
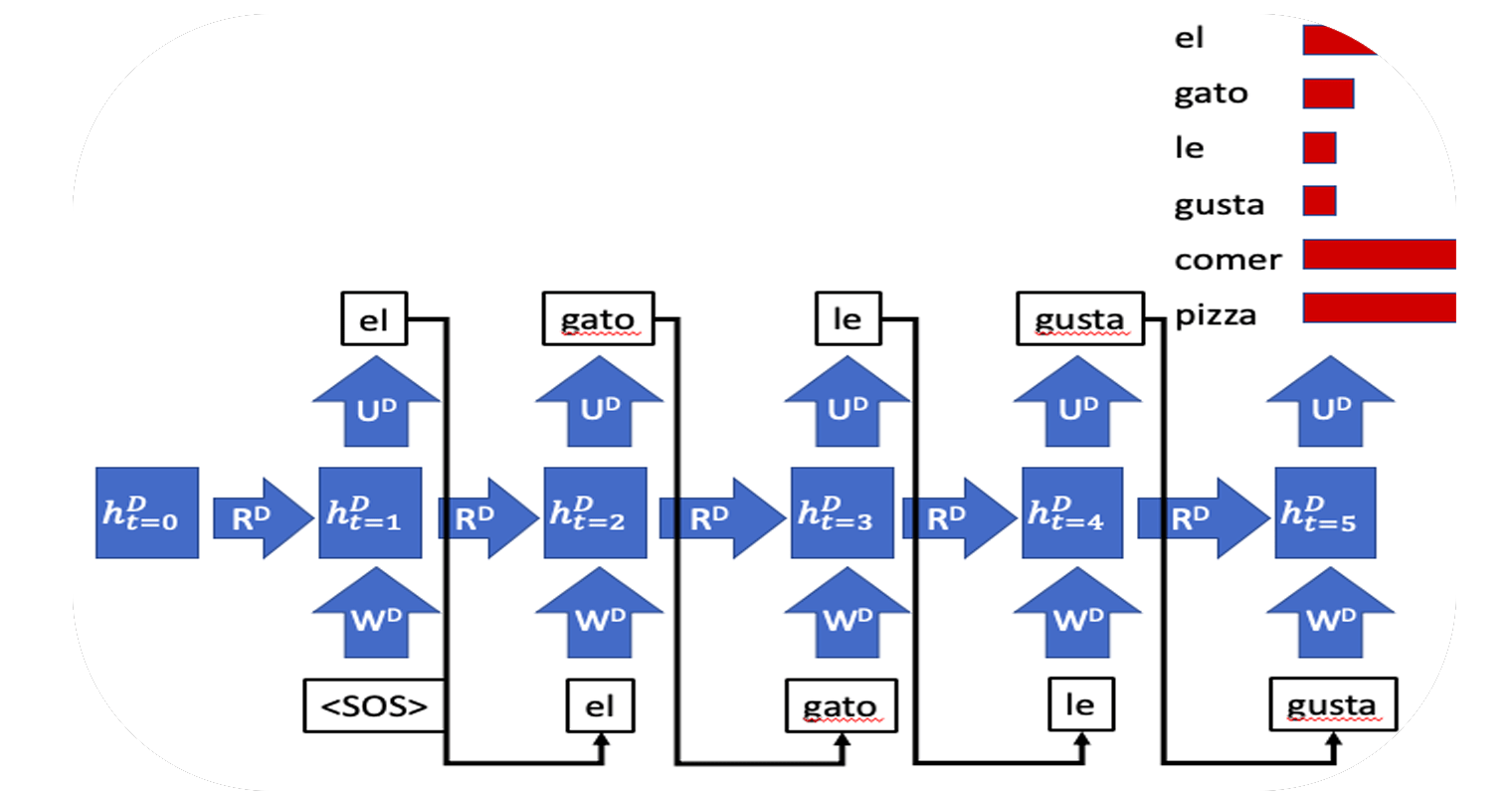
- المعالجة المسبقة للبيانات
- المعالجة المسبقة لخط أنابيب للترجمة الآلية
- تدريب شبكة عصبية للترجمة الآلية
تعد الترجمة الآلية Machine Translation واحدة من أكثر المهام تحديًا في الذكاء الاصطناعي والتي تعمل من خلال التحقق من استخدام البرنامج لترجمة نص أو خطاب من لغة إلى أخرى. في هذه المقالة، سوف آخذك عبر الترجمة الآلية باستخدام الشبكات العصبية.
في نهاية هذه المقالة، ستتعلم تطوير نموذج ترجمة آلية باستخدام الشبكات العصبية وبايثون. سأستخدم اللغة الإنجليزية كمدخل وسنقوم بتدريب نموذج الترجمة الآلية لدينا لإعطاء المخرجات باللغة الفرنسية. لنبدأ الآن باستيراد جميع المكتبات التي نحتاجها لهذه المهمة:
import collections
import helper
import numpy as np
import project_tests as tests
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import GRU, Input, Dense, TimeDistributed, Activation, RepeatVector, Bidirectional
from keras.layers.embeddings import Embedding
from keras.optimizers import Adam
from keras.losses import sparse_categorical_crossentropy
سأقوم أولاً بإنشاء دالتين لتحميل البيانات ودالة أخرى لاختبار بياناتنا:
import os
def load_data(path):
"""
Load dataset
"""
input_file = os.path.join(path)
with open(input_file, "r") as f:
data = f.read()
return data.split('\n')
def _test_model(model, input_shape, output_sequence_length, french_vocab_size):
if isinstance(model, Sequential):
model = model.model
assert model.input_shape == (None, *input_shape[1:]),\
'Wrong input shape. Found input shape {} using parameter input_shape={}'.format(model.input_shape, input_shape)
assert model.output_shape == (None, output_sequence_length, french_vocab_size),\
'Wrong output shape. Found output shape {} using parameters output_sequence_length={} and french_vocab_size={}'\
.format(model.output_shape, output_sequence_length, french_vocab_size)
assert len(model.loss_functions) > 0,\
'No loss function set. Apply the `compile` function to the model.'
assert sparse_categorical_crossentropy in model.loss_functions,\
'Not using `sparse_categorical_crossentropy` function for loss.
لنقم الآن بتحميل البيانات وإلقاء نظرة على بعض الأفكار من البيانات، حيث تحتوي مجموعة البيانات التي أستخدمها هنا على عبارة باللغة الإنجليزية مع ترجمتها:
english_sentences = helper.load_data('data/small_vocab_en')
french_sentences = helper.load_data('data/small_vocab_fr')
print('Dataset Loaded')
تم تحميل مجموعة البيانات
for sample_i in range(2):
print('small_vocab_en Line {}: {}'.format(sample_i + 1, english_sentences[sample_i]))
print('small_vocab_fr Line {}: {}'.format(sample_i + 1, french_sentences[sample_i]))
small_vocab_en Line 1: new jersey is sometimes quiet during autumn , and it is snowy in april . small_vocab_fr Line 1: new jersey est parfois calme pendant l' automne , et il est neigeux en avril . small_vocab_en Line 2: the united states is usually chilly during july , and it is usually freezing in november . small_vocab_fr Line 2: les états-unis est généralement froid en juillet , et il gèle habituellement en novembre .
أثناء قيامنا بترجمة اللغة، سيتم تحديد مدى تعقيد هذه المشكلة من خلال تعقيد المفردات. كلما كانت مفردات لغتنا أكثر تعقيدًا، كلما كانت مشكلتنا أكثر تعقيدًا. دعونا نلقي نظرة على البيانات لمعرفة البيانات المعقدة التي نتعامل معها:
english_words_counter = collections.Counter([word for sentence in english_sentences for word in sentence.split()])
french_words_counter = collections.Counter([word for sentence in french_sentences for word in sentence.split()])
print('{} English words.'.format(len([word for sentence in english_sentences for word in sentence.split()])))
print('{} unique English words.'.format(len(english_words_counter)))
print('10 Most common words in the English dataset:')
print('"' + '" "'.join(list(zip(*english_words_counter.most_common(10)))[0]) + '"')
print()
print('{} French words.'.format(len([word for sentence in french_sentences for word in sentence.split()])))
print('{} unique French words.'.format(len(french_words_counter)))
print('10 Most common words in the French dataset:')
print('"' + '" "'.join(list(zip(*french_words_counter.most_common(10)))[0]) + '"')
1823250 English words.
227 unique English words.
10 Most common words in the English dataset:
"is" "," "." "in" "it" "during" "the" "but" "and" "sometimes"
1961295 French words.
355 unique French words.
10 Most common words in the French dataset:
"est" "." "," "en" "il" "les" "mais" "et" "la" "parfois"
المعالجة المسبقة للبيانات
في التعلم الآلي أينما نتعامل مع أي نوع من القيم النصية، نحتاج أولاً إلى تحويل القيم النصية إلى تسلسلات من الأعداد الصحيحة باستخدام طريقتين أساسيتين مثل الترميز Tokenize والحشو Padding. لنبدأ الآن بالترميز Tokenization:
def tokenize(x):
x_tk = Tokenizer(char_level = False)
x_tk.fit_on_texts(x)
return x_tk.texts_to_sequences(x), x_tk
text_sentences = [
'The quick brown fox jumps over the lazy dog .',
'By Jove , my quick study of lexicography won a prize .',
'This is a short sentence .']
text_tokenized, text_tokenizer = tokenize(text_sentences)
print(text_tokenizer.word_index)
print()
for sample_i, (sent, token_sent) in enumerate(zip(text_sentences, text_tokenized)):
print('Sequence {} in x'.format(sample_i + 1))
print(' Input: {}'.format(sent))
print(' Output: {}'.format(token_sent))
{'the': 1, 'quick': 2, 'a': 3, 'brown': 4, 'fox': 5, 'jumps': 6, 'over': 7, 'lazy': 8, 'dog': 9, 'by': 10, 'jove': 11, 'my': 12, 'study': 13, 'of': 14, 'lexicography': 15, 'won': 16, 'prize': 17, 'this': 18, 'is': 19, 'short': 20, 'sentence': 21}
Sequence 1 in x
Input: The quick brown fox jumps over the lazy dog .
Output: [1, 2, 4, 5, 6, 7, 1, 8, 9]
Sequence 2 in x
Input: By Jove , my quick study of lexicography won a prize .
Output: [10, 11, 12, 2, 13, 14, 15, 16, 3, 17]
Sequence 3 in x
Input: This is a short sentence .
Output: [18, 19, 3, 20, 21]
دعنا الآن نستخدم طريقة الحشو لعمل كل التسلسلات بنفس الطول:
def pad(x, length=None):
if length is None:
length = max([len(sentence) for sentence in x])
return pad_sequences(x, maxlen = length, padding = 'post')
tests.test_pad(pad)
# Pad Tokenized output
test_pad = pad(text_tokenized)
for sample_i, (token_sent, pad_sent) in enumerate(zip(text_tokenized, test_pad)):
print('Sequence {} in x'.format(sample_i + 1))
print(' Input: {}'.format(np.array(token_sent)))
print(' Output: {}'.format(pad_sent))
Sequence 1 in x
Input: [1 2 4 5 6 7 1 8 9]
Output: [1 2 4 5 6 7 1 8 9 0]
Sequence 2 in x
Input: [10 11 12 2 13 14 15 16 3 17]
Output: [10 11 12 2 13 14 15 16 3 17]
Sequence 3 in x
Input: [18 19 3 20 21]
Output: [18 19 3 20 21 0 0 0 0 0]
المعالجة المسبقة لخط أنابيب للترجمة الآلية
دعنا الآن نحدد دالة المعالجة المسبقة لإنشاء خط أنابيب لمهمة الترجمة الآلية حتى نتمكن من استخدام هذا النموذج في المستقبل أيضًا:
def preprocess(x, y):
preprocess_x, x_tk = tokenize(x)
preprocess_y, y_tk = tokenize(y)
preprocess_x = pad(preprocess_x)
preprocess_y = pad(preprocess_y)
# Keras's sparse_categorical_crossentropy function requires the labels to be in 3 dimensions
preprocess_y = preprocess_y.reshape(*preprocess_y.shape, 1)
return preprocess_x, preprocess_y, x_tk, y_tk
preproc_english_sentences, preproc_french_sentences, english_tokenizer, french_tokenizer =\
preprocess(english_sentences, french_sentences)
max_english_sequence_length = preproc_english_sentences.shape[1]
max_french_sequence_length = preproc_french_sentences.shape[1]
english_vocab_size = len(english_tokenizer.word_index)
french_vocab_size = len(french_tokenizer.word_index)
print('Data Preprocessed')
print("Max English sentence length:", max_english_sequence_length)
print("Max French sentence length:", max_french_sequence_length)
print("English vocabulary size:", english_vocab_size)
print("French vocabulary size:", french_vocab_size)
Data Preprocessed
Max English sentence length: 15
Max French sentence length: 21
English vocabulary size: 199
French vocabulary size: 344
تدريب شبكة عصبية للترجمة الآلية
الآن، سأقوم هنا بتدريب نموذج باستخدام الشبكات العصبية. لنبدأ بإنشاء دالة مساعدة:
def logits_to_text(logits, tokenizer):
index_to_words = {id: word for word, id in tokenizer.word_index.items()}
index_to_words[0] = '<PAD>'
return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])
print('`logits_to_text` function loaded.')
Data Preprocessed
Max English sentence length: 15
Max French sentence length: 21
English vocabulary size: 199
French vocabulary size: 344
تدريب شبكة عصبية للترجمة الآلية
الآن، سأقوم هنا بتدريب نموذج باستخدام الشبكات العصبية. لنبدأ بإنشاء دالة مساعدة:
def logits_to_text(logits, tokenizer):
index_to_words = {id: word for word, id in tokenizer.word_index.items()}
index_to_words[0] = '<PAD>'
return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])
print('`logits_to_text` function loaded.')
الآن سأقوم بتدريب نموذج RNN والذي سيكون بمثابة قاعدة جيدة جدًا لتسلسلاتنا التي يمكنها ترجمة اللغة الإنجليزية إلى الفرنسية:
def simple_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
learning_rate = 1e-3
input_seq = Input(input_shape[1:])
rnn = GRU(64, return_sequences = True)(input_seq)
logits = TimeDistributed(Dense(french_vocab_size))(rnn)
model = Model(input_seq, Activation('softmax')(logits))
model.compile(loss = sparse_categorical_crossentropy,
optimizer = Adam(learning_rate),
metrics = ['accuracy'])
return model
tests.test_simple_model(simple_model)
tmp_x = pad(preproc_english_sentences, max_french_sequence_length)
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2], 1))
# Train the neural network
simple_rnn_model = simple_model(
tmp_x.shape,
max_french_sequence_length,
english_vocab_size,
french_vocab_size)
simple_rnn_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
# Print prediction(s)
print(logits_to_text(simple_rnn_model.predict(tmp_x[:1])[0], french_tokenizer))
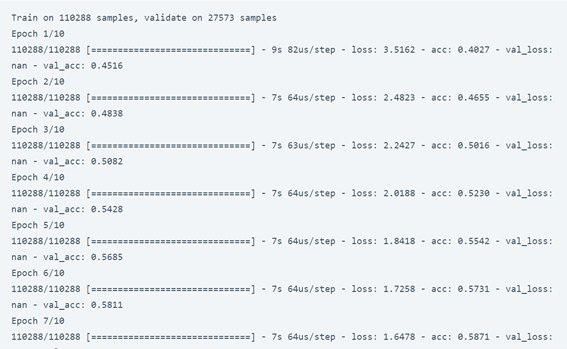
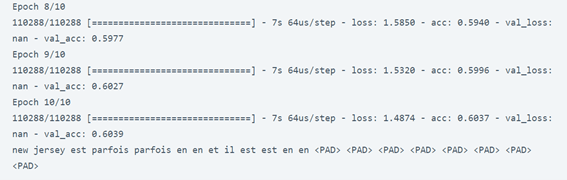
أعطانا نموذج RNN دقة 60 في المائة فقط، دعنا نستخدم شبكة عصبية أكثر تعقيدًا لتدريب نموذجنا بدقة أفضل. سأقوم الآن بتدريب نموذجنا باستخدام RNN مع التضمين embedding. يمثل التضمين متجهًا لكلمة قريبة جدًا من كلمة مشابهة في العالم ذي البعد n. يمثل n هنا حجم متجهات التضمين:
from keras.models import Sequential
def embed_model(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
learning_rate = 1e-3
rnn = GRU(64, return_sequences=True, activation="tanh")
embedding = Embedding(french_vocab_size, 64, input_length=input_shape[1])
logits = TimeDistributed(Dense(french_vocab_size, activation="softmax"))
model = Sequential()
#em can only be used in first layer --> Keras Documentation
model.add(embedding)
model.add(rnn)
model.add(logits)
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
tests.test_embed_model(embed_model)
tmp_x = pad(preproc_english_sentences, max_french_sequence_length)
tmp_x = tmp_x.reshape((-1, preproc_french_sentences.shape[-2]))
embeded_model = embed_model(
tmp_x.shape,
max_french_sequence_length,
english_vocab_size,
french_vocab_size)
embeded_model.fit(tmp_x, preproc_french_sentences, batch_size=1024, epochs=10, validation_split=0.2)
print(logits_to_text(embeded_model.predict(tmp_x[:1])[0], french_tokenizer))
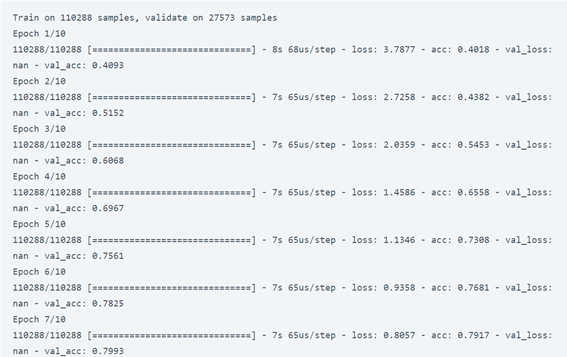
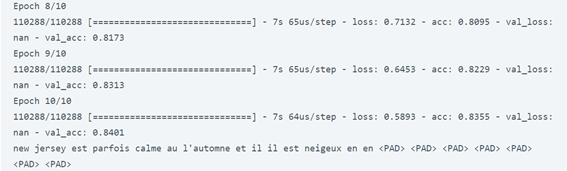
لذلك، أدى نموذج RNN الخاص بنا مع التضمين إلى دقة جيدة جدًا تبلغ 84 في المائة. آمل أن تكون قد أحببت هذا المقال عن الترجمة الآلية باستخدام الشبكات العصبية وبايثون.




Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.