

تركز المقالة على بناء تطبيقات ويب جميلة وتفاعلية للتعلم الآلي دون أي خبرة في تطوير الويب!
سنغطي تحميل البيانات data loading، والتصور visualization، والتفاعل interaction، وإنشاء لوحات التحكم dashboards في بضعة أسطر من كود بايثون الخالص!
ستوفر لوحات التحكم التفاعلية للتعلم الآلي للمستخدمين إمكانية اختيار أي خوارزمية تصنيف classification، وتحديد مقاييس التقييم evaluation metrics، وتبديل المعلمات الفائقة أثناء التنقل في الوقت الفعلي hyperparameters، وكل ذلك بدون أي خبرة في البرمجة.
مقدمة
لا ترغب في إنشاء تطبيقات ويب تفاعلية رائعة لمشاريع التعلم الآلي الخاصة بك!! لكن تطوير الويب، ليس موطن قوتك؟
Streamlit هو طريقك الجديد للخروج! لم يكن تطوير ونشر تطبيقات الويب القوية للتعلم الآلي بهذه السهولة من قبل!
Streamlit هي مكتبة بايثون مفتوحة المصدر تتيح بناء تطبيق ويب مخصص لعلم البيانات والتعلم الآلي وغير ذلك الكثير. يهدف Streamlit إلى بناء ونشر التطبيقات دون الحاجة إلى أي معرفة بتطوير الويب.
لماذا تختار Streamlit؟
تقدم مكتبة Streamlit مجموعة من الميزات الفريدة التي تميزها عن غيرها.
- سكريبتات بايثون النقية دون الحاجة إلى HTML أو CSS وما إلى ذلك.
- تتوفر ميزات التخزين المؤقت للبيانات.
- بناء ونشر سريع وسهل.
- يدعم العديد من أطر عمل علم البيانات.
- يقوم بإنشاء تطبيقات تفاعلية دون أي تعقيد.
- يقدم الويدجيت كمتغيرات.
في غضون دقائق قليلة يمكننا بسهولة إنشاء لوحات تحكم رائعة لمشروع التعلم الآلي الخاص بنا – فلنبدأ!
أهداف التعلم
- استخدام Streamlit وبايثون لبناء لوحة تحكم تفاعلية للتعلم الآلي.
- تدريب العديد من المصنفات بما في ذلك الانحدار اللوجستي Logistic Regression، والغابات العشوائية Random Forest، ومصنفات المتجهات الداعمة Support Vector Classifiers.
- تبديل وتحديد إعدادات المعاملات الفائقة لكل خوارزمية تصنيف.
- رسم مقاييس التقييم للمصنفات.
إعداد التطبيق
يمكننا إعداد التطبيق في بضع خطوات سهلة.
التثبيت
قم بتثبيت مكتبة بايثون Streamlit
pip install streamlit
الاستيراد
قم باستيراد المكتبات المطلوبة لتطبيق التعلم الآلي.
from numpy.core.numeric import True_
from sklearn import metrics
import streamlit as st
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import plot_confusion_matrix, plot_roc_curve, plot_precision_recall_curve
from sklearn.metrics import precision_score, recall_score
التهيئة
لنبدأ ببساطة عن طريق إنشاء سكريبت بايثون يطبع النص على تطبيق الويب.
def main():
st.title(“Introduction to building Streamlit WebApp”)
st.sidebar.title(“This is the sidebar”)
st.sidebar.markdown(“Let’s start with binary classification!!”)
if __name__ == ‘__main__’:
main()
يمكننا تهيئة التطبيق من خلال تحديد طريقة main . نسمي streamlit بواسطة st ثم نحدد الويدجت أو الدالة التي يجب إضافتها إلى التطبيق.
لإنشاء العنوان الرئيسي، نستخدم st.title. يمكن إضافة عناوين الأقسام بواسطة st.header أو st.subheader. يدعم Streamlit أيضًا Markdowns بواسطة st.markdown.
يمكننا إنشاء شريط جانبي sidebar لإضافة عناصر تفاعلية حتى يتمكن المستخدمون من اتخاذ الخيارات المرغوبة لضبط المعلمة الفائقة واختيار النموذج
النتائج سوف تنعكس على الصفحة الرئيسية. يمكن إضافة عنوان الشريط الجانبي بواسطة st.sidebar.title.
تشغيل التطبيق
قم بالتبديل إلى التيرمينال وتشغيل التطبيق من خلال الأمر التالي، وهذا يجب أن يفتح متصفح الويب تلقائيًا. وسيتم تشغيل هذا على المضيف المحلي باستخدام المنفذ الافتراضي 8501.
streamlit run app.py
سيتم تحديث أي تغييرات إضافية يتم إجراؤها على الكود في المحرر تلقائيًا بعد الحفظ دون الحاجة إلى إعادة تنفيذ البرنامج.
تحميل البيانات
سنقوم الآن بتحميل مجموعة البيانات المتاحة مجانًا من مستودعات التعلم الآلي لـ UCI، ويمكننا استخدام مجموعة البيانات هذه للتصنيف الثنائي binary classification. يتكون من عدة أعمدة، وكل عمود من نوع بيانات فئوية لذلك نحتاج إلى إجراء نوع من الترميز لتحويل هذه الميزات الفئوية categorical features إلى بيانات رقمية numerical data.
بالنسبة لعملية تحميل البيانات، نحدد دالة داخل طريقة main لقراءة ملف CSV وتخزينه كإطار بيانات pandas. نحن نصنع دالة للتكرار خلال كل عمود في إطار البيانات لدينا وfit transform في البيانات بحيث يتم تسميتها وترميزها.
@st.cache(persist= True)
def load():
data= pd.read_csv("mushrooms.csv")
label= LabelEncoder()
for i in data.columns:
data[i] = label.fit_transform(data[i])
return data
df = load()
ونظرًا لأننا لا نريد أن يقوم تطبيقنا بتحميل البيانات في كل مرة يتم إجراء أي تغيير على الكود. لهذا، يمكننا استخدام مفكك رمز streamlit (@st.cache(persist= True)) الذي يساعدنا على تخزين المخرجات مؤقتًا على القرص واستخدامها في أي وقت.
يمكننا إضافة دالة إضافية لعرض البيانات الأولية على تطبيق الويب عن طريق إضافة مربع اختيار checkbox في الشريط الجانبي والذي سيعكس البيانات الموجودة في القسم الرئيسي إذا تم تحديده.
if st.sidebar.checkbox("Display data", False):
st.subheader("Show Mushroom dataset")
st.write(df)

إنشاء تقسيمات التدريب والاختبار
تتمثل الخطوة الأولى لإنشاء النموذج في إنشاء تقسيمات تدريب واختبار training and test splits. يمكننا إنشاء دالة التقسيم لنفسها. يمكننا الآن استخدام دالة تقسيم التدريب والاختبار من مكتبة sklearn لتقسيم مجموعة البيانات الخاصة بنا وحذف العمود الهدف.
@st.cache(persist=True)
def split(df):
y = df.type
x = df.drop(columns=["type"])
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3, random_state=0)
return x_train, x_test, y_train, y_test
x_train, x_test, y_train, y_test = split(df)
الآن يمكننا المضي قدمًا في تدريب وتقييم النموذج.
مقاييس التقييم
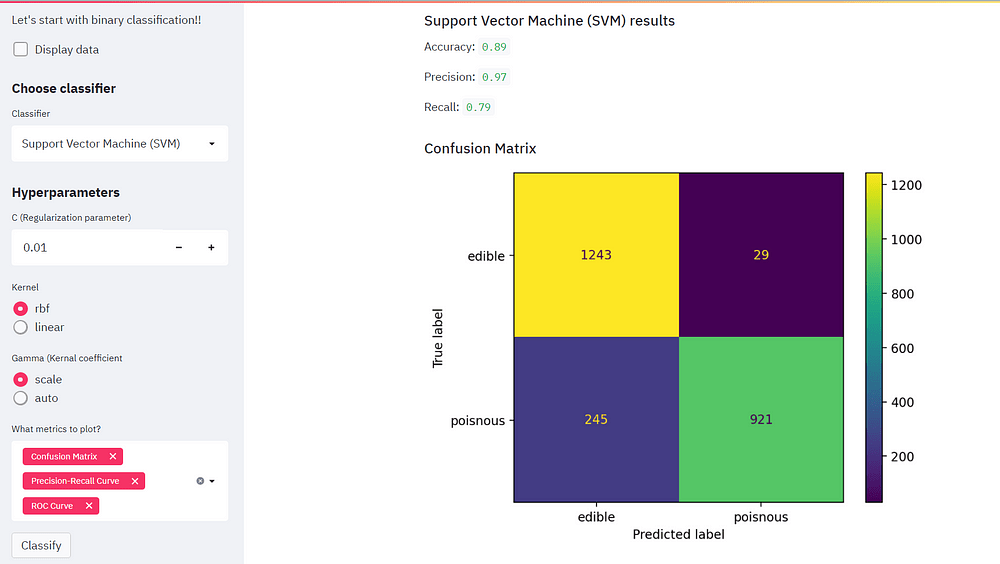
سننشئ دالة لرسم مقاييس التقييم المختلفة. يتيح ذلك للمستخدم تحديد أي مقاييس للتقييم مثل مصفوفة الارتباك Confusion matrix ومنحنى ROC ومنحنى Precision-Recall لأنها مشكلة تصنيف ثنائية.
قم بإنشاء قائمة مقاييس وعنوان فرعي لإنشاء الرسومات. دعونا أيضًا ننشئ فئة تحتوي على قيمتين صالحة للأكل edible وسامة poisonous.
def plot_metrics(metrics_list):
if "Confusion Matrix" in metrics_list:
st.subheader("Confusion Matrix")
plot_confusion_matrix(model, x_test, y_test, display_labels= class_names)
st.pyplot()
if "ROC Curve" in metrics_list:
st.subheader("ROC Curve")
plot_roc_curve(model, x_test, y_test)
st.pyplot()
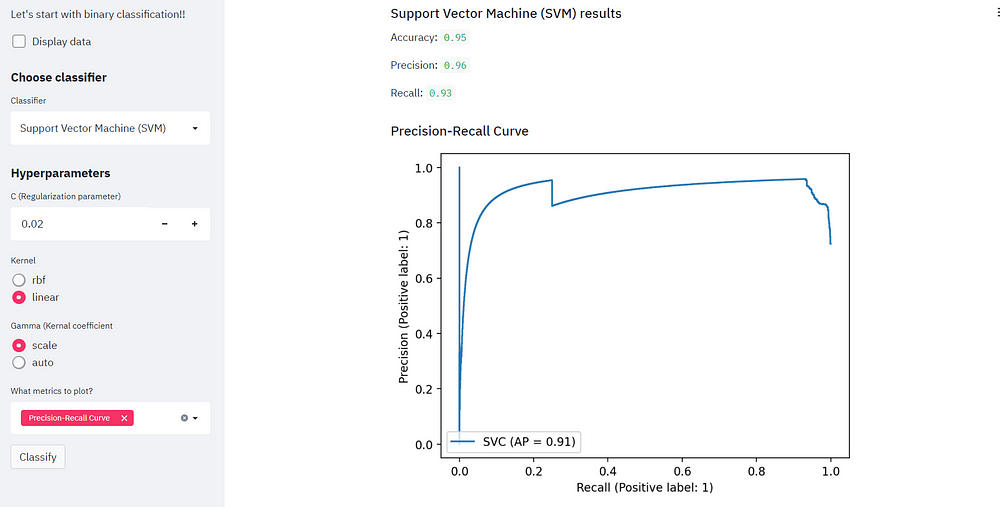
if "Precision-Recall Curve" in metrics_list:
st.subheader("Precision-Recall Curve")
plot_precision_recall_curve(model, x_test, y_test)
st.pyplot()
class_names = ["edible", "poisnous"]
بمجرد استدعاء دالة التقييم المحددة، سيتم إنشاء مخطط matplotlib الذي سيتم عرضه على الصفحة الرئيسية.
تدريب مصنف SVM
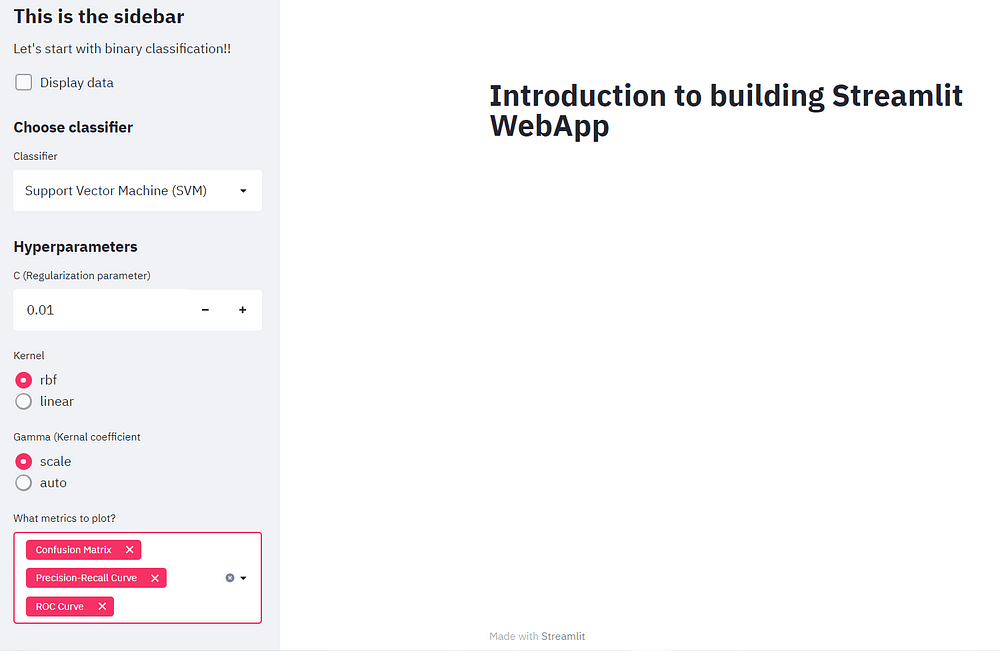
دعنا نضيف عنوان فرعي إلى الشريط الجانبي مما يسمح للمستخدم باختيار مصنف. بعد ذلك، يمكننا إنشاء ويدجت يعرض قائمة من المصنفات بطريقة قائمة منسدلة. يمكننا إضافة خيارات المصنف الخاصة بنا بدءًا من SVM والانحدار اللوجستي والأخير باعتباره السؤال الأول العشوائي.
st.sidebar.subheader("Choose classifier")
classifier = st.sidebar.selectbox("Classifier", ("Support Vector Machine (SVM)", "Logistic Regression", "Random Forest"))

إضافة المعلمات الفائقة لـ SVM
بعد أن يحدد المستخدم مصنف SVM، يتم عرض قائمة بالمعلمات الفائقة. يمكننا إضافة معلمة تنظيم regularization parameter وتوفير نطاق من 0.1 إلى 10.0 يمكن التعامل معه بعلامات زائد وناقص. تكمن قوة SVMs في اختيار انويتها kernels.
يمكننا ببساطة إضافة زر اختيار radio button يسمح للمستخدمين بالاختيار من بين نواتين – RBF وخطي linear. وأخيرًا، دعنا نضيف آخر معلمة فائقة تسمى جاما Gamma.
لأننا نريد أيضًا أن يتم رسم مقاييس التقييم على تطبيق الويب. لذلك دعنا نضيف أيضًا الميزة التي تلبي مقاييس التقييم المطلوبة للمستخدم لهذا الغرض، يمكننا إنشاء ويدجت متعددة التحديد تتيح للمستخدم إدخال مقياس واحد أو أكثر.
if classifier == "Support Vector Machine (SVM)":
st.sidebar.subheader("Hyperparameters")
C = st.sidebar.number_input("C (Regularization parameter)", 0.01, 10.0, step=0.01, key="C")
kernel = st.sidebar.radio("Kernel", ("rbf", "linear"), key="kernel")
gamma = st.sidebar.radio("Gamma (Kernal coefficient", ("scale", "auto"), key="gamma")
metrics = st.sidebar.multiselect("What metrics to plot?", ("Confusion Matrix", "ROC Curve", "Precision-Recall Curve"))
تدريب النموذج
المضي قدما نحو إنشاء المصنف الفعلي. أولاً، سنقوم بإنشاء مثيل للنموذج وتطبيق fit بيانات التدريب الخاصة بنا. متبوعًا بحساب الدقة accuracy ثم إجراء تنبؤات على مجموعة بيانات الاختبار.
نحن لا نهتم فقط بالدقة ولكن أيضًا بالدقة precision والاسترجاع recall ومن ثم نود عرضها على الشاشة الرئيسية.
قم بتضمين الكود التالي في if كتلة مصنف SVM.
if st.sidebar.button("Classify", key="classify"):
st.subheader("Support Vector Machine (SVM) results")
model = SVC(C=C, kernel=kernel, gamma=gamma)
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
y_pred = model.predict(x_test)
st.write("Accuracy: ", accuracy.round(2))
st.write("Precision: ", precision_score(y_test, y_pred, labels=class_names).round(2))
st.write("Recall: ", recall_score(y_test, y_pred, labels=class_names).round(2))
plot_metrics(metrics)
مذهل!! لقد أكملنا مصنف SVM مما يسمح للمستخدم بتجربة العديد من ميزات ضبط مقياس التقييم والمعلمات الفائقة.
قم بتغيير معامل التنظيم واطلع على مقاييس التقييم المختلفة!

يمكننا أيضًا تبديل النواة ونلاحظ كيف تتحسن الدقة! يمكننا تحليل نفس الشيء من خلال مقاييس التقييم.
تدريب تصنيف الانحدار اللوجستي
دعونا نبني دوال مصنف الانحدار اللوجستي تمامًا كما فعلنا مع SVM.
قم بملاءمة Fit نموذج الانحدار اللوجستي واحصل على الدقة والتنبؤ لنفسه واكتب النتائج المقابلة على الصفحة الرئيسية. دعونا لا ننسى إجراء بعض التغييرات الطفيفة مثل إضافة شريط التمرير slider الذي سيسمح للمستخدم باختيار الحد الأقصى للتكرار. ثبت الحد الأدنى والأعلى عند 100 و 500 على التوالي.
قم بتغيير المعلمات الفائقة وفقًا لمصنف الانحدار اللوجستي وإزالة معلمات Kernel و Gamma.
if classifier == "Logistic Regression":
st.sidebar.subheader("Hyperparameters")
C = st.sidebar.number_input("C (Regularization parameter)", 0.01, 10.0, step=0.01, key="C_LR")
max_iter = st.sidebar.slider("Maximum iterations", 100, 500, key="max_iter")
metrics = st.sidebar.multiselect("What metrics to plot?", ("Confusion Matrix", "ROC Curve", "Precision-Recall Curve"))
if st.sidebar.button("Classify", key="classify"):
st.subheader("Logistic Regression Results")
model = LogisticRegression(C=C, max_iter=max_iter)
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
y_pred = model.predict(x_test)
st.write("Accuracy: ", accuracy.round(2))
st.write("Precision: ", precision_score(y_test, y_pred, labels=class_names).round(2))
st.write("Recall: ", recall_score(y_test, y_pred, labels=class_names).round(2))
plot_metrics(metrics)
الآن نحن جاهزون لمقارنة أداء كلا المصنفين!
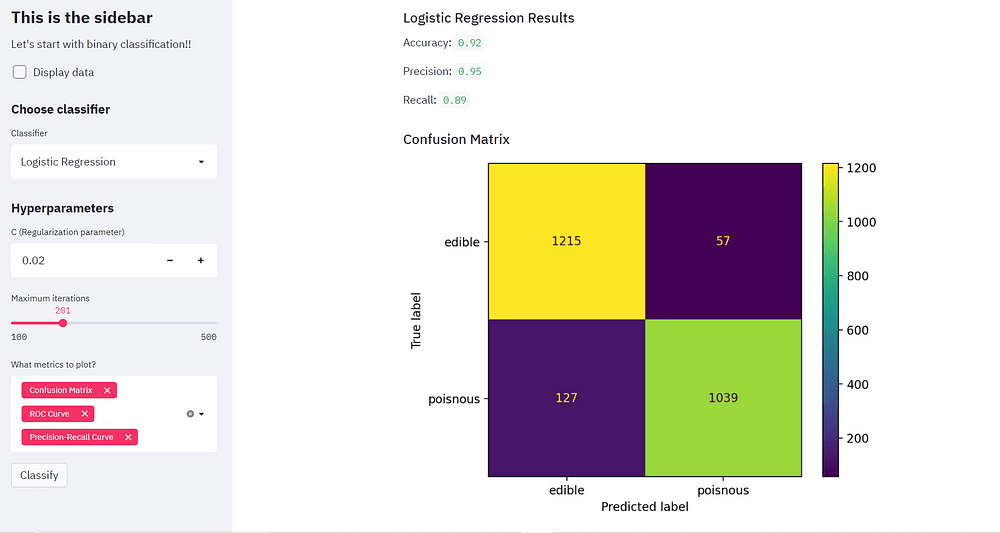
تدريب مصنف الغابة العشوائية
مرحبًا بكم في المهمة النهائية لمشروعنا! هنا سنقوم بإنشاء مصنف للغابات العشوائية. ابدأ بمسح المعلمات السابقة وإضافة معلمات جديدة مثل عدد المقدرات number of estimators التي تحدد عدد الأشجار في الغابة لذلك نضيف مربع إدخال input box، ونضبط الرقم الافتراضي على 100، ونعرف 10 كقيمة زيادة.
أضف معلمات أخرى أيضًا، أولها هو أقصى عمق max depth للغابة وهذه المرة قم بتعيين خطوة زيادة بمقدار 1. بعد ذلك، يمكننا تضمين زر اختيار يسمح للمستخدم بتحديد عينات التمهيد عند بناء الأشجار.
if classifier == "Random Forest":
st.sidebar.subheader("Hyperparameters")
n_estimators= st.sidebar.number_input("The number of trees in the forest", 100, 5000, step=10, key="n_estimators")
max_depth = st.sidebar.number_input("The maximum depth of tree", 1, 20, step =1, key="max_depth")
bootstrap = st.sidebar.radio("Bootstrap samples when building trees", ("True", "False"), key="bootstrap")
metrics = st.sidebar.multiselect("What metrics to plot?", ("Confusion Matrix", "ROC Curve", "Precision-Recall Curve"))
if st.sidebar.button("Classify", key="classify"):
st.subheader("Random Forest Results")
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, bootstrap= bootstrap, n_jobs=-1 )
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
y_pred = model.predict(x_test)
st.write("Accuracy: ", accuracy.round(2))
st.write("Precision: ", precision_score(y_test, y_pred, labels=class_names).round(2))
st.write("Recall: ", recall_score(y_test, y_pred, labels=class_names).round(2))
plot_metrics(metrics)
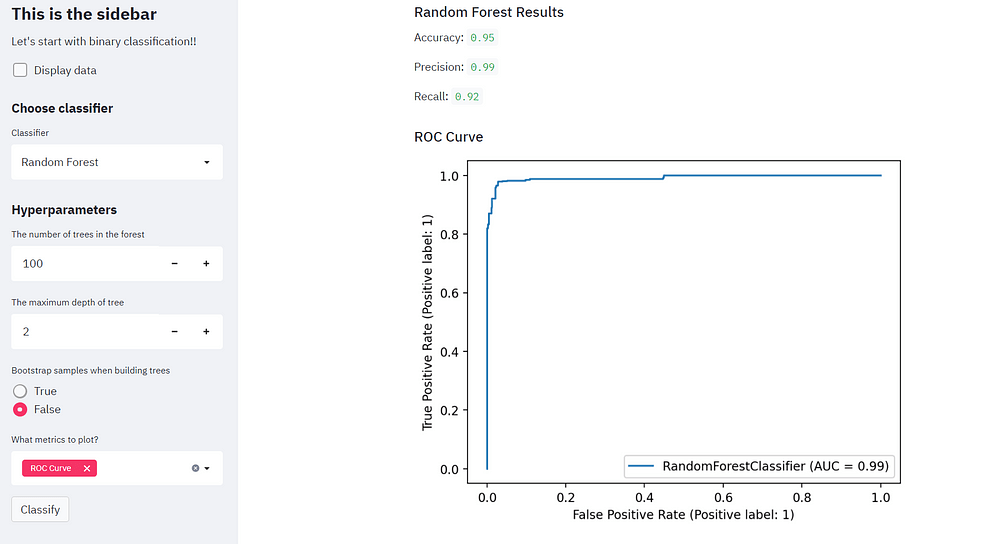
قم بإجراء التصنيف باستخدام مصنف الغابات العشوائية ولاحظ كيف نمتلك دقة عالية جدًا وقيمًا مرغوبة للـ position والاسترجاع recall.
الملاحظات النهائية
لقد نجحنا في استخدام مكتبة Streamlit وبايثون لبناء تطبيق ويب بسيط ولكنه قوي للتعلم الآلي ، كما تعلمنا أيضًا العنوان وإضافة نص Markdown وويدجت مثل القوائم المنسدلة وأزرار الاختيار ومدخلات الأرقام ومربعات الاختيار واشرطة التمرير.
ليس ذلك فحسب، لقد قمنا بتنفيذ هذه الأدوات بمرونة للسماح للمستخدم بإجراء اختيار النموذج وتعيين المعلمات الفائقة، مما يسمح للمستخدمين باختيار مقاييس التقييم المختلفة.
مع هذا المشروع العملي، يجب أن تكون قد أدركت القوة الحقيقية لمكتبة Streamlit!! يسمح Streamlit لأي شخص ليس لديه خلفية رسمية للتعلم الآلي أو البرمجة بالتعامل مع نماذج التعلم الآلي بسهولة.



