

- مقدمة
- ما هو نقل التعلم؟
- ما هو النموذج الذي تم تدريبه مسبقًا؟
- لماذا نستخدم النماذج المدربة مسبقًا؟
- كيف يمكنني استخدام النماذج المدربة مسبقًا؟
- طرق ضبط النموذج
- استخدم النماذج المدربة مسبقًا لتحديد الأرقام المكتوبة بخط اليد
- الملخص
مقدمة
الشبكات العصبية Neural networks هي سلالة مختلفة من النماذج مقارنة بخوارزميات التعلم الآلي الخاضعة للإشراف supervised machine learning algorithms. لماذا اقول ذلك؟ هناك أسباب متعددة لذلك، ولكن أبرزها تكلفة تشغيل الخوارزميات على الجهاز.
في عالم اليوم، تعتبر ذاكرة الوصول العشوائي على الجهاز رخيصة ومتوفرة بكثرة. أنت بحاجة إلى مئات الجيجابايت من ذاكرة الوصول العشوائي لتشغيل مشكلة التعلم الآلي المعقدة للغاية تحت الإشراف – يمكن أن تكون ملكك مقابل القليل من الاستثمار / الإيجار. من ناحية أخرى، فإن الوصول إلى وحدات معالجة الرسومات GPU ليس رخيصًا. تحتاج إلى الوصول إلى مائة جيجابايت من VRAM على وحدات معالجة الرسومات – لن يكون الأمر مباشرًا وسيتضمن تكاليف كبيرة.
الآن، قد يتغير ذلك في المستقبل. ولكن في الوقت الحالي، هذا يعني أنه يتعين علينا أن نكون أكثر ذكاءً بشأن الطريقة التي نستخدم بها مواردنا في حل مشكلات التعلم العميق. على وجه الخصوص، عندما نحاول حل مشاكل الحياة الواقعية المعقدة في مجالات مثل التعرف على الصور والصوت. بمجرد أن يكون لديك بعض الطبقات المخفية في النموذج الخاص بك، فإن إضافة طبقة أخرى من الطبقة المخفية ستحتاج إلى موارد هائلة.
لحسن الحظ، هناك شيء يسمى “نقل التعلم Transfer Learning” والذي يمكننا من استخدام نماذج مدربة مسبقًا pre-trained models من أشخاص آخرين من خلال إجراء تغييرات صغيرة. في هذه المقالة، سأخبرك كيف يمكننا استخدام النماذج المدربة مسبقًا لتسريع حلولنا.
لمعرفة المزيد حول النماذج المدربة مسبقًا ونقل التعلم وحالات الاستخدام الخاصة بها، يمكنك الاطلاع على المقالات التالية:
Deep Learning for Everyone: Master the Powerful Art of Transfer Learning using PyTorch
Top 10 Pretrained Models to get you Started with Deep Learning (Part 1 – Computer Vision)
8 Excellent Pretrained Models to get you Started with Natural Language Processing (NLP)
ملاحظة: تفترض هذه المقالة الإلمام الأساسي بالشبكات العصبية Neural networks والتعلم العميق deep learning. إذا كنت جديدًا في التعلم العميق، فإنني أوصي بشدة بقراءة المقالات التالية أولاً:
What is deep learning and why is it getting so much attention?
Deep Learning vs. Machine Learning – the essential differences you need to know!
25 Must Know Terms & concepts for Beginners in Deep Learning
Why are GPUs necessary for training Deep Learning models?
ما هو نقل التعلم؟
دعونا نبدأ بتطوير مثال لنقل التعلم. دعونا نفهم من مدرس بسيط – تشبيه الطالب.
يتمتع المعلم بسنوات من الخبرة في موضوع معين يقوم بتدريسه. مع كل هذه المعلومات المتراكمة، فإن المحاضرات التي يتلقاها الطلاب هي نظرة عامة موجزة وموجزة عن الموضوع. لذلك يمكن اعتباره بمثابة “نقل” للمعلومات من المتعلم إلى المبتدئ.

مع الأخذ في الاعتبار هذا التشبيه، نقارن هذا بالشبكة العصبية. يتم تدريب الشبكة العصبية على البيانات. تكتسب هذه الشبكة المعرفة من هذه البيانات، والتي يتم تجميعها على أنها “أوزان weights” للشبكة. يمكن استخراج هذه الأوزان ثم نقلها إلى أي شبكة عصبية أخرى. بدلاً من تدريب الشبكة العصبية الأخرى من البداية، نقوم “بنقل transfer” الميزات المكتسبة.
الآن، دعونا نفكر في أهمية نقل التعلم من خلال الارتباط بتطورنا. وما هي أفضل طريقة من استخدام نقل التعلم لهذا الغرض! لذلك أنا أختار مفهومًا تطرق إليه Tim Urban من إحدى مقالاته الأخيرة على waitbutwhy.com
يوضح تيم أنه قبل اختراع اللغة، كان على كل جيل من البشر إعادة ابتكار المعرفة لأنفسهم، وهكذا كان نمو المعرفة يحدث من جيل إلى آخر:

ثم اخترعنا اللغة! طريقة لنقل التعلم من جيل إلى آخر وهذا ما حدث خلال نفس الإطار الزمني:
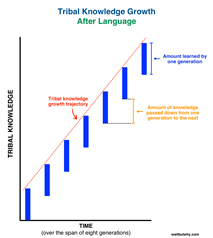
أليست هذه اللعبة استثنائية وذات قوة عظمى؟ لذا، فإن نقل التعلم عن طريق تمرير الأوزان يعادل اللغة المستخدمة لنشر المعرفة عبر الأجيال في التطور البشري.
ما هو النموذج الذي تم تدريبه مسبقًا؟
ببساطة، النموذج المدرب مسبقًا هو نموذج تم إنشاؤه بواسطة شخص آخر لحل مشكلة مماثلة. بدلاً من بناء نموذج من البداية لحل مشكلة مماثلة، يمكنك استخدام النموذج المدرب على مشكلة أخرى كنقطة بداية.
على سبيل المثال، إذا كنت ترغب في بناء سيارة التعلم الذاتي. يمكنك قضاء سنوات في إنشاء خوارزمية جيدة للتعرف على الصور من البداية أو يمكنك أن تأخذ نموذجًا أوليًا (نموذجًا مدربًا مسبقًا) من Google والذي تم إنشاؤه على بيانات ImageNet لتحديد الصور في تلك الصور.
قد لا يكون النموذج المدرَّب مسبقًا دقيقًا بنسبة 100٪ في تطبيقك، ولكنه يوفر الجهود الضخمة المطلوبة لإعادة اختراع العجلة. دعني أريكم هذا بمثال حديث.
لماذا نستخدم النماذج المدربة مسبقًا؟
قضيت الأسبوع الماضي أعمل على حل مشكلة في منصة CrowdAnalytix – تحديد السمات من صور حالة الهاتف المحمول. كانت هذه مشكلة في تصنيف الصور حيث حصلنا على 4591 صورة في مجموعة بيانات التدريب و1200 صورة في مجموعة بيانات الاختبار. كان الهدف هو تصنيف الصور إلى واحدة من الفئات الـ 16. بعد خطوات المعالجة المسبقة الأساسية، بدأت بنموذج MLP بسيط مع المعمارية التالية:

لتبسيط البنية أعلاه بعد تسوية صورة الإدخال [224X224X3] في [150528] ، استخدمت ثلاث طبقات مخفية تحتوي على 500 و 500 و 500 خلية عصبية على التوالي. تحتوي طبقة المخرجات على 16 خلية عصبية تتوافق مع عدد الفئات التي نحتاج فيها لتصنيف الصورة المدخلة.
بالكاد تمكنت من تحقيق دقة تدريب بلغت 6.8٪ واتضح أنها سيئة للغاية. حتى تجربة الطبقات المخفية hidden layers، وعدد الخلايا العصبية في الطبقات المخفية ومعدلات التسرب dropout rates. لم أتمكن من زيادة دقة التدريب بشكل كبير. أدت زيادة الطبقات المخفية وعدد الخلايا العصبية إلى تشغيل حقبة (epoch) واحدة لمدة 20 ثانية على وحدة معالجة الرسومات Titan X GPU الخاصة بي مع ذاكرة VRAM بسعة 12 جيجابايت.
يوجد أدناه ناتج التدريب باستخدام نموذج MLP مع البنية المذكورة أعلاه
Epoch 10/10
50/50 [==============================] – 21s – loss: 15.0100 – acc: 0.0688
كما يمكنك أن ترى أن MLP لن تعطيني أي نتائج أفضل دون زيادة وقت التدريب بشكل كبير. لذلك انتقلت إلى الشبكة العصبية التلافيفية CNN لمعرفة كيفية أدائها على مجموعة البيانات هذه وما إذا كنت سأتمكن من زيادة دقة التدريب.
كان لدى CNN المعمارية أدناه :

تستخدم 3 كتل تلافيفية مع كل كتلة تتبع المعمارية أدناه:
- 32 فلتر مقاس 5×5
- دالة التنشيط (Activation function) relu
- طبقة التجميع الأقصى (Max pooling layer) مقاس 4 × 4
النتيجة التي تم الحصول عليها بعد أن تم تسطيح الكتلة التلافيفية convolutional blocks النهائية إلى حجم [256] وتمريرها إلى طبقة مخفية واحدة بها 64 خلية عصبية. تم تمرير ناتج الطبقة المخفية إلى طبقة الإخراج بعد معدل تسرب 0.5.
يتم تلخيص النتيجة التي تم الحصول عليها من خلال المعمارية أعلاه :
Epoch 10/10
50/50 [==============================] – 21s – loss: 13.5733 – acc: 0.1575
على الرغم من زيادة دقتي مقارنةً بإخراج MLP ، إلا أنها زادت أيضًا من الوقت المستغرق لتشغيل حقبة واحدة – 21 ثانية.
لكن النقطة الرئيسية التي يجب ملاحظتها هي أن فئة الأغلبية في مجموعة البيانات كانت حوالي 17.6٪. لذلك، حتى لو توقعنا أن تكون فئة كل صورة في مجموعة بيانات التدريب هي فئة الأغلبية، فسنكون قد حققنا أداءً أفضل من MLP و CNN على التوالي. أدت إضافة المزيد من الكتل التلافيفية إلى زيادة وقت التدريب بشكل كبير. قادني هذا إلى التبديل إلى استخدام النماذج المدربة مسبقًا حيث لن أضطر إلى تدريب المعمارية بأكملها ولكن فقط بضع طبقات.
لذلك ، استخدمت نموذج VGG16 الذي تم تدريبه مسبقًا على مجموعة بيانات ImageNet وتم توفيره في مكتبة keras للاستخدام. يوجد أدناه بنية نموذج VGG16 الذي استخدمته.

التغيير الوحيد الذي أجريته على البنية الحالية لـ VGG16 هو تغيير طبقة softmax مع 1000 إخراج إلى 16 فئة مناسبة لمشكلتنا وإعادة تدريب الطبقة الكثيفة dense layer.
أعطتني هذه البنية دقة 70٪ أفضل بكثير من MLP و CNN. أيضًا ، كانت أكبر فائدة لاستخدام نموذج VGG16 المدرَّب مسبقًا هي الوقت الضئيل تقريبًا لتدريب الطبقة الكثيفة بدقة أكبر.
لذلك، تقدمت في هذا النهج المتمثل في استخدام نموذج مدرب مسبقًا وكانت الخطوة التالية هي ضبط طراز VGG16 الخاص بي ليناسب هذه المشكلة.
كيف يمكنني استخدام النماذج المدربة مسبقًا؟
ما هو هدفنا عندما نقوم بتدريب شبكة عصبية؟ نرغب في تحديد الأوزان الصحيحة للشبكة من خلال التكرارات المتعددة للأمام والخلف. من خلال استخدام النماذج المدربة مسبقًا والتي تم تدريبها مسبقًا على مجموعات البيانات الكبيرة، يمكننا استخدام الأوزان والبنية التي تم الحصول عليها بشكل مباشر وتطبيق التعلم على بيان المشكلة الخاص بنا. هذا هو المعروف باسم نقل التعلم. نحن “ننقل التعلم” للنموذج المدرب مسبقًا إلى بيان المشكلة المحدد لدينا.
يجب أن تكون حذرًا للغاية أثناء اختيار الطراز المدرب مسبقًا الذي يجب أن تستخدمه في حالتك. إذا كانت عبارة المشكلة التي لدينا مختلفة تمامًا عن تلك التي تم تدريب النموذج المدرب مسبقًا عليها – فإن التنبؤ الذي سنحصل عليه سيكون غير دقيق للغاية. على سبيل المثال، قد يعمل النموذج الذي تم تدريبه مسبقًا على التعرف على الكلام بشكل مروع إذا حاولنا استخدامه لتحديد الكائنات التي تستخدمها.
نحن محظوظون لأن العديد من الهياكل المدربة مسبقًا متاحة لنا مباشرة في مكتبة Keras. تم استخدام مجموعة بيانات Imagenet على نطاق واسع لبناء هياكل مختلفة نظرًا لأنها كبيرة بما يكفي (1.2 مليون صورة) لإنشاء نموذج عام. بيان المشكلة هو تدريب نموذج يمكنه تصنيف الصور بشكل صحيح إلى 1000 فئة كائن منفصلة. تمثل فئات الصور التي يبلغ عددها 1000 فئات الكائنات التي نواجهها في حياتنا اليومية، مثل أنواع الكلاب والقطط والأشياء المنزلية المختلفة وأنواع المركبات وما إلى ذلك.
تُظهر هذه الشبكات المُدرَّبة مسبقًا قدرة قوية على التعميم على الصور خارج مجموعة بيانات ImageNet عبر تعلم النقل. نقوم بإجراء تعديلات على النموذج الموجود مسبقًا عن طريق ضبط النموذج. نظرًا لأننا نفترض أن الشبكة المدربة مسبقًا قد تم تدريبها جيدًا، فلن نرغب في تعديل الأوزان في وقت مبكر جدًا وبالكثير. أثناء التعديل، نستخدم بشكل عام معدل تعلم أصغر من المعدل المستخدم لتدريب النموذج في البداية.
طرق ضبط النموذج
- استخراج الميزات Feature extraction: يمكننا استخدام نموذج مدرب مسبقًا كآلية لاستخراج الميزات. ما يمكننا القيام به هو أنه يمكننا إزالة طبقة الإخراج (الطبقة التي تعطي احتمالات التواجد في كل فئة من الفئات 1000) ثم استخدام الشبكة بالكامل كمستخرج ميزة ثابتة لمجموعة البيانات الجديدة.
- استخدام بنية النموذج المدرب مسبقًا: ما يمكننا فعله هو استخدام بنية النموذج بينما نقوم بتهيئة جميع الأوزان بشكل عشوائي وتدريب النموذج وفقًا لمجموعة البيانات الخاصة بنا مرة أخرى.
- تدريب بعض الطبقات بينما تقوم بتجميد البعض الآخر : هناك طريقة أخرى لاستخدام نموذج تم تدريبه مسبقًا وهي التدريب جزئيًا. ما يمكننا القيام به هو الاحتفاظ بأوزان الطبقات الأولية للنموذج مجمدة بينما نقوم بإعادة تدريب الطبقات العليا فقط. يمكننا تجربة واختبار عدد الطبقات التي سيتم تجميدها وعدد الطبقات التي سيتم تدريبها.
يجب أن يساعدك الرسم البياني أدناه في اتخاذ قرار بشأن كيفية المضي قدمًا في استخدام النموذج المدرب مسبقًا في حالتك:
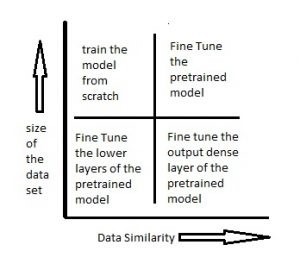
السيناريو 1: حجم مجموعة البيانات صغير بينما تشابه البيانات مرتفع جدًا – في هذه الحالة، نظرًا لأن تشابه البيانات مرتفع جدًا، لا نحتاج إلى إعادة تدريب النموذج. كل ما نحتاج إلى القيام به هو تخصيص وتعديل طبقات الإخراج وفقًا لبيان المشكلة. نحن نستخدم النموذج الجاهز كمستخرج للميزات. لنفترض أننا قررنا استخدام نماذج مدربة على Imagenet لتحديد ما إذا كانت مجموعة الصور الجديدة بها قطط أم كلاب. هنا الصور التي نحتاج إلى تحديدها ستكون مشابهة لـ imagenet، لكننا نحتاج فقط إلى فئتين كمخرجات – قطط أو كلاب. في هذه الحالة، كل ما نقوم به هو تعديل الطبقات الكثيفة وطبقة softmax النهائية لإخراج فئتين بدلاً من 1000.
السيناريو 2: حجم البيانات صغير وكذلك تشابه البيانات منخفض جدًا – في هذه الحالة يمكننا تجميد الطبقات الأولية (دعنا نقول k) للنموذج الذي تم اختباره مسبقًا وتدريب الطبقات المتبقية (n-k) مرة أخرى. سيتم بعد ذلك تخصيص الطبقات العليا لمجموعة البيانات الجديدة. نظرًا لأن مجموعة البيانات الجديدة ذات تشابه منخفض، فمن المهم إعادة تدريب الطبقات العليا وتخصيصها وفقًا لمجموعة البيانات الجديدة. يتم تعويض الحجم الصغير لمجموعة البيانات من خلال حقيقة أن الطبقات الأولية يتم الاحتفاظ بها مسبقًا (والتي تم تدريبها على مجموعة بيانات كبيرة مسبقًا) ويتم تجميد أوزان تلك الطبقات.
السيناريو 3: حجم مجموعة البيانات كبير ولكن تشابه البيانات منخفض جدًا – في هذه الحالة، نظرًا لأن لدينا مجموعة بيانات كبيرة، سيكون تدريب الشبكة العصبية لدينا فعالاً. ومع ذلك، نظرًا لأن البيانات التي لدينا مختلفة جدًا مقارنة بالبيانات المستخدمة لتدريب نماذجنا التي تم اختبارها مسبقًا. لن تكون التنبؤات التي تم إجراؤها باستخدام النماذج التي تم اختبارها مسبقًا فعالة. وبالتالي، من الأفضل تدريب الشبكة العصبية من البداية وفقًا لبياناتك.
السيناريو 4: حجم البيانات كبير وكذلك يوجد تشابه كبير في البيانات – هذا هو الوضع المثالي. في هذه الحالة، يجب أن يكون النموذج الذي تم اختباره مسبقًا هو الأكثر فعالية. أفضل طريقة لاستخدام النموذج هي الاحتفاظ ببنية النموذج والأوزان الأولية للنموذج. ثم يمكننا إعادة تدريب هذا النموذج باستخدام الأوزان كما تم تهيئتها في النموذج المدرب مسبقًا.
استخدام النماذج المدربة مسبقًا لتحديد الأرقام المكتوبة بخط اليد
دعونا نحاول الآن استخدام نموذج تم اختباره مسبقًا لحل مشكلة بسيطة. هناك العديد من البنى التي تم تدريبها على مجموعة بيانات imageNet. يمكنك الاطلاع على العديد من البنى هنا. لقد استخدمت vgg16 كنموذج معماري تم اختباره مسبقًا وحاولت تحديد الأرقام المكتوبة بخط اليد handwritten digits باستخدامه. دعونا نرى في أي من السيناريوهات المذكورة أعلاه قد تقع هذه المشكلة. لدينا حوالي 60.000 صورة تدريبية للأرقام المكتوبة بخط اليد. مجموعة البيانات هذه صغيرة بالتأكيد. لذا فإن الموقف إما أن يقع في السيناريو 1 أو السيناريو 2. سنحاول حل المشكلة باستخدام هذين السيناريوهين. يمكن تنزيل مجموعة البيانات من هنا.
- أعادة تدريب طبقات الإخراج الكثيفة فقط : هنا نستخدم vgg16 كمستخرج للميزات. ثم نستخدم هذه الميزات ونرسلها إلى طبقات كثيفة يتم تدريبها وفقًا لمجموعة البيانات الخاصة بنا. يتم أيضًا استبدال طبقة الإخراج بطبقة softmax الجديدة الخاصة بنا ذات الصلة بمشكلتنا. طبقة الإخراج في vgg16 عبارة عن تنشيط softmax مع 1000 فئة. نقوم بإزالة هذه الطبقة واستبدالها بطبقة softmax من 10 فئات. نقوم فقط بتدريب أوزان هذه الطبقات ونحاول تحديد الأرقام.
# importing required libraries
from keras.models import Sequential
from scipy.misc import imread
get_ipython().magic('matplotlib inline')
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras.layers import Dense
import pandas as pd
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.applications.vgg16 import decode_predictions
train=pd.read_csv("R/Data/Train/train.csv")
test=pd.read_csv("R/Data/test.csv")
train_path="R/Data/Train/Images/train/"
test_path="R/Data/Train/Images/test/"
from scipy.misc import imresize
# preparing the train dataset
train_img=[]
for i in range(len(train)):
temp_img=image.load_img(train_path+train['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
train_img.append(temp_img)
#converting train images to array and applying mean subtraction processing
train_img=np.array(train_img)
train_img=preprocess_input(train_img)
# applying the same procedure with the test dataset
test_img=[]
for i in range(len(test)):
temp_img=image.load_img(test_path+test['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
test_img.append(temp_img)
test_img=np.array(test_img)
test_img=preprocess_input(test_img)
# loading VGG16 model weights
model = VGG16(weights='imagenet', include_top=False)
# Extracting features from the train dataset using the VGG16 pre-trained model
features_train=model.predict(train_img)
# Extracting features from the train dataset using the VGG16 pre-trained model
features_test=model.predict(test_img)
# flattening the layers to conform to MLP input
train_x=features_train.reshape(49000,25088)
# converting target variable to array
train_y=np.asarray(train['label'])
# performing one-hot encoding for the target variable
train_y=pd.get_dummies(train_y)
train_y=np.array(train_y)
# creating training and validation set
from sklearn.model_selection import train_test_split
X_train, X_valid, Y_train, Y_valid=train_test_split(train_x,train_y,test_size=0.3, random_state=42)
# creating a mlp model
from keras.layers import Dense, Activation
model=Sequential()
model.add(Dense(1000, input_dim=25088, activation='relu',kernel_initializer='uniform'))
keras.layers.core.Dropout(0.3, noise_shape=None, seed=None)
model.add(Dense(500,input_dim=1000,activation='sigmoid'))
keras.layers.core.Dropout(0.4, noise_shape=None, seed=None)
model.add(Dense(150,input_dim=500,activation='sigmoid'))
keras.layers.core.Dropout(0.2, noise_shape=None, seed=None)
model.add(Dense(units=10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
# fitting the model
model.fit(X_train, Y_train, epochs=20, batch_size=128,validation_data=(X_valid,Y_valid))
- تجميد أوزان الطبقات القليلة الأولى : ما نقوم به هنا هو تجميد أوزان الطبقات الثمانية الأولى من شبكة vgg16 ، بينما نقوم بإعادة تدريب الطبقات اللاحقة. هذا لأن الطبقات القليلة الأولى تلتقط ميزات عامة مثل المنحنيات والحواف التي ترتبط أيضًا بمشكلتنا الجديدة. نريد الحفاظ على هذه الأوزان كما هي وسنعمل على جعل الشبكة تركز على تعلم الميزات الخاصة بمجموعة البيانات في الطبقات اللاحقة.
كود لتجميد أوزان الطبقات الأولى.
from keras.models import Sequential
from scipy.misc import imread
get_ipython().magic('matplotlib inline')
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras.layers import Dense
import pandas as pd
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.applications.vgg16 import decode_predictions
from keras.utils.np_utils import to_categorical
from sklearn.preprocessing import LabelEncoder
from keras.models import Sequential
from keras.optimizers import SGD
from keras.layers import Input, Dense, Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D, Dropout, Flatten, merge, Reshape, Activation
from sklearn.metrics import log_loss
train=pd.read_csv("R/Data/Train/train.csv")
test=pd.read_csv("R/Data/test.csv")
train_path="R/Data/Train/Images/train/"
test_path="R/Data/Train/Images/test/"
from scipy.misc import imresize
train_img=[]
for i in range(len(train)):
temp_img=image.load_img(train_path+train['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
train_img.append(temp_img)
train_img=np.array(train_img)
train_img=preprocess_input(train_img)
test_img=[]
for i in range(len(test)):
temp_img=image.load_img(test_path+test['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
test_img.append(temp_img)
test_img=np.array(test_img)
test_img=preprocess_input(test_img)
from keras.models import Model
def vgg16_model(img_rows, img_cols, channel=1, num_classes=None):
model = VGG16(weights='imagenet', include_top=True)
model.layers.pop()
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
x=Dense(num_classes, activation='softmax')(model.output)
model=Model(model.input,x)
#To set the first 8 layers to non-trainable (weights will not be updated)
for layer in model.layers[:8]:
layer.trainable = False
# Learning rate is changed to 0.001
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
return model
train_y=np.asarray(train['label'])
le = LabelEncoder()
train_y = le.fit_transform(train_y)
train_y=to_categorical(train_y)
train_y=np.array(train_y)
from sklearn.model_selection import train_test_split
X_train, X_valid, Y_train, Y_valid=train_test_split(train_img,train_y,test_size=0.2, random_state=42)
# Example to fine-tune on 3000 samples from Cifar10
img_rows, img_cols = 224, 224 # Resolution of inputs
channel = 3
num_classes = 10
batch_size = 16
nb_epoch = 10
# Load our model
model = vgg16_model(img_rows, img_cols, channel, num_classes)
model.summary()
# Start Fine-tuning
model.fit(X_train, Y_train,batch_size=batch_size,epochs=nb_epoch,shuffle=True,verbose=1,validation_data=(X_valid, Y_valid))
# Make predictions
predictions_valid = model.predict(X_valid, batch_size=batch_size, verbose=1)
# Cross-entropy loss score
score = log_loss(Y_valid, predictions_valid)
الملخص
آمل أن تتمكن الآن من تطبيق نماذج مدربة مسبقًا على بيانات مشكلتك. تأكد من أن النموذج المدرب مسبقًا الذي حددته قد تم تدريبه على مجموعة بيانات مماثلة لتلك التي ترغب في استخدامه عليها. هناك العديد من البنى التي جربها الأشخاص على أنواع مختلفة من مجموعات البيانات وأنا أشجعك بشدة على متابعة هذه البنى وتطبيقها على بيانات المشكلة الخاصة بك. لا تتردد في مناقشة شكوكك واهتماماتك في قسم التعليقات.

