

هل أنت جديد في التعلم العميق وتبحث عن دليل شامل لمساعدتك على فهم الأساسيات وما بعدها؟ لا مزيد من البحث! في هذه المقالة، سوف نتعمق في 20 مفهومًا أساسيًا للتعلم العميق، بدءًا من الأساسيات والانتقال تدريجيًا إلى موضوعات أكثر تقدمًا. من الشبكة العصبية الاصطناعية (ANN) إلى الانحدار الاشتقاقي ودوال والتنشيط (Sigmoid، ReLU، Softmax)، سوف نستكشف كل ما تحتاج إلى معرفته للحصول على أساس متين في التعلم العميق. لذا، تناول قهوتك ودعنا نبدأ!
الشبكة العصبية الاصطناعية Artificial Neural Network (ANN):

الشبكة العصبية الاصطناعية Artificial Neural Network (ANN) هي نموذج رياضي مستوحى من بُنية ودالة الدماغ البشري. يتكون ANN من عقد مترابطة، تُعرف أيضًا باسم الخلايا العصبية الاصطناعية artificial neurons، والتي تعالج المعلومات. كل خلية عصبية تتلقى مدخلات، وتنفذ عملية حسابية، وتولد مخرجات.
مثال: تخيل أنك تحاول تحديد ما إذا كانت الفاكهة تفاحة أم برتقالة بناءً على لونها وشكلها. قد تبدأ بطرح بعض الأسئلة: “هل الفاكهة مستديرة؟” و “هل الثمرة حمراء؟” بناءً على إجابات هذه الأسئلة، ستتمكن من تحديد ما إذا كانت الفاكهة تفاحة أم برتقالة.
الانحدار الاشتقاقي Gradient Descent
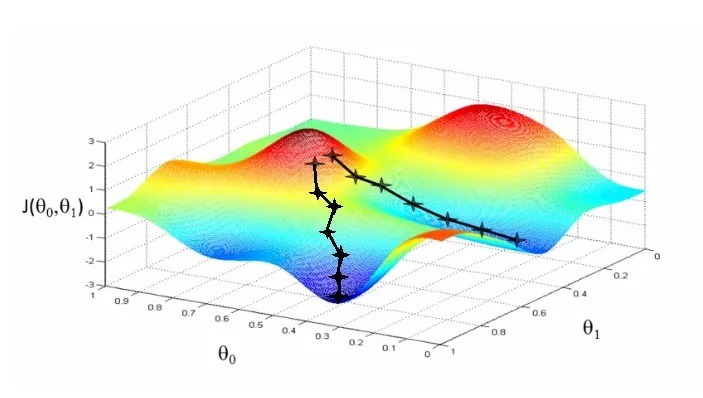
الانحدار الاشتقاقي Gradient Descent هو أحد أكثر المحسّنات شيوعًا. إنها طريقة لتحديث معلمات النموذج بحيث تقل دالة الخسارة (الخطأ) loss function. الفكرة هي حساب الانحدار الاشتقاقي لدالة الخطأ فيما يتعلق بالمعلمات ثم اتخاذ خطوة في الاتجاه الذي يقلل من دالة الخطأ. تتكرر هذه العملية عدة مرات حتى تصبح دالة الخطأ صغيرة قدر الإمكان.
مثال: افترض أنك تقف على قمة تل وتحاول الوصول إلى القاع. لا تريد أن تسلك طريقًا مستقيمًا لأنها قد لا تكون الطريقة الأسرع أو الأكثر فاعلية للأسفل. بدلاً من ذلك، تريد أن تأخذ خطوات صغيرة في الاتجاه الذي سيوصلك إلى أسفل التل بشكل أسرع. هذا مشابه للانحدار الاشتقاقي. يأخذ خطوات صغيرة في الاتجاه الذي سيقلل من الخطأ ويجد الحل الأفضل.
دالة التنشيط Activation Function (Sigmoid, ReLU, Softmax)
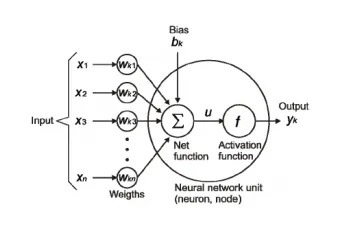
دالة التنشيط activation function مثل حارس البوابة لكل خلية عصبية في ANN. إنه يقرر ما إذا كان يجب “تشغيل” أو “إيقاف تشغيل” الخلية العصبية. أنواع مختلفة من دوال التنشيط تؤدي عملية صنع القرار هذه بطرق مختلفة.
Sigmoid
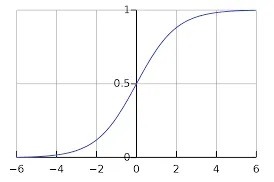
دالة Sigmoid مثل مفتاح الضوء. يقوم بتشغيل الخلايا العصبية أو إيقاف تشغيلها بناءً على الإدخال. إذا كان الإدخال أعلى من عتبة معينة، فإن دالة Sigmoid تُخرج القيمة 1، مما يؤدي إلى تشغيل الخلية العصبية. إذا كان الإدخال أقل من العتبة، فإن دالة Sigmoid تُخرج القيمة 0، مما يؤدي إلى إيقاف تشغيل الخلايا العصبية.
ReLU
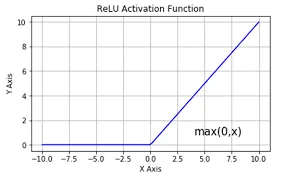
تشبه دالة ReLU (الوحدة الخطية المصححة rectified linear unit) مفتاح الضوء أيضًا، لكنها أكثر تعقيدًا بعض الشيء. إذا كان الإدخال موجبًا، فإن دالة ReLU تُخرج نفس القيمة الإيجابية، مما يؤدي إلى تشغيل الخلية العصبية. إذا كان الإدخال سالبًا، فإن دالة ReLU تخرج 0 ، مما يؤدي إلى إيقاف تشغيل الخلايا العصبية.
Softmax
دالة softmax مثل نظام التصويت. يأخذ في مخرجات جميع الخلايا العصبية في الطبقة ويقرر أي الخلايا العصبية يجب أن يكون لها أكبر تأثير على الناتج النهائي. يقوم بذلك عن طريق تحويل المخرجات إلى احتمالات، مع أعلى احتمال يمثل التأثير الأكبر.
الانتشار الخلفي Backpropagation
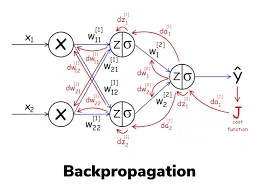
الانتشار الخلفي Backpropagation هو خوارزمية تستخدم لتدريب الشبكات العصبية الاصطناعية (ANNs). إنها طريقة تعلم خاضعة للإشراف supervised learning تتضمن حساب الانحدار الاشتقاقي لدالة الخطأ فيما يتعلق بأوزان الشبكة. الهدف من الانتشار الخلفي هو تحديث الأوزان بطريقة تقلل من قيمة دالة الخطأ.
مثال: فكر في الأمر كمدرس يساعد الطالب على التعلم. يضع المعلم اختبارًا، ويأخذه الطالب، ويصنفه المعلم لمعرفة ما إذا كان الطالب قد حصل على الإجابات الصحيحة أم الخاطئة. ثم يستخدم المعلم هذه المعلومات لتوجيه الطالب في كيفية التحسين في المرة القادمة.
الانتشار الامامي Forward Propagation:
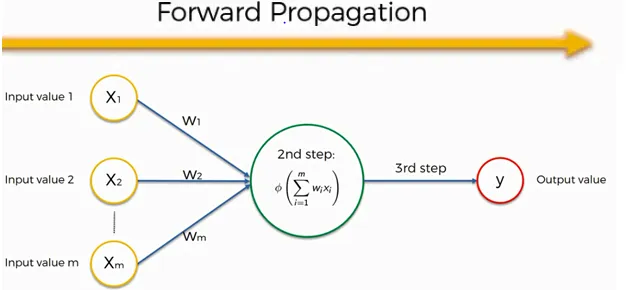
الانتشار الامامي Forward Propagation هي عملية في التعلم العميق حيث يتم تمرير بيانات الإدخال عبر طبقات الشبكة العصبية لتوليد المخرجات. يتم ضرب المدخلات بأوزان كل طبقة، ويتم تمرير النتيجة من خلال دالة التنشيط لإنتاج المخرجات. يصبح هذا الناتج هو المدخلات للطبقة التالية حتى تنتج الطبقة النهائية الناتج النهائي.
مثال: تخيل أن لديك مشكلة في الرياضيات حيث يتعين عليك العثور على الإجابة عن طريق حل عدة خطوات. يشبه الانتشار إلى الأمام حل هذه الخطوات واحدة تلو الأخرى وتمرير النتائج إلى الخطوة التالية. يستمر هذا حتى الخطوة الأخيرة حيث نحصل على الإجابة.
بالطريقة نفسها، في الشبكة العصبية، فإن الانتشار الأمامي هو عملية تمرير بيانات الإدخال عبر الشبكة، طبقة تلو الأخرى، حتى يتم إنشاء المخرجات النهائية. في كل طبقة، يتم تحويل البيانات بناءً على أوزان وتحيزات الخلايا العصبية الموجودة في تلك الطبقة.
الشبكة العصبية التلافيفية Convolutional Neural Network (CNN):
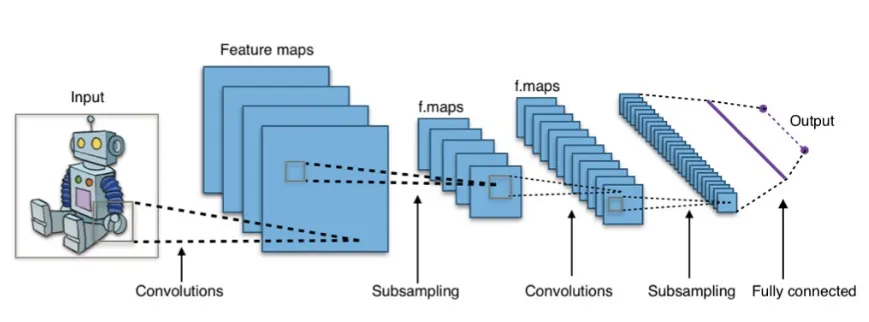
الشبكة العصبية التلافيفية (الالتفافية) Convolutional Neural Network (CNN) هي نوع من الشبكات العصبية الاصطناعية التي تعتبر جيدة بشكل خاص في تحليل الصور ومقاطع الفيديو. يستخدم عملية رياضية تسمى الالتفاف convolution لمسح الصورة وتحديد الأنماط patterns، مثل الأشكال أو الحواف.
مثال: فكر في الأمر كمحقق يبحث عن أدلة في صورة، ولكن بدلاً من البحث عن بكسل واحد في كل مرة، تنظر شبكة CNN إلى وحدات بكسل متعددة في وقت واحد للعثور على أنماط.
الفترة Epoch:
تشير الفترة (حقبة) Epoch في التعلم الآلي والشبكات العصبية الاصطناعية (ANNs) إلى تكرار واحد كامل من خلال مجموعة بيانات التدريب بأكملها. خلال فترة ما، يعالج النموذج ويستخدم المعلومات من بيانات التدريب لتحديث أوزانه weights وتحيزاته biases، من أجل التنبؤ بشكل أفضل بنتيجة التكرار التالي.
مثال: الأمر أشبه بإجراء اختبار عدة مرات، ففي كل مرة تقوم فيها بإجراء الاختبار، يمكنك التعلم من أخطائك والقيام بعمل أفضل في المرة القادمة. بنفس الطريقة، بعد كل حقبة، يجب أن يصبح النموذج أفضل في التعرف على الأنماط في البيانات.
الضبط الزائد Overfitting والضبط الناقص Underfitting
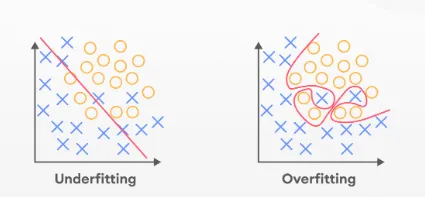
الضبط الزائد Overfitting:
يحدث الضبط الزائد عندما يصبح النموذج جيدًا جدًا في التعرف على الأنماط في بيانات التدريب ويصبح محددًا جدًا لتلك البيانات. هذا يعني أنه لن يعمل بشكل جيد على البيانات الجديدة غير المرئية unseen data.
مثال: تخيل طفلًا يحفظ جميع إجابات الاختبار، لكنه لا يفهم المفاهيم حقًا. سيكون أداء هذا الطفل ضعيفًا في اختبار مماثل مع أسئلة مختلفة.
الضبط الناقص Underfitting:
الضبط الناقص هو عكس الضبط الزائد. يحدث عندما يكون النموذج بسيطًا جدًا ولا يمتلك القدرة الكافية لتعلم الأنماط في البيانات.
مثال: طفل لا يدرس بشكل كافٍ للاختبار ولا يعرف الإجابات. سيكون أداء هذا الطفل ضعيفًا في الاختبار حتى لو كانت الأسئلة هي نفسها التي رأوها من قبل.
التسوية بالدفعات Batch Normalization:

التسوية بالدُفعات Batch Normalization هي تقنية تُستخدم لتطبيع (تسوية) عمليات تنشيط الطبقة عبر دفعة صغيرة mini-batch من البيانات. هذا يساعد على تحسين استقرار عملية التدريب وتقليل فرص الضبط الزائد.
مثال: افترض أن مدرسًا يتحقق مما إذا كان جميع الطلاب في الفصل قد قاموا بواجبهم المنزلي قبل إعطائهم اختبارًا. يريد المعلم التأكد من أن كل شخص لديه فرصة عادلة لأداء الاختبار بشكل جيد، لذلك يقومون بفحص عمل كل طالب لمعرفة ما إذا كانوا جميعًا على نفس المستوى.
الحذف العشوائي Dropout
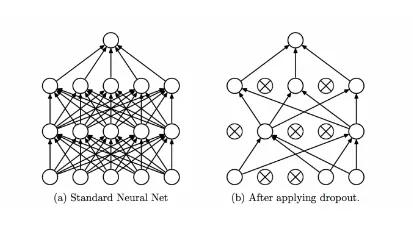
الحذف العشوائي (التسرب) Dropout هو أسلوب يستخدم لمنع الضبط الزائد في نماذج التعلم العميق. إنه يعمل عن طريق إسقاط (حذف) بعض الخلايا العصبية بشكل عشوائي خلال كل فترة. هذا يفرض على النموذج تعلم تمثيلات مختلفة متعددة للبيانات، مما يساعد على منعها من أن تصبح محددة للغاية لبيانات التدريب.
مثال: وجود عدة أشخاص يحاولون حل نفس المشكلة، سيأتي كل شخص بحل مختلف، ومن خلال الجمع بين حلولهم، تحصل على نتيجة أفضل.
الشبكة العصبية المتكررة Recurrent Neural Network (RNN):
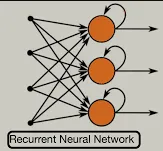
الشبكة العصبية المتكررة Recurrent Neural Network (RNN) هي نوع من الشبكات العصبية المستخدمة في معالجة تسلسل البيانات. الفكرة الرئيسية وراء RNNs هي استخدام نفس الأوزان لمعالجة جميع العناصر في تسلسل ، بحيث يمكن للشبكة الاحتفاظ بالمعلومات حول عناصر التسلسل التي تمت معالجتها حتى الآن. يمكن استخدام RNN في مهام مثل ترجمة اللغة language translation والتعرف على الكلام speech recognition وإنشاء النص text generation.
الذاكرة طويلة قصيرة المدى Long Short-Term Memory (LSTM):
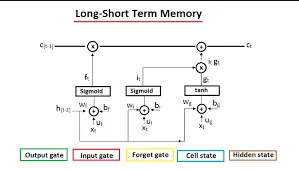
الذاكرة طويلة قصيرة المدى LSTM هو نوع من الشبكات العصبية المتكررة RNN المصممة للتعامل مع مشكلة تلاشي التدرج vanishing gradient. تحدث مشكلة تلاشي التدرج عند تدريب RNN وتصبح تدرجات الخطأ فيما يتعلق بالأوزان صغيرة جدًا، مما يجعل من الصعب تحديث الأوزان بشكل فعال. تحل LSTM هذه المشكلة باستخدام بوابات gates للتحكم في تدفق المعلومات والتدرجات عبر الشبكة.
نقل التعلم Transfer Learning:
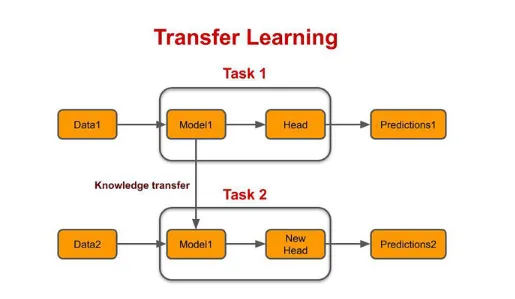
نقل التعلم Transfer Learning هو أسلوب في التعلم العميق حيث يتم ضبط fine-tuned نموذج الشبكة العصبية المدرب مسبقًا pre-trained neural network model لمهمة مختلفة ولكنها ذات صلة. على سبيل المثال، يمكن ضبط نموذج تصنيف الصور المُدرَّب مسبقًا لاكتشاف الكائنات أو تقسيمها. يسمح نقل التعلم بتدريب أسرع وأداء أفضل مقارنة بتدريب نموذج من البداية.
المشفر التلقائي Autoencoder:
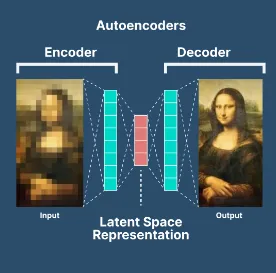
يعد المشفر التلقائي Autoencoder نوعًا من الشبكات العصبية المستخدمة للتعلم غير الخاضع للإشراف unsupervised learning. الفكرة الرئيسية وراء المشفر التلقائي هي تعلم تمثيل مضغوط لبيانات الإدخال ثم استخدام هذا التمثيل لإعادة بناء بيانات الإدخال. يمكن استخدام المشفرات التلقائية في مهام مثل تقليل الأبعاد dimensionality reduction واكتشاف الشذوذ anomaly detection.
شبكة الخصومة التوليدية Generative Adversarial Network (GAN):
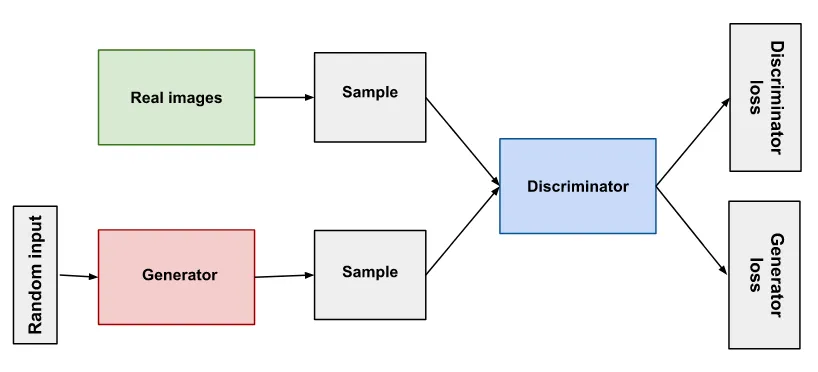
شبكة الخصومة التوليدية Generative Adversarial Network (GAN) هي نوع من الشبكات العصبية المستخدمة في النمذجة التوليدية generative modeling. الفكرة الرئيسية وراء شبكات GAN هي تدريب شبكتين، مولد generator ومميز discriminator، ضد بعضهما البعض. يحاول المولد إنشاء بيانات تشبه البيانات الحقيقية، ويحاول المميز التمييز بين البيانات التي تم إنشاؤها والبيانات الحقيقية. الهدف هو إيجاد توازن بين الشبكتين، حيث يولد المولد بيانات لا يمكن تمييزها عن البيانات الحقيقية.
دالة الخطأ Loss Function
تشبه دالة الخطأ (الخسارة) loss function بطاقة الأداء لشبكة ANN الخاصة بك. يخبرك بمدى نجاح ANN في حل المشكلة. تخيل أنك تلعب لعبة هدفها هو الحصول على أكبر عدد ممكن من النقاط. النتيجة التي تحصل عليها بعد كل جولة هي دالة الخطأ. كلما انخفضت النتيجة، كان أداء ANN أفضل.
لدينا أنواع مختلفة من دالة الخطأ وبعضها مذكور هنا:
- الخطأ التربيعي المتوسط Mean Squared Error (MSE)
- خطأ متوسط الجذر التربيعي Root Mean Squared Error (RMSE)
الخطأ التربيعي المتوسط Mean Squared Error (MSE)
الخطأ التربيعي المتوسط (MSE) هو متوسط الفروق التربيعية بين قيم المخرجات الفعلية actual output values والقيم المتوقعة predicted values. يقيس متوسط حجم الخطأ في التنبؤات.
رياضيا، يتم تعريفه على النحو التالي:
MSE = 1/N * Σ(actual — predicted)²,
حيث N هو عدد العينات وactual وpredicted هي القيم الفعلية والمتوقعة، على التوالي.
على سبيل المثال، لنفترض أن لديك نموذجًا يتنبأ بارتفاع الشخص بناءً على عمره. لديك 5 أشخاص، وارتفاعاتهم وأعمارهم الفعلية هي كما يلي:
P1 : Age = 25, Height = 170 cm
P2: Age = 28, Height = 165 cm
P3: Age = 30, Height = 160 cm
P4: Age = 32, Height = 155 cm
P5: Age = 35, Height = 150 cm
الآن، لنفترض أن نموذجك يتوقع الارتفاعات التالية لهؤلاء الأشخاص:
P1: Age = 25, Height = 165 cm
P2: Age = 28, Height = 170 cm
P3: Age = 30, Height = 162 cm
P4: Age = 32, Height = 157 cm
P5: Age = 35, Height = 153 cm
يمكن حساب MSE للنموذج الخاص بك على النحو التالي:
MSE = 1/5 * ( (170–165)² + (165–170)² + (160–162)² + (155–157)² + (150–153)² ) = (5² + 5² + 2² + 2² + 3²)/5 = 51
إذن، MSE لنموذجك هو 51 ، مما يعني أن متوسط حجم الخطأ في التنبؤات هو 51 سم².
خطأ متوسط الجذر التربيعي Root Mean Squared Error (RMSE)
خطأ متوسط الجذر التربيعي (RMSE) هو الجذر التربيعي لـ MSE . يعطي الخطأ في نفس الوحدات مثل القيم الفعلية والمتوقعة.
رياضيا، يتم تعريفه على النحو التالي:
RMSE = √(MSE)
باستخدام نفس المثال، يمكن حساب RMSE للنموذج الخاص بك على النحو التالي:
RMSE = √(51) = 7.14 cm
إذن، RMSE لنموذجك هو 7.14 سم ، مما يعني أن متوسط حجم الخطأ في التنبؤات هو 7.14 سم.
الموتر Tensor:
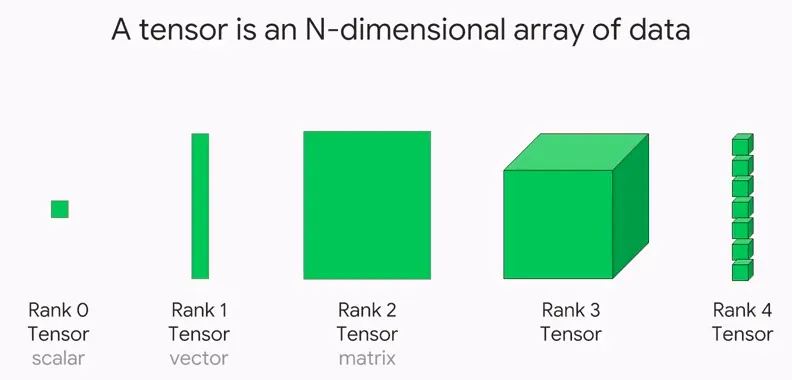
الموتر Tensor هو كائن رياضي يمثل البيانات. إنها مثل مصفوفة متعددة الأبعاد، لكنها أكثر عمومية. فكر في الأمر على أنه مكعب مصنوع من مكعبات أصغر. المكعبات الأصغر تشبه قطع البيانات الفردية، والمكعب الأكبر يشبه الموتر الذي يجمعهم جميعًا معًا. تُستخدم الموترات في العديد من مجالات التعلم الآلي، ولكن بشكل خاص في التعلم العميق، حيث تُستخدم لتخزين كميات كبيرة من البيانات ومعالجتها.
مثال: لنفترض أن لديك بيانات حول الطول والوزن لعشرة أشخاص. يمكنك تمثيل هذه البيانات كموتّر ثنائي الأبعاد، حيث يمثل كل صف ارتفاع ووزن شخص واحد.
التحقق المتقاطع Cross-Validation:
التحقق المتقاطع Cross-Validation هو تقنية مستخدمة في التعلم الآلي لتقييم مدى جودة أداء النموذج على البيانات غير المرئية. الفكرة هي تقسيم البيانات إلى جزأين: مجموعة تدريب training set ومجموعة التحقق من الصحة validation set. يتم تدريب النموذج على مجموعة التدريب ثم يتم تقييمه على مجموعة التحقق من الصحة. تتكرر هذه العملية عدة مرات مع استخدام أجزاء مختلفة من البيانات كمجموعة تحقق في كل مرة. الهدف هو معرفة ما إذا كان النموذج يعاني من الضبط الزائد او الضبط الناقص، والحصول على فكرة أفضل عن كيفية أدائه على البيانات الجديدة غير المرئية.
مثال: افترض أنك معلم ولديك مجموعة من 100 طالب وتريد اختبار مدى معرفتهم بجداول الضرب الخاصة بهم. يمكنك تقسيم الطلاب إلى مجموعتين من 50 لكل طالب. يتم استخدام المجموعة الأولى المكونة من 50 طالبًا لتدريب النموذج، بينما يتم استخدام المجموعة الثانية المكونة من 50 طالبًا للتحقق من صحتها. تكرر هذه العملية عدة مرات، في كل مرة تستخدم مجموعة مختلفة من 50 طالبًا للتحقق من الصحة. بهذه الطريقة، تحصل على فكرة جيدة عن مدى معرفة الطلاب بجداول الضرب الخاصة بهم، دون الحاجة إلى اختبار كل منهم المائة مرة واحدة.
ضبط المعلمات الفائقة Hyperparameter Tuning:
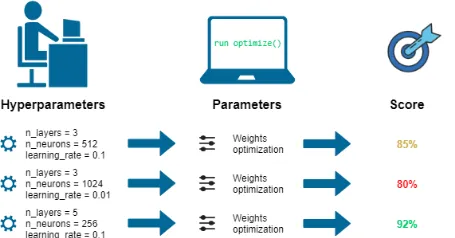
ضبط المعلمات الفائقة Hyperparameter tuning هو عملية اختيار أفضل مجموعة من المعلمات الفائقة لنموذج التعلم الآلي. المعلمات الفائقة Hyperparameters هي المعلمات التي يتم تعيينها قبل تدريب نموذج ولا يمكن تعلمها من البيانات. تتضمن أمثلة المعلمات الفائقة معدل التعلم learning rate أو عدد الطبقات المخفية the number of hidden layers في الشبكة العصبية أو عدد الأشجار في مجموعة التفرعات العشوائية. الهدف من ضبط hyperparameter هو العثور على مجموعة من المعلمات الفائقة التي تؤدي إلى أفضل أداء في مجموعة التحقق من الصحة.
مثال: لنفترض أن لديك وصفة لخبز كعكة. تشبه المكونات الموجودة في الوصفة المعلمات الفائقة لنموذج التعلم الآلي. يمكنك تغيير مكونات الوصفة لترى كيف تؤثر على طعم الكيك. على سبيل المثال، يمكنك محاولة إضافة المزيد من السكر أو القليل من الدقيق لمعرفة ما سيحدث. هذا يشبه ضبط المعلمات الفائقة في التعلم الآلي، حيث يمكنك تجربة مجموعات مختلفة من المعلمات الفائقة لمعرفة أيهما يعمل بشكل أفضل.
الخلايا العصبية Neurons:
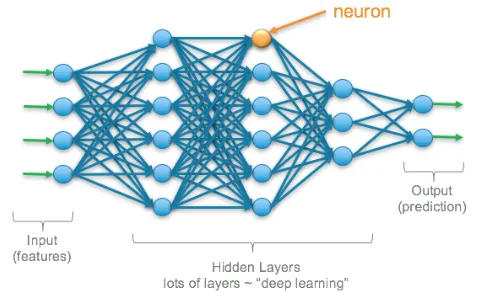
الخلايا العصبية (العصبونات) Neurons هي لبنة بناء أساسية للشبكة العصبية. إنه مثل جهاز كمبيوتر صغير يمكنه إجراء عمليات حسابية بسيطة واتخاذ القرارات بناءً على المدخلات. ترتبط الخلايا العصبية ببعضها البعض في شبكة، وتعمل معًا لأداء مهام معقدة، مثل تصنيف الصور أو ترجمة اللغة. مدخلات الخلايا العصبية هي أرقام تمثل المعلومات، ومخرجات الخلية العصبية هي قرار حول ما يجب فعله بهذه المعلومات.
مثال: لنفترض أن لديك مجموعة من الأصدقاء وتريد أن تلعب لعبة “الهاتف”. في هذه اللعبة، يهمس شخص ما برسالة إلى الشخص التالي، وهكذا دواليك، حتى يتم تمرير الرسالة إلى كل فرد في المجموعة. كل شخص في المجموعة يشبه خلية عصبية في شبكة عصبية، يتلقى المعلومات من شخص واحد ويمررها.
الخاتمة:
التعلم العميق هو حقل فرعي من التعلم الآلي مستوحى من بُنية ووظيفة الدماغ البشري ويستخدم الشبكات العصبية الاصطناعية (ANNs). في هذه المقالة، اكتشفنا 20 مفهومًا أساسيًا للتعلم العميق بدءًا من الأساسيات وحتى الموضوعات الأكثر تقدمًا.
تتضمن هذه المفاهيم الشبكة العصبية الاصطناعية (ANN)، الانحدار الاشتقاقي ، دوال التنشيط (السيني ، ReLU ، Softmax) ، الانتشار الخلفي ، الانتشار الأمامي ، الشبكة العصبية التلافيفية (CNN) ، الفترة ، الضبط الزائد ، التسوية بالدُفعات ، التسرب ، نقل التعلم ، شبكة الخصومة التوليدية (GAN) ، والمشفر التلقائي ، والشبكة العصبية التلافيفية (CNN) ، والشبكة العصبية المتكررة (RNN) ، والذاكرة طويلة قصيرة المدى (LSTM) ونقل التعلم.
من خلال فهم هذه المفاهيم، يمكن للمبتدئين اكتساب فهم شامل وبديهي للتعلم العميق.



