيمة حد معينة، على سبيل المثال 70٪ أو 80٪ ، وإذا تجاوز عدد القيم الخالية الحد الأدنى، فقد نرغب في حذف هذا العمود المعين من مجموعة بيانات التدريب الخاصة بنا.
threshold=0.7
dataset = dataset[dataset.columns[dataset.isnull().mean() < threshold]]
print(dataset)
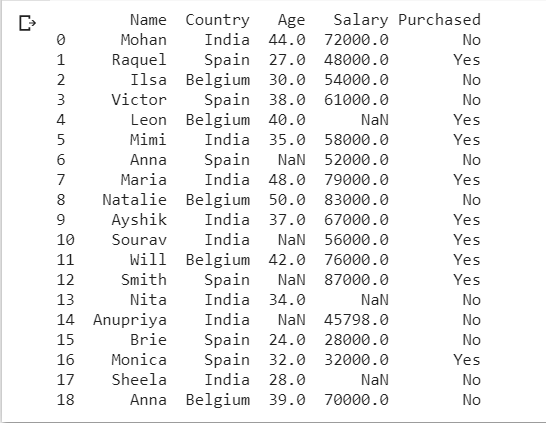
ما يفعله هذا الجزء من الكود هو تحديد الأعمدة التي تحتوي على قيم فارغة أقل من قيمة العتبة threshold المحددة. في مثالنا، نرى أنه تمت إزالة عمود السيارات ” Cars”. عدد القيم الخالية هو 14 والعدد الإجمالي للإدخالات لكل عمود هو 20. نظرًا لأن عدد القيم الخالية لا يقل عن العتبة المطلوبة، فإننا نحذف العمود.
الإيجابيات:
- تقليل الأبعاد.
- يقلل من تعقيد العمليات الحسابية.
السلبيات
- يسبب فقدان المعلومات.
لتسهيل الفهم، نحن نتعامل مع مجموعة بيانات صغيرة، ولكن في الواقع تُفضل هذه الطريقة فقط عندما تكون مجموعة البيانات كبيرة ولن يؤثر حذف بعض الأعمدة عليها كثيرًا، أو عندما يكون العمود المراد حذفه ميزة أقل أهمية نسبيًا.
تضمين القيم المفقودة للمتغير المستمر
يشير تضمين القيم المفقودة Imputing Missing Values إلى عملية ملء القيم المفقودة ببعض القيم المحسوبة من أعمدة الميزات المقابلة.
يمكننا استخدام عدد من الاستراتيجيات لإدخال قيم المتغيرات المستمرة Continuous variables. يتم احتساب بعض هذه الاستراتيجيات مع المتوسط Mean أو الوسيط Median أو المنوال Mode.
دعونا نعرض أولاً المتغير الأصلي x.
x= dataset.iloc[:,1:-1].values
y= dataset.iloc[:,-1].values
print (x)

التضمين مع المتوسط
الآن، للقيام بذلك، سنقوم باستيراد SimpleImputer من sklearn.impute وتمرير استراتيجيتنا كمعامل. سنحدد أيضًا الأعمدة التي سيتم تطبيق هذه الإستراتيجية فيها باستخدام التقطيع slicing.
from sklearn.impute import SimpleImputer
imputer =SimpleImputer(missing_values=np.nan, strategy= "mean")
imputer.fit(x[:,1:3])
x[:,1:3]= imputer.transform(x[:,1:3])

نرى أنه تم استبدال قيم nan بالقيم المتوسطة للأعمدة المقابلة لها.
التضمين مع الوسيط
الآن، بدلاً من المتوسط إذا أردنا أن نضمن القيم المفقودة بالوسيط بدلاً من المتوسط، علينا ببساطة تغيير المعلمة إلى ” median”.
from sklearn.impute import SimpleImputer
imputer =SimpleImputer(missing_values=np.nan, strategy= "median")
imputer.fit(x[:,1:3])
x[:,1:3]= imputer.transform(x[:,1:3])
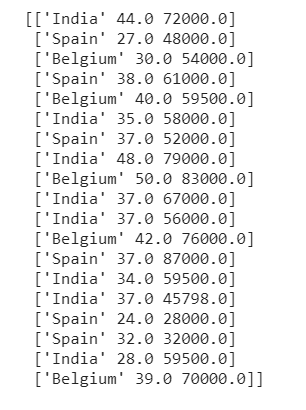
التضمين مع المنوال
تتمثل إحدى طرق التضمين الأكثر شيوعًا للتعامل مع القيم المفقودة في استبدال القيم المفقودة بالقيمة الأكثر شيوعًا في العمود. في مثل هذه الحالات، نضمن القيم المفقودة إلى المنوال. للقيام بذلك، علينا ببساطة تمرير “most_frequent” كمعامل استراتيجيتنا.
from sklearn.impute import SimpleImputer
imputer =SimpleImputer(missing_values=np.nan, strategy= "most_frequent")
imputer.fit(x[:,1:3])
x[:,1:3]= imputer.transform(x[:,1:3])
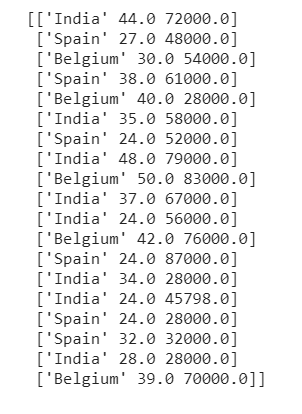
تضمين القيم المفقودة للمتغير الفئوي
في حالتنا، لا تحتوي مجموعة البيانات الخاصة بنا على أي متغير فئوي Categorical Variable بقيم مفقودة. ومع ذلك، قد تكون هناك حالات عندما تصادف مجموعة بيانات قد تضطر فيها إلى احتساب القيم المفقودة لبعض المتغيرات الفئوية.
لفهم كيفية التعامل مع مثل هذا السيناريو، دعونا نعدل مجموعة البيانات الخاصة بنا قليلاً وآخر جديد الجنس “Gender” الذي يحتوي على بعض الإدخالات المفقودة. سيساعدنا هذا على فهم كيفية التعامل مع مثل هذه الحالات. تبدو مجموعة البيانات الخاصة بنا الآن كما يلي:
dataset.isnull().sum()
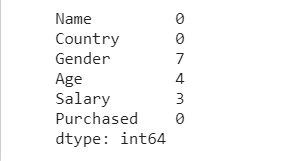
dataset.head(10)
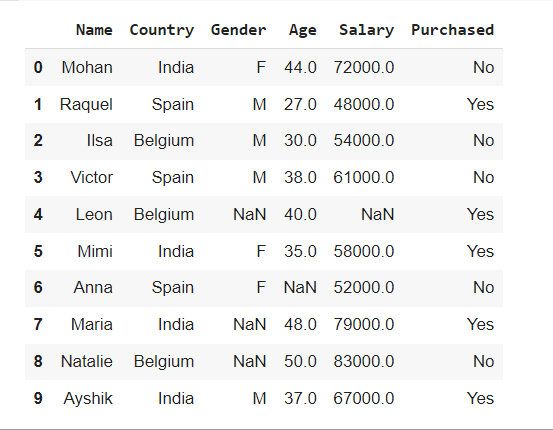
الآن، انظر بعناية إلى عمود “Gender”. يحتوي على “M” و “F” والقيم المفقودة (nan) كمدخلات.
هناك ثلاث طرق رئيسية للتعامل مع القيم الفئوية المفقودة. سنناقش كل واحد منهم.
إسقاط الصفوف التي تحتوي على قيم فئوية مفقودة
dataset.dropna(axis=0, subset=['Gender'], inplace=True)
dataset.head(10)
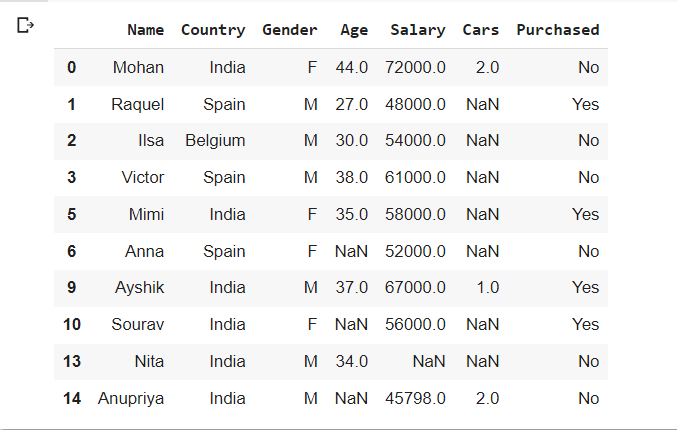
لاحظ أنه تمت إزالة جميع الصفوف التي بها “Gender” عبارة عن NAN من مجموعة البيانات. هنا يحدد المحور = 0 أنه يجب إزالة الصفوف التي تحتوي على قيم مفقودة وتحتوي معلمة المجموعة الفرعية ‘subset’ على قائمة الأعمدة التي يجب التحقق منها بحثًا عن القيم المفقودة.
تضمين فئة جديدة للقيم الفئوية المفقودة
يؤدي حذف القيم المفقودة ببساطة إلى فقدان المعلومات. لتجنب ذلك يمكننا أيضًا استبدال القيم المفقودة بفئة جديدة. على سبيل المثال، قد نقوم بتعيين “U” للأجناس المفقودة حيث يشير الحرف “U” إلى Unknown.
dataset['Gender']= dataset['Gender'].fillna('U')
dataset.head(10)
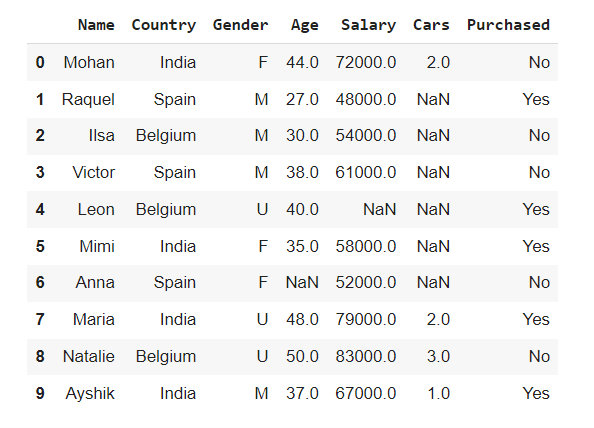
هنا تم استبدال جميع القيم المفقودة في عمود “Gender”بـ “U”. تضيف هذه الطريقة معلومات إلى مجموعة البيانات بدلاً من التسبب في فقدان المعلومات.
تضمين متغير فئوي ذو قيمة أكثر تكراراً
أخيرًا، قد نضمن أيضًا القيمة المفقودة بالقيمة الأكثر شيوعًا لهذا العمود المحدد. نعم، لقد خمنت ذلك بشكل صحيح! سنقوم باستبدال قيمة المنوال mode value في الحقول المفقودة. نظرًا لأن الفئة ذات التكرار الأعلى في مجموعة البيانات الخاصة بنا هي “M”، فيجب استبدال القيم المفقودة بـ ‘M’ .
dataset['Gender']= dataset['Gender'].fillna(dataset['Gender'].mode()[0])
dataset.head(10)
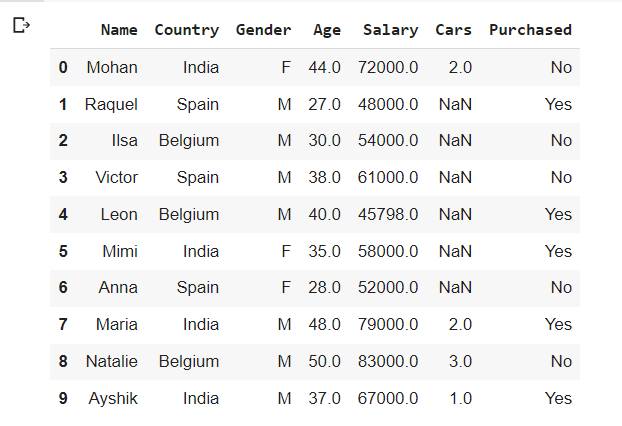
توقع القيم المفقودة
لقد انتهينا تقريبًا من التقنيات المختلفة للتعامل مع القيم المفقودة. لقد وصلنا الآن إلى الطريقة الأخيرة وهي طريقة التضمين بالتنبؤ Prediction Imputation.
الحدس الكامن وراء هذه الطريقة بسيط للغاية ولكنه فعال. سنفكر في العمود الذي يحتوي على قيم مفقودة كمتغير تابع (أو العمود y). يمكن أن تكون بقية الأعمدة المتغير المستقل (أو العمود x). الآن، نأخذ الصفوف المملوءة بالكامل كمجموعة تدريب لدينا والقيمة المفقودة التي تحتوي على صفوف كمجموعة الاختبار الخاصة بنا. ثم نستخدم نموذج الانحدار الخطي البسيط أو نموذج التصنيف للتنبؤ بالقيم المفقودة. نظرًا لأن هذه الطريقة تأخذ في الاعتبار الارتباط بين عمود القيمة المفقودة والأعمدة الأخرى للتنبؤ بالقيم المفقودة، فإنها تؤدي إلى نتائج أفضل بكثير من الطرق السابقة. هذه استراتيجية رائعة للتعامل مع القيم المفقودة.
ترميز البيانات الفئوية
تهانينا! لقد انتهيت من جميع تقنيات معالجة البيانات المفقودة. تأتي الآن إحدى أهم خطوات هندسة الميزات – ترميز المتغيرات الفئوية Encoding the categorical variables.
دعونا نفهم أولاً سبب الحاجة إلى ذلك.
تحتوي مجموعة البيانات الخاصة بنا على حقول مثل الدولة “Country” التي لها أسماء بلدان مثل الهند وإسبانيا وبلجيكا. يحتوي العمود تم شراؤه “Purchased” على نعم أو لا. لا يمكننا العمل مع هذه المتغيرات الفئوية لأنها حرفية. يجب ترميز كل هذه القيم غير الرقمية في قيمة رقمية ملائمة يمكن استخدامها لتدريب نموذجنا. هذا هو السبب في أننا بحاجة إلى ترميز المتغيرات الفئوية.
ترميز المتغيرات المستقلة
دعنا نعود إلى مجموعة البيانات الأصلية الخاصة بنا ونلقي نظرة على المتغير المستقل x.
x= dataset.iloc[:,1:-1].values
y= dataset.iloc[:,-1].values
print (x)
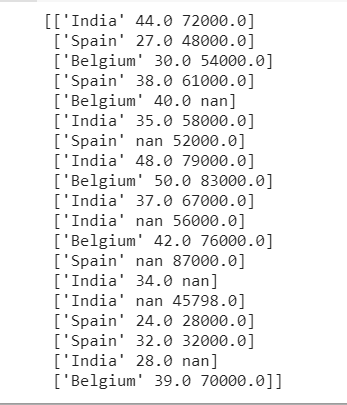
يحتوي المتغير المستقل x على متغير فئوي “Country”. يحتوي هذا الحقل على 3 قيم مختلفة – الهند وإسبانيا وبلجيكا.
إذن ، هل يجب ترميز الهند وإسبانيا وبلجيكا بالرقم 0 و 1 و 2؟
يبدو أن هذا لا بأس به، أليس كذلك؟ لكن انتظر. هناك شي!
الإجابة الصحيحة هي: لا. لا يمكننا ترميز البلدان الثلاثة بشكل مباشر كـ 0،1 و 2. هذا لأنه إذا قمنا بترميز البلدان بهذه الطريقة، فسيفترض نموذج التعلم الآلي خطأ أن هناك نوعًا من العلاقة التسلسلية بين البلدان. سيجعل هذا النموذج يعتقد أن الهند وإسبانيا وبلجيكا لها ترتيب تسلسلي مثل الأرقام 0 و 1 و 2. هذا ليس صحيحًا. ومن ثم، يجب علينا عدم تغذية النموذج بمثل هذه المعلومات غير الصحيحة.
فما هو الحل؟
الحل هو إنشاء أعمدة منفصلة لكل فئة من المتغيرات الفئوية. ثم نقوم بتعيين 1 للعمود وهو صحيح و 0 للعمود الآخر. يجب أن تعطينا المجموعة الكاملة من الأعمدة التي تمثل المتغير الفئوي النتيجة دون إنشاء أي علاقة ترتيبية.
على سبيل المثال لدينا، قد نقوم بترميز البلدان على النحو التالي:

يمكن القيام بذلك بمساعدة One Hot Encoding. تُعرف الأعمدة المنفصلة التي تم إنشاؤها لتمثيل المتغيرات الفئوية باسم المتغيرات الوهمية Dummy Variables. يتم استدعاء طريقة fit_transform() من فئة OneHotEncoder التي تنشئ المتغيرات الوهمية وتعينها بقيم ثنائية. دعونا نلقي نظرة على الكود.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = np.array(ct.fit_transform(x))
print(X)

هاهو! هناك لدينا المتغيرات الفئوية الخاصة بنا المرمزة بشكل جميل إلى متغيرات وهمية دون أي علاقة ترتيبية بين الفئات المختلفة.
ترميز المتغيرات التابعة
دعونا الآن نلقي نظرة على المتغير التابع y.
print(y)

المتغير التابع y هو أيضًا متغير فئوي. ومع ذلك، في هذه الحالة يمكننا ببساطة تخصيص 0 و 1 للفئتين “لا” و “نعم”. في هذه الحالة، لا نطلب متغيرات وهمية لترميز المتغير المتوقع “Predicted” لأنه متغير تابع لن يتم استخدامه لتدريب النموذج.
لترميز هذا، سنحتاج إلى فئة LabelEncoder.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
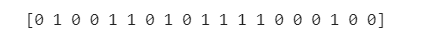
تحجيم الميزات – الخطوة الأخيرة في هندسة الميزات
أخيرًا، وصلنا إلى الخطوة الأخيرة من هندسة الميزات – تحجيم الميزات Feature Scaling.
تحجيم الميزة هو عملية تغيير جميع القيم الموجودة في مجموعة البيانات الخاصة بنا أو تحويلها إلى مقياس معين. تستخدم بعض خوارزميات التعلم الآلي مثل الانحدار الخطي والانحدار اللوجستي وما إلى ذلك تحسين التدرج الاشتقاقي. تتطلب مثل هذه الخوارزميات البيانات ليتم تحجيمها من أجل الأداء الأمثل. يُظهر K-Nearest Neighbours و Support Vector Machine و K-Means Cluster أيضًا ارتفاعًا حادًا في الأداء على قياس البيانات.
هناك طريقتان رئيسيتان لتوسيع نطاق الميزات:
- التوحيد Standardization.
- التسوية Normalization.
التسوية
التسوية هو عملية قياس قيم البيانات بحيث تقع قيمة جميع الميزات بين 0 و 1.
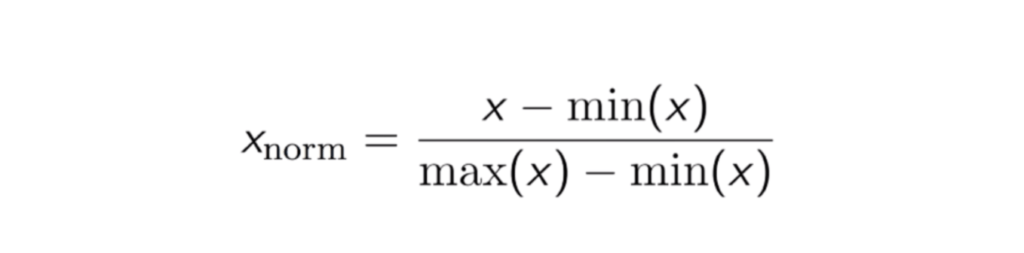
تعمل هذه الطريقة بشكل جيد عندما يتم توزيع البيانات بشكل طبيعي.
التوحيد
التوحيد هو عملية قياس قيم البيانات بطريقة تجعلها تكتسب خصائص التوزيع الطبيعي القياسي. هذا يعني أنه يتم إعادة قياس البيانات بحيث يصبح المتوسط صفراً وتكون البيانات لها انحراف معياري موحد.
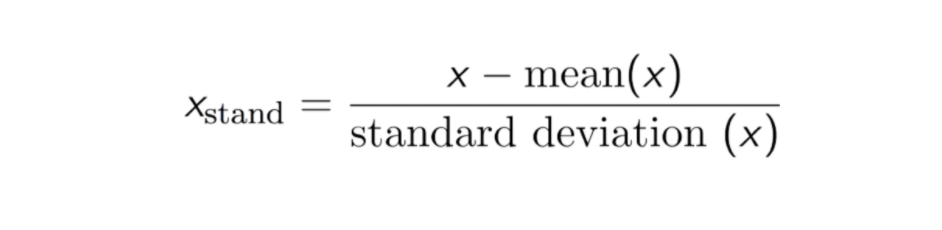
لا تحتوي القيم الموحدة Standardized values على نطاق محدد ثابت مثل القيم المطبعة Normalised values.
دعونا نلقي نظرة على الكود. إذا لم يكن لديك مجموعات تدريب واختبار منفصلة، فيمكنك تقسيم مجموعة البيانات إلى جزأين – أحدهما للتدريب والآخر للاختبار.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
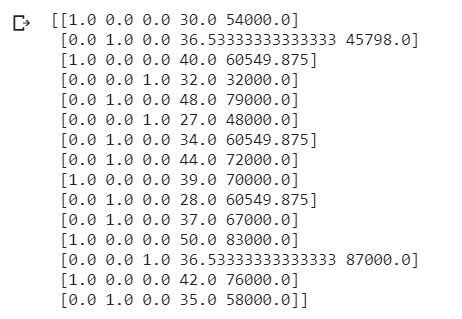
print(X_train)
print(X_test)

الآن سنقوم باستيراد فئة StandardScaler لتوحيد جميع المتغيرات.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train[:, 3:] = sc.fit_transform(X_train[:, 3:])
X_test[:, 3:] = sc.transform(X_test[:, 3:])
print(X_train)

print(X_test)
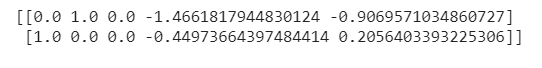
نلاحظ أن جميع قيمنا قد تم تحجيمها. هذه هي الطريقة التي يتم بها تنفيذ ميزة تحجيم الميزات.
ملاحظة: ضع في اعتبارك أنه أثناء تحجيم الميزات، يجب علينا فقط استخدام المتغيرات المستقلة لمجموعة التدريب لحساب المتوسط (x) والانحراف المعياري (x). ثم يجب استخدام نفس قيم المتوسط (x) والانحراف المعياري (x) لمجموعة التدريب لتطبيق تحجيم الميزة على مجموعة الاختبار.
الاستنتاج
الآن تم تصميم مجموعة البيانات الخاصة بنا بشكل هندسي وجاهز لتضمينها في نموذج التعلم الآلي. يمكن الآن استخدام مجموعة البيانات هذه لتدريب النموذج لعمل التنبؤات المرغوبة. لقد صممنا جميع ميزاتنا بشكل فعال. تم التعامل مع القيم المفقودة، وتم ترميز المتغيرات الفئوية بشكل فعال وتم تحجيم الميزات إلى مقياس موحد. كن مطمئنًا، يمكننا الآن الجلوس بأمان وانتظار بياناتنا لتوليد بعض النتائج المذهلة!
بمجرد الانتهاء من تصميم جميع المتغيرات في مجموعة البيانات الخاصة بك بشكل فعال، يمكنك التأكد من إنشاء نماذج تتمتع بأفضل كفاءة ممكنة حيث يمكن لجميع الخوارزميات الآن أن تؤدي إلى إمكاناتها المثلى.
هذا هو سحر هندسة الميزات!
لذا في المرة القادمة التي تضع فيها يديك على مجموعة بيانات، أخرج مونيكا (ممثلة في مسلسل فريندز) بداخلك وابدأ في تنظيف تلك البيانات الأولية! أنا متأكد من أنك سوف تتفوق عليها بمساعدة جميع أدوات هندسة الميزات المكتسبة حديثًا والموجودة لديك الآن في مربع أدوات التعلم الآلي الخاص بك!




